Dolphinscheduler调度DataX从MySQL导入到Hive
1、Dolphinscheduler创建文件夹及创建文件

2、mysql_dms_good_2_hive文件配置(全量抽取)
{
“job”: {
“content”: [{
“reader”: {
“name”: “mysqlreader”,
“parameter”: {
“column”: ["*"],
“connection”: [{
“jdbcUrl”: [“jdbc:mysql://hadoop01:4000/boot”],
“table”: [“dms_goods”]
}],
“password”: “root”,
“username”: “root”,
“where”: “”
}
},
“writer”: {
“name”: “hdfswriter”,
“parameter”: {
“column”: [{
“name”: “id”,
“type”: “string”
},
{
“name”: “name”,
“type”: “string”
},
{
“name”: “erp_good_id”,
“type”: “string”
},
{
“name”: “unit”,
“type”: “string”
},
{
“name”: “sec_unit”,
“type”: “string”
},
{
“name”: “org_id”,
“type”: “string”
},
{
“name”: “disable”,
“type”: “int”
},
{
“name”: “remarks”,
“type”: “string”
},
{
“name”: “del_flag”,
“type”: “string”
},
{
“name”: “updated_by”,
“type”: “string”
},
{
“name”: “created_by”,
“type”: “string”
},
{
“name”: “opt_counter”,
“type”: “int”
},
{
“name”: “created_date”,
“type”: “string”
},
{
“name”: “updated_date”,
“type”: “string”
},
],
“compress”: “”,
“defaultFS”: “hdfs://hdfs-ha:8020”,
“fieldDelimiter”: “,”,
“fileName”: “dms_goods”,
“fileType”: “text”,
“path”: “/user/hive/warehouse/nf_meat_ods.db/dms_goods”,
“writeMode”: “nonConflict”
}
}
}],
“setting”: {
“speed”: {
“channel”: “1”
}
}
}
}
3、hive创建表
CREATE TABLE nf_meat_ods.dms_goods(id string,
name string,
erp_good_id string,
unit string,
sec_unit string,
org_id string,
DISABLE int, remarks string,
del_flag string,
updated_by string,
created_by string,
opt_counter int, created_date string,
updated_date string) ROW format delimited fields terminated BY “,” STORED AS TEXTFILE;
4、Dolphinscheduler创建工作流
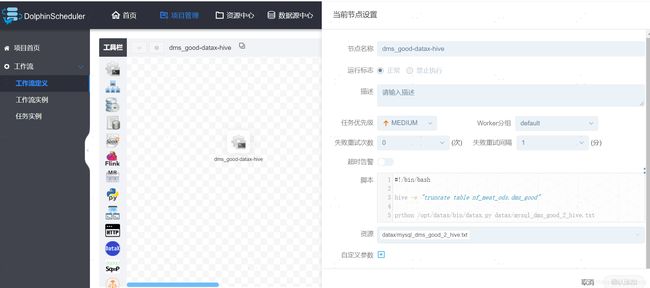
5、Dolphinscheduler 运行该工作流
