深度学习在语音中的应用
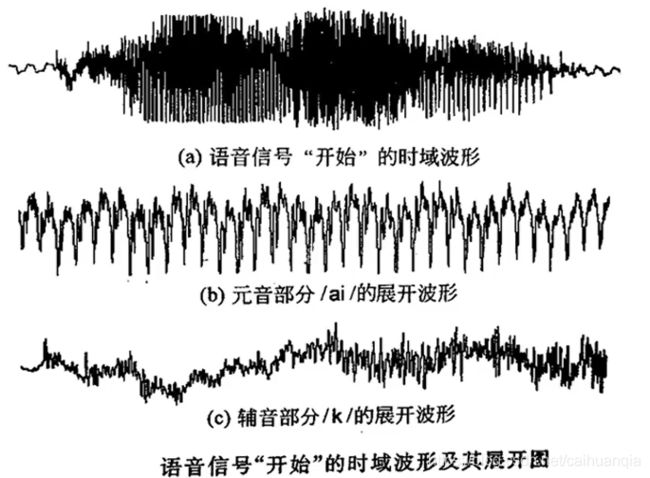
发音分类:浊音(使声带发生张弛振动)、清音(声带不振动)、爆破音
声学特性:音色(音质,两种声音区别的特性)、音调(声波的频率,即声音的高低)、音强(强弱,由声波的震动幅度)、音长(声音长短)
时域波形:
语音处理的流程

语音信号的处理:
1.分帧:短时分析时将语音流分成一段一段来处理
2.帧长:帧的时间跨度,常用20ms
3.帧移:帧与帧的平滑过渡:0-0.5帧长
预加重:
在发送端实现对语音信号的高频分量进行补偿的方法。
目的是减少尖锐噪声的影响,提升高频部分。
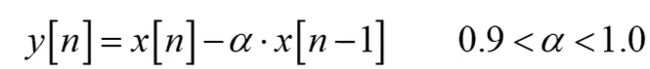 加窗:防止吉布斯效应:声音波形从高到低可能产生突变矩形窗、Hamming、Hanning。
加窗:防止吉布斯效应:声音波形从高到低可能产生突变矩形窗、Hamming、Hanning。
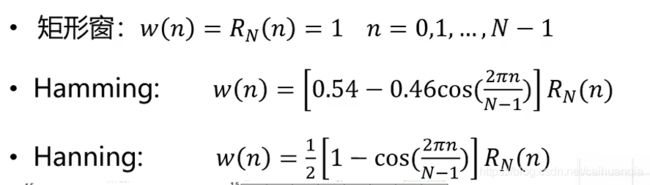
短时能量:一帧语音段的能量,计算如下

过零就是信号通过零值。过零率:每秒经过的次数
短时能量大,过零率小,相反则大。

MFCC特征提取(Mel-Frequency Cepstral Coefficients)
1.信号预处理:预加重、分帧、加窗
2.对每一帧进行FFT,得到幅度谱
3.对幅度谱加Mel滤波器组:
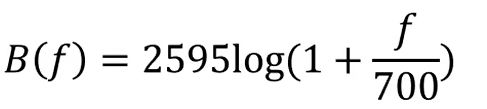
4.对滤波器输出做对数运算,再做一步离散余弦变换得MFCC
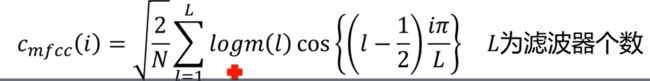

