yolo-nas对自定义数据集进行训练,测试详解 & 香烟数据集
yolov5格式的香烟数据集
https://download.csdn.net/download/qq_42864343/88110620?spm=1001.2014.3001.5503
创建yolo-nas的运行环境
进入Pycharm的terminal,输入如下命令
conda create -n yolonas python=3.8
pip install super-gradients
使用自定义数据训练Yolo-nas
准备数据
在YOLO-NAS根目录下创建mydata文件夹(名字可以自定义),目录结构如下:
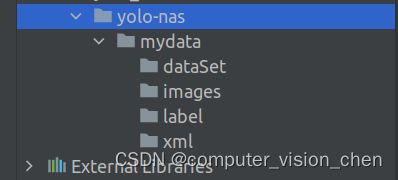
将自己数据集里用labelImg标注好的xml文件放到xml目录
图片放到images目录
划分数据集
把划分数据集代码 split_train_val.py放到yolo-nas目录下:
# coding:utf-8
import os
import random
import argparse
# 通过argparse模块创建一个参数解析器。该参数解析器可以接收用户输入的命令行参数,用于指定xml文件的路径和输出txt文件的路径。
parser = argparse.ArgumentParser()
# 指定xml文件的路径
parser.add_argument('--xml_path', default='mydata/xml', type=str, help='input xml label path')
# 设置输出txt文件的路径
parser.add_argument('--txt_path', default='mydata/dataSet', type=str, help='output txt label path')
opt = parser.parse_args()
# 训练集与验证集 占全体数据的比例
trainval_percent = 1.0
# 训练集 占训练集与验证集总体 的比例
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
# 获取到xml文件的数量
total_xml = os.listdir(xmlfilepath)
# 判断txtsavepath是否存在,若不存在,则创建该路径。
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
# 统计xml文件的个数,即Image标签的个数
num = len(total_xml)
list_index = range(num)
# tv (训练集和测试集的个数) = 数据总数 * 训练集和数据集占全体数据的比例
tv = int(num * trainval_percent)
# 训练集的个数
tr = int(tv * train_percent)
# 按数量随机得到取训练集和测试集的索引
trainval = random.sample(list_index, tv)
# 打乱训练集
train = random.sample(trainval, tr)
# 创建存放所有图片数据路径的文件
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
# 创建存放所有测试图片数据的路径的文件
file_test = open(txtsavepath + '/test.txt', 'w')
# 创建存放所有训练图片数据的路径的文件
file_train = open(txtsavepath + '/train.txt', 'w')
# 创建存放所有测试图片数据的路径的文件
file_val = open(txtsavepath + '/val.txt', 'w')
# 遍历list_index列表,将文件名按照划分规则写入相应的txt文件中
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
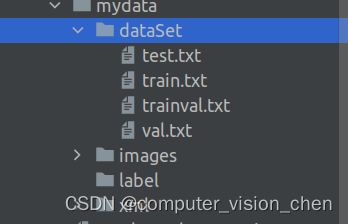
运行代码:
dataSet中出现四个文件,里面是图片的名字
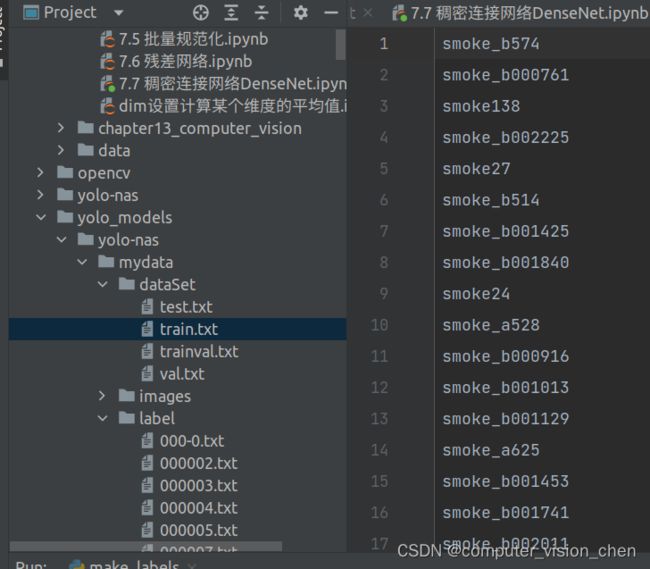
根据xml标注文件制作适合yolo的标签
即将每个xml标注提取bbox信息为txt格式,每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height。
创建make_labes.py,复制如下代码运行:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ['smoke'] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('mydata/xml/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('mydata/label/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('mydata/label/'):
os.makedirs('mydata/label/')
image_ids = open('mydata/dataSet/%s.txt' % (image_set)).read().strip().split()
list_file = open('mydata/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/mydata/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
运行完成:
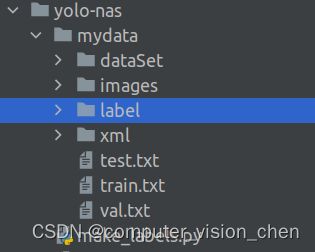
label目录下出现了图片对应的标记位置(好像是标记框左上角和由上角的坐标)与类别
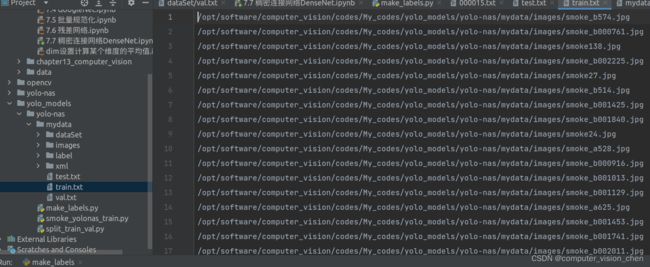
mydata目录下,出现了训练集train.txt,测试集test.txt,里面是对应的图片路径
将划分好的数据集转成适合yolo-nas要求的数据集
创建data目录
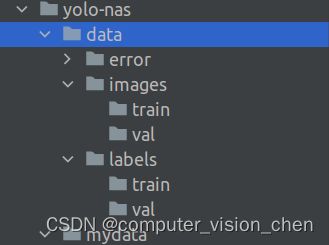
error目录: 存放格式有问题的图片,格式有问题的图片会中断训练
images/train目录:存放训练集图片
images/val目录:存放测试集图片
labels/train目录:存放训练集图片的标签
labels/val目录:存放测试集图片的标签
训练代码
import os
import requests
import torch
from PIL import Image
from super_gradients.training import Trainer, dataloaders, models
from super_gradients.training.dataloaders.dataloaders import (
