医疗知识图谱构建
In this article, you will learn about one of the most important applications of medical word embeddings: a machine learning model that identifies medical entities (as drug names or diseases) in text.
在本文中,您将了解医学单词嵌入的最重要应用之一:一种机器学习模型,该模型可识别文本中的医学实体(如药物名称或疾病 )。
As seen on our previous article, word embeddings can be used to obtain numerical representations of words that capture syntactic and semantic information. If these embeddings are trained on medical text, they give us a good vector representation of medical entities: words in text that have a medical meaning. For instance, “Lyme borreliosis” is a medical entity that belongs to the class of diseases, and “amoxicillin” is an entity in the class of drugs (see figure below). The process of identifying entity types in text is known in the Natural Language Processing (NLP) community as Named-Entity Recognition (NER).
正如我们在前一篇文章中看到的,单词嵌入可用于获取捕获语法和语义信息的单词的数字表示。 如果将这些嵌入物训练在医学文本上,它们将为我们提供医学实体的良好矢量表示:具有医学意义的文本中的单词。 例如,“ 莱姆包柔螺旋体”是属于类疾病的医学实体,而“阿莫西林”是在类药物 (参见下图)的实体。 在自然语言处理(NLP)社区中,识别文本中的实体类型的过程称为命名实体识别(NER) 。
In practice, what the NER does is to predict a label for each word of a given sentence. To formalise the output of the NER model, we can tag each word of the previous example as it follows:
在实践中,NER所做的是为给定句子的每个单词预测一个标签。 为了形式化NER模型的输出,我们可以标记上一个示例的每个单词,如下所示:
Lyme → B-Disease
莱姆→ B病
borreliosis → I-Disease
疏螺旋 体病 → I病
can → O
可以→ O
be → O
是→ O
treated → O
处理→ O
with → O
与→ O
antibacterials → B-TherapeuticClass
抗菌药物→ B-治疗类
This is known as the IOB tagging format (for Inside, Outside, Begin). Disease and TherapeuticClass indicate entity types. B- indicates the beginning of an entity (the first word of an entity composed of several words, as “Lyme borreliosis”); I- indicates that the previous entity has not ended yet; and O tell us that a given word is not a medical entity.
这称为IOB标记格式 (对于Inside,Outside , Begin )。 Disease和TherapeuticClass指示实体类型。 B-表示实体的开头(由多个单词组成的实体的第一个单词,称为“ 莱姆病”) ; I-表示先前的实体尚未结束; O告诉我们,给定的单词不是医学实体。
Common NER models are able to identify non-medical entity types as “person” or “location”. At Posos, thanks to a thorough annotation campaign of hundreds of thousand of medical extracts, we are able to detect entities that are relevant to medical practitioners.
普通的NER模型能够将非医疗实体类型识别为“人员”或“位置” 。 在Posos ,得益于十万种医学摘要的全面注释活动,我们能够检测与执业医师相关的实体。
Some of the entities that we detects at Posos are
我们在Posos中检测到的一些实体是
Drugs (e.g., paracetamol; aspirine)
药物 ( 例如 对乙酰氨基酚 ; 阿司匹林 )
Therapeutic classes (e.g., antihistamine; antibiotic)
治疗类别 ( 例如 抗组胺药 ; 抗生素 )
Diseases or symptoms (e.g., acute pancreatitis; Alzheimer’s disease)
疾病或症状 ( 例如 急性胰腺炎 ; 阿尔茨海默氏病)
Doses (e.g., 500 mg/l)
剂量 ( 例如 500 mg / l )
Dose forms (e.g., capsules; liquid solution)
剂量形式 ( 例如 胶囊 ; 液体溶液 )
Routes of administration (e.g., intradermal; sublingual)
给药途径 ( 例如 皮内 ; 舌下 )
Side or adverse effects (e.g., fever; headache)
副作用或副作用 ( 例如 发烧 , 头痛 )
Population (e.g., age, weight)
人口 ( 例如年龄,体重)
From a machine learning’s point of view, the NER algorithm can be seen as a classification problem for every word of the input text (all the entity types plus an extra class O for non medical words). The complexity of the task comes from the fact that the classification of a word depends on its context in text. For instance, the word “Parkinson” should be tagged as Disease in the sentence “A 60 years old patient with Parkinson’s disease”, but as O in “Mr. Parkinson is 60 years old”.
从机器学习的角度来看,NER算法可以看作是输入文本中每个单词的分类问题(所有实体类型加上非医学单词的额外类别O )。 任务的复杂性来自单词的分类取决于其在文本中的上下文这一事实。 例如,单词“ 帕金森”应该在句子“一名60岁的患者,帕金森氏病”被标记为疾病 ,但如“先生Ø 帕金森已经60岁了。
After identifying entity types in text, and in order to gain real knowledge about its content, we need to link the detected entities to entries on medical ontologies. This linking process allow us to know that “Lyme borreliosis” is a specific infectious disease that corresponds, for example, to the code A69.2 in the International Classification of Diseases, 10th Revision (ICD-10). The latter task is know as Named-Entity Linking (NEL) (see figure below).
