[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练
Self-Supervised Pre-Training of Swin Transformers for 3D Medical Image Analysis
摘要
-
Vision Transformer(ViT)在全局和局部表示的自监督学习方面表现出了出色的性能,这些表示它可以转移到下游任务的应用中。
-
提出模型:提出一种新的自监督学习框架Swin UNETR,它具有定制的代理任务,用于医学图像分析。
-
模型介绍:
(1)一种新的基于3D变压器的模型,称为Swin UNEt Transformer (Swin UNETR),具有用于自我监督前训练的分层编码器;
(2)为学习人体解剖学的基本模式定制代理任务。
-
取得成绩:
(1)在来自各种身体器官的5050个公开的计算机断层扫描(CT)图像上成功地演示了所提出的模型的预训练。
(2)通过使用13个腹部器官和来自医学分割十项athlon (MSD)数据集的分割任务对预训练的模型进行微调,验证了方法的有效性。
(3)模型目前在MSD1和BTCV 2数据集的公共测试排行榜上是最先进的。
引言
背景:
-
Vision Transformer(ViT)的在计算机视觉和医学图像分析中开创了一种革命性的趋势。Transformer在学习文本前任务方面表现出非凡的能力,在跨层学习全局和局部信息方面非常有效,并提供大规模训练的可扩展性。与接受域有限的卷积神经网络(CNN)不同,ViT对来自一系列补丁的视觉表示进行编码,并利用自注意块来建模远程全局信息。
-
最近,移位窗口(Swin)变压器提出了一个层次化的ViT,允许本地计算自注意与重叠的窗口。相对于ViT中自注意层的二次复杂度,该体系结构实现了线性复杂度,从而提高了ViT的效率。此外,由于Swin transformer的层次性,它们非常适合于需要多尺度建模的任务。
-
与基于CNN的模型相比,基于Transformer的模型在预训练期间学习更强的特征表示,因此在下游任务的微调上表现良好。最近在ViT方面的一些努力通过在ImageNet等大规模数据集上进行自监督的预训练,取得了最新的结果。
-
医学图像分析还没有从通用计算机视觉的这些进步中受益,这是因为:
(1)自然图像和医学成像模式之间的巨大领域差距,如计算机断层扫描(CT)和磁共振成像(MRI);
(2)应用于体积(3D)图像(如CT或MRI)时,缺乏跨平面上下文信息。后者是二维Transformer模型的一个限制,用于各种医学成像任务,如分割。
之前的研究已经证明了医学成像中有监督的预培训对不同应用的有效性。但是大规模创建专家注释的3D医疗数据集是一项重要且耗时的工作。
提出模型:
提出了一种新的自监督学习框架用于三维医学图像分析。
-
首先,提出了一种名为Swin UNEt Transformer (Swin UNETR)的新架构,该架构带有Swin Transformer编码器,直接利用3D输入补丁。
-
随后,利用各种代理任务,如图像嵌入、3D旋转预测和对比学习(如下图是培训前框架概述,输入CT图像被随机裁剪成子卷,并通过随机的内部切割和旋转增强,然后输入到Swin UNETR编码器中作为输入。我们使用掩蔽体积嵌入、对比学习和旋转预测作为代理任务来学习输入图像的上下文表示),使用定制的自监督任务对Transformer编码器进行预训练。
-
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第1张图片](http://img.e-com-net.com/image/info8/911301125d184da69ec23896ad32d5c8.jpg)
具体来说,由于人体所描绘的解剖结构,人体在CT等放射图像中呈现自然一致的上下文信息。因此,代理任务被用来学习人体解剖学的基本模式。为此,本文从不同的身体组成(如头、颈、肺、腹和骨盆)提取了大量的补丁查询,以从各种解剖环境、器官、组织和形状中学习健壮的特征表示。
-
本文的框架使用对比学习,掩蔽体积嵌入和3D旋转预测作为训练前代理任务。对比学习用于区分不同身体组成的各种ROIs,而嵌入学习允许学习纹理、结构和掩蔽区域与周围环境的对应关系。旋转任务作为学习图像结构内容的机制,生成各种子卷,可用于对比学习。本文利用这些代理任务对从各种公开数据集获得的5050个CT图像集合进行预训练。
-
