BERT与知识图谱的结合——ERNIE模型浅析
在nlp领域中,自然语言表征模型由于可以让机器更好地理解人类语言,因此越来越受到人们的关注,其中具有代表性的就是BERT模型,它通过在大量的语料库上进行预训练的方式来实现对于文本语义的理解。简单来说,BERT先随机mask掉一些单词,然后再通过上下文预测的方式来实现语言表征,得到预训练模型后,再针对性地对预训练模型进行微调,就能完成一些nlp的下游任务。
通过分析BERT模型我们可以发现,它虽然考虑了上下文语义,但是还是缺少了一些东西,那就是知识信息。换句话说,BERT模型通过在大量语料的训练可以告诉我们一句话是否通顺,但是它却不知道这句话描述的是什么,它也许能通过训练学到上下文单词之间的一些关系,但是这样的关系还不足以构成知识。举例来说,对于“北京是中国的首都”这句话,如果把“北京”二字mask掉,BERT也许可以通过下文的字样预测正确,但是这并不意味着它理解了“北京”、“中国”和“首都”这些词之间的关系,而这些关系才是知识信息,它们在自然语言中至关重要,如果能够让模型考虑到知识信息,就能让模型不仅在字词、语法层面,还能在知识层面符合人类语言的要求,从而成为一个“有文化”的模型。
一、知识图谱
为了向语言表征模型提供知识信息,我们就需要用到知识图谱,知识图谱能够提供丰富的结构化知识事实,如果能将知识图谱引入到模型当中,就能够对模型进行增强。所以本文首先来介绍一下什么是知识图谱。
虽然知识的种类有很多,但它们基本都可以归纳为形如{实体,关系,实体}三元组的形式,例如对于“北京是中国的首都”这个知识点,就可以归纳为{中国,首都,北京}这样的形式,如下图所示,让每一个实体成为一个节点,用边代表它们之间的关系,就可以将复杂的知识构建为若干三元组,进而组成一个知识图谱。

知识图谱示例
不过仅仅是有这样抽象的图结构是不够的,我们需要知道不同实体之间量化的语义关系,这样才能够让机器去理解,而这就需要用到知识嵌入算法,其中一个代表性的算法就是TransE算法,它的基本思想很简单,就是将每一个实体和关系都表示成一个向量,比如两个实体为h和t,关系为r向量,对于一个三元组,h实体向量加上r关系向量后应该尽可能地等于t实体向量,如下图所示。算法要做的就是通过优化向量的取值,让知识图谱中的每一个三元组都尽可能满足h + r = t,这样就可以得到一个关于知识图谱的最优向量表示。

TransE算法
有了向量表示之后,对于不同实体之间的关系就变得很直观了,如果给定一个三元组中的两个向量,那么就可以通过h + r = t 来对第三个元素进行预测。可以看出,算法只需要学习出实体和关系的向量表示,这样的模型复杂度很小,而且实验表明该模型的预测效果很好,因此这是一个简单高效的算法。
二、ERNIE模型
下面介绍两种通过知识图谱来增强BERT语言表征模型的方法,有趣的是这两种增强模型都叫做ERNIE,一个是由清华和华为提出来的Enhanced Language Representation with Informative Entities,另一个是百度提出的Enhanced Representation through Knowledge Integration。
1. Enhanced Language Representation with Informative Entities
该模型利用了知识图谱中的多信息实体(informative entity)来作为外部知识改善语言表征,为了将知识信息加入到模型当中,该ERNIE模型解决了下面的两个问题:
- 结构化的知识编码:对于抽象的知识信息,需要将它们进行编码,这样才能够将知识用于语言表征。
- 异质信息融合:显然,BERT预训练时对单词的编码和对知识的编码是不同的,虽然都是将其转化为向量,但是却位于不同的向量空间,因此就需要对模型进行设计,来实现对于词汇、句法和知识信息的融合。
该模型分为两个部分:抽取知识信息与训练语言模型,为了得到结构化的知识编码,模型采用了上面提到的TransE知识嵌入算法,然后再将编码后的知识信息整合到语义信息当中;为了将更好地将语义和知识信息融合起来,模型改进了BERT模型的架构,并设计了新的预训练任务,这样就可以将实现知识信息与语义信息的融合,具体的模型结构如下图所示。