常见的语音数据集
THCHS30:
•包含了1万余条语音文件,大约40小时的中文语音数据,内容 以文章诗句为主,全部为女声
•数据库对学术用户完全免费。
•https://arxiv.org/abs/1512.01882 •https://www.openslr.org/18/
AISHELL:
•该数据集包含400个来自中国不同地区、具有不同口音的人的语 音。
•该数据免费供学术使用。
•https://arxiv.org/abs/1709.05522 •https://www.openslr.org/33/
ST-CMDS :
•数据内容以平时的网上语音聊天和智能语音控制语句为主,855 个不同说话者,同时有男声和女声。
•https://www.openslr.org/38/
Primewords Chinese Corpus Set 1:
•包含了大约100小时的中文语音数据,语料库由296名母语为 中文的智能手机录制。
•https://www.openslr.org/47/
•TIMIT
TIMIT数据集的语音采样频率为16kHz,一共包含6300个句子。
•语音由来自美国八个主要方言地区的630个人每人说出给定的 10个句子,所有的句子都在音素级别(phone level)上进行 了手动分割,标记。
•https://catalog.ldc.upenn.edu/LDC93S1
•TED-LIUM Corpus
•包括TED演讲音频和对应讲稿。其中包括1495段演讲录音和 对应的演讲稿,数据获取自TED网站。 •https://www.openslr.org/51/
**•VoxForge •**该数据集是带口音的语音清洁数据集,对测试模型在不同重音 或语调下的鲁棒性非常有用。 •http://www.voxforge.org/
语音识别
技术框架:
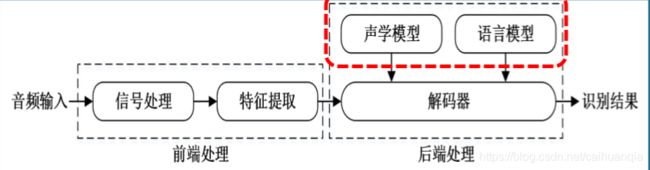
声学模型(Acoustic Model, AM)的任务是给模型产 生语音波形的概率。 占据着语 音识别大部分的计算开销,决定着语音识别系统的性能。
将声学和发音学的知识进行整合,以特征提取模块提取 的特征为输入,生成声学模型得分。
•高斯混合模型(Gaussian mixture model,GMM)用于对语 音信号的声学特征分布进行建模。
•隐马尔科夫模型(Hidden Markov model,HMM)则用于对 语音信号的时序性进行建模。
•维特比算法(Viterbi):针对有向图的短路径问题而提出 的动态规划算法。凡是使用隐含马尔可夫模型描述的问题都 可以用维特比算法来解码
GMM-HMM语音识别分三步:
•第一步,把帧识别成状态(难点),GMM
•第二步,把状态组合成音素,HMM
•第三步,把音素组合成单词,HMM
GMM模拟任意函数的功能取决于混合高斯函数的个数,具有一定的局限性,属于浅层模型。
而DNN模型可以模拟任意的函数,表达能力更强。所以替代了GMM进行HMM状态的建立。
•连接时序分类(Connectionist temporal classification, CTC ):CTC不需要标签在时间上一一对齐就可以进行训练, 在对输入数据的任一时刻做出的预测不是很关心,而关心的是 **整体上输出是否与标签一致,**从而减少了标签预划定的冗杂工 作。在整个网络结构中把CTC作为损失函数。
DFCNN 先对时域的语音信号进行傅里叶变换得到语音的语谱 图,直接将一句语音转化成一张图像作为输入,输出单元则 直接与终的识别结果(比如音节或者汉字)相对应
声纹识别
作为说话人的辨认,根据说话人的声波的特性。
可分为:文本相关 、文本独立(只关心是谁,不关心文本)的声纹识别。
技术框架:

