Aviator这么丝滑,怎么实现的呢?
大家好,我是老三,在上期 里我们介绍了轻量级规则引擎AviatorScript的基本用法和一些使用案例,这期我们来研究一下,这么丝滑的规则脚本是怎么实现的。
概览
我们先来回顾一个简单的例子:
@Test
public void test(){
//表达式脚本
String expression = "if(a > 1) { return b+2; } else { return c; }";
//一:编译
Expression compiledExpression=AviatorEvaluator.getInstance().compile(expression);
//上下文
Map<String, Object> env = new HashMap<>();
env.put("a", 2);
env.put("b", 3);
env.put("c", 4);
//二、执行
Object result =compiledExpression.execute(env);
System.out.println(result);
}
这是一个很简单的is-else·脚本,脚本里做了一个条件判断,分别返回不同的值。
要执行这个脚本,主要分为两步,一是编译,二是执行,AviatorScript的具体实现,就藏在了这两大步里,我们一起去挖掘Aviator实现的秘密吧。
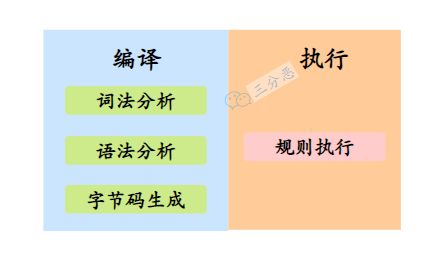
编译compile()
接着上面这个例子,我们进去看一下compile()的关键代码:
public Expression compile(final String expression) {
return compile(expression, this.cachedExpressionByDefault);
}

经过一层套一层的compile(),我们终于看到一个代码多一些的compile()方法。
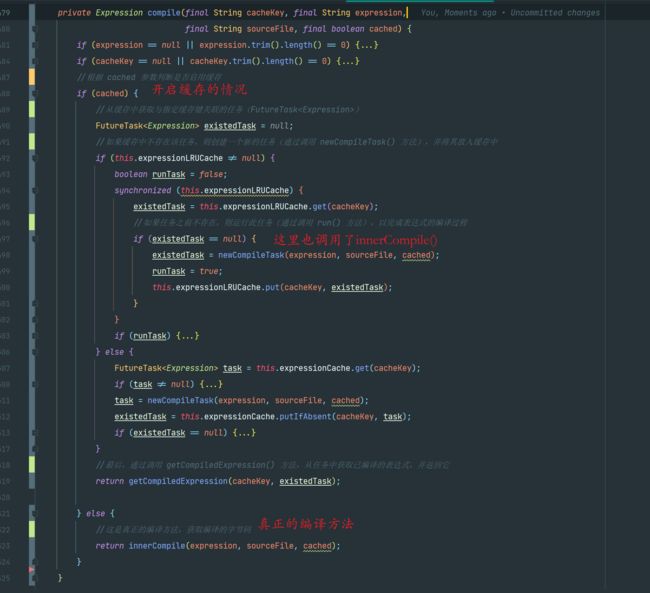
分析一下这段代码:
-
根据传入的cached参数判断是否启用缓存。如果启用缓存,则会执行以下步骤:
a. 如果使用了LRU(最近最少使用)缓存策略,那么首先会尝试从LRU缓存中获取已经存在的FutureTask对象,该对象用于表示正在编译的任务。如果存在,就返回已编译的表达式;如果不存在,则创建一个新的编译任务(newCompileTask),并将其放入LRU缓存中。
b. 如果没有使用LRU缓存(this.expressionLRUCache为null),那么会尝试从普通的缓存(this.expressionCache)中获取已经存在的FutureTask对象。如果存在,就返回已编译的表达式;如果不存在,则创建一个新的编译任务,并将其放入缓存中。
-
如果在缓存中找到了对应的编译任务(existedTask),则执行该任务(existedTask.run())并返回已编译的表达式。
-
如果不启用缓存(cached为false),则调用innerCompile方法进行实际的编译操作,并返回编译后的表达式。
到了这里,我们终于抓住了执行实际编译的方法innerCompile(),继续跟着源码前进。
innerCompile()
innerCompile()这个方法就是实际用来来执行编译的方法:
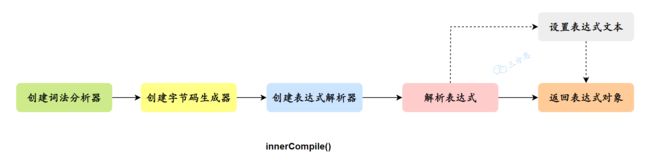
/**
* 执行真正的编译操作:将给定的表达式进行词法分析、语法分析,并生成一个完整的表达式对象
* @param expression 需要编译的表达式
* @param sourceFile 源文件路径
* @param cached 是否启用缓存
* @return 表达式对象
*/
private Expression innerCompile(final String expression, final String sourceFile,
final boolean cached) {
//1.创建表达式词法分析器:通过传入当前对象和表达式,创建 ExpressionLexer 对象。ExpressionLexer 用于对表达式进行词法分析,如将脚本解析为变量、数字、字符串、注释等,并构造Token流进行后续处理。
ExpressionLexer lexer = new ExpressionLexer(this, expression);
//2.创建字节码生成器:调用 newCodeGenerator 方法创建 CodeGenerator 对象。CodeGenerator 用于生成自定义的字节码
CodeGenerator codeGenerator = newCodeGenerator(sourceFile, cached);
//3.创建表达式解析器:通过传入当前对象、Lexer 和 CodeGenerator,创建 ExpressionParser 对象。ExpressionParser 用于将词法分析得到的标记组装成一个完整的表达式。
ExpressionParser parser = new ExpressionParser(this, lexer, codeGenerator);
//4.解析表达式:调用 parser 的 parse 方法,将词法分析得到的标记解析为一个表达式对象(exp)。
Expression exp = parser.parse();
//5.设置表达式文本(可选):根据选项 Options.TRACE_EVAL 的值来判断是否需要设置表达式对象的文本。如果 Options.TRACE_EVAL 为 true,则将 expression 设置在 exp 对象中,用于跟踪和调试目的。
if (getOptionValue(Options.TRACE_EVAL).bool) {
((BaseExpression) exp).setExpression(expression);
}
//6.返回表达式对象:返回解析后的表达式对象 exp。
return exp;
}
在这段代码里,创建了几个关键的角色:

- ExpressionLexer:词法分析器,它用于将AviatorScript脚本解析成变量、数字、字符串、注释等不同的词法单元(Token),并构造一个Token流以供后续处理。
- CodeGenerator:字节码生成器,它用于动态生成自定义的字节码。在AviatorScript中,CodeGenerator负责将ExpressionLexer生成的Token流编译成表达式对象的字节码。
- ExpressionParser:表达式解析器,它用于将AviatorScript脚本编译为表达式对象(通常是ClassExpression)。ExpressionParser支持解析多种AviatorScript脚本,并且在解析过程中会利用CodeGenerator将ExpressionLexer构建的Token流编译成适当的表达式对象(比如ClassExpression)。
ExpressionLexer词法分析器
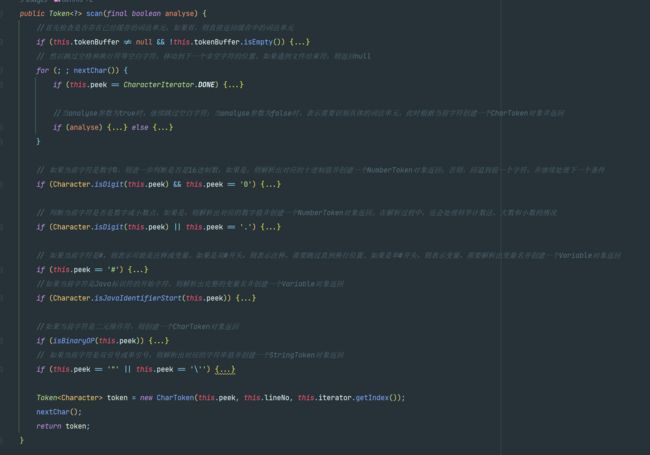
ExpressionLexer负责对AviatorScript脚本进行词法分析,将其解析为Token流。
public Token<?> scan() {
return this.scan(true);
}
这个类里代码不多,最重要的方法就是scan,用于扫描输入的字符串并将其转换为不同类型的词法单元(Token),它会在创建ExpressionParser的时候被调用。
具体来说,它按照一定的规则逐个字符地读取输入,并根据字符的特征确定相应的词法单元类型。
CodeGenerator字节码生成器
CodeGenerator用于动态生成自定义的字节码。
我们先来看下它的继承体系:
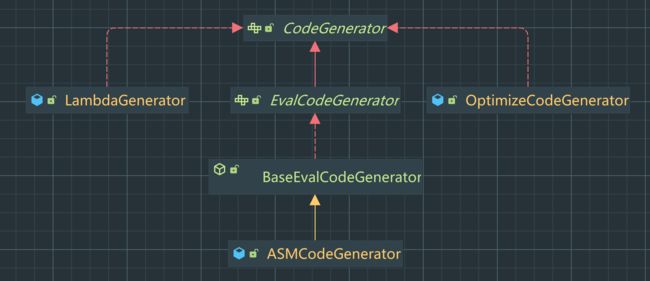
CodeGenerator是一个顶层接口,定义了字节码生成的方法和规范。ASMCodeGenerator是默认的实现类,它基于ASM框架进行具体的字节码生成。它实现了CodeGenerator接口中声明的操作,将代码转化为ASM指令并生成对应的字节码。OptimizeCodeGenerator是一个优化过的字节码生成器,默认情况下也使用的是ASMCodeGenerator作为底层实现。OptimizeCodeGenerator可以提高提高执行效率,在生成字节码之前,它可以执行一些预处理的计算逻辑,然后再将结果交给ASMCodeGenerator来生成字节码。通过这种优化,可以减少运行时的计算量,提高脚本执行的效率。LambdaGenerator是一个用于生成Lambda表达式代码的代码生成器。它接受一个父级代码生成器和其他参数作为输入,并通过调用内部的codeGenerator来生成Lambda表达式的代码。
ASM拾遗
这里再简单学习一下字节码技术,因为ASM在Aviator里扮演了非常重要的作用,是Aviator依赖的核心类库。
ASM 是一个 Java 字节码操控框架。它能被用来动态生成类或者增强既有类的功能。ASM 可以直接产生二进制 class 文件,也可以在类被加载入 Java 虚拟机之前动态改变类行为。Java class 被存储在严格格式定义的 .class 文件里,这些类文件拥有足够的元数据来解析类中的所有元素:类名称、方法、属性以及 Java 字节码(指令)。ASM 从类文件中读入信息后,能够改变类行为,分析类信息,甚至能够根据用户要求生成新类。
