Malloc动态内存分配
在C语言中我们会使用malloc来动态地分配内存,这样做的一个主要理由是有些数据结构的大小只有在运行时才能确定。例如,如果你正在编写一个程序,需要用户输入一些数据,但你不知道用户会输入多少数据,那么你就需要使用动态内存分配。而堆是一种用于动态内存分配的数据结构,当程序员使用 malloc 或其他动态内存分配函数请求内存时,这些函数会从堆中分配内存。堆是由动态内存分配器管理的,分为:
-
显式分配器:应用程序会分配和释放空间。例如,在C语言中,我们使用
malloc来分配内存,然后在不再需要的时候使用free来释放内存。这种分配器需要程序员明确地管理内存。 -
隐式分配器:应用程序会分配,但不会释放空间。例如,在Java语言中,我们使用
new来分配内存,但不需要(也不能)明确地释放内存。Java 有垃圾回收机制(Garbage Collection),它会自动管理和回收不再使用的内存。
说个题外话,其实这里malloc是在虚拟内存空间中的堆区域分配内存,关于虚拟内存后面再写,这里可以就小提一下。
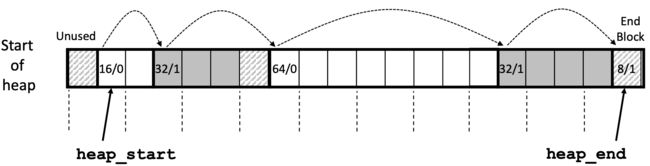
下图是一个简单的动态内存分配的顺序,假设每一个块大小是8 byte,这个分配顺序展示了我们在堆中分配和释放的过程。(图中的alignment意思是例如在64位系统上,必须满足16字节(x86-64)对齐,图中箭头这里如果不空那一小块,开始位置是72,并不是16的倍数,而再+8就是80,满足16字节对齐了。)
一般为了让下一个块可以满足alignment,前一个块都会计算好然后占据合适大小的空间,因此图中的那个白色块应该是属于前一个已分配块的,只不过它没有存任何东西,属于是内部碎片化。这里箭头处画成白色的意思就是它没有存数据,但它是已经被分配了的,下面的内容会再次讲到这一点。

上面的例子看似很简单,但其实也很低效,因为我们无法控制和预测malloc每次请求的大小,分配器必须在第一时间从现有的free块中找到合适的(包括大小足够、满足alignment条件等),这样就会导致整个堆的利用率不高,比如有很多小的free块(也叫碎片Fragmentation)被分割出来,却没法被使用。提到利用率,一般来说我们使用吞吐量(Throughput)以及利用率(Utilization)来描述动态内存分配器的性能。这两个目标往往是相互冲突的。
- 吞吐量是每单位时间内完成的请求数量。例如,如果在10秒内完成了5000次
malloc调用和5000次free调用,那么吞吐量就是1000次操作/秒。 - 利用率是另一个关键的性能目标,它衡量了分配内存(即正在使用的内存)占总内存的比例。
刚刚提到了碎片,碎片化其实就是导致利用率utilization不高的原因,内存碎片化的两种主要形式有内部碎片化和外部碎片化。这两种碎片化都会导致内存利用率低下。
-
内部碎片化(Internal Fragmentation)
当给定的内存块的有效负载(payload)小于块的大小时,就会发生内部碎片化。这种碎片化发生在内存块的内部。当我们为一个小的内存请求分配一个大块的内存时,分配出的内存块中的剩余部分就会形成内部碎片化。这些未使用的内存位于已分配的内存块内部,因此称为"内部"碎片化。为什么分配的内存大小会比请求的大小大呢?因为许多内存管理系统采用固定大小的块来分配内存。举个例子,假设你有一个内存管理系统,它总是分配4KB的内存块。如果一个程序请求1KB的内存,系统会分配一个4KB的块,但只有1KB被使用,剩下的3KB就成了内部碎片。后面要讲的header和footer其实就会导致内部碎片化。