为了验证预训练的有效性,使用三维医学图像分割作为下游任务,并将其重新定义为一维序列到序列的预测任务。为此,我们利用Swin UNETR编码器与分层特征编码和移位窗口,以四种不同分辨率提取特征表示。然后将提取的表示连接到一个基于CNN的解码器。在解码器的末端附加分割头,用于计算最终的分割输出。使用预先训练的权重对Swin UNETR进行微调,这两个公共基准分别是医疗分割十项全能(MSD)和颅外Vault (BTCV)。本文模型目前在各自的公开测试排行榜上是最先进的。
本文创新点:
- 设计了一种新的自监督学习框架,该框架具有定制的代理任务,用于CT图像数据集的预训练。为此,本文提出了一种新的基于3DTransformer的架构,称为Swin UNETR,由一个编码器组成,该编码器可以在多个分辨率下提取特征表示,并用于预训练。
- 本文使用提出的编码器和代理任务,对来自各种任务的5050个公开可用CT图像进行了成功的预训练。这产生了一个强大的预训练模型,具有鲁棒的特征表示,可用于各种医学图像分析下游任务。
- 通过对预先训练的Swin UNETR在MSD和BTCV两个公共基准上进行微调,本文验证了拟议框架的有效性,并在两个数据集的测试排行榜上取得了最先进的成绩。
相关工作
利用Transformer进行医学图像分割
- Vision Transformer首次用于分类任务是在自然语言处理中用于序列到序列的建模。从整个输入序列中聚合信息的自注意机制首先获得了相当的性能,然后比先前的卷积体系结构技术(如ResNet或U-Net)的性能更好。
- 最近,基于Transformer的网络被提出用于医学图像分割。在这些开创性的工作中,Transformer块要么被用作瓶颈特征编码器,要么被用作卷积层之后的附加模块,从而限制了Transformer的空间上下文优势的开发。与以往的工作使用Transformer作为辅助编码器相比,本文提出利用Transformer来嵌入高维体积医学图像,这允许更直接的3D补丁编码和位置嵌入。
- 大多数医学图像分析任务,如分割,都需要从多尺度特征进行密集推断。基于跳跃式连接的体系结构,如UNet和金字塔网络被广泛采用,以利用层次结构的特性。然而,单一补丁大小的Vision Transformer,虽然在自然图像应用中成功,但在高分辨率和高维体积图像中是难以处理的。为了避免计算自注意在尺度上的二次溢出,Swin Transformer被提出通过移动窗口机制构造分层编码。
- 最近的工作如Swin UNet和DS-TransUNet利用Swin Transformer的优点进行二维分割,取得了良好的性能。在上述方法的基础上,我们在更广泛的医学图像分割场景中借鉴了三维解剖学,并结合了层次和体积的上下文。
医学图像分析的预训练
- 在医学图像分析中,先前对标记数据进行预训练的研究表明迁移学习可以提高性能。然而,为医学图像生成注释是昂贵和耗时的。自监督学习的最新进展提供了利用无标记数据的希望。
- 自监督表示学习通过设计文本前任务来构建特征嵌入空间,例如解决拼图游戏。另一个常用的前文本任务是记忆医学图像的空间上下文,其动机是图像恢复。这一思想被推广到嵌入任务中,通过预测原始图像补丁来学习视觉表示。类似的重构空间上下文的努力被表述为解决魔方问题、随机旋转预测和对比编码。
- 与这些努力不同的是,本文预训练框架是通过组合的预文本任务进行模拟训练的,为3D医学成像数据量身定制,并利用基于Transformer的编码器作为强大的特征提取器。
Swin UNETR
Swin UNETR包括一个Swin Transformer编码器,该编码器直接利用3D补丁,并通过不同分辨率的跳跃式连接连接到基于CNN的解码器。
网络架构模型:
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第2张图片](http://img.e-com-net.com/image/info8/9ba641f51d444531afa78ad114c65764.jpg)
当给定一个输入,首先将数据切割为多个小的体素块,将每个体素块进行两次不同的数据增强后分别输入到网络编码器中,计算自监督损失。
三维分割网络是 U-Net 结构,网络的编码器为 Swin Transformer,解码器为卷积网络。
