ARM 64 协程切换上下文的汇编代码解读
ARM 64协程切换上下文的汇编代码解读
贺志国
2023.8.11
在ARM 64位架构中,有一组通用寄存器(General Purpose Registers)、一组浮点寄存器(Floating-point Registers)和一组特殊寄存器(Special Registers)。
通用寄存器(x0-x30)是用于存储数据和计算结果的寄存器。这些寄存器可以用于存储整数、指针和地址等数据。其中,寄存器x0-x7有特殊用途,例如x0通常用于存储函数的返回值,x1-x7用于传递函数参数。
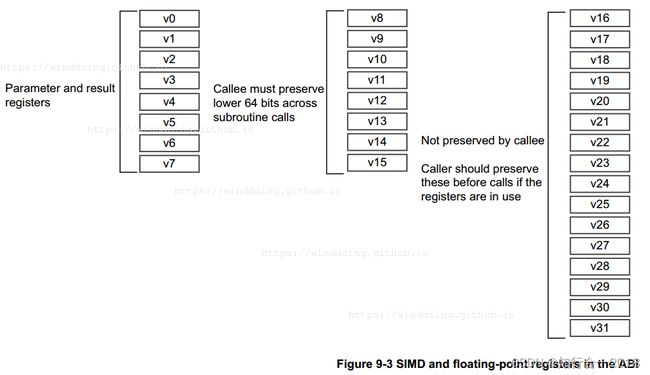
与通用寄存器类似,浮点寄存器也有一定的编号规律。在ARM 64位架构中,浮点寄存器从d0到d31,共有32个。这些寄存器可以用于存储和进行浮点数计算。ARM 64位架构支持SIMD(Single Instruction Multiple Data)指令集,用于高效地进行向量化计算。在汇编语言中,可以使用特定的寄存器名称来引用浮点寄存器,例如d0表示浮点寄存器0,d8表示浮点寄存器8等。在编写ARM 64位汇编代码时,可以使用这些浮点寄存器进行浮点数的加载、存储和运算操作。
特殊寄存器包括:
程序计数器(Program Counter,PC):存储下一条将要执行的指令的地址。
栈指针(Stack Pointer,SP):指向当前栈的顶部。
链接寄存器(Link Register,LR):存储函数调用前的返回地址。
状态寄存器(Condition Flags):存储比较和算术操作的结果。
程序状态寄存器(Program Status Register,PSR):存储处理器的运行状态和控制位。
上述寄存器在汇编语言中通过特定的寄存器名称来引用,例如x0代表通用寄存器0,d8表示浮点寄存器8,sp代表栈指针寄存器,pc代表程序计数器等。
以下是一段ARM 64协程切换上下文的汇编代码:
.text; ; 以下是代码段
.align 4 ; 按2^4=16字节的倍数对齐地址,空隙默认用0来填充
.globl ctx_swap ; 全局入口函数是ctx_swap
; 以下单个寄存器和内存变量的空间均为64位(8字节)
ctx_swap: ; 定义全局函数ctx_swap
stp x0, x30, [sp,#-16]! ; 将x0, x30的值存储到sp - 16的地址上,并且执行sp -= 16
stp d8, d9, [sp,#-16]! ; 将d8, d9的值存储到sp - 16的地址上,并且执行sp -= 16
stp d10, d11, [sp,#-16]! ; 将d10, d11的值存储到sp - 16的地址上,并且执行sp -= 16
stp d12, d13, [sp,#-16]! ; 将d12, d13的值存储到sp - 16的地址上,并且执行sp -= 16
stp d14, d15, [sp,#-16]! ; 将d14, d15的值存储到sp - 16的地址上,并且执行sp -= 16
stp x1, x19, [sp,#-16]! ; 将x1, x19的值存储到sp - 16的地址上,并且执行sp -= 16
stp x20, x21, [sp,#-16]! ; 将x20, x21的值存储到sp - 16的地址上,并且执行sp -= 16
stp x22, x23, [sp,#-16]! ; 将x22, x23的值存储到sp - 16的地址上,并且执行sp -= 16
stp x24, x25, [sp,#-16]! ; 将x24, x25的值存储到sp - 16的地址上,并且执行sp -= 16
stp x26, x27, [sp,#-16]! ; 将x26, x27的值存储到sp - 16的地址上,并且执行sp -= 16
stp x28, x29, [sp,#-16]! ; 将x28, x29的值存储到sp - 16的地址上,并且执行sp -= 16
mov x3, sp ; 将sp的值传送到x3
str x3, [x0] ; 将x3的值存储到x0的地址上
ldr x3, [x1] ; 从x1的地址里取一个64位数存储到x3中
mov sp, x3 ; 将x3的值传送到sp
ldp x28, x29, [sp] ; 从sp的地址里取出2个64位的数(共16字节),分别存入x28, x29
ldp x26, x27, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入x26, x27,并且执行sp += 16
ldp x24, x25, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入x24, x25,并且执行sp += 16
ldp x22, x23, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入x22, x23,并且执行sp += 16
ldp x20, x21, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入x20, x21,并且执行sp += 16
ldp x1, x19, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入x1, x9,并且执行sp += 16
ldp d14, d15, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入d14, d15,并且执行sp += 16
ldp d12, d13, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入d12, d13,并且执行sp += 16
ldp d10, d11, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入d10, d11,并且执行sp += 16
ldp d8, d9, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入d8, d9,并且执行sp += 16
ldp x0, x30, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入x0, x30,并且执行sp += 16
add sp, sp, #16 ; sp += 16
ret ; 从当前函数返回,寻找x30上的地址并执行其中的指令
这是一个上下文切换函数,它将当前寄存器值保存到一个内存栈中,然后从另一个内存栈中恢复之前保存的寄存器值并返回。