-
外部碎片化(External Fragmentation)
当存在足够的总体堆内存,但没有单个空闲块足够大时,就会发生外部碎片化。这种碎片化发生在内存块的外部。当内存中的空闲空间被分割成小块时,这些小块可能无法满足大的内存请求,即使它们的总和足够大。这些未使用的内存块位于已分配的内存块之间(也就是外部),因此称为"外部"碎片化。当然,如果有一个足够小的内存请求,那么之前形成的外部碎片(也就是一些小的、分散的空闲内存块)也是有可能被利用起来的。

内存管理器都要考虑的基本问题
上面讲了衡量内存管理器效率的指标,除了这些外,内存管理器还有很多最基本的功能和细节要考虑。比如给出一个地址要free掉,怎么知道这个块的大小;在分配和释放的过程中如何跟踪和维护空闲块们;假如有多个合适的空闲块,选择哪一个等。
使用header来存储内存块的大小
要知道各个块的大小,可以为每个分配的块额外使用一个单词word,也叫做header。这个header里存储记录块的大小,以及一些其他信息,比如当前块是否是已分配或者free等。这种方法的优点是简单、易于实现。但是,缺点是因为每个分配的块都包含了一个固定大小的头部,会额外占用空间,导致内部碎片化。

在上图中,每个块大小是8 byte。可以看到虽然我们malloc需要分配32byte,但是由于有一个header以及alignment,实际整个块的大小来到了48 byte。(这里的alignment是为了让下一个块的地址符合要求,要想让每个块都符合16 byte的alignment,只需要让每个块的整体大小都是16的倍数即可。这里需要32+header的8=40 byte,所以需要再补个8来到48才是16的倍数,这就是为什么有那一个大小为8的alignment块。)这里的alignment依然属于内部碎片,因为它属于这个被分配的块。
跟踪空闲块的三种方法(重点)
方法一:隐式空闲列表 Implicit list
隐式空闲链表其实就是把heap分成一个个线性相连的块。上图中灰色部分就是已分配的,白色部分是未分配的。每一个块都有一个header用来存放着个块的大小以及是否被分配。由于我们的块都是align对齐的特性(一般来说是以16 bytes 来align,那么16的倍数,二进制的后四位一定都是0),所以地址的低4位一定是0,我们就可以用低位存储“是否被分配”这一信息。当读取header中的大小时,把低位屏蔽掉就好。
Implicit list 中的 split
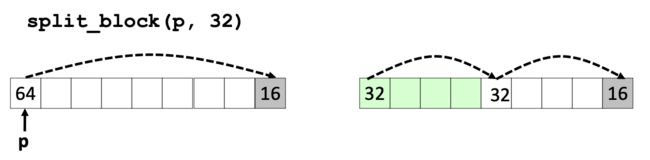
当我们准备分配内存空间时,我们只能是从前向后按顺序遍历查找,如果找到了一个空闲块的大小大于我们需要的内存大小,为了避免浪费空间,往往会进行split,比如下面将64 bytes到分割成两个32 bytes大小的块。
Implicit list 中的 coalesce
接着上面的步骤,如果我们马上又把刚刚分配的32 bytes 释放了,那么我们就会有两个连续的32 bytes 大小的free block,这不是我们想得到的,我们还需要把它变成一个大小的64 bytes的块,这种合二为一的过程就是coalesce。

上图就是一个部分正确coalesce的示例,这种情况下,我们free了中间的块,然后因为它后面还跟着一个free块,所以我们可以加上它后面块的大小得到32+16=48。可是,前面还有一个空闲块,我们似乎就没法合并了,因为我们很难知道前面块的大小,无法定位到前面块的header。因此,我们需要引入footer。

footer和header的内容完全一样,这样我们通过一个header往前一位,就能得到前面块的footer,从而知道前面块的大小,然后进行相关的coalesce。footer和header一般是必须的,因此上面的这幅图其实才是一个最标准的implicit list。
方法二:显式空闲列表 Explicit list
隐士空闲链表其实就是整个heap,我们要找空闲块还得遍历一些已分配的块,实在是太慢了。显式空闲列表则只管理空闲块,用指针将空闲块们连起来,做成一个双向链表。