编码器部分首先是一个Patch Partition层来创建一个3D的token序列,通过线性嵌入层投影到C维空间中,为了对token交互进行有效建模,输入卷划分到不重叠的窗口中,并在每个区域内计算局部自注意。编码器使用patch大小为2x2x2,特征维度2x2x2x1=8(即单输入通道CT图像)和C=48维嵌入空间,编码器的整体架构由4级构成,每一级包括两个Transformer块(L=8),在每个阶段之间,使用一个Patch Merge层来降低两倍的分辨率。
Swin UNETR的编码器通过跳跃连接在每个分辨率上连接到基于CNN的解码器,为下游任务(如分段)创建一个“U型”网络。将每个阶段提取的表示形式输入到一个残块中,该残块由两个后归一化的3x3x3卷积层组成,实例归一化。然后使用反卷积层对每个阶段处理过的特征进行上采样,并与前一阶段处理过的特征进行连接。将连接的特征输入到具有上述描述的残块中。
对于分割,将编码器的输出(即Swin Transformer)与经过处理的输入体积特征连接起来,并将它们输入到一个残块中,然后是最后一个具有适当激活函数(即softmax)的1x1x1卷积层,以计算分割概率。
预训练时在编码器的输出端链接了三个任务头,微调时去掉三个任务头,添加分割头,微调全部网络参数。
Inpainting 预测头为一个卷积层;旋转头和对抗头为 MLP 。
Inpainting 损失为 L1 损失;旋转损失为交叉熵,对抗损失是InfoNce。
Inpainting 从二维扩展到了三维; 旋转是沿 Z 轴旋转。
三个损失组合成了混合损失来指导训练,三个损失之间的权重均为 1。
编码器
假设编码器的输入的子卷X属于RHxWxDxS,一个patch的分辨率为()的数据维度为:H’x
W’xD’xS。
- Patch Partition层:创建一个3D令牌序列,大小为H/H’xW/W’xD/D’,通过线性嵌入层投影到C维空间中,为了对令牌交互进行有效建模,将输入卷划分到不重叠的窗口中,并在每个区域内计算局部自注意。
- 具体来说,在第一层使用一个MxMxM大小的窗口,最终将一个3D令牌序列划分成H’/MxW’/MxD’/M大小的窗口,在随后的层中使用我们用(M/2,M/2,M/2)体素来移动分区的窗口。移位的开窗机构如下图所示:
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第3张图片](http://img.e-com-net.com/image/info8/9f0cf4c105534d0f82882d89ba6d44eb.jpg)
- l和l+1层的计算输出公式如下:
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第4张图片](http://img.e-com-net.com/image/info8/8394dd628c884a4ab9091e5ad4343fd4.jpg)
其中W-MSA和SW-MSA分别表示规则分区和窗口分区的多头自注意模块,z^l是W-MSA和SW-MSA的输出,LN和MLP分别表示层归一化和多层感知器(见图2)。采用了3D循环移位来进行移位窗口的高效批量计算:![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第5张图片](http://img.e-com-net.com/image/info8/f1a3f13778f1434fabf8d1b42bad0719.jpg)
其中Q、K、V分别表示查询、键和值,d为查询和键的大小。
- 编码器使用patch大小为2x2x2,特征维度2x2x2x1=8(即单输入通道CT图像)和C=48维嵌入空间,此外,编码器的整体架构由4级构成,每一级包括两个Transformer块(L=8),在每个阶段之间,使用一个Patch Merge层来降低两倍的分辨率,阶段1是一个线性嵌入层和Transformer块组成,维持令牌的数量为H/2xW/2xD/2,一个Patch Merge将分辨率为2x2x2的补丁分组,并将它们连接起来,形成一个4C维的特征嵌入。然后使用线性层通过将尺寸降低到2C来降低分辨率。相同的过程仍在第二阶段,第三阶段和第四阶段中:H/4xW/4xD/4,H/8xW/8xD/8,H/16xW/16xD/16,编码器在不同阶段的层次表示用于下游任务,如多尺度特征提取的分割。
解码器
Swin UNETR的编码器通过跳跃式连接在每个分辨率上连接到基于CNN的解码器,为下游任务(如分段)创建一个“U型”网络。