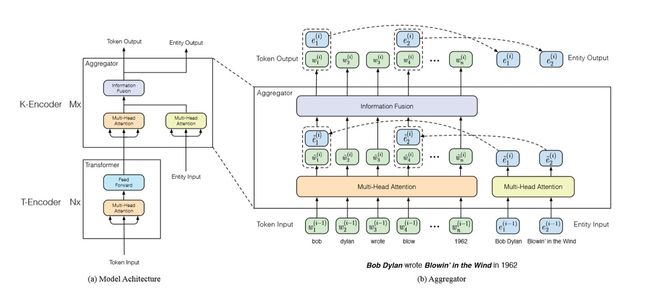
ERNIE模型架构
模型的整体架构如上图(a)所示,主要由两个模块构成,文本编码器T-Encoder和知识编码器K-Encoder。对于T-Encoder,它负责获取输入token的词法和句法等语义信息,首先它需要对token embedding, segment embedding和positional embedding进行求和来获得input embedding,然后通过多层的双向Transformer编码器来实现对于语义特征的提取,这和BERT模型一致,就不再赘述了。
对于K-Encoder,它需要实现上面提到的异质信息融合,也就是将额外知识信息整合进来自底层的文本信息,这样就可以在一个统一的特征空间中表征 token 和实体的异构信息。具体如上图(b)所示,用 {w1, w2,.....wn} 来表示token序列的 embedding,用 来表示该序列中实体的embedding(由TransE得到),首先令两序列分别通过各自的multi-head self-attention层,如下所示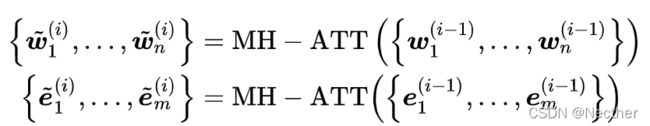
然后再将序列中的token与相应的实体对齐(实体与对应的首位token对齐),然后将这样的序列输入到信息融合层当中,信息融合层的计算步骤如下:
对于有对应实体的token: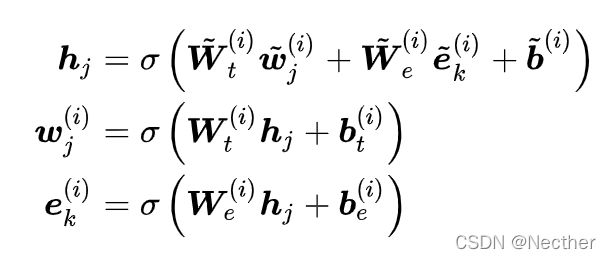
对于没有对应实体的token: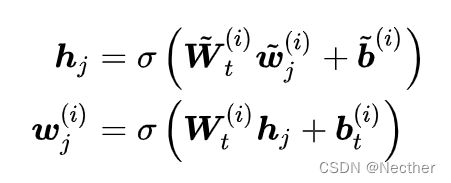
其中 Wt 代表隐藏层中的权重, 是非线性激活函数。
这里说一下个人对于K-Encoder的作用理解,前面的multi-head self-attention层是让模型分别对token和对应实体进行编码,从而能够分别找到两序列内部的关系;然后将两序列对齐后输入信息融合层,使得token embedding在原有的语义信息基础上,还加入了来自于实体的知识信息,从而实现了对于BERT语言表征模型的增强。
为了能够更好地融入知识信息,需要对训练的任务进行新的设计,在BERT原有的masked language model (MLM) 和the next sentence prediction (NSP)作为预训练任务之外,该模型还额外引入了一种新的训练任务,叫做denoising entity auto-encoder (dEA),它做的就是随机 Mask 掉一些实体,并要求模型基于与实体对齐的token、从给定的实体序列中预测最有可能的实体,预测的概率分布计算公式如下所示: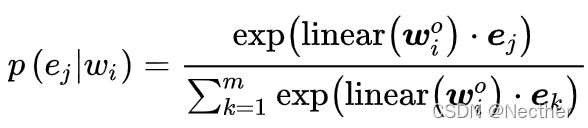
其中linear()代表线性层,dEA预测的损失函数可由交叉熵来计算。
在实际情况中,token与实体的对齐有时会出现一些错误,因此该dEA任务也人为地引入一些错误。1)模型会以5%的概率将与token对齐的实体换位另一个随机的实体,这样做是为了能够矫正token与实体对应错误的情况。2)模型会有15%的概率mask掉对应的token与实体,这样做是为了让模型能够矫正一些没有提取到token-实体对的情况。 3)剩下的概率token-实体对不会变化,这就是为了训练模型将实体信息整合到token表示当中,从而实现更好的语言理解。
对于下游任务的微调过程,该模型通过设计了不同的标记token以适应不同的任务,这就使得输入的训练因任务的不同而不同,如下图所示,其中的[ENT]、[HD]和[TL]都是特定的标记token,为了让不同类型的输入对齐,对于普通任务中对应的是占位符(虚线框)。

由于模型从零开始的训练成本很高,因此该模型的初始化参数采用的是BERT模型的参数。而对于训练数据,该模型不能只采用无监督的纯文本数据了,还需要对文本数据中的实体进行提取和对齐。论文中的模型采用了Wikipedia的数据作为语料库,并将其中的文本与Wikidata中的实体对齐,然后再利用TransE算法将实体转化成为向量,最后就可以将对齐的token和实体向量输入到模型当中进行训练。
