最小生成树——Kruskal算法
最小生成树——Kruskal算法
- Kruskal算法简介 & 基本思想
- Kruskal算法步骤
- Kruskal算法时间复杂度
- 关于Kruskal的其它
- Kruskal板题 & 讲解
- 【模板】最小生成树
-
- 题目描述
- 输入格式
- 输出格式
- 样例 #1
-
- 样例输入 #1
- 样例输出 #1
- 提示
- 代码
Kruskal算法简介 & 基本思想
K r u s k a l Kruskal Kruskal算法是一种用于解决最小生成树问题的贪心算法。最小生成树问题是指在一个连通图中找到一棵包含所有顶点的树,且树的边权重之和最小。
K r u s k a l Kruskal Kruskal算法的基本思想是从图中的边集合中选择权重最小的边,并且保证选择的边不会构成环,直到选择了 n − 1 n-1 n−1条边为止( n n n为图中顶点的个数)。
Kruskal算法步骤
-
将图中的所有边按照边权从小到大进行排序。这可以使用快速排序、归并排序等排序算法来实现,但是通常使用sort排序函数。
-
创建一个空的边集合,用于存储最小生成树的边。开始时,这个集合是空的。
-
创建一个并查集,用于判断选择的边是否会构成环。并查集是一种用于处理不相交集合的数据结构,它支持合并集合和查找元素所属集合的操作。开始时,每个顶点都是一个独立的集合。(关于并查集,请看文章并查集)
-
遍历边集合,依次选择权重最小的边。
-
对于每条选择的边,判断它的两个顶点是否属于同一个集合。这可以通过并查集的查找操作来实现。如果两个顶点属于不同的集合,则选择的边不会构成环,可以将其加入边集合中。
-
如果选择的边会构成环,则舍弃该边,继续遍历下一条边。
-
重复步骤 4 − 6 4-6 4−6,直到选择了 n − 1 n-1 n−1条边。这样就构建了一棵最小生成树。
Kruskal算法时间复杂度
Kruskal算法的时间复杂度主要取决于对边集合的排序操作,通常为O(ElogE),其中E为边的数量。并查集的操作时间复杂度为O(logV),其中V为顶点的数量。
关于Kruskal的其它
Kruskal算法的优点是简单且易于实现,适用于稀疏图。它不需要事先知道图的具体结构,只需要给出边的集合即可。另外,Kruskal算法可以处理带有负权边的图。
然而,Kruskal算法并不适用于存在负权环的图,因为负权环会导致算法无限循环。此外,Kruskal算法不能处理不连通图,因为最小生成树要求图是连通的。
总结起来,Kruskal算法通过选择权重最小的边,并使用并查集来判断是否构成环,逐步构建最小生成树。它是一种高效且简单的算法,常用于解决最小生成树问题。
Kruskal板题 & 讲解
洛谷P3366【模板】最小生成树
【模板】最小生成树
题目描述
如题,给出一个无向图,求出最小生成树,如果该图不连通,则输出 orz。
输入格式
第一行包含两个整数 N , M N,M N,M,表示该图共有 N N N 个结点和 M M M 条无向边。
接下来 M M M 行每行包含三个整数 X i , Y i , Z i X_i,Y_i,Z_i Xi,Yi,Zi,表示有一条长度为 Z i Z_i Zi 的无向边连接结点 X i , Y i X_i,Y_i Xi,Yi。
输出格式
如果该图连通,则输出一个整数表示最小生成树的各边的长度之和。如果该图不连通则输出 orz。
样例 #1
样例输入 #1
4 5
1 2 2
1 3 2
1 4 3
2 3 4
3 4 3
样例输出 #1
7
提示
数据规模:
对于 20 % 20\% 20% 的数据, N ≤ 5 N\le 5 N≤5, M ≤ 20 M\le 20 M≤20。
对于 40 % 40\% 40% 的数据, N ≤ 50 N\le 50 N≤50, M ≤ 2500 M\le 2500 M≤2500。
对于 70 % 70\% 70% 的数据, N ≤ 500 N\le 500 N≤500, M ≤ 1 0 4 M\le 10^4 M≤104。
对于 100 % 100\% 100% 的数据: 1 ≤ N ≤ 5000 1\le N\le 5000 1≤N≤5000, 1 ≤ M ≤ 2 × 1 0 5 1\le M\le 2\times 10^5 1≤M≤2×105, 1 ≤ Z i ≤ 1 0 4 1\le Z_i \le 10^4 1≤Zi≤104。
样例解释:
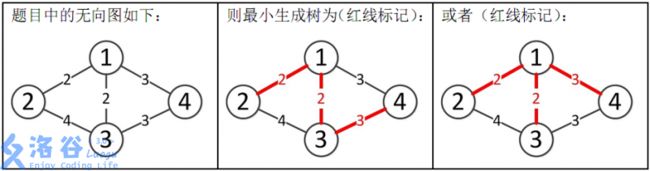
所以最小生成树的总边权为 2 + 2 + 3 = 7 2+2+3=7 2+2+3=7。
代码
这题非常简单,直接套模板!!
#include