BERT原理&Fine Tuning&Bert变种
文章目录
-
- BERT原理
-
- 训练时的任务
-
- 任务一
- 任务二
-
- 任务二的改进
- 模型的输入
- BERT - Fine Tuning
-
- 单个句子的预测类
- 序列标注类
- Q&A类
- seq2seq?
- BERT 变种
-
- Transformer-XL
- XLNet
-
- Autoregressive Language Model
- Denoising Auto-Encoder
- 乱序
- Two-Stream Attention
- 与Transformer-XL结合
- ALBert
BERT原理
BERT全称为Bidirectional Encoder Representation from Transformer,从名字可以知道,BERT是Transformer的Encoder部分。BERT的最大的改进是在模型的训练核数据的输入部分。
BERT是一个动态词向量模型,其主要功能就是抽取每个词在句子中的语义信息,并且表示出来。
训练时的任务
BERT在训练时,采用的多任务的方式,这样可以期待模型在多多种任务的情况下学到更好的抽取语义特征的能力。
任务一
在处理数据时,会有15%的概率把一些句子给替换成别的,然后要求模型对被替换的部分进行预测和还原,例如:
今 天 天 气 很 好 -> 今
天 气 很 好
模型需要预测被MASK的部分究竟是什么。其操作很简单,只需要把MASK的位置拿出来,通过一个线性层变换到voc_size的维度,在进行预测就可以了。
由于微调时,不存在MASK的情况,所以可能会出现不一致的情况发生。例如模型认为句子中会经常出现一个叫MASK的token,但实际在下游任务中可能不会出现(看你做的啥任务)。
为了使模型能更好的应用于下游任务,所以对MASK的机制在进行改进:

这样就可以使模型不会学到一些奇怪的信息了。
任务二
除了单个句子,我们还期望模型能够对多个句子进行处理。例如比较两个句子是否有关等。此时我们就需要在预训练时加入多个句子处理的任务。
BERT加入的任务是句子的下一个句子预测:
今天天气真好。
我要出旅游。
这两个句子,明显第二个句子很可能是第一个句子的下一个句子,所以输出1。
BERT会对这两个句子进行处理,把其变成以下的格式:
[CLS] 今天天气真好。[SEP] 我要出旅游。 [SEP]
CLS是BERT用于分类句子的标记,如果需要对整个句子进行分类,则只需要把CLS的输出部分进行处理即可。而SEP则是用于分割句子的,用SEP来分开句子和句子之间。
这两我们就把两个句子表示成了一个句子,然后我们可以通过CLS的输出来进行判断两句是否有上下文关系。
任务二的改进
任务二在后续的很多论文中被证实对BERT的性能提升没啥太大帮助。其原因很可能是太简单了,所以有人对任务二进行了改进。
BERT不再要求判断两个句子是否是下一个关系。
而是要求判断两个句子的顺序是否正确。举例来说就是把两个相邻的句子随机打乱,让模型预测这两个句子顺序是否正确。
这显然比判断两个句子是否相邻要困难。从而逼迫模型学习到更多的有用特征。
模型的输入
回忆一下Transformer的输入部分,一共有两个Embedding。
一个是Position Embedding,一个是Word Embedding。而BERT又加入了一个Segment Embedding。
这是为了进一步的区分两个句子,举个例子:

可以看到第一个句子的部分(包括其结尾的Sep)都被表示成了EA,而第二个句子被表示成了EB。
最后三个EMbedding通过相加来融合信息。也就是说Segment Embedding的大小和d_model的大小一致,并且只有两个状态,0和1。0代表第一个句子,1代表第二个。
BERT - Fine Tuning
BERT的Fine Tuning有两种方式:
一种是固定住BERT不变,只训练一个分类器。此时BERT单纯只作为一种特征抽取器。这种方式得到的结果一般比较差,但训练速度比较快。
另一种是让BERT和分类器一块训练,得到一个结果,这种的效果一边比较好,但耗费的计算资源比较大。
BERT的微调,也就是Fine Tuning,所需要的训练数据仍然是比较大的,可能要上2k的大小。
所以对于很少的数据,例如只有几百,几十的数据量,Fine Tuning可能达到不了很好的效果。
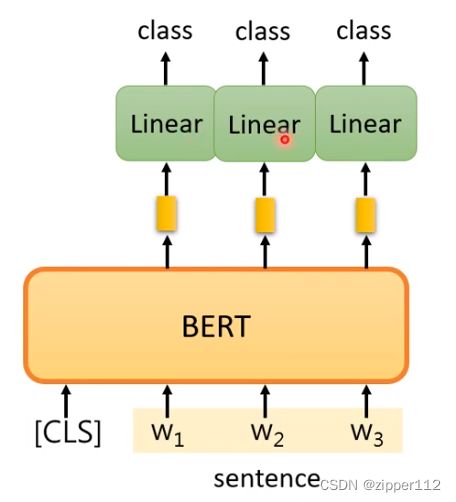
单个句子的预测类
如果需要对句子分类,比如评价某个句子是正面的还是负面的,只需要取出CLS层进行分类即可。

如上图所所示,我们默认CLS输出的信息代表了整个句子的信息,对它通过一个线性层变换后进行分类,就可以得到最终的类别。
序列标注类
同样的道理,如果要做序列标注,我们只需要利用除了CLS,SEP之外的输出即可。我们这些输出进过一个线性层变换即可得到结果。
Q&A类
对于Q&A的问题,我们输入的是两个句子,一个是文章,一个是提问。
我们的答案在文章之中,也就说是文章(document)的某句话(这是一个有限制的Q&A问题)
此时我们可以有如下策略:
- 对于文章的每个输出,都与两个向量做点乘
- 文章的每个输出对Start向量做点乘,取最高的那个结果的位置作为答案的起点a
- 文章的每个输出对End向量做点乘,取最高的那个结果的位置作为答案的终点b
- 最后的答案就是document[a: b]
换而言之,就是我们需要学习得出答案在文章的起点和终点。而计算起点和终点需要依靠两个可以学习的向量Start和End

如上图所示,蓝色的end向量与每个document的输出做点乘,然后把结果扔给softmax,取最高的那个作为答案的终点。
seq2seq?
seq2seq任务对BERT来说是无法直接解决的,因为seq2seq任务有Encoder和Decoder。而BERT只含有Encoder。
所以无法直接解决这个问题,但也有人使用了一些方法让BERT能够解决这些问题,这里暂时先不写。
虽然BERT不能直接的为我们做seq2seq,但我们仍可以把其当做为Encoder的特征提取器,期待着他能够在Encode时提取更多的特征。
下面的代码,我作出了一些相关的尝试
BERT 变种
Transformer-XL
先来说一个Transformer的进阶版本,Transformer-XL。再来说后面的XLNet
普通Transformer的缺陷:
Transformer虽然没有长度限制,但一般的Transformer的上下文捕捉能力也是有有限的。
而且对于太长的句子,Transformer的计算难度会变的非常大,比如Bert中一般限制输入句子最长长度为512,再长可能效果就不好了。
此时我们一般的做法是截断,分别进行推理,然后再融合。这种做法固然可以解决文本过长的问题,但仍然难以避免在截断处的上下文语义缺失。
Transformer-XL就是为了解决这个问题而提出了,Transformer-XL又重新加入了类似于RNN的循环机制,不过是在Transformer原本的架构基础上改进的。
假设我们的Transformer每次都只计算的句子的某个固定长度区间,除此之外,还会像RNN一样看一下前面的序列的计算结果。

如上图所示,大括号的部分是本次要计算的一段序列,而阴影部分是我们上一次计算的序列。我们大致的计算思路如下:
- 灰色部分的每一层输出的值 h t − 1 h_{t-1} ht−1都保留
- 计算当前new segment时,前一层的 h h h也参与运算,不过只生成k,v,但不生成q。
- new segment生成的q对所有的k做运算(包括灰色部分的),然后在作用于所有的v,最后生成本层的输出。
- 重复上面步骤
这样我们就计算出了new segment的输出,也就是说new segment的部分会对前面已经输出的元素的输出层做自注意力运算。
注意,前面已经输出的部分(灰色的部分)不会在计算梯度。
这样我们就可以像RNN一样的来循环的计算了。
如果每次我们选取的子句的长度为S,Transformer有N个层,那么我们每次最多可以捕捉到的上下文长度为 N ∗ S N*S N∗S。如图所示:

第一层,只能看到前S个长度
第二层,可以看到上一层的前S个长度,但由于上一层看到了再上一层的前S个长度,于是第二层我们可以看到2S的长度,以此类推。
除此之外,还有一个问题,如果每次我们只计算一个区间,就会出现一个问题。那就是原本的位置编码会变的失效。
我们先来看原来Transformer的注意力是怎么算的:
首先,每个token都有两个embedding,一个是位置一个是词向量,分别记为 U , E U, E U,E。假设Q和K的矩阵分别为 W q , W k W_q,W_k Wq,Wk。那么 x i , x j x_i,x_j xi,xj之间的注意力运算就是 ( W q ( U x i + E x i ) ) T W k ( U x j + E x j ) (W_q(U_{x_i}+E_{x_i}))^TW_k(U_{x_j}+E_{x_j}) (Wq(Uxi+Exi))TWk(Uxj+Exj)展开后得到:

Transformer-XL对上述的位置编码做了改变,首先把 U j U_{j} Uj变成了 R i − j R_{i-j} Ri−j,这个 R i − j R_{i-j} Ri−j是一种相对位置编码,是不可学的。
然后为了更好地辅助学习到相对位置关系,Transformer-XL把 c , d c,d c,d中的 U i T W q T U_i^TW_q^T UiTWqT分别替换成了 u T u^T uT和 v T v^T vT,这两个参数是可以学习的。

XLNet
首先先来讲一下自回归语言模型。
先来回忆一下语言模型最初始的定义,给定一个句子S,求出S出现的可能性的大小 P ( S ) P(S) P(S)。由于S可以由多个token组成,于是就变成了计算 P ( w 1 , w 2 , . . . w n ) P(w_1,w_2,...w_n) P(w1,w2,...wn)出现的概率。
我们再由乘法公式对其进行拆解,得到计算 P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 w 2 ) . . . P ( w n ∣ w 1 w 2 . . . w n − 1 ) P(w_1)P(w_2|w_1)P(w_3|w_1w_2)...P(w_n|w_1w_2...w_{n-1}) P(w1)P(w2∣w1)P(w3∣w1w2)...P(wn∣w1w2...wn−1)
于是我们建模语言模型,一般就是要根据前面的若干个词,来预测下一个词。
Autoregressive Language Model
上述的根于一个词预测下一个词的语言模型我们称之为自回归语言模型。
例如ngram,ELMo,GPT都是这一类的语言模型。他们通常具有强大的生成能力,因为他们是对整个句子进行建模的。
但是他们也有缺陷,那就是只能看到上文而不能看到下文。虽然ELMo可以看到下文,但是当句子过长时,就难以处理,比如中间的信息可能会被遗忘。
Denoising Auto-Encoder
类似BERT这种模型,我们称之为去噪自编码器(也有人称之为Mask Language Model,也就是MLM)。
这种模型通过做完形填空的方式来预测缺失部分的词汇,从而学习上下文的信息。
但是,这样做有一个致命的缺陷,那就是无法获取Mask和Mask之间的信息。也就是它假设每个Mask之间是相互独立的。
比如有一个句子是:“我喜欢吃梨,因为它水很多”。
我们进行随机的Mask,就可能会得到:“我喜欢吃[Mask],因为它[Mask]很多。”
这样进行预测可能会效果并不好。因为前后两个Mask是有关系的,如果都Mask掉就难以预测。那么,我们能不能想GPT一样按照自回归的方式挨个的对他们进行预测呢?
乱序
XLNet基于上述的想法,然后对句子序列进行的乱序。其具体的思想如下:
如果我们要计算 P ( S ) P(S) P(S),那没有必要我们非得从 x 1 x_1 x1开始。具体的我们可以这么做分解