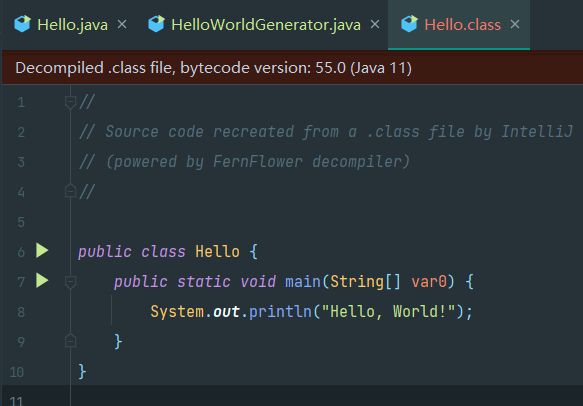
看一个简单的例子,Hello World都写过吧:
public class Hello {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
Java代码在执行前,需要先编译,那么要生成和这个类编译之后相同的Java类文件(.class文件),用ASM怎么实现呢?
稍微有点繁琐:
public class HelloWorldGenerator {
public static void main(String[] args) throws IOException {
// 1.创建一个 ClassWriter 实例,以生成一个新的类
ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_FRAMES);
// 2.定义类的基本信息:访问修饰符、类名、父类、接口
cw.visit(Opcodes.V11, Opcodes.ACC_PUBLIC, "Hello", null, "java/lang/Object", null);
// 3.定义主方法
MethodVisitor mainMethod = cw.visitMethod(Opcodes.ACC_PUBLIC + Opcodes.ACC_STATIC, "main",
"([Ljava/lang/String;)V", null, null);
mainMethod.visitCode();
mainMethod.visitFieldInsn(Opcodes.GETSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;");
mainMethod.visitLdcInsn("Hello, World!");
mainMethod.visitMethodInsn(Opcodes.INVOKEVIRTUAL, "java/io/PrintStream", "println",
"(Ljava/lang/String;)V", false);
mainMethod.visitInsn(Opcodes.RETURN);
mainMethod.visitMaxs(2, 1);
mainMethod.visitEnd();
//4.类结束
cw.visitEnd();
//5.将字节码写入文件
byte[] byteCode = cw.toByteArray();
FileOutputStream fos = new FileOutputStream("Hello.class");
fos.write(byteCode);
fos.close();
}
}
在Idea里可以直接反编译生成的字节码文件:
ASM框架,主要由这几个核心组件组成:

- ClassReader(类读取器):ClassReader用于读取已编译的Java类文件的字节码。它将字节码解析为可以访问和操作的结构化表示形式。
- ClassWriter(类写入器):ClassWriter用于生成新的Java类文件的字节码。它提供了一组API来创建类、方法、字段和指令等,并将它们转换为字节码形式。
- ClassVisitor(类访问器):ClassVisitor是一个接口,用于访问和修改正在被读取或写入的类。通过实现ClassVisitor接口,开发人员可以自定义对类的访问方式,并在访问过程中进行相应的操作。
- MethodVisitor(方法访问器):MethodVisitor是ClassVisitor的子接口,用于访问和修改正在被读取或写入的方法。通过实现MethodVisitor接口,开发人员可以自定义对方法的访问方式,并在访问过程中进行相应的操作。
- FieldVisitor(字段访问器):FieldVisitor是ClassVisitor的子接口,用于访问和修改正在被读取或写入的字段。通过实现FieldVisitor接口,开发人员可以自定义对字段的访问方式,并在访问过程中进行相应的操作。
- AnnotationVisitor(注解访问器):AnnotationVisitor是ClassVisitor的子接口,用于访问和修改正在被读取或写入的注解。通过实现AnnotationVisitor接口,开发人员可以自定义对注解的访问方式,并在访问过程中进行相应的操作。
……
简单了解一下ASM技术之后,接下来我们看看核心的代码生成器ASMCodeGenerator。
ASMCodeGenerator
ASMCodeGenerator在Aviator中的作用是将用户提供的表达式转换为可执行的Java字节码,并且能够动态生成类和方法来存储和执行这些字节码。
包括其它几个CodeGenerator最后调用的也是ASMCodeGenerator。
ASMCodeGenerator是对ASM的一个封装,加入了一些定制化的逻辑判断,其实生成代码的主要流程和我们前面HelloWorld的例子是类似的。
-
创建 ClassWriter 对象,用于生成类文件的字节码。
ASMCodeGenerator的构造方法:
public ASMCodeGenerator(final AviatorEvaluatorInstance instance, final String sourceFile, final AviatorClassLoader classLoader, final OutputStream traceOut) { super(instance, sourceFile, classLoader); //创建内部类型 this.className = "Script_" + System.currentTimeMillis() + "_" + CLASS_COUNTER.getAndIncrement(); //创建ClassWriter, 自动填充栈帧信息 this.classWriter = new ClassWriter(ClassWriter.COMPUTE_FRAMES); //访问类 visitClass(); } -
定义类名、父类、接口等基本信息,并开始访问类
visitClass()方法:/** * 访问类,生成类的相关信息 */ private void visitClass() { // 设置类的基本信息 this.classWriter.visit(this.instance.getBytecodeVersion(), ACC_PUBLIC + ACC_SUPER, this.className, null, "com/googlecode/aviator/ClassExpression", null); // 设置类的源文件名 this.classWriter.visitSource(this.sourceFile == null ? this.className : this.sourceFile, null); } -
设置类的字段和方法,生成对应的字段和方法的字节码。
- 比如在启动代码生成过程的
start()里生成了一个默认的构造函数,并且开始生成方法代码。
/** * 启动代码生成过程 */ @Override public void start() { //生成构造函数的代码 makeConstructor(); //用于开始生成方法的代码 startVisitMethodCode(); }makeConstructor()方法:
private void makeConstructor() { // 创建公共构造函数 this.mv = this.classWriter.visitMethod(ACC_PUBLIC, CONSTRUCTOR_METHOD_NAME, "(Lcom/googlecode/aviator/AviatorEvaluatorInstance;Ljava/util/List;Lcom/googlecode/aviator/lexer/SymbolTable;)V", null, null); this.mv.visitCode(); // 开始访问构造函数的代码 // 调用父类的构造函数 this.mv.visitVarInsn(ALOAD, 0); this.mv.visitVarInsn(ALOAD, 1); this.mv.visitVarInsn(ALOAD, 2); this.mv.visitVarInsn(ALOAD, 3); this.mv.visitMethodInsn(INVOKESPECIAL, "com/googlecode/aviator/ClassExpression", CONSTRUCTOR_METHOD_NAME, "(Lcom/googlecode/aviator/AviatorEvaluatorInstance;Ljava/util/List;Lcom/googlecode/aviator/lexer/SymbolTable;)V"); // 设置内部变量的值 if (!this.innerVars.isEmpty()) { for (Map.Entry<String, String> entry : this.innerVars.entrySet()) { String outterName = entry.getKey(); String innerName = entry.getValue(); this.mv.visitVarInsn(ALOAD, 