以下这段代码是将当前的寄存器x0, x30, d8, d9, d10, d11, d12, d13, d14, d15, x1, 19, x20, x21, x22, x23, x24, x25, x26, x27, x28, x29的值保存到内存栈中。
stp x0, x30, [sp,#-16]! ; 将x0, x30的值存储到sp - 16的地址上,并且执行sp -= 16
stp d8, d9, [sp,#-16]! ; 将d8, d9的值存储到sp - 16的地址上,并且执行sp -= 16
stp d10, d11, [sp,#-16]! ; 将d10, d11的值存储到sp - 16的地址上,并且执行sp -= 16
stp d12, d13, [sp,#-16]! ; 将d12, d13的值存储到sp - 16的地址上,并且执行sp -= 16
stp d14, d15, [sp,#-16]! ; 将d14, d15的值存储到sp - 16的地址上,并且执行sp -= 16
stp x1, x19, [sp,#-16]! ; 将x1, x19的值存储到sp - 16的地址上,并且执行sp -= 16
stp x20, x21, [sp,#-16]! ; 将x20, x21的值存储到sp - 16的地址上,并且执行sp -= 16
stp x22, x23, [sp,#-16]! ; 将x22, x23的值存储到sp - 16的地址上,并且执行sp -= 16
stp x24, x25, [sp,#-16]! ; 将x24, x25的值存储到sp - 16的地址上,并且执行sp -= 16
stp x26, x27, [sp,#-16]! ; 将x26, x27的值存储到sp - 16的地址上,并且执行sp -= 16
stp x28, x29, [sp,#-16]! ; 将x28, x29的值存储到sp - 16的地址上,并且执行sp -= 16
以下这段代码是将保存了当前寄存器值快照的内存栈顶地址的寄存器sp保存到当前上下文中(寄存器x0指向的内存地址)
mov x3, sp ; 将sp的值传送到x3
str x3, [x0] ; 将x3的值存储到x0的地址上
以下这段代码是从新的上下文中(寄存器x1指向的内存地址)加载内存栈顶地址,并将其保存到寄存器sp。
ldr x3, [x1] ; 从x1的地址里取一个64位数存储到x3中
mov sp, x3 ; 将x3的值传送到sp
以下这段代码是从之前存储在内存栈中的寄存器值快照恢复到寄存器x0, x30, d8, d9, d10, d11, d12, d13, d14, d15, x1, x19, x20, x21, x22, x23, x24, x25, x26, x27, x28, x29中(反方向恢复)。
ldp x28, x29, [sp] ; 从sp的地址里取出2个64位的数(共16字节),分别存入x28, x29
ldp x26, x27, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入x26, x27,并且执行sp += 16
ldp x24, x25, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入x24, x25,并且执行sp += 16
ldp x22, x23, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入x22, x23,并且执行sp += 16
ldp x20, x21, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入x20, x21,并且执行sp += 16
ldp x1, x19, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入x1, x9,并且执行sp += 16
ldp d14, d15, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入d14, d15,并且执行sp += 16
ldp d12, d13, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入d12, d13,并且执行sp += 16
ldp d10, d11, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入d10, d11,并且执行sp += 16
ldp d8, d9, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入d8, d9,并且执行sp += 16
ldp x0, x30, [sp,#16]! ; 从sp + 16的地址里取出2个64位的数(共16字节),分别存入x0, x30,并且执行sp += 16
可能有人会问,寄存器有很多,为什么要保留以下这些寄存器:x0, x30, d8, d9, d10, d11, d12, d13, d14, d15, x1,x19, x20, x21, x22, x23, x24, x25, x26, x27, x28, x29 ?根据博客:ARMv8-aarch64 寄存器和指令集一文的介绍,x0,x1用于保存函数的调用参数,x30保存当前函数的返回地址,即当前函数调用结束后下一条需要执行的指令地址。x19, x20, x21, x22, x23, x24, x25, x26, x27, x28, x29是CPU上下文切换时,被调用者必须保存的寄存器。d8, d9, d10, d11, d12, d13, d14, d15是128位浮点寄存器v8, v9, v10, v11, v12, v13, v14, v15的低64位(例如,128位浮点寄存器v8分高64位和低64位,其中低64位使用d8表示),被调用者在协程切换时必须保留上述浮点寄存器。也就是说,根据ARMv8-aarch64指导手册,在切换协程时,要将调用参数寄存器x0, x1(实际上,x0保存的是当前CPU寄存器快照值在内存栈的栈顶地址,x1保存的是原来CPU寄存器快照值在内存栈的栈顶地址),返回地址寄存器x30, 被调用者用到的临时通用寄存器x19, x20, x21, x22, x23, x24, x25, x26, x27, x28, x29,以及被调用者用到的临时浮点寄存器d8, d9, d10, d11, d12, d13, d14, d15当前的快照值全部保存到内存栈,同时从内存栈取出之前保存的上述寄存器快照值,从而顺利完成协程上下文的切换。