coco_detection_yolo_format_train, coco_detection_yolo_format_val
)
from super_gradients.training.losses import PPYoloELoss
from super_gradients.training.metrics import DetectionMetrics_050
from super_gradients.training.models.detection_models.pp_yolo_e import (
PPYoloEPostPredictionCallback
)
class config:
# trainer params
CHECKPOINT_DIR = 'checkpoints' # specify the path you want to save checkpoints to
EXPERIMENT_NAME = 'cars-from-above' # specify the experiment name
# dataset params
DATA_DIR = 'data' # parent directory to where data lives
TRAIN_IMAGES_DIR = 'images/train' # child dir of DATA_DIR where train images are
TRAIN_LABELS_DIR = 'labels/train' # child dir of DATA_DIR where train labels are
VAL_IMAGES_DIR = 'images/val' # child dir of DATA_DIR where validation images are
VAL_LABELS_DIR = 'labels/val' # child dir of DATA_DIR where validation labels are
# TEST_IMAGES_DIR = 'images/test' # child dir of DATA_DIR where validation images are
# TEST_LABELS_DIR = 'labels/test' # child dir of DATA_DIR where validation labels are
CLASSES = ['smoke'] # 指定类名
NUM_CLASSES = len(CLASSES) # 获取类个数
# dataloader params - you can add whatever PyTorch dataloader params you have
# could be different across train, val, and test
DATALOADER_PARAMS = {
'batch_size': 16,
'num_workers': 2
}
# model params
MODEL_NAME = 'yolo_nas_l' # 可以选择 yolo_nas_s, yolo_nas_m, yolo_nas_l。分别是 小型,中型,大型
PRETRAINED_WEIGHTS = 'coco' # only one option here: coco
trainer = Trainer(experiment_name=config.EXPERIMENT_NAME, ckpt_root_dir=config.CHECKPOINT_DIR)
# 指定训练数据
train_data = coco_detection_yolo_format_train(
dataset_params={
'data_dir': config.DATA_DIR,
'images_dir': config.TRAIN_IMAGES_DIR,
'labels_dir': config.TRAIN_LABELS_DIR,
'classes': config.CLASSES
},
dataloader_params=config.DATALOADER_PARAMS
)
# 指定评估数据
val_data = coco_detection_yolo_format_val(
dataset_params={
'data_dir': config.DATA_DIR,
'images_dir': config.VAL_IMAGES_DIR,
'labels_dir': config.VAL_LABELS_DIR,
'classes': config.CLASSES
},
dataloader_params=config.DATALOADER_PARAMS
)
# test_data = coco_detection_yolo_format_val(
# dataset_params={
# 'data_dir': config.DATA_DIR,
# 'images_dir': config.TEST_IMAGES_DIR,
# 'labels_dir': config.TEST_LABELS_DIR,
# 'classes': config.CLASSES
# },
#
dataloader_params=config.DATALOADER_PARAMS
# )
# train_data.dataset.plot()
model = models.get(config.MODEL_NAME,
num_classes=config.NUM_CLASSES,
pretrained_weights=config.PRETRAINED_WEIGHTS
)
train_params = {
# ENABLING SILENT MODE
"average_best_models":True,
"warmup_mode": "linear_epoch_step",
"warmup_initial_lr": 1e-6,
"lr_warmup_epochs": 3,
"initial_lr": 5e-4,
"lr_mode": "cosine",
"cosine_final_lr_ratio": 0.1,
"optimizer": "Adam",
"optimizer_params": {"weight_decay": 0.0001},
"zero_weight_decay_on_bias_and_bn": True,
"ema": True,
"ema_params": {"decay": 0.9, "decay_type": "threshold"},
# ONLY TRAINING FOR 10 EPOCHS FOR THIS EXAMPLE NOTEBOOK
"max_epochs": 200,
"mixed_precision": True,
"loss": PPYoloELoss(
use_static_assigner=False,
# NOTE: num_classes needs to be defined here
num_classes=config.NUM_CLASSES,