具体来说,提取编码器中每个阶段i (i属于0,1,2,3,4)以及瓶颈(i=5)的输出序列表示形式,并将其重塑为大小为H /2ix W /2ix D/ 2i的特征。然后将每个阶段提取的表示形式输入到一个残块中,该残块由两个后归一化的3x3x3卷积层组成,实例归一化。然后使用反卷积层对每个阶段处理过的特征进行上采样,并与前一阶段处理过的特征进行连接。将连接的特征输入到具有上述描述的残块中。对于分割,将编码器的输出(即Swin Transformer)与经过处理的输入体积特征连接起来,并将它们输入到一个残块中,然后是最后一个具有适当激活函数(即softmax)的1x1x1卷积层,以计算分割概率(参见图2所示的体系结构细节)。
预训练
用多个代理任务对Swin UNETR编码器进行了预训练,并用多目标损耗函数对其进行了描述,自监督表示学习的目标是对人体感兴趣区域(ROI)感知信息进行编码。受之前关于上下文重建和对比编码的工作的启发,本文开发了三个代理任务用于医学图像表示学习。
在预训练期间,另外三个投影头附加到编码器上。此外,下游任务,例如分割,微调完整的Swin UNETR模型,去掉投影头。在训练中,子体积是裁剪的随机区域的体积数据。然后,随机数据增强与随机旋转和切割应用于一个小批内的每个子体积两次,得到每个数据的两个视图。
Masked Volume Inpainting
Masked Volume Inpainting是由先前专注于2D图像的工作所激发的。我们将其扩展到三维领域,以展示其在体医学图像表示学习中的有效性。
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第6张图片](http://img.e-com-net.com/image/info8/f0d3fe569e5c483a9d37efd8d3092f8e.jpg)
图像旋转
为了简单起见,采用沿z轴的0、90、180、270旋转的R级。采用MLP分类头来预测旋转类别的最大概率。
旋转预测任务使用交叉熵损失:
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第7张图片](http://img.e-com-net.com/image/info8/77799a4f81c740d994d3fc66891f0ebd.jpg)
对比编码
自监督对比编码在转移到下游任务时,在视觉表征学习方面表现出很好的性能。在给定一批增强子卷的情况下,对比编码通过最大化正对(来自同一子卷的增强样本)之间的互信息,同时最小化负对(来自不同子卷的视图)之间的互信息,允许更好的表示学习。对比编码是通过在Swin UNETR编码器上附加一个线性层来获得的,该层将每个增强子体积映射到一个潜在表示v,使用余弦相似度作为定义的编码表示的距离测量。形式上,对vi和vj之间的三维对比编码损失定义为:
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第8张图片](http://img.e-com-net.com/image/info8/d76b72c5794b4193b95e281eef120999.jpg)
损失函数
通过使用掩蔽体嵌入、3D图像旋转和对比编码的多个预训练目标训练Swin UNETR的编码器来最小化总损耗函数,如下所示:

通过网格搜索超参数优化,得到了λ1=λ2=λ3=1的最优值。
实验
数据集
- 预训练数据集:共有5个公共CT数据集,包含5050个受试者,用于构建训练前数据集。胸部、腹部和头颈的3D体积分别为2018、1520和1223。收集资料和来源详情载于补充材料。在预训练阶段,不会从这些数据集中利用现有的注释或标签。
- BTCV: BTCV (Beyond The Cranial V ault)腹部挑战数据集包含30名患者CT扫描,13个器官在V anderbilt大学医学中心放射科医生的监督下由翻译人员注释。每次门静脉增强期CT扫描共80 ~ 225片,512 ~ 512像素,片厚1 ~ 6mm。多器官分割问题被表述为13类分割任务:Spl:脾,RKid:右肾,LKid:左肾,Gall:胆囊,Eso:食管,Liv:肝脏,Sto:胃,Aor:主动脉,IVC:下腔静脉,V eins:门静脉和脾静脉,Pan:胰腺,AG:左、右肾上腺。
- MSD:医疗分割十项全能(MSD)数据集由来自不同器官和图像模式的10个分割任务组成。这些任务设计的特点是跨越医学图像的困难,如小训练集、不平衡类、多模态数据和小对象。因此,MSD挑战可以作为评价医学图像分割方法可泛化性的综合基准。
实现细节