0); this.mv.visitTypeInsn(NEW, JAVA_TYPE_OWNER); this.mv.visitInsn(DUP); this.mv.visitLdcInsn(outterName); this.mv.visitVarInsn(ALOAD, 3); this.mv.visitMethodInsn(INVOKESPECIAL, JAVA_TYPE_OWNER, CONSTRUCTOR_METHOD_NAME, "(Ljava/lang/String;Lcom/googlecode/aviator/lexer/SymbolTable;)V"); this.mv.visitFieldInsn(PUTFIELD, this.className, innerName, "Lcom/googlecode/aviator/runtime/type/AviatorJavaType;"); } } // 设置内部方法的值 if (!this.innerMethodMap.isEmpty()) { for (Map.Entry<String, String> entry : this.innerMethodMap.entrySet()) { String outterName = entry.getKey(); String innerName = entry.getValue(); this.mv.visitVarInsn(ALOAD, 0); this.mv.visitVarInsn(ALOAD, 1); this.mv.visitLdcInsn(outterName); this.mv.visitVarInsn(ALOAD, 3); this.mv.visitMethodInsn(INVOKEVIRTUAL, "com/googlecode/aviator/AviatorEvaluatorInstance", "getFunction", "(Ljava/lang/String;Lcom/googlecode/aviator/lexer/SymbolTable;)Lcom/googlecode/aviator/runtime/type/AviatorFunction;"); this.mv.visitFieldInsn(PUTFIELD, this.className, innerName, "Lcom/googlecode/aviator/runtime/type/AviatorFunction;"); } } // 设置常量池中的值 if (!this.constantPool.isEmpty()) { for (Map.Entry<Token<?>, String> entry : this.constantPool.entrySet()) { Token<?> token = entry.getKey(); String fieldName = entry.getValue(); this.mv.visitVarInsn(ALOAD, 0); onConstant0(token, true); this.popOperand(); this.mv.visitFieldInsn(PUTFIELD, this.className, fieldName, OBJECT_DESC); } } this.mv.visitInsn(RETURN); // 返回 this.mv.visitMaxs(4, 1); // 最大栈深度和局部变量数 this.mv.visitEnd(); // 结束访问构造函数 } - 比如在启动代码生成过程的
-
在方法的字节码生成过程中,根据代码逻辑和类型信息,生成相应的字节码指令和操作数。
- 比如这个方法
onTernaryLeft0,表示处理三元表达式的左侧逻辑:
/** * 处理三元表达式的左侧逻辑 * @param lookhead 当前处理的标记 */ @Override public void onTernaryLeft(final Token<?> lookhead) { // 跳转到 peekLabel1() 标签处执行 this.mv.visitJumpInsn(GOTO, peekLabel1()); // 访问 popLabel0() 标签 visitLabel(popLabel0()); // 访问当前代码行号 visitLineNumber(lookhead); // 弹出一个布尔值 this.popOperand(); }在ASMCodeGenerator的方法里,只要是on开头的,基本都是根据一定的逻辑去生成对应的代码。
- 比如这个方法
-
最后,结束访问类,输出字节码。
- 在
end()方法里结束方法体和结束类的访问
/** * 结束方法体,对方法代码和类进行结束访问 */ private void end(final boolean unboxObject) { // 结束访问方法的代码 endVisitMethodCode(unboxObject); // 结束访问类 endVisitClass(); } - 在
这里我们就对ASMCodeGenerator有了一个大概的了解,ASMCodeGenerator在Aviator扮演的就是默默无闻的搬砖工,把底层的事情都干了。
ExpressionParser表达式解析器
ExpressionParser将Token流编译为表达式对象,它充当一个协调者的角色,战斗在编译工作的一线。
我们先来看下构造方法:
/**
* ExpressionParser的构造方法
*/
public ExpressionParser(final AviatorEvaluatorInstance instance, final ExpressionLexer lexer,
final CodeGenerator codeGenerator) {
super();
//创建了一个 ScopeInfo 对象,并将其赋值给 scope 属性。ScopeInfo 对象用于跟踪变量和函数的作用域信息。
this.scope = new ScopeInfo(0, 0, 0, 0, false, new ArrayDeque<DepthState>());
//将传入的 AviatorEvaluatorInstance 实例赋值给 instance 属性。
this.instance = instance;
//从 instance 中获取选项 CAPTURE_FUNCTION_ARGS 的值,并将其设置为解析器的 captureFuncArgs 属性。
this.captureFuncArgs = instance.getOptionValue(Options.CAPTURE_FUNCTION_ARGS).bool;
//将传入的 ExpressionLexer 实例赋值给 lexer 属性
this.lexer = lexer;
//⚡⚡⚡通过调用 lexer 的 scan() 方法,获取下一个 Token,并将其赋值给 lookhead 属性。lookhead 表示当前待处理的 Token。
this.lookhead = this.lexer.scan();
//如果 lookhead 不为空,则将 parsedTokens 的值加1。parsedTokens 表示已经解析的 Token 数量。
if (this.lookhead != null) {
this.parsedTokens++;
}
//从 instance 中获取选项 FEATURE_SET 的值,并将其设置为解析器的 featureSet 属性。featureSet 表示当前使用的特性集合。
this.featureSet = this.instance.getOptionValue(Options.FEATURE_SET).featureSet;
//如果 lookhead 为空,则报告语法错误,提示输入的脚本为空。
if (this.lookhead == null) {
reportSyntaxError("blank script");
}
//设置解析器的代码生成器为传入的 CodeGenerator 实例。
setCodeGenerator(codeGenerator);
//通过调用 getCodeGeneratorWithTimes() 方法获取代码生成器,并将解析器实例设置为其属性中的 parser。
getCodeGeneratorWithTimes().setParser(this);
}
在这段代码里我们可以看到前面说的调用词法分析器的部分:
//⚡⚡⚡通过调用 lexer 的 scan() 方法,获取下一个 Token,并将其赋值给 lookhead 属性。lookhead 表示当前待处理的 Token。
this.lookhead = this.lexer.scan();
parse()
接下来我们看看直接干活的parse()方法,通过parse()方法完成对Token的解析。
//4.解析表达式:调用 parser 的 parse 方法,将词法分析得到的标记解析为一个表达式对象(exp)。
Expression exp = parser.parse();
比如if,for,let等脚本特性,解析逻辑都是依赖parse()方法完成的:
public Expression parse(final boolean reportErrorIfNotEOF) {
//调用statements()方法解析一系列语句,并将结果保存在statementType变量中。
//StatementType表示语句的类型,可能是三元表达式(StatementType.Ternary)或其他类型的语句。