reg_max=16
),
"valid_metrics_list": [
DetectionMetrics_050(
score_thres=0.1,
top_k_predictions=300,
# NOTE: num_classes needs to be defined here
num_cls=config.NUM_CLASSES,
normalize_targets=True,
post_prediction_callback=PPYoloEPostPredictionCallback(
score_threshold=0.01,
nms_top_k=1000,
max_predictions=300,
nms_threshold=0.7
)
)
],
"metric_to_watch": '[email protected]'
}
trainer.train(model=model,
training_params=train_params,
train_loader=train_data,
valid_loader=val_data)
best_model = models.get(config.MODEL_NAME,
num_classes=config.NUM_CLASSES,
checkpoint_path=os.path.join(config.CHECKPOINT_DIR, config.EXPERIMENT_NAME, 'average_model.pth'))
连接网络摄像头用训练好的模型参数进行预测
import torch
from super_gradients.training import models
import cv2
import time
def get_video_capture(video, width=None, height=None, fps=None):
"""
获得视频读取对象
-- 7W Pix--> width=320,height=240
-- 30W Pix--> width=640,height=480
720P,100W Pix--> width=1280,height=720
960P,130W Pix--> width=1280,height=1024
1080P,200W Pix--> width=1920,height=1080
:param video: video file or Camera ID
:param width: 图像分辨率width
:param height: 图像分辨率height
:param fps: 设置视频播放帧率
:return:
"""
video_cap = cv2.VideoCapture(video)
# 如果指定了宽度,高度,fps,则按照制定的值来设置,此处并没有指定
if width:
video_cap.set(cv2.CAP_PROP_FRAME_WIDTH, width)
if height:
video_cap.set(cv2.CAP_PROP_FRAME_HEIGHT, height)
if fps:
video_cap.set(cv2.CAP_PROP_FPS, fps)
return video_cap
# 此处连接网络摄像头进行测试
video_file = 'rtsp://账号:密码@ip/Streaming/Channels/1'
# video_file = 'data/output.mp4'
num_classes = 1
# best_pth = '/home/computer_vision/code/my_code/checkpoints/cars-from-above/ckpt_best.pth'
best_pth = 'checkpoints/cars-from-above/smoke_small_ckpt_best.pth'
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
best_model = models.get("yolo_nas_s", num_classes=num_classes, checkpoint_path=best_pth).to(device)
'''开始计时'''
start_time = time.time()
video_cap = get_video_capture(video_file)
while True:
isSuccess, frame = video_cap.read()
if not isSuccess:
break
result_image = best_model.predict(frame, conf=0.45, fuse_model=False)
result_image = result_image._images_prediction_lst[0]
result_image = result_image.draw()
'''改动'''
result_image = cv2.resize(result_image, (960, 540))
'''end'''
cv2.namedWindow('result', flags=cv2.WINDOW_NORMAL)
cv2.imshow('result', result_image)
kk = cv2.waitKey(1)
if kk == ord('q'):
break
video_cap.release()
'''时间结束'''
end_time = time.time()
run_time = end_time - start_time
print(run_time)
补充
对视频进行预测
import torch
from super_gradients.training import models
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
model = models.get("yolo_nas_l", pretrained_weights="coco").to(device)
model.predict("data/output.mp4",conf=0.4).save("output/output_lianzhang.mp4")
对图片进行预测
import torch
from super_gradients.training import models
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
model = models.get("yolo_nas_s", pretrained_weights="coco").to(device)
out = model.predict("camera01.png", conf=0.6)
out.show()
out.save("output")
预测data目录下的视频并保存预测结果
model.predict("data/output.mp4").save("output/output_lianzhang.mp4")