HashMap的底层存储结构和实现原理
文章目录
- 前言
- 一、HashMap是什么?
- 二、 数组
- 三、 链表
- 四、哈希算法
- 五、哈希冲突
- 总结
前言
HashMap实现了Map接口,我们常用来put/get操作读存键值对数据,比较典型的key-value结构,那么本文将详细分析此数据结构的底层原理及实现,包括底层存储原理,哈希算法,哈希冲突,源码等等。
一、HashMap是什么?
HashMap实际上是一种数组+链表(jdk1.8后加入红黑树)的一种数据结构,在put操作中通过内部定义的算法(哈希算法)找到数组的下标,将数组放在此数组元素中,如果该数组元素已经有了元素(hash冲突),将会把这个数组元素上的链表进行遍历,放在此链表的末尾,内部有next code下一步节点,根据这个来定义位置。
二、 数组
简单的说:数组就是采用一段连续的存储单元来存储数据。 特点:查询快O(1),删除插入慢O(N)
查询快:因为数组是有自增的下标(索引),查询的时候可以依据索引直接定位到要查询的数据,因此从查询的角度来说效率更高。
删除插入慢:因为:当插入或者删除数据的时候,其他的数据会重新计算下标,重新移位,时间复杂度就是O(N),假设有一个大小为10的数组,当要在下标4~5之间插入数据时,新数据的下标就为6,而原本为6的数据下标则为7,以此类推在6后面的所有数据都要重新移位,计算下标,除非插入和删除的是最后一个数据。
自己画的一个潦草的图
实际上ArrayList底层就是一个数组实现。
private static final long serialVersionUID = 8683452581122892189L;
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = new Object[0];
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = new Object[0];
transient Object[] elementData; // 数组
private int size;
private static final int MAX_ARRAY_SIZE = 2147483639;
/** arraylist的add方法 **/
public boolean add(E var1) {
this.ensureCapacityInternal(this.size + 1);
this.elementData[this.size++] = var1;
return true;
}
上面代码是jdk1.8的源码,可以看到“elementData”实际上就是一个数组,所以arrayList的底层实现实际上也是一个数组,也具有查询快,删除插入慢的特性。
三、 链表
是一种根据元素节点逻辑关系排列的一种数据结构,可以保存多个数据,有点像数组的概念,但是数组有个一个缺点——数组的长度 是固定的,不可改变,在长度固定的情况下首选肯定是数组,但是在开发中有时候保存的内容长度是不确定的,这个时候就能用链表来代替数组使用。
/** 每一个链表实际上就是多个节点 **/
class Node {
/** 保存数据 **/
private String data;
/** 保存下一个节点 **/
private Node nextCode;
/** 每一个Node都必须保存有数据 **/
public Node(String data){
this.data = data ;
}
public void setNextCode(Node nextCode){
this.nextCode = nextCode ;
}
public Node getNextCode(){
return this.nextCode ;
}
public String getData(){
return this.data ;
}
}
public class LinkedList {
public static void main(String[] args) {
/** 1.准备数据 **/
Node root = new Node("飞机头") ;
Node n1 = new Node("机厢A") ;
Node n2 = new Node("机厢B") ;
/** 链接节点 **/
root.setNextCode(n1);
n1.setNextCode(n2);
/** 2.取出数据 **/
Node currentNode = root ; //从当前根节点开始
while( currentNode != null){
System.out.println(currentNode.getData()) ;
/** 将下一个节点设置为当前节点 **/
currentNode = currentNode.getNextCode() ;
}
}
}
四、哈希算法