在确定文本中的实体类型之后,为了获得有关其内容的真实知识,我们需要将检测到的实体链接到医学本体上的条目。 通过此链接过程,我们可以知道“ 莱姆病”是一种特定的传染病,例如,与《 国际疾病分类(第10版)》 (ICD-10)中的代码A69.2相对应。 后一项任务称为命名实体链接(NEL) (请参见下图)。
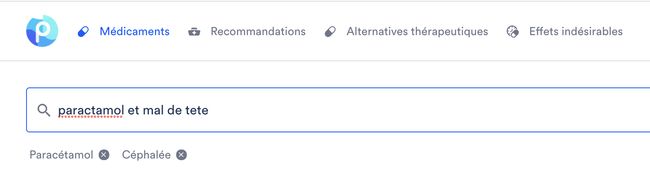
The NER and NEL tasks are very important for the Posos’ search engine, as they allow to filter documents by the detected medical entities in the query. This makes Posos resilient to typos or semantical variations of medical expressions (see the example below).
NER和NEL任务对于Posos的搜索引擎非常重要,因为它们允许通过查询中检测到的医疗实体过滤文档。 这使Posos可以抵抗医学表达的拼写错误或语义变化(请参见下面的示例)。
Now that we have a rough idea of how to identify medical entities from text in a two step process, we can describe with more details the main components of the NER and NEL algorithms currently used in the Posos’ search engine.
现在,我们对如何通过两步过程从文本中识别医疗实体有了一个大概的想法,我们可以更详细地描述Posos搜索引擎中当前使用的NER和NEL算法的主要组成部分。
NER和NEL的机器学习算法 (Machine learning algorithms for NER and NEL)
The NER algorithm that we implemented at Posos is a supervised learning model based on [Lample, 2016]. Supervised models require labeled or annotated data to learn. One drawback of supervised models is that, in general, the data annotation process is expensive and time consuming, as it requires expert manual annotation.
我们在Posos实施的NER算法是基于[ Lample ,2016]的监督学习模型。 监督模型需要标记或带注释的数据才能学习。 监督模型的一个缺点是,通常,数据注释过程昂贵且耗时,因为它需要专家手动注释。
At Posos, we launched an annotation campaign with healthcare professionals to manually annotate several hundred of thousands of medical extracts. The data is then transformed into the IOB tagging format and used to train a NER algorithm that relies on complex deep learning tools.
在Posos ,我们与医疗保健专业人员一起发起了注释活动,以手动注释数十万种医学提取物。 然后将数据转换为IOB标记格式,并用于训练依赖于复杂的深度学习工具的NER算法。
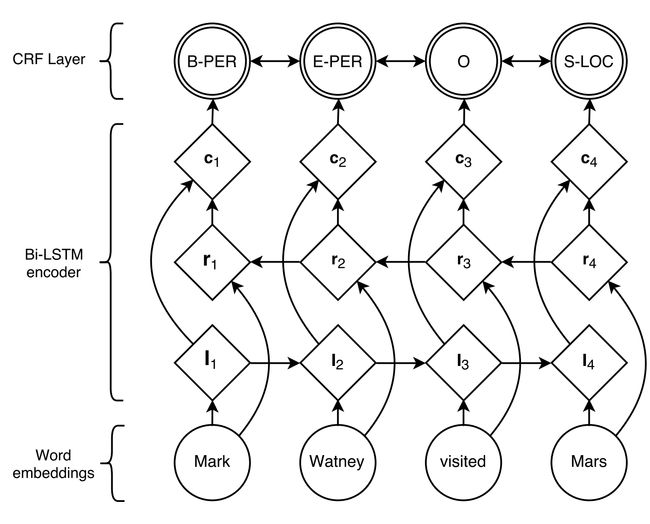
The main components of the NER algorithm are a bidirectional Long Short-Term Memory (bi-LSTM) layers [Huang, 2015] — a type of neural network that considers the context of tokens in text, i.e., the surrounding words — followed by a Conditional Random Field (CRF) [Lafferty, 2001], a probabilistic model that assigns a probability of transition between consecutive words — for example, the probability of finding the word “car” after “Parkinson’s” in medical text is much lower than the probability of finding the word “disease”.
NER算法的主要组成部分是双向长期短期记忆(bi-LSTM)层[ Huang ,2015] —一种神经网络,考虑文本中标记的上下文( 即周围的单词),后跟a条件随机场(CRF)[ Lafferty ,2001],一种概率模型,分配了连续单词之间的转移概率,例如,医学文本中“ 帕金森 ”之后找到“ 汽车 ”一词的概率远低于概率找到“ 疾病 ”一词。
To improve results, the algorithm takes as input data the syntax (embedding based on the character structure) and the semantics (our medical word embeddings) of words, as well as the position of tokens in the sentence (figure below).