对于训练前的任务,(1)掩模体积嵌入:ROI下降率设置为30%;丢弃的区域是随机生成的,它们的总和达到体素的总数量;(2)三维对比编码:采用512特征尺寸作为嵌入尺寸;(3)旋转预测:旋转度可配置为0、90、180、270。使用AdamW优化器和500次迭代的热身余弦调度程序来训练模型。
预训练实验使用每个GPU的批处理大小为4(使用96x96x96的补丁),初始学习率为4e-4,动量为0.9,衰减为1e-5。本文模型在PyTorch和MONAI中实现。五倍交叉验证策略用于训练所有BTCV和MSD实验的模型。在每个折叠中选择最好的模型,并集成它们的输出进行最终的分割预测。
详细的训练超参数微调BTCV和MSD任务可以在补充材料中找到。所有模型都在NVIDIA DGX-1服务器上训练。
评价指标
Dice系数和豪斯多夫距离95%
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第9张图片](http://img.e-com-net.com/image/info8/b8b889c69a0740fb852f8fbe5d3ea10b.jpg)
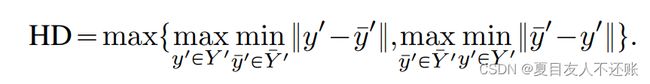
实验结果
BTCV多器官分割挑战
广泛地比较了模型的基准和基线。公布的排行榜评价如表1所示。与其他提交的最佳作品相比,Swin UNETR的表现最好。得到了最先进的Dice为0.908,在13个器官上分别比排名第二、第三和第四的基线平均高出1.6%、2.0%和2.4%。对于较小的器官,可以特别观察到明显的改善,如脾和门静脉的3.6%,比之前的先进方法,胰腺1.6%,肾上腺3.8%。其他器官也有中度改善。
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第10张图片](http://img.e-com-net.com/image/info8/49c58bc299794c8caebe3a250a5efe85.jpg)
图4中的代表性样本表明Swin UNETR成功地识别了器官细节。本文方法检测到胰腺尾部(第1行)和图4门静脉中的分支(第2行),其中其他方法在每个组织的分割部分。此外,我们的方法在肾上腺分割方面有明显的改善(第3行)。
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第11张图片](http://img.e-com-net.com/image/info8/702c4add44b24aa995cdcd5f2db71a22.jpg)
MSD分割结果
每项任务的整体MSD结果和挑战排行榜的排名如表2所示。该Swin UNETR在Task01脑瘤、Task06肺、Task07胰腺和Task10结肠中达到了最先进的性能。Task02心脏,Task03肝脏,Task04海马,Task05前列腺,Task08肝血管和Task09脾脏的结果是相似的。总的来说,Swin UNETR在所有10个任务中呈现了最佳的平均Dice(78.68%),并在MSD排行榜中排名第一。
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第12张图片](http://img.e-com-net.com/image/info8/8c529a6bf1b24c54bd3599d4b6270d9b.jpg)
多个任务的详细数量如表3所示。
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第13张图片](http://img.e-com-net.com/image/info8/70a830e7ac59473aa83de4cea54c7100.jpg)
定性可视化可以在图5中观察到。Swin UNETR与自监督预训练在CT任务中显示了更好的视觉分割结果。预先训练的权重仅用于微调CT任务,包括肝脏、肺、胰腺、肝血管、脾脏和结肠。对于MRI任务:脑瘤,心脏,海马,前列腺,由于CT和MRI图像之间的领域差距,实验从零开始训练。由于篇幅所限,在补充材料中给出了剩余三个MRI任务的MSD测试基准。
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第14张图片](http://img.e-com-net.com/image/info8/5b0b71d89dbb490184ba854670e57c93.jpg)
消融实验
预训练效果