哈希算法是HashMap的底层实现原理里面很重要的一个组成部分,它来决定数据的位置及访问记录,哈希算法也叫散列算法,把我们存在map中的key(任意长度的值)通过此算法变成固定长度的key(地址),通过这个地址访问数据。
通过一张图,我们可以简单看一下
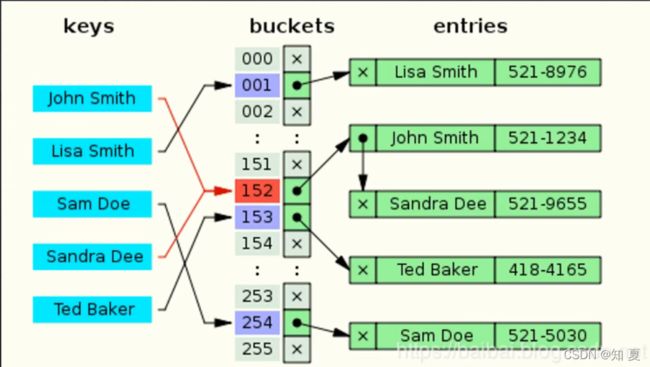
上图主要展示的就是我们存储一个任意长度的key,通过算法转换为一个固定地址。
实际上,hashCode是通过字符串算出它的ascii码,然后进行取模,得到哈希表的下标。
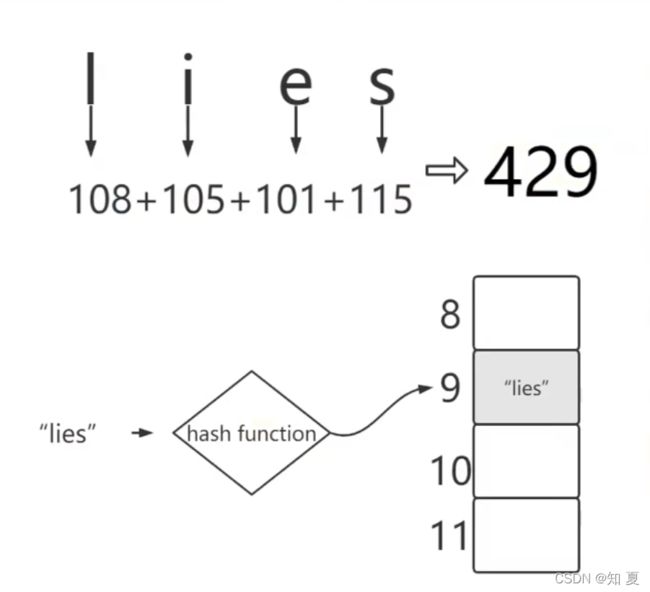
借用上面这张图,我们可以看到“lies”是存储到map里面的key,那么它是由4个字母组成,这4个字母分别的ascii码是l=108 i=105 e=101 s=115,相加等于429,那么这个429就是可以理解为lies的标识,然后通过hsah function(取模)得到哈希表的下标为9,把这个数据存储到下标为9的里面。
之所以要去hash function,主要是为了节省空间,这个也跟上面我所说到的数组的特性有关,假设lies的标识为429,那么数组是有固定长度的,不可能把数组扩容到429,那么这个时候就用到取模。
那么这个时候问题来了!!!敲黑板!!!
取模是为了节省空间,也是为了计算出在哈希表的下标,那么如果相同的ascii值去取模,得到的下标就是相同的,那么一个下标怎么存储两个数据呢?这个就叫哈希冲突(哈希碰撞)
五、哈希冲突
话不多说,先来张图简单看下
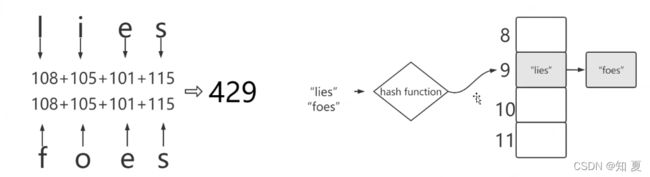
借用上面这张图,我们可以大概了解到哈希冲突的意思,“lies”与“foes”的ascii码都是429,那么相同的ascii码去取模,得到的哈希表下标都是9,这个时候就出现了哈希冲突。
那么出现哈希冲突后,不代表不能存储值或者覆盖原先的值,这个时候我们就用到了上面说的链表引入,因为链表是具有下一步指针特性的,当出现哈希冲突的时候,底层特性会将“lies”的下一步节点指向“foes”,那么也就是说在下标为9的结构里面,存储了lies,但是因为链表特性,lies的下一步节点指向了foes,
public static void main(String[] args) {
TestEs map = new TestEs();
map.put("A", "A");
map.put("B", "B");
map.put("C", "C");
map.put("D", "D");
map.put("E", "E");
}
public void put(String key, String value) {
logger.info("key={},hash值={},存储位置={}", key, key.hashCode(), Math.abs(key.hashCode() % 15));
}
put - key=A,hash值=65,存储位置=5
put - key=B,hash值=66,存储位置=6
put - key=C,hash值=67,存储位置=7
put - key=D,hash值=68,存储位置=8
put - key=E,hash值=69,存储位置=9
上述代码是我写的一个小例子,我进行取模取的是15,通过这个例子可以看到不管运行几次,hash值是不会变的;这也是hash算法的一个特点,是具有幂等性的。
这个时候HashMap的基本组成我想应该有个大概的了解了,那么我们使用PUT操作时,究竟是怎么一步步将值存储的呢?又是怎么样的流程呢?这个时候就要解析源码了。
JDK的源码我就不一一截图了,我仿造着源码自己写了套HashMap的实现,并把自己的理解都标注了注释。
首先定义一个Map接口
这个接口我会定义put/get方法 以及存储的接口
package com.company;
public interface Map<K, V> {
V put(K k, V v);
V get(K k);
int size();
interface Entry<K, V> {
K getKey();
V getValue();
}
}
创建一个实体类,实现定义的Map接口
package com.company;
public class HashMap<K, V> implements Map<K, V> {
private Entry<K, V> table[] = null;
int size = 0;
public HashMap() {
this.table = new Entry[16];
}
/**
* step1:通过key 使用hash算法得到hashCode值
* step2:通过hash值取模得到index下标,找到此下标对应的对象
* step3:判断当前对象是否为空 为空 可以直接存储
* step4:不为空 说明出现了hash冲突 用到next链表特性
* step5:返回当前节点对象
*