StatementType statementType = statements();
if (this.lookhead != null && reportErrorIfNotEOF) {
if (statementType == StatementType.Ternary) {
reportSyntaxError("unexpect token '" + currentTokenLexeme()
+ "', maybe forget to insert ';' to complete last expression ");
} else {
reportSyntaxError("unexpect token '" + currentTokenLexeme() + "'");
}
}
//将代码生成器的结果作为返回值返回,即返回一个Expression对象
return getCodeGeneratorWithTimes().getResult(true);
}
这段代码,主要做了两件事情:
- 调用statements()方法解析一系列语句,并将结果保存在statementType变量中。StatementType表示语句的类型,可能是三元表达式(StatementType.Ternary)或其他类型的语句。
- 将代码生成器的结果作为返回值返回,即返回一个Expression对象
statements()
我们来看下statements(),大体上是循环解析一系列Token,返回最后一个Token解析的StatementType。
具体的解析在私有的statement()方法里里,源码扒出来看下:
/**
* 根据当前标记的类型选择相应的语句处理方法,并返回相应的语句类型。
* 包括条件语句、循环语句、返回语句、异常处理语句、作用域语句、函数声明语句和三元表达式。
* 根据不同的语句类型,调用相应的处理方法,并返回对应的语句类型。如果无法匹配任何语句类型,则返回StatementType.Empty表示空语句。
* @return
*/
private StatementType statement() {
if (this.lookhead == Variable.IF) {
// 确保 if 语句的功能已启用
ensureFeatureEnabled(Feature.If);
// 解析 if 语句,并返回是否成功解析了 return 语句
if (ifStatement(false, false)) {
return StatementType.Return;
} else {
return StatementType.Other;
}
} else if (this.lookhead == Variable.FOR) {
// 确保 for 循环的功能已启用
ensureFeatureEnabled(Feature.ForLoop);
// 解析 for 循环语句
forStatement();
return StatementType.Other;
} else if (this.lookhead == Variable.RETURN) {
// 确保 return 语句的功能已启用
ensureFeatureEnabled(Feature.Return);
// 解析 return 语句
returnStatement();
return StatementType.Return;
} else if (this.lookhead == Variable.BREAK) {
// 解析 break 语句
breakStatement();
return StatementType.Return;
} else if (this.lookhead == Variable.CONTINUE) {
// 解析 continue 语句
continueStatement();
return StatementType.Return;
} else if (this.lookhead == Variable.LET) {
// 确保 let 语句的功能已启用
ensureFeatureEnabled(Feature.Let);
// 解析 let 语句
letStatement();
return StatementType.Other;
} else if (this.lookhead == Variable.WHILE) {
// 确保 while 循环的功能已启用
ensureFeatureEnabled(Feature.WhileLoop);
// 解析 while 循环语句
whileStatement();
return StatementType.Other;
} else if (this.lookhead == Variable.FN) {
// 确保 fn 语句的功能已启用
ensureFeatureEnabled(Feature.Fn);
// 解析 fn 语句
fnStatement();
return StatementType.Other;
} else if (this.lookhead == Variable.TRY) {
// 确保异常处理的功能已启用
ensureFeatureEnabled(Feature.ExceptionHandle);
// 解析 try 语句
tryStatement();
return StatementType.Other;
} else if (this.lookhead == Variable.THROW) {
// 确保异常处理的功能已启用
ensureFeatureEnabled(Feature.ExceptionHandle);
// 解析 throw 语句
throwStatement();
return StatementType.Other;
} else if (expectChar('{')) {
// 确保词法作用域的功能已启用
ensureFeatureEnabled(Feature.LexicalScope);
// 解析作用域语句,并返回是否成功解析了 return 语句
if (scopeStatement()) {
return StatementType.Return;
} else {
return StatementType.Other;
}
} else if (this.lookhead == Variable.USE) {
// 确保 use 语句的功能已启用
ensureFeatureEnabled(Feature.Use);
// 解析 use 语句
useStatement();
return StatementType.Other;
} else {
if (ternary()) {
return StatementType.Ternary;
} else {
return StatementType.Empty;
}
}
}
看到这里,老三不由感慨,原来再牛的规则引擎,底层也是一堆的if-sle。
这个方法根据当前的 Token 类型来解析不同类型的语句,并返回每个语句的类型。
ifStatement()
我们来抓住一个典型,比如代码里最常用的if,看看Aviator是怎么处理的,试着管中窥豹,分析Aviator的设计。
/**
* *用于处理条件语句(if语句):
* 接受两个布尔值参数isWhile和isElsif,用于确定当前条件语句是否是while语句或者是elsif语句。
*
* if(test) {
* ...if-body...
* }else {
* ...else-body...
* }
* ...statements...
*
*
* ===>
*
*
* __if_callcc(test ? (lambda() -> ...if-body... end)() : (lambda() -> ...else-body... end)(),
* lambda()- >
* ...statements...
* end);
*
*/
private boolean ifStatement(final boolean isWhile, final boolean isElsif) {
// 移动到下一个 Token
if (!isWhile) {
move(true);
}
// 标记 if 语句的主体和 else 语句的返回情况
boolean ifBodyHasReturn = false;
boolean elseBodyHasReturn = false;
// 设置新的词法作用域
boolean newLexicalScope = this.scope.newLexicalScope;
this.scope.newLexicalScope = true;
// 准备调用 __if_callcc(result, statements)
getCodeGeneratorWithTimes().onMethodName(Constants.IfReturnFn);
// 解析 if 语句的条件部分
{
//对三元表达式(ternary),调用相应的代码生成方法进行处理。
if (!ternary()) {
reportSyntaxError("missing test statement for if");
}
getCodeGeneratorWithTimes().onTernaryBoolean(this.lookhead);
// 解析 if 语句的主体部分
if (expectChar('{')) {
move(true);
//调用 this.scope.enterBrace() 进入一个新的花括号作用域