为了提高结果,该算法将单词的语法(基于字符结构的嵌入)和语义(我们的医学单词嵌入 )以及标记在句子中的位置作为输入数据(下图)。
命名实体链接(NEL) (Named-Entity Linking (NEL))
As in the NER task, our NEL algorithm uses our custom medical word embeddings to create an embedding representation of medical entities. Because medical entities are often composed of several words, we rely on sentence embedding techniques. The simplest sentence embedding strategy is to average word embeddings of each word in the sentence. For example, imagine that we have the following 3-dimensional embeddings:
与NER任务一样,我们的NEL算法使用自定义医学单词嵌入来创建医学实体的嵌入表示。 由于医疗实体通常由多个单词组成,因此我们依赖于句子嵌入技术。 最简单的句子嵌入策略是对句子中每个单词的单词嵌入进行平均。 例如,假设我们具有以下3维嵌入:
Chronic → (0.1, 0.7, 0.6)
慢性 →(0.1,0.7,0.6)
Conjunctivitis → (0.5, 0.9, 0.2)
结膜炎 →(0.5,0.9,0.2)
Then, the sentence embedding (with the averaging strategy) of the disease “Chronic conjunctivitis”, will be:
然后,嵌入“慢性结膜炎”疾病的句子(采用平均策略)将为:
Chronic conjunctivitis → (.1, .7, .6)*.5 + (.5, .9, .2)*.5 = (0.3, 0.8, 0.4)
慢性结膜炎 →(.1,.7,.6)*。5 +(.5,.9,.2)*。5 =(0.3,0.8,0.4)
This strategy is not optimal as it assumes that all words in an entity are equally important. In the example, the word chronic is less important because many diseases can contain it (e.g, chronic pancreatitis, chronic meningitis, etc). Better sentence embeddings can be obtained if we consider the inverse document frequency (idf) of words, a weighting strategy that gives more importance to unfrequent words in a document corpus, as they are usually more informative. For example, if the weights of chronic and conjunctivitis are 0.2 and 0.8 respectively (in terms of their frequency in the ICD-10 ontology), then:
此策略不是最佳方法,因为它假定实体中的所有单词都同等重要。 在示例中,“慢性”一词的重要性较低,因为许多疾病都可以包含该疾病( 例如 , 慢性胰腺炎 , 慢性脑膜炎等)。 如果我们考虑单词的反文档频率(idf) ,可以获得更好的句子嵌入,这是一种加权策略,它对文档语料库中的不常见单词更加重视,因为它们通常更具信息性。 例如,如果慢性和结膜炎的权重分别为0.2和0.8(就其在ICD-10本体中的出现频率而言),则:
chronic conjunctivitis → (.1, .7, .6)*.2 + (.5, .9, .2)*.8 = (0.42, 0.86, 0.28)
慢性结膜炎 →(.1,.7,.6)*。2 +(.5,.9,.2)*。8 =(0.42,0.86,0.28)
Notice that this last entity embedding is really close to the embedding of the word conjunctivitis! This improves the performance of the NEL algorithm
注意,最后的实体嵌入实际上与结膜炎一词的嵌入非常接近! 这样可以提高NEL算法的性能
Once the sentence embedding strategy has been chosen, we can compute the embedding for every entity in our ontology and index them to perform fast linking on the detected entities in the NER step. For this, we use a nearest neighbour search on the entity embeddings: given an input embedding, this algorithm gives you the closest medical entity in terms of the cosine similarity between the query and the indexed entity embeddings.
一旦选择了句子嵌入策略,我们就可以计算本体中每个实体的嵌入,并对其进行索引,以在NER步骤中对检测到的实体执行快速链接。 为此,我们对实体嵌入使用最近邻搜索:给定输入嵌入后,该算法根据查询和索引实体嵌入之间的余弦相似度为您提供最接近的医学实体。
结论 (Conclusion)
Identifying medical entities in text is a crucial step in order to have a robust and reliable medical search engine. To accomplish this, Posos uses a NERL model that has been trained on hundred of thousand of expert-annotated data.
为了拥有健壮和可靠的医学搜索引擎,在文本中识别医学实体是至关重要的一步。 要做到这一点, Posos使用经过训练的专家标注数据的千百元NERL模型。
The automatic entity detection allow us to process the queries made by medical practitioners in the Posos’ search engine. The NERL is also used to tag our official sources, with the purpose to facilitate one of the main of Posos’ missions: finding the most pertinent documents to the questions made by medical practitioners.
自动实体检测使我们能够在Posos的搜索引擎中处理医生的查询。 NERL还用于标记我们的官方资料,目的是促进Posos的主要任务之一: 查找与医生所提问题最相关的文档 。
Now that we have a better idea of the functioning of the NERL algorithm, we can pass to the following step of the ML pipeline: finding the most pertinent documents of a query.
现在,我们对NERL算法的功能有了一个更好的了解,我们可以转到ML管道的以下步骤:查找查询中最相关的文档。
翻译自: https://medium.com/posos-tech/building-a-medical-search-engine-step-2-identifying-medical-entities-in-text-392560a6801d
医疗知识图谱构建