所有使用预训练模型的MSD CT任务与从零开始训练的对比如图6所示。
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第15张图片](http://img.e-com-net.com/image/info8/5950e9ff90c84ab89bf5eb977304fb55.jpg)
Task03肝脏、骰子的改善明显,分别为77.77%和75.27%。Task08肝V血管达到68.52%对64.63%。Task10 Colon的改进最大,从34.83%提高到43.38%。
Task07胰腺和Task09脾脏的改善率分别为67.12% ~ 67.82%和96.05% ~ 97.32%。
减少手工标记的工作量
图7展示了使用BTCV数据集子集进行微调的比较结果。用了10%的有标记的数据,训练前权重的实验与从零开始的训练相比,获得了大约10%的改进。在使用所有标记数据时,自监督预训练的平均Dice提高了1.3%。使用预训练的Swin UNETR在60%的数据下可以实现整个数据集从头学习的骰子数83.13。图7表明,本文方法可以为BTCV任务减少至少40%的注释工作量。
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第16张图片](http://img.e-com-net.com/image/info8/70245096507e441cb3edfb6f4d2fcb46.jpg)
预训练数据集大小
对BTCV数据集进行器官方面的研究,使用预先训练的较小的未标记数据的权重。在图8中,预训练100、3000和5000次扫描的微调结果。观察到Swin UNETR相对于训练的CT扫描总数是稳健的。如图8所示,提出的模型可以从更大的预训练数据集中受益,且未标记数据的大小不断增加。
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第17张图片](http://img.e-com-net.com/image/info8/d1945c3b6af9404b8f6849801dd8bd4f.jpg)
自监督目标的效能
对不同自监督目标组合的预培训进行了实证研究。如表4所示,在BTCV测试集上,通过inpainting使用预训练的权值在单个任务建模中取得了最高的改进。
在配对任务中,inpainting和contrast learning的Dice为84.45%,Hausdorff Distance (HD)为24.37。总的来说,使用所有的代理任务可以获得84.72%的最佳Dice。
![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练_第18张图片](http://img.e-com-net.com/image/info8/b0febc4b88674920934ab52146f58135.jpg)
讨论与局限性
在MSD和BTCV数据集的测试排行榜上的最新结果验证了所提出的自监督学习框架在利用大量可用医学图像而不需要注释工作方面的有效性。随后,对预训练的Swin UNETR模型进行微调,与从头随机初始化权重训练相比,可以获得更高的精度,提高收敛速度,并减少注释工作量。本文框架是可伸缩的,可以通过更多的代理任务和扩展转换轻松地进行扩展。同时,经过预训练的编码器可以用于各种医学图像分析任务的迁移学习,如分类和检测。
在MSD胰腺分割任务中,经过预训练权重的Swin UNETR算法的性能优于AutoML算法,如DiNTS和C2FNAS,这两种算法专为在同一分割任务中搜索最优网络架构而设计。目前,Swin UNETR仅使用CT图像进行预训练,实验在直接应用于其他医学成像模式(如MRI)时还没有证明足够的可移植性。这主要是由于明显的领域差距和不同数量的输入通道特定于每种模式。因此,这是未来工作中应该研究的一个潜在方向。
结论
在这项工作中,提出了一个新的框架的自我监督预训练三维医学图像。受到按比例合并特征图的启发,通过将Transformer编码的空间表示形式利用到基于卷积的解码器中,构建了Swin UNETR。通过提出第一个基于Transformer的3D医学图像预训练,利用Swin Transformer编码器的能力进行微调分割任务。Swin UNETR具有自监督的预训练,在BTCV多器官分割挑战和MSD挑战中实现了最先进的性能。特别是,通过结合多个公开数据集和解剖roi的多样性,展示了5050卷的大规模CT预训练。