this.scope.enterBrace();
//调用代码生成器的 onLambdaDefineStart() 方法,表示开始定义一个 lambda 函数
getCodeGeneratorWithTimes().onLambdaDefineStart(
getPrevToken().withMeta(Constants.SCOPE_META, this.scope.newLexicalScope));
//调用代码生成器的 onLambdaBodyStart() 方法,表示 lambda 函数的主体部分开始
getCodeGeneratorWithTimes().onLambdaBodyStart(this.lookhead);
//调用 statements() 方法解析 lambda 函数的主体部分,判断主体部分的类型是否为 Return,并将结果赋值给 ifBodyHasReturn 变量
ifBodyHasReturn = statements() == StatementType.Return;
//调用代码生成器的 onLambdaBodyEnd() 方法,表示 lambda 函数的主体部分结束
getCodeGeneratorWithTimes().onLambdaBodyEnd(this.lookhead);
//调用代码生成器的 onMethodName() 方法,使用匿名方法名
getCodeGeneratorWithTimes().onMethodName(anonymousMethodName());
// 调用代码生成器的 onMethodInvoke() 方法,生成方法调用
getCodeGeneratorWithTimes().onMethodInvoke(this.lookhead);
//调用代码生成器的 onTernaryLeft() 方法,表示条件表达式的左侧部分
getCodeGeneratorWithTimes().onTernaryLeft(this.lookhead);
} else {
reportSyntaxError("expect '{' for if statement");
}
// 验证 if 语句的主体部分是否有正确的右大括号结束
if (!expectChar('}')) {
reportSyntaxError("missing '}' to close if body");
}
this.scope.leaveBrace();
move(true);
// 解析 else 语句
elseBodyHasReturn = elseStatement(isWhile, ifBodyHasReturn);
getCodeGeneratorWithTimes().onMethodParameter(this.lookhead);
}
// 处理 if 语句后面的陈述部分
{
if (isWhile || isElsif) {
// 直接加载 ReducerEmptyVal
getCodeGenerator().onConstant(Constants.ReducerEmptyVal);
} else {
if (expectChar(';')) {
// 陈述部分已结束,加载 ReducerEmptyVal
getCodeGenerator().onConstant(Constants.ReducerEmptyVal);
} else {
// 创建一个包含 if 语句后陈述部分的 lambda 函数
getCodeGeneratorWithTimes().onLambdaDefineStart(
getPrevToken().withMeta(Constants.SCOPE_META, this.scope.newLexicalScope)
.withMeta(Constants.INHERIT_ENV_META, true));
getCodeGeneratorWithTimes().onLambdaBodyStart(this.lookhead);
if (statements() == StatementType.Empty) {
// 陈述部分为空,加载 ReducerEmptyVal
getCodeGenerator().onConstant(Constants.ReducerEmptyVal);
} else {
if (ifBodyHasReturn && elseBodyHasReturn && !isElsif) {
reportSyntaxError("unreachable code");
}
}
getCodeGeneratorWithTimes().onLambdaBodyEnd(this.lookhead);
}
}
getCodeGenerator().onMethodParameter(this.lookhead);
// 调用 __if_callcc(result, statements)
getCodeGenerator().onMethodInvoke(this.lookhead);
this.scope.newLexicalScope = newLexicalScope;
}
//返回if主体和else主体是否有返回语句的布尔值
return ifBodyHasReturn && elseBodyHasReturn;
}
在这段代码开头,作者给出了注释,这个方法会对if脚本进行转换,抽象成一个lambda表达式:
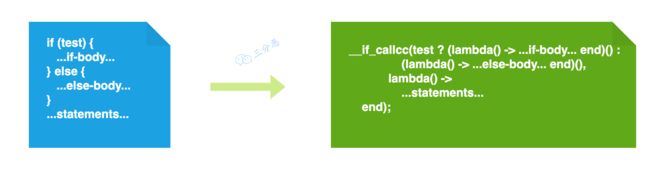
把if语句转换为使用 __if_callcc 函数的形式。转换后的代码使用了三元表达式(ternary)来选择执行 ...if-body... 或者 ...else-body...,并在转换后的代码中使用lambda函数来表示if和else的主体部分。
这段代码比较长,主要的解析过程可以分为以下几个部分:
-
解析三元表达式:通过
ternary()方法完成对三元表达式的解析和处理(解析结果放入OptimizeCodeGenerator的Token流中,后续统一生成字节码) -
解析if的主体部分:将if的方法体(ifBody)抽象为一个lambda表达式,并委托给lambdaGenerator进行解析;
-
解析else的主体部分:调用了
elseStatement(),实际的解析过程和ifBody的解析过程类似,也是委托给新构建的lambdaGenerator进行解析;
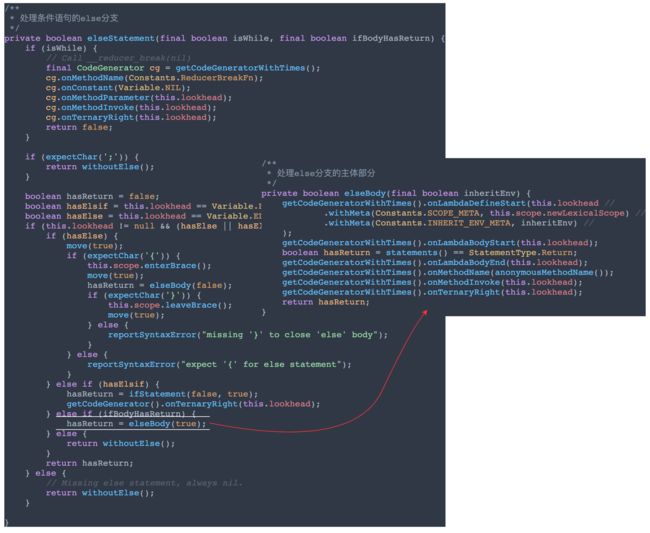
- 最后对对if语句的陈述部分解析:也可以理解成对整个代码块进行处理,抽象成一个lambda表达式,也是委托给lambdaGenerator进行解析;
接下来我们再研究一下lambda()的秘密。
LambdaGenerator
我们从这段代码开始看起:
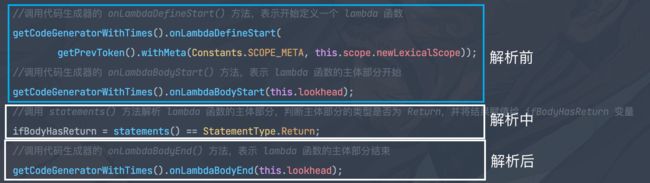
可以大体上把生成lambda脚本解析生成分为三步:
- 解析前:
onLambdaDefineStart()创建并配置一个 LambdaGenerator 实例,用于处理 lambda 函数的生成和编译过程。它还负责设置 lambda 函数的词法作用域,并确保每个 lambda 函数只能在一个作用域中定义。

-
onLambdaBodyStart(this.lookhead)调用代码生成器的onLambdaBodyStart()方法,准备开始处理lambda 函数的主体部分。它主要的作用是在处理 lambda 函数的主体部分时,将当前的代码生成器切换为 lambda 生成器。这样可以确保 lambda 函数的代码生成过程是独立的,并且符合 lambda 函数的语义和要求。
-
解析中:
- 具体的解析就不用多说了,因为还是接着调用
statements(),绕来绕去又绕回去了。
- 具体的解析就不用多说了,因为还是接着调用
-
解析后
onLambdaBodyEnd()方法里,会调用getLmabdaBootstrap构造LambdaFunctionBootstrap实例对象,并且缓存起来。
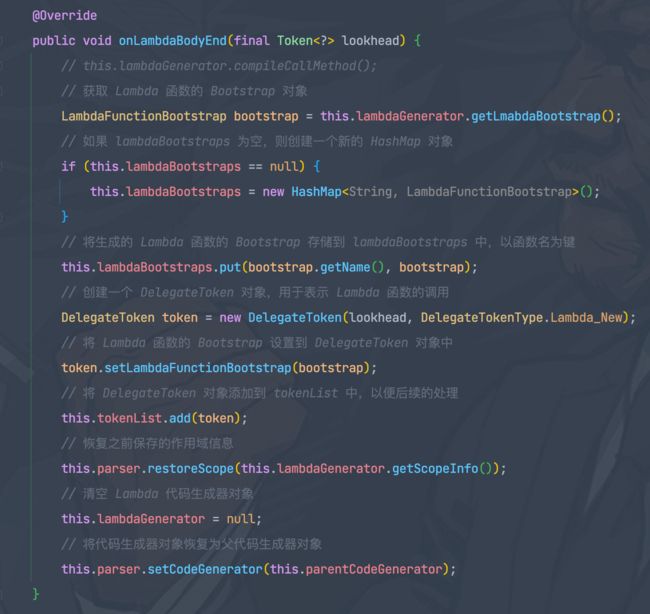
- 进一步展开
getLmabdaBootstrap(),这里把Lambda 函数的信息打包成一个 LambdaFunctionBootstrap 对象,并返回该对象。LambdaFunctionBootstrap 是一个用于表示 Lambda 函数的引导类,它包含了 Lambda 函数的类名、表达式、参数列表和是否继承环境等信息。
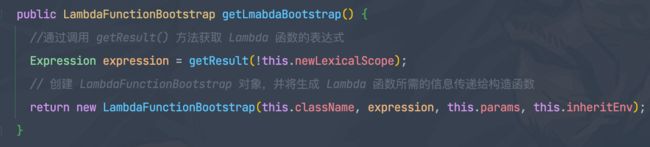
这里也可以看到调用了getResult()方法,这个方法里,会调用代码生成器,去生成字节码。
getResult()
先回顾一下parse()的代码最后一句:
//将代码生成器的结果作为返回值返回,即返回一个Expression对象
return getCodeGeneratorWithTimes().getResult(true);
Aviator脚本解析完成之后,解析结果Token流会存放到OptimizeCodeGenerator的成员变量List
OptimizeCodeGeneratord的getResult()方法具体实现如下:
/**
* 根据给定的tokenList列表生成相应的表达式对象。
* 它根据不同类型的token,对变量、方法和常量进行处理,并根据情况返回对应的表达式对象。