* @param k
* @param v
* @return
*/
public V put(K k, V v) {
/* 通过hash算法 得到要存储数组的下标 */
int index = hash(k);
/* 以此下标 获取数组中的对象 */
Entry<K, V> entry = table[index];
/* 为空 则证明可以直接进行存储 */
if (null == entry) {
table[index] = new Entry(k, v, index, null);
size++;
}
/* 不为空,发生了冲突,使用链表 */
else {
table[index] = new Entry(k, v, index, entry);
}
return table[index].getValue();
}
/**
* 这个就是我自己定义hash算法的方法
* 这个比较简单,真实的源码会有一些移位的操作
* 主要涉及到性能和计算机底层原理的一些东西 这个我还不懂
*
* @param k
* @return
*/
private int hash(K k) {
int index = k.hashCode() % 16;
return index >= 0 ? index : -index;
}
/**
* 通过key 进行hash得到 index
* 通过index下标获取数组对象
* 判断当前对象是否为空 如果不为空
* 判断是否相等 如果不相等
* 判断next节点是否为空 如果不为空
* 判断是否相等 直到相等或者为空。
* 返回。
*
* @param k
* @return
*/
public V get(K k) {
if (0 == size) {
return null;
}
int index = hash(k);
/* 以此下标 获取数组中的对象 */
Entry<K, V> entry = findValue(table[index], k);
return null == entry ? null : entry.getValue();
}
/**
* 采取递归来完成get的步骤
*
* @param entry
* @param k
* @return
*/
private Entry<K, V> findValue(Entry<K, V> entry, K k) {
if (k.equals(entry.getKey()) || k == entry.getKey()) {
return entry;
} else {
if (null != entry.next) {
return findValue(entry.next, k);
}
}
return null;
}
public int size() {
return size;
}
class Entry<K, V> implements Map.Entry<K, V> {
K k;
V v;
int hash;
Entry<K, V> next;
public Entry(K k, V v, int hash, Entry<K, V> next) {
this.k = k;
this.v = v;
this.hash = hash;
this.next = next;
}
public K getKey() {
return k;
}
public V getValue() {
return v;
}
}
}
测试
package com.company;
public class TestMap {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("知夏", "这是一篇技术分享的文章");
map.put("爱吃饭的侯", "小侯爱吃饭");
System.out.println(map.get("知夏"));
System.out.println(map.get("爱吃饭的侯"));
}
}
这是参照源码简单写的一个map实现,代码解释,实现原理都写成了注释,实际的源码比这个发杂的多的多,但是这个例子依然是map的实现逻辑,当然这个例子没有实现红黑树。
这里顺便提一下红黑树,简单的说 当数组的容量固定的时候,如果存储的数据超过了数组的固定容量,那么就会出现巨大的哈希冲突,这个时候会使用链表特性,会纵向的无限延申数据,上面我也记录了链表的特性,插入快,查询慢,如果出现了这种情况 对性能和查询是非常不利的,这就是为什么要推出红黑树,红黑树准备再开一篇文章单独记录。
总结
写到这里,我们知道了HashMap的结构和底层实现,我们知道它是一种以数组+链表+红黑树为组合的key-value存储的数据结构,它是我们开发中使用率很高的一个朋友,它的底层涵盖了哈希算法,如何解决哈希冲突,如何解决链表无限延申,对数据和结构进行了重新定义,以前呢,我没有想过要去深入了解它,会用就行了,趁着疫情封控在家,花时间整理一下,顺带记录下来,回头忘了可以过来重温下。