2.Enhanced Representation through Knowledge Integration
相对于前一个ERNIE模型,这个ERNIE模型的原理更简单一些,该模型并没用直接输入外部的知识信息,而是通过改变masking策略的方式,隐式地去学习诸如实体关系、实体属性等知识信息。
对于BERT模型,其masking策略是基于字的,而这样的策略不利于知识信息的学习,特别是对于中文语言模型,如下图所示,对于BERT模型,它mask掉的只是一些字,因此它在训练时学习到的更多是字与字之间的关系,例如[尔]与[哈]和[滨]之间的局部关系,而对于该ERNIE模型来说,它还会mask掉一些连续的tokens,这样该模型除了能学到上面的关系之外,还能学到[哈尔滨]与[黑龙江]、[省会]等之间的关系,而这就是所谓的知识信息。
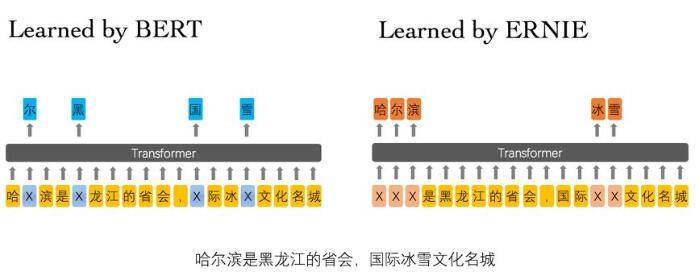
需要注意的是,该ERNIE模型采用的仍是基于字特征的输入建模,也就是说模型的token还是基于字的,只不过mask的粒度大小有所变化。对于语料库中的纯文本,先使用词法分析工具对文本数据进行字、词、实体等不同粒度的切分,然后对切分后的数据进行 token 化处理,得到文本的 token 序列及切分边界,接着根据词典将其映射为id数据,在训练过程中模型会根据切分边界对连续的token进行随机mask操作,这样就能让模型能够在语义、知识等不同层次上学习到相应的关系。
在训练数据上,该模型也引入了诸如基于百科类、资讯类、论坛对话类等构造的具有上下文关系的句子对数据,其中论坛对话类数据的引入是该模型的一个特色,模型采用了 DLM(Dialogue Language Model)建模 Query-Response 对话结构,将对话 Pair 对作为输入,引入 Dialogue Embedding 标识对话的角色,利用 Dialogue Response Loss 学习对话的隐式关系,通过该方法建模进一步提升模型语义表示能力。
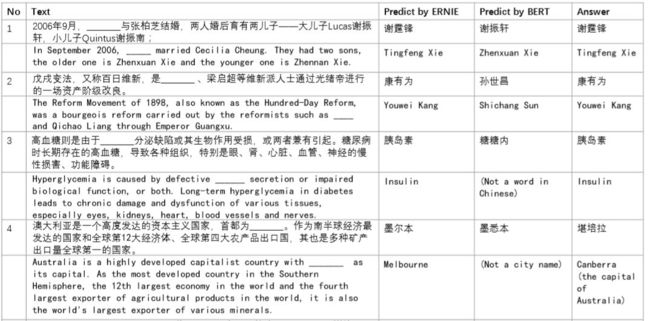
下图是一些填空问题的,通过与BERT进行对比可以看出,经过增强后的模型对于实体的预测能力有了显著的提高。
最后对两个ERNIE模型做一个总结,
- 首先从模型架构来看,相较于BERT,前一个模型有所改动,它在BERT的基础上加入了K-Encoder,实现了知识信息与token原始语义信息的融合,而后一个模型的架构基本没有什么变动。
- 从输入数据来看,相比较于BERT的纯文本数据,仍然是前一个模型的输入数据变化较大,它在纯文本数据的基础上,还需要提取出其中的实体、并通过知识嵌入算法将其变为向量,输入的数据既有token embeddings也有entity embeddings,而对于后一个ERNIE模型,输入数据仍然还是纯文本的生成的token,只不过需要先通过词法分析工具对文本数据进行不同粒度的切分。
- 从训练任务上来看,为了使得模型能够学到更多的知识信息,两个模型都额外加入了预测mask实体的任务,不过前者是根据token以及其它实体,从一些给定的实体序列中找出概率最大的那个,而后者则是直接根据上下文的token来预测实体对应的每个token。
总结
上面就是关于知识图谱与语言表征模型结合的一些工作,为了提高性能,模型通过引入实体关系等外部知识来进行语言模型的预训练,相信这样的研究方向是非常值得我们接下来去探索的。
参考资料
[1] ERNIE: Enhanced Language Representation with Informative Entities
[2] https://github.com/thunlp/ERNIE
[3] ACL 2019 | 清华等提出ERNIE:知识图谱结合BERT才是「有文化」的语言模型
[4] ERNIE: Enhanced Representation through Knowledge Integration
[5] https://github.com/PaddlePaddle/LARK/tree/develop/ERNIE
[6] 中文任务全面超越BERT:百度正式发布NLP预训练模型ERNIE