* 其中包括执行字面量表达式、创建变量和常量的映射集合、调用 ASM(Java字节码框架)生成字节码等操作。
* 最后返回生成的表达式对象
*/
@Override
public Expression getResult(final boolean unboxObject) {
// 执行字面量表达式
while (execute() > 0) {
;
}
// 创建变量、方法和常量的映射集合
Map<String, VariableMeta/* metadata */> variables = new LinkedHashMap<String, VariableMeta>();
Map<String, Integer/* counter */> methods = new HashMap<String, Integer>();
Set<Token<?>> constants = new HashSet<>();
// 遍历tokenList列表
for (Token<?> token : this.tokenList) {
// 如果token是常量,则将其添加到constants集合中
if (ExpressionParser.isConstant(token, this.instance)) {
constants.add(token);
}
// 根据不同的token类型进行不同的处理
switch (token.getType()) {
case Variable:
if (SymbolTable.isReservedKeyword((Variable) token)) {
continue;
}
String varName = token.getLexeme();
VariableMeta meta = variables.get(varName);
// 如果变量在variables集合中不存在,则创建新的VariableMeta对象,并将其添加到variables集合中
if (meta == null) {
meta = new VariableMeta((CompileTypes) token.getMeta(Constants.TYPE_META), varName,
token.getMeta(Constants.INIT_META, false), token.getStartIndex());
variables.put(varName, meta);
} else {
meta.add(token);
}
break;
case Delegate:
DelegateToken delegateToken = (DelegateToken) token;
// 如果是委托类型的token,则根据不同的委托类型进行不同的处理
if (delegateToken.getDelegateTokenType() == DelegateTokenType.Method_Name) {
Token<?> realToken = delegateToken.getToken();
if (realToken == null) {
continue;
}
if (realToken.getType() == TokenType.Variable) {
String methodName = token.getLexeme();
// 统计方法出现的次数,并将其添加到methods集合中
if (!methods.containsKey(methodName)) {
methods.put(methodName, 1);
} else {
methods.put(methodName, methods.get(methodName) + 1);
}
}
} else if (delegateToken.getDelegateTokenType() == DelegateTokenType.Array) {
Token<?> realToken = delegateToken.getToken();
if (realToken.getType() == TokenType.Variable) {
varName = token.getLexeme();
VariableMeta varMeta = variables.get(varName);
// 如果变量在variables集合中不存在,则创建新的VariableMeta对象,并将其添加到variables集合中
if (varMeta == null) {
varMeta =
new VariableMeta((CompileTypes) realToken.getMeta(Constants.TYPE_META), varName,
realToken.getMeta(Constants.INIT_META, false), realToken.getStartIndex());
variables.put(varName, varMeta);
} else {
varMeta.add(realToken);
}
}
}
break;
}
}
Expression exp = null;
// 如果tokenList的大小小于等于1,则根据情况返回对应的LiteralExpression对象
if (this.tokenList.size() <= 1) {
if (this.tokenList.isEmpty()) {
exp = new LiteralExpression(this.instance, null, new ArrayList<>(variables.values()));
} else {
final Token<?> lastToken = this.tokenList.get(0);
if (ExpressionParser.isLiteralToken(lastToken, this.instance)) {
exp = new LiteralExpression(this.instance,
getAviatorObjectFromToken(lastToken).getValue(getCompileEnv()),
new ArrayList<>(variables.values()));
}
}
}
if (exp == null) {
// 调用ASM生成字节码
callASM(variables, methods, constants);
// 从ASM获取结果
exp = this.codeGen.getResult(unboxObject);
}
// 对于BaseExpression对象,设置编译环境和源文件
if (exp instanceof BaseExpression) {
((BaseExpression) exp).setCompileEnv(getCompileEnv());
((BaseExpression) exp).setSourceFile(this.sourceFile);
}
return exp;
}
这里主要包含以下几部分:
-
可以前置执行的逻辑提前执行,比如文本表达式(1+2)等,先行计算出执行结果,优化执行效率
-
初始化常量集、变量集、aviator函数实例集合,为后续ASM生成类成员变量和类构造函数使用
-
调用callASM方法生成字节码,根据不同的Token类型进行不同的asm操作
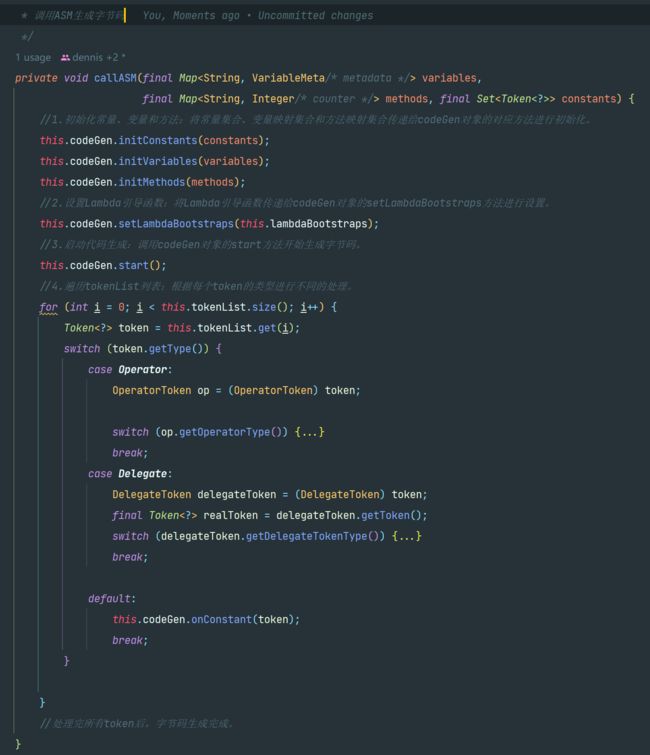
- 调用
ASMCodeGenerator的getResult()方法,结束代码生成过程,根据生成的字节码构造Expression子类实例(ClassExpression)
/*
* (non-Javadoc)
*
* @see com.googlecode.aviator.code.CodeGenerator#getResult()
* 生成并返回一个表达式(Expression)对象
*/
@Override
public Expression getResult(final boolean unboxObject) {
// 调用 end(unboxObject) 方法结束代码生成过程,并获取生成的字节码数据 byte[] bytes
end(unboxObject);
// 使用 ClassDefiner.defineClass 方法动态定义一个类,并使用生成的字节码数据作为类的定义内容。
// 这里定义的类是继承自 Expression 的类。返回的是一个 Class 类型的对象,表示定义的类
byte[] bytes = this.classWriter.toByteArray();
// 这里额外加了一段代码:将字节码保存到文件
try (OutputStream outputStream = new FileOutputStream("classes/" + this.className + ".class")) {
outputStream.write(bytes);
} catch (IOException e) {
e.printStackTrace();
}
try {
// 从定义的类中获取构造函数 Constructor constructor,
// 该构造函数接受三个参数:AviatorEvaluatorInstance 实例、List 类型的列表,以及 SymbolTable 实例
Class<?> defineClass = ClassDefiner.defineClass(this.className, Expression.class, bytes, this.classLoader);