按照乘法公式,我们最后计算出来也是 P ( S ) P(S) P(S),这样我们就相当于是先把序列打乱,然后再按照自回归的方式进行训练。
这样我们预测某一词,其前面的词可能是其上下文的词。例如 P ( x 2 ∣ x 1 x 3 x 4 ) P(x_2|x_1x_3x_4) P(x2∣x1x3x4)我们即看到了 x 2 x_2 x2的上文信息,也看到了下文信息。这就解决了自回归语言模型的不足。
又由于我们是逐个进行预测的,所以又不会出现Mask之间没有注意到的情况。
那么,乱序之后会不会导致语义混乱呢?这不用担心,因为虽然顺序打乱,但是位置编码还是原序的编码,所以每个词的原本位置信息仍然是保留的了。
看似这种模型没有问题了,但是其实还存在一个很大的问题,我们看下面这两种状况:
假设有个句子 S = ( w 1 , w 2 , w 3 , w 4 ) S=(w_1,w_2,w_3,w_4) S=(w1,w2,w3,w4)
乱序两次之后分别得到:
S = ( w 2 , w 1 , w 3 , w 4 ) 和 S = ( w 2 , w 1 , w 4 , w 3 ) S=(w_2,w_1,w_3,w_4)和S=(w_2,w_1,w_4,w_3) S=(w2,w1,w3,w4)和S=(w2,w1,w4,w3)
现在问题就出现了,如果我们要预测第三个数,在知道 w 2 , w 1 w_2,w_1 w2,w1的情况下,我们是预测到 w 3 w_3 w3还是 w 4 w_4 w4?
此时我们在同样的输入的情况下,可能得到不同的输出,这就导致模型性能可能变差。
于是为了解决这个问题,作者提出了双流注意力机制,这个机制就是为了解决上述的问题的。
作者把一个句子的输入和每层的计算都变成了两个部分,一个是 h h h称之为内容表示,一个是 g g g称之为查询表示。
Two-Stream Attention
然后双流注意力机制的机理如下:
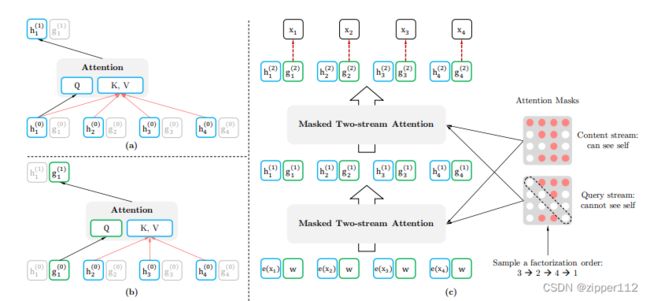
其中 h ( 0 ) h^{(0)} h(0)是word embedding,而 g ( 0 ) g^{(0)} g(0)是一个可学习的参数。
每一次预测某个token,我们都会计算两个向量,一个是 h h h一个是 g g g
其中h的计算如上图所示:
首先被预测的位置的h会参加Q的计算,而剩余的部分计算K和V(这里被预测的位置也参加了)
然后是g的计算:
g的计算里我们可以看到,被预测的位置没有参加K和V的计算,这是为了防止泄露这个token的信息。
就按照这种方式我们不断地计算下去,最后把g的部分作为最终的输出
与Transformer-XL结合
XLNet加入了Transformer-XL的循环机制,使得模型能够处理更长的句子。
总结:
- XLNet没有引入新的额外参数
- XLNet在推理时不需要额外的计算
- XLNet在训练时需要一些额外的计算量
- XLNet融合了MLM和ALM的特点
ALBert
AlBert本身的创新点并不多,只对Bert做出了一些小的改进,其最重要作用是通过共享参数降低了模型的大小。
- ALBert抛弃了NSP任务,不在判断两个句子是否相邻,而是给两个相邻的句子让其判断两者顺序是否正确。后续许多实验证明原本Bert的NSP任务作用不大
- ALBert对Embedding做了因式分解,把原本 V × E V×E V×E变成了 V × K + K × E V×K+K×E V×K+K×E。假设V是100,E是10,K是5。100*10=1000 > 100 * 5 + 5 * 10=550。从而降低了要学习的参数个数。
- ALBert对模型的参数进行了共享,其具体有如下共享策略

可以看到,在共享Attention的参数时,其模型参数量减少,同时精度变化不大。需要注意的是,ALBert并没有减少计算量。