CMake: 检测并使用OpenMP的并行环境
CMake: 检测OpenMP的并行环境
- 导言
- OpenMP简介
- 项目结构
- CMakeLists.txt
- 相关源码
- 输出结果
导言
目前,市面上的计算机几乎都是多核机器,对于性能敏感的程序,我们必须关注这些多核处理器,并在编程模型中使用并发。OpenMP是多核处理器上并行性的标准之一。为了从OpenMP并行化中获得性能收益,通常不需要修改或重写现有程序。一旦确定了代码中的性能关键部分,例如:使用分析工具,我们就可以借助OpenMP通过预处理器指令,指示编译器为这些区域生成可并行的代码。
OpenMP简介
OpenMP(Open Multi-Processing)是一个用于共享内存多处理器计算机体系结构的并行编程模型。它提供了一套用于并行化应用程序的指令集和编程接口,使得开发者能够更容易地在多核处理器上实现并行计算。以下是关于OpenMP的一些基本介绍:
1. 并行性模型: OpenMP旨在简化并行程序的编写过程,它基于共享内存架构,其中多个处理器核心共享同一内存。每个核心都可以访问所有内存位置,因此通过共享数据来实现并行计算。
2. 指令注释: OpenMP使用一种通过在现有代码中插入特殊的指令注释来实现并行性的方法。这些指令告诉编译器在代码中的哪些部分可以并行执行,以及如何在并行执行期间处理共享的数据。
3. 线程级并行: OpenMP将任务分解成多个线程,每个线程在不同的处理器核心上运行。每个线程都可以独立地执行指定的任务,这样可以充分利用多核处理器的计算能力。
4. 并行语法: OpenMP使用预处理器指令、函数注释以及库函数来实现并行性。可以通过在代码中插入特定的编译器指令来标识需要并行执行的代码块。
5. 数据共享与同步: 在多线程并行计算中,共享数据的访问需要特别注意。OpenMP提供了一些机制,如原子操作和临界段,以确保数据的正确共享和同步。
6. 跨平台: OpenMP支持许多不同的操作系统和编译器,使得开发者可以在各种平台上使用相同的并行代码。
7. 编译器支持: 大多数现代编译器都支持OpenMP,并可以通过在编译时启用OpenMP选项来生成并行代码。
8. 灵活性: OpenMP提供了不同级别的并行性,从单一的for循环并行到更复杂的任务并行。
9. 用途广泛: OpenMP适用于许多领域,包括科学计算、数据分析、图像处理等,使得在多核处理器上提高应用程序性能变得更加简单。
总之,OpenMP是一个用于共享内存并行编程的强大工具,它通过为开发者提供简单且高效的方式来实现多核处理器上的并行计算,帮助优化性能并加速应用程序的执行。
项目结构
.
├── CMakeLists.txt
├── test_no_openmp.cpp
└── test_openmp.cpp
为了窥探使用OpenMP与不使用OpenMP之间的差异性,项目中新建了两个进程以验证其性能,具体性能表现参考最后一部分的输出结果。
项目地址:
https://gitee.com/jiangli01/tutorials/tree/master/cmake-tutorial/chapter3/04
CMakeLists.txt
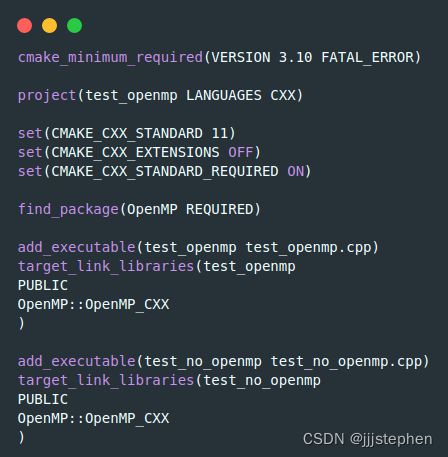
find_package(OpenMP REQUIRED)
调用find_package来搜索OpenMP。
add_executable(example example.cpp)
target_link_libraries(example
PUBLIC
OpenMP::OpenMP_CXX
)
链接到FindOpenMP模块提供的导入目标。
相关源码
test_openmp.cpp
#include test_no_openmp.cpp
#include 输出结果
$ mkdir -p build
$ cd build
$ cmake ..
$ cmake --build .
$./test_openmp
number of available processors: 16
number of threads: 16
we will form sum of numbers from 1 to 1000000000
sum: 500000000500000000
elapsed wall clock time: 0.15193 seconds
$./test_no_openmp
torials/cmake-tutorial/chapter3/04/build/test_openmp
number of available processors: 16
number of threads: 16
we will form sum of numbers from 1 to 1000000000
sum: 500000000500000000
希望大家眼里永远充满激情,心里永远充满热爱!!!