Constructor<?> constructor = defineClass.getConstructor(AviatorEvaluatorInstance.class, List.class, SymbolTable.class);
// 使用构造函数创建一个实例 BaseExpression exp,并通过反射调用构造函数的 newInstance 方法进行实例化。
// 传递的参数包括 this.instance、new ArrayList(this.variables.values()) 和 this.symbolTable
BaseExpression exp = (BaseExpression) constructor.newInstance(this.instance, new ArrayList<VariableMeta>(this.variables.values()), this.symbolTable);
// 设置生成的表达式对象 exp 的一些属性,包括 lambda 表达式的引导、函数参数、源文件等
exp.setLambdaBootstraps(this.lambdaBootstraps);
exp.setFuncsArgs(this.funcsArgs);
exp.setSourceFile(this.sourceFile);
// 最后,返回生成的表达式对象 exp
return exp;
} catch (ExpressionRuntimeException e) {
throw e;
} catch (Throwable e) {
if (e.getCause() instanceof ExpressionRuntimeException) {
throw (ExpressionRuntimeException) e.getCause();
}
throw new CompileExpressionErrorException("define class error", e);
}
}
注意看,我在源码添加了一段代码,把二进制的流保存到文件里,方便我们接下来查看ASM生成的字节码。
字节码文件解析
在项目的根目录下创建一个文件夹classes,运行测试代码,我们会看到一堆的.class文件,这就是生成的字节码文件。
如果没有保存的话,这些字节码文件都会以流的形式保存在内存中,所以说为什么使用Aviator的时候要开启缓存。
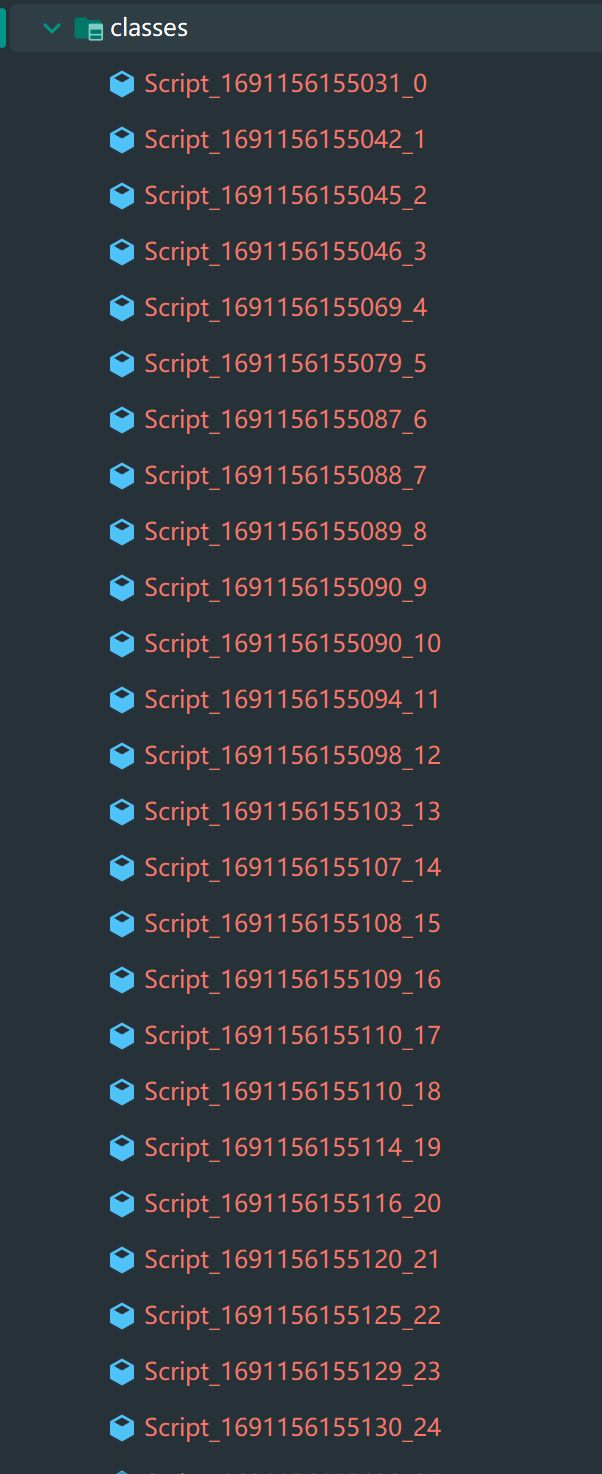
我们来看看这个例子里的脚本生成的字节码文件。
if (a > 1) {
return b + 2;
} else {
return c;
}
通过在ifStatement()方法和getResult()方法的断点调试,
- if主体生成的字节码文件
public class Script_1691416070302_59 extends ClassExpression {
private final AviatorObject f0;
private final AviatorJavaType f1;
private final AviatorFunction f2;
public Script_1691416070302_59(AviatorEvaluatorInstance var1, List var2, SymbolTable var3) {
super(var1, var2, var3);
this.f1 = new AviatorJavaType("b", var3);
this.f2 = var1.getFunction("__reducer_return", var3);
this.f0 = AviatorLong.valueOf(2L);
}
public final Object execute0(Env var1) {
return RuntimeUtils.assertNotNull(this.f2.call(var1, this.f1.add(this.f0, var1))).deref(var1);
}
}
- else主体生成的字节码文件
public class Script_1691416071434_60 extends ClassExpression {
private final AviatorJavaType f0;
private final AviatorFunction f1;
public Script_1691416071434_60(AviatorEvaluatorInstance var1, List var2, SymbolTable var3) {
super(var1, var2, var3);
this.f0 = new AviatorJavaType("c", var3);
this.f1 = var1.getFunction("__reducer_return", var3);
}
public final Object execute0(Env var1) {
return RuntimeUtils.assertNotNull(this.f1.call(var1, this.f0)).deref(var1);
}
}
- if语句后面的语句生成的字节码
public class Script_1691156155220_61 extends ClassExpression {
private final AviatorJavaType f0;
public Script_1691156155220_61(AviatorEvaluatorInstance var1, List var2, SymbolTable var3) {
super(var1, var2, var3);
this.f0 = new AviatorJavaType("__reducer_empty", var3);
}
public final Object execute0(Env var1) {
return this.f0.deref(var1);
}
}
- 整个if脚本生成的字节码
public class Script_1691416070302_58 extends ClassExpression {
private final AviatorObject f0;
private final AviatorJavaType f1;
private final AviatorFunction f2;
public Script_1691416070302_58(AviatorEvaluatorInstance var1, List var2, SymbolTable var3) {
super(var1, var2, var3);
this.f1 = new AviatorJavaType("a", var3);
this.f2 = var1.getFunction("__if_callcc", var3);
this.f0 = AviatorLong.valueOf(1L);
}
public final Object execute0(Env var1) {
return RuntimeUtils.assertNotNull(this.f2.call(var1, (this.f1.compare(this.f0, var1) > 0 ? AviatorBoolean.TRUE : AviatorBoolean.FALSE).booleanValue(var1) ? RuntimeUtils.assertNotNull(RuntimeUtils.getFunction(this.newLambda(var1, "Lambda_1691416070302_57"), var1).call(var1)) : RuntimeUtils.assertNotNull(RuntimeUtils.getFunction(this.newLambda(var1, "Lambda_1691416071434_58"), var1).call(var1)), this.newLambda(var1, "Lambda_1691416078763_59"))).getValue(var1);
}
}
执行execute()
我们接下来看看规则脚本是怎么执行的,执行就简单很多了,简单说,就是利用生成的字节码,在运行时对变量进行赋值,并按照预期的逻辑执行计算。
/**
* 执行脚本方法
*/
@Override
public Object execute(Map<String, Object> map) {
// 检查传入的参数 map 是否为空,如果为空则使用空的不可变映射作为默认值
if (map == null) {
map = Collections.emptyMap();
}
// 生成顶层环境(Env)对象
Env env = genTopEnv(map);
// 获取环境处理器(EnvProcessor)实例
EnvProcessor envProcessor = this.instance.getEnvProcessor();
// 如果环境处理器存在,则在执行之前调用 beforeExecute 方法
if (envProcessor != null) {
envProcessor.beforeExecute(env, this);
}
try {
// 直接执行表达式,传入生成的环境对象
return executeDirectly(env);
} finally {
// 如果环境处理器存在,则在执行之后调用 afterExecute 方法
