%matplotlib inline
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
import time
'''
使用CIFAR-10数据集,而不是我们之前使用的Fashion-MNIST数据集。这是因为Fashion-MNIST数据集中对象的位置和大小已被规范化,而CIFAR-10数据集中对象的颜色和大小差异更明显。CIFAR-10数据集中的前32个训练图像如下所示。
'''
all_images = torchvision.datasets.CIFAR10(train=True, root="../data",download=True)
d2l.show_images([all_images[i][0] for i in range(32)], 4, 8, scale=0.8);

def load_cifar10(is_train, augs, batch_size):
dataset = torchvision.datasets.CIFAR10(root="../data", train=is_train,transform=augs, download=True)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=is_train, num_workers=d2l.get_dataloader_workers())
return dataloader
def train_batch_ch13(net, X, y, loss, trainer, devices):
"""用多GPU进行小批量训练"""
if isinstance(X, list):
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
best_test_acc = 0
for epoch in range(num_epochs):
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch_ch13(net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
'''
num_batches // 5 是总批次的1/5,(i + 1) % (num_batches // 5) == 0表示,每过1/5总批次,就做如下操作
i == num_batches - 1 表示是否到最后一个批次
train_l = metric[0](总损失) / metric[2](样本个数)
train_acc = metric[1] (准确预测的个数) / metric[3] (标签总数)
'''
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
avg_loss = metric[0] / metric[2]
avg_acc = metric[1] / metric[3]
animator.add(epoch + (i + 1) / num_batches,(avg_loss,avg_acc,None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
if test_acc>best_test_acc:
best_test_acc = test_acc
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc 'f'{metric[1] / metric[3]:.3f},'
f' test acc {test_acc:.3f}, best test acc {best_test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on 'f'{str(devices)}')
'''
定义train_with_data_aug函数,使用图像增广来训练模型。该函数获取所有的GPU,并使用Adam作为训练的优化算法,将图像增广应用于训练集,最后调用刚刚定义的用于训练和评估模型的train_ch13函数。
'''
def train_with_data_aug(train_augs, test_augs, net,epoch=10, lr=0.001,batch_size=256):
train_iter = load_cifar10(True, train_augs, batch_size)
test_iter = load_cifar10(False, test_augs, batch_size)
loss = nn.CrossEntropyLoss(reduction="none")
trainer = torch.optim.Adam(net.parameters(), lr=lr)
'''开始计时'''
start_time = time.time()
train_ch13(net, train_iter, test_iter, loss, trainer, epoch, devices)
'''计时结束'''
end_time = time.time()
run_time = end_time - start_time
if int(run_time)<60:
print(f'{round(run_time,2)}s')
else:
print(f'{round(run_time/60,2)}minutes')
模型架构
batch_size, devices, net,lr = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3),0.001
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(resnet_block1): Sequential(
(0): Residual(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(resnet_block2): Sequential(
(0): Residual(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(resnet_block3): Sequential(
(0): Residual(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(resnet_block4): Sequential(
(0): Residual(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(global_avg_pool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=512, out_features=10, bias=True)
)
)
无图片增广的训练代码和结果
batch_size, epoch,devices, net,lr = 256,10, d2l.try_all_gpus(), d2l.resnet18(10, 3),0.001
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
train_augs = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
test_augs = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_with_data_aug(train_augs, test_augs, net,lr=lr,batch_size=batch_size)
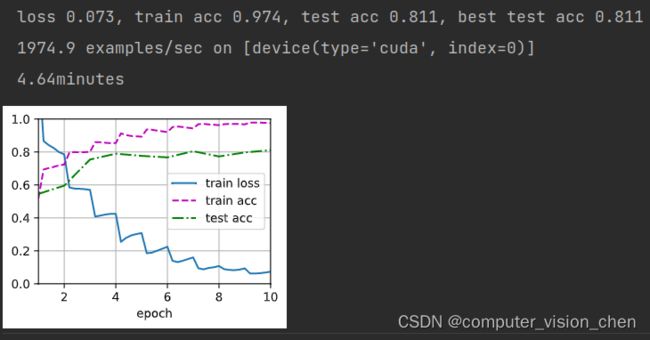
加入图片增广的训练代码和结果
batch_size,epoch, devices, net,lr = 256,20, d2l.try_all_gpus(), d2l.resnet18(10, 3),0.001
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
train_augs = torchvision.transforms.Compose([torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor()])
test_augs = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_with_data_aug(train_augs, test_augs, net=net,epoch=epoch,lr=lr,batch_size=batch_size)

图片增广+Normalize()归一化的训练代码和结果
batch_size,epoch, devices, net,lr = 256,20, d2l.try_all_gpus(), d2l.resnet18(10, 3),0.001
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
'''
[0.485, 0.456, 0.406]是均值(mean),[0.229, 0.224, 0.225]是标准差(standard deviation)。
对于每个RGB通道,减去相应的均值,再除以相应的标准差,即可完成归一化处理。
这些均值和标准差是基于ImageNet数据集计算得出的,并且在训练深度学习模型时被广泛使用
'''
normalize = torchvision.transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
train_augs = torchvision.transforms.Compose([torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize])
test_augs = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
normalize])
train_with_data_aug(train_augs, test_augs, net,lr=lr,batch_size=batch_size)

补充
transforms.ToTensor()把图像的取值范围压缩到了[0,1]与transforms.Normalize()归一化的区别
**ToTensor**的作用是将导入的图片转换为Tensor的格式,
1.导入的图片为PIL image 或者 numpy.nadrry格式的图片,其shape为(HxWxC)数值范围在[0,255],转换之后shape为(CxHxw)
2.数值范围在[0,1],方法是直接 每个元素/255
**Normalize()**作用是将图片在每个通道上做标准化处理,即将每个通道上的特征减去均值,再除以方差。
net = nn.DataParallel(net, device_ids=devices).to(devices[0])解读
这行代码的作用是将神经网络模型(net)包装成一个并行模型,以便在多个GPU设备上进行训练或推断。`nn.DataParallel`是PyTorch框架提供的一个工具类,用于并行地在多个GPU上运行模型。
在给定的代码中,`devices`是一个包含了多个GPU设备的列表,`devices[0]`表示使用第一个GPU设备作为主设备。`nn.DataParallel(net, device_ids=devices)`会将`net`模型复制到所有列出的GPU设备上,并自动进行数据的分割和并行计算。
最后,通过调用`.to(devices[0])`,确保模型和数据都在主设备上。主设备是用来存储模型参数和计算梯度的设备,其他设备则用于并行计算。这样可以确保主设备具有最新的权重更新,并且在训练或推断过程中把数据传输到其他设备进行并行计算。
normalize = torchvision.transforms.Normalize( [0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
其中[0.485, 0.456, 0.406]是均值(mean),[0.229, 0.224, 0.225]是标准差(standard deviation)。对于每个RGB通道,减去相应的均值,再除以相应的标准差,即可完成归一化处理。
需要注意的是,这些均值和标准差是基于ImageNet数据集计算得出的,并且在训练深度学习模型时被广泛使用。但在某些特定的应用场景下,可能需要根据具体数据集的特点重新计算和调整这些值。