识别主要就是特征提取和模式匹配(GMM高斯混合模型)。
•通用背景模型(Universal Background Model, UBM)描述的 是语音特征在空间中的平均分布,且语音特征与目标说话者 无关,与环境噪声和声道有关
声纹模型
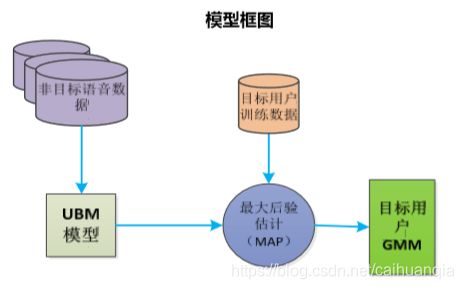
1.先使用大量非目标数据训练UBM,然后使用极大后验概率MAP自适应算法和目标说话人数据来更新局部参数得到GMM。
MAP自适应算法相当于先进行一轮EM迭代得到新的参数,然后将新参数和旧参数整合。
下面是GMM-UBM模型
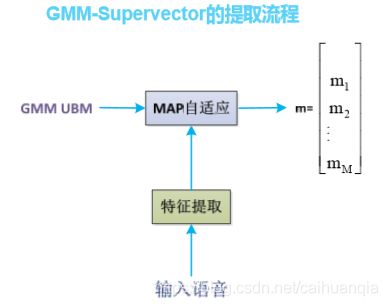
下面是GMM-SVM模型
对GMM中每个高斯分量均值构建一 个高斯超向量作为SVM的样本,SVM计算得分,设置阈值,得到一个正例;利用带核的SVM的非线性分类能力,在上一个模型基础上大幅提升了识别性能。
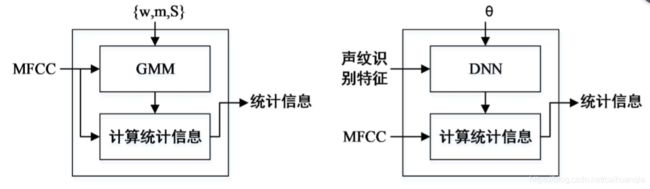
DNN的方法的改进:
语音合成
基本框架:
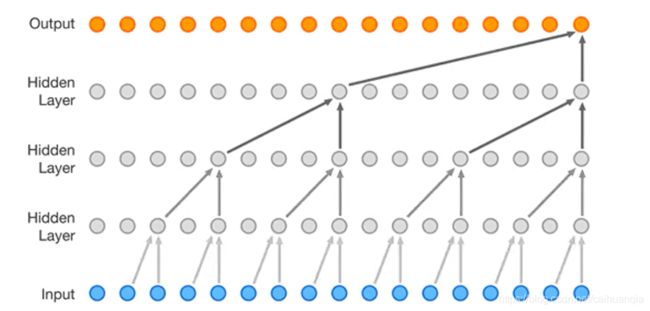
重要: WAVENET–序列模型,可以直接学习到采样值的序列的映射
每次生成一个OUTPUT
parallel Wavenet
包括老师和学生两部分,可以生成多个output
预训练的老师网络用来给学生的输出打分,学生用来最小化它和老师里的分布的KL散度,通过最大化样本的log-likelihood,并同时最大化它的熵

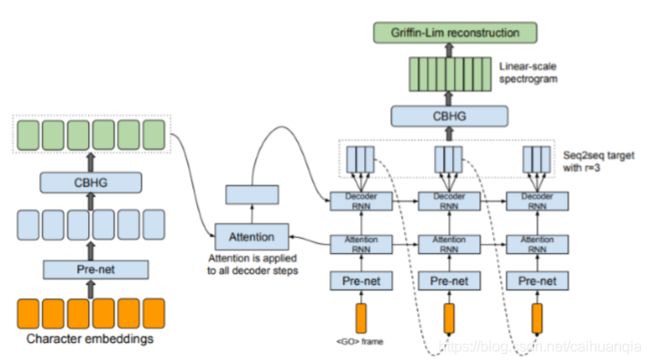
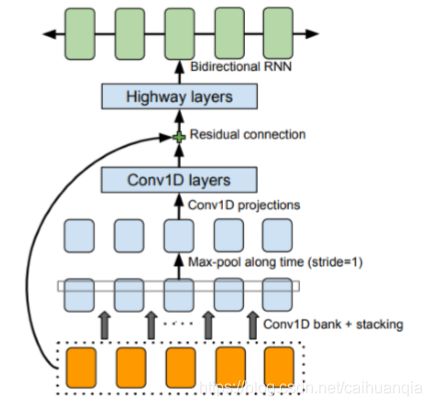
Tacotron 深度学习模型-端到端
使用了注意力机制