我们直接在原来payload的部分放prev和next指针,因为空闲块的payload必然都是空的,所以在它空闲的时候用来存储指针没什么毛病。因此,一个标准的显式空闲列表中,一个free block的最小大小是32 bytes(header+prev+next+footer 各 8 bytes)。
Explicit list 因为只管理空闲块所以效率大大提升了,但是每次分配和释放内存包括coalesce时都要管理好这个双向链表(涉及到链表的插入删除操作等),实现起来是复杂一些,但总体值得!
当然,这里我们使用了两个指针,如果空闲块的最小大小(这个由设计者决定)足够我们在payload里放指针,那么其实对空间没啥影响;但如果payload大小都不够两个指针也就是16 bytes的话,双指针就不能使用了,可以考虑只保留一个指针做单向链表。

上面是explicit list 进行分配的例子,当我们找到一个大小比所分配大小大的块后,能split还是得split,然后插入到列表当中。所以对于我们的双向链表来说,这里实际上是“先删除了一个大的块,然后又插入回了一个小的块”。
方法三:分隔空闲列表 Segregated List (Seglist)

看图你就明白啦,其实就是在 explicit list 基础上,多弄了几个列表,划分依据就是根据大小,这样一来,对于需要分配/释放的块,我们只需要从相关大小的列表里找,再一次加快了搜索的效率。
选择空闲块的四种策略
不管我们使用上面哪种空闲块管理方式,在我们试图搜寻和分配空闲块时,面对多个不同的满足条件的空闲块,总会面临一些通用的选择困境。下面是一些通用的参考思想和选择方案。
- 首次适应(First Fit) 这个很简单,就从内存的开始处搜索,选择第一个足够大的空闲块进行分配。这种策略的优点是简单且速度较快,但因为太无脑了,可能会在内存的前部产生很多小的碎片。
- 下一次适应(Next Fit) 类似于首次适应,但是从上次搜索结束的地方开始搜索,而非每次都从头开始。这种策略可以避免重新扫描无用的块,通常会比首次适应稍快。举例来说,假设我们有一个内存块列表,大部分块的大小都接近,只有一小部分块的大小远大于其他块。如果我们有一系列的大请求,那在 Next Fit 中,我们在找到大块并分配之后就可以记住这个位置,那么下一次又有一个大请求时,我们可以直接从这个位置开始扫描,避免了重新扫描前面那些小块。但是这种场景也太苛刻了,你又不知道下一个请求是多大的,所以这个next fit看看了解就好。某些研究表明,使用下一次适应可能会导致更严重的内存碎片化。
- 最佳适应(Best Fit) 顾名思义,遍历所有的空闲块,然后在所有的空闲块中,选择一个能够满足需求且剩余空间最小的块进行分配。这种策略可以最小化每次分配后的剩余空间,从而减少内存碎片,但是搜索的过程可能会比首次适应和下一次适应更慢。在极端情况下,如果我们在分隔空闲列表 Segregated List (Seglist) 中为每个块都设立一个自己的大小类别,那么这就等同于最佳适应(Best Fit )。因为我们总是能找到和需求完全匹配的块,不会有内存浪费。
- 更好适应(Better Fit) "Better Fit"算法是"First Fit"和"Best Fit"的折中方案。在找到第一个足够大的空闲块后,不立即进行分配,而是继续向后搜索一定数量的空闲块。然后从这些块中选择最小的足够大的块进行分配。这种策略旨在在快速分配和减少空间浪费之间找到一种平衡,但可能会略微增加搜索的时间和复杂度。
选择哪种策略取决于特定应用的需求。例如,如果内存分配请求不频繁,可以选择最佳适应以最小化碎片;如果内存分配请求非常频繁,那么首次适应或下一次适应可能更合适,因为这两种策略的查找速度较快。
小结
以上大概是动态内存分配这块的重点内容,要想更加深入的理解推荐去做大名鼎鼎的 malloc lab,我做到满分还是花了很多时间,要想提高分配器的utilization以及throughput,需要使用segregate list,去掉footer(此时可以用header后面的倒数第二位来存储前一个块的是否被分配信息)以及减少minimum block size(再去掉prev指针)等技巧,还是比较有趣的~