if (envProcessor != null) {
envProcessor.afterExecute(env, this);
}
}
}
这里包含了EnvProcessor前置拦截和后置拦截器,下面主要分析下executeDirectly方法具体执行过程:
@Override
public Object executeDirectly(final Map<String, Object> env) {
try {
// 调用 execute0 方法执行表达式,将 env 强制转换为 Env 类型
Object result = execute0((Env) env);
// 如果 env 中设置了跟踪标志,打印结果到跟踪输出流
if (RuntimeUtils.isTracedEval(env)) {
RuntimeUtils.printlnTrace(env, "Result : " + result);
}
// 返回执行结果
return result;
} catch (ExpressionRuntimeException e) {
// 如果捕获到 ExpressionRuntimeException 异常,直接抛出
throw e;
} catch (Throwable t) {
// 将捕获到的 Throwable 异常使用 Reflector.sneakyThrow 方法抛出(用于避免编译时类型检查)
throw Reflector.sneakyThrow(t);
}
}
ClassExpression的方法executeDirectly中又调用了execute0进行执行,来获取最终的结果:
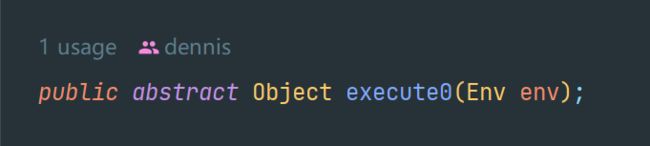
注意看execute0是个抽象方法,没有具体的实现,它的具体实现,就是我们上面通过ASM技术生成的对应的字节码的成员方法
针对上述的if脚本示例,生成的ClassExpression子类和实现的execute0方法如下:
public class Script_1691416070302_58 extends ClassExpression {
private final AviatorObject f0;
private final AviatorJavaType f1;
private final AviatorFunction f2;
public Script_1691416070302_58(AviatorEvaluatorInstance var1, List var2, SymbolTable var3) {
super(var1, var2, var3);
this.f1 = new AviatorJavaType("a", var3);
this.f2 = var1.getFunction("__if_callcc", var3);
this.f0 = AviatorLong.valueOf(1L);
}
public final Object execute0(Env var1) {
return RuntimeUtils.assertNotNull(this.f2.call(var1, (this.f1.compare(this.f0, var1) > 0
? AviatorBoolean.TRUE : AviatorBoolean.FALSE).booleanValue(var1)
? RuntimeUtils.assertNotNull(RuntimeUtils.getFunction(
this.newLambda(var1, "Lambda_1691416070302_57"), var1).call(var1)) :
RuntimeUtils.assertNotNull(RuntimeUtils.getFunction(
this.newLambda(var1, "Lambda_1691416071434_58"), var1).call(var1)),
this.newLambda(var1, "Lambda_1691416078763_59"))).getValue(var1);
}
}
这样,execute0通过传入env实参,执行的方法体即完整实现了if示例脚本的内容,最终产出if脚本计算结果。
其中在执行到某个具体if分支时,会调用newLambda函数:
public LambdaFunction newLambda(final Env env, final String name) {
LambdaFunctionBootstrap bootstrap = this.lambdaBootstraps.get(name);
if (bootstrap == null) {
throw new ExpressionNotFoundException("Lambda " + name + " not found");
}
return bootstrap.newInstance(env);
}
newLambda函数中会调用缓存的lambdaBootstraps,获取对应的LambdaFunctionBootstrap,然后通过newInstance方法创建对应的LambdaFunction,如下:
/**
* 创建一个 Lambda 函数的新实例。
*
* @param env Lambda 函数的执行环境
* @return LambdaFunction 实例
*/
public LambdaFunction newInstance(final Env env) {
Reference<LambdaFunction> ref = null;
// 如果函数启用继承环境且在本地缓存中存在引用,则从缓存中获取函数实例并设置新的执行环境
if (this.inheritEnv && (ref = this.fnLocal.get()) != null) {
LambdaFunction fn = ref.get();
if (fn != null) {
fn.setContext(env);
return fn;
} else {
this.fnLocal.remove();
}
}
// 创建一个新的 LambdaFunction 实例,并设置名称、参数、表达式和执行环境
LambdaFunction fn = new LambdaFunction(this.name, this.params, this.expression, env);
fn.setInheritEnv(this.inheritEnv);
// 如果函数启用继承环境,则将新实例的软引用存储到本地缓存中
if (this.inheritEnv) {
this.fnLocal.set(new SoftReference<>(fn));
}
return fn;
}
后面继续调用LambdaFunction的call函数:
@Override
public AviatorObject call(final Map<String, Object> env) {
try {
if (this.isVariadic && !this.installed) {
return variadicCall(env, true);
}
return AviatorRuntimeJavaType.valueOf(this.expression.executeDirectly(newEnv(env)));
} finally {
if (this.inheritEnv) {
this.context = null;
}
}
}
call方法体中,又进一步调用了lambda脚本通过ASM生成的expression,进而执行了对应分支的逻辑,至此,最终产出计算结果。
总结
这篇文章,我们跟着一个简单的Aviator脚本的例子,一步步深入挖掘了一下Aviator的实现原理。
Aviator的实现大体上可以分为两大步:
- 一:编译:经历词法分析、表达式解析、字节码生成,最终产出可以执行的Java字节码
- 二:执行:执行相对简单一些,就是调用生成的字节码的过程。
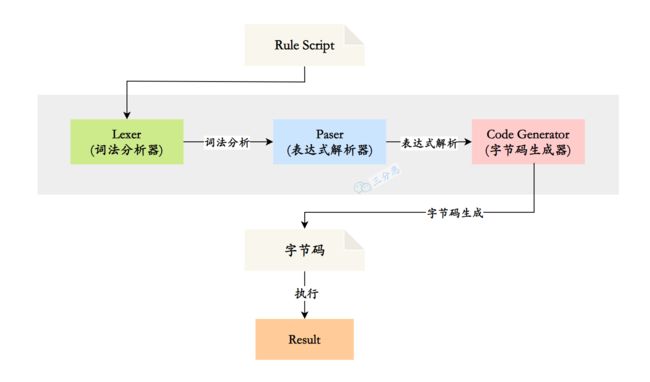
当然,这篇文章只是梳理了大体的脉络,对于很多细节都没有深入地去探究,只是做到了观其大略。
我觉得对于一个开源项目,真正说地上熟悉原理的话,就得看能不能给开源项目提交PR。Aviator是一个非常好用的规则脚本,希望有一天能在PR看到各位或者我自己的身影:https://github.com/killme2008/aviatorscript/pulls?q=is%3Apr+is%3Aclosed
参考:
[1].https://blog.csdn.net/supzhili/article/details/131224578
[2].https://www.yuque.com/boyan-avfmj/aviatorscript/cpow90
[3].https://bugstack.cn/md/bytecode/asm/2020-03-25-%5BASM%E5%AD%97%E8%8A%82%E7%A0%81%E7%BC%96%E7%A8%8B%5D%E5%A6%82%E6%9E%9C%E4%BD%A0%E5%8F%AA%E5%86%99CRUD%EF%BC%8C%E9%82%A3%E8%BF%99%E7%A7%8D%E6%8A%80%E6%9C%AF%E4%BD%A0%E6%B0%B8%E8%BF%9C%E7%A2%B0%E4%B8%8D%E5%88%B0.html