分布式环境下的莎士比亚数据集处理
项目要求
对莎士比亚语料库处理,输出统计数据:
- 语料库中唯一(或不同)术语的数量
- 语料库中以字母T / t开头的单词数
- 出现少于5次的术语数量
- 整体读取的文件数
- 最常出现的5个术语及其词频
实现思路
-
统计唯一词汇数量
利用mapper将分词结果转换为以单词为key的键值组合,之后会对每个相同key的组合执行一次reduce。在reducer中调用counter并增加值即可计算词汇数量。 -
统计以字母T/t开头的单词数
在mapper中每分出一个词,小写化后进行判断,t开头的情况下调用一次counter并增加值计算单词数量。 -
统计出现次数少于5次的术语数
Reducer进行完数量统计后,进行判断并增加counter值即可。 -
统计读取的文件数
在mapper中,利用getInputSplit() 获取分片后得到文件名,将文件名加上filename_ 前缀,作为key存入mapper的输出。之后,在reducer中对接受的key进行判断,当前缀为文件名时利用counter进行计数。 -
统计最常出现的5个术语与词频
利用Mapper输出时按key排序的机制,将词频与词对换,进行排序输出。
代码实现
代码实现分为三个部分,词频统计,倒序输出与任务执行部分。
词频统计部分
WordCountMapper类
该类继承Mapper类,实现停止词读取,分词计算功能。
停止词读取:
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 读取stop_word文件,存入内存
Path path = new Path("hdfs://huiluczPc:8020/input/stop_word.txt");
Configuration conf = new Configuration();
FileSystem fileSystem = path.getFileSystem(conf);
FSDataInputStream fsdis = fileSystem.open(path);
LineReader lineReader = new LineReader(fsdis, conf);
stopWords = new ArrayList<String>();
Text line = new Text();
while(lineReader.readLine(line) > 0){
stopWords.add(line.toString());
}
lineReader.close();
}
setup方法在所有的mapper创建前进行一次调用,在该继承方法中,获取hdfs文件系统中stop_word.txt所在地址,并逐行读取停止词,转为字符串集合存入内存中,方便map生成时进行调用。
分词:
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 分词操作
StringTokenizer itr = new StringTokenizer(value.toString(), " \r\t\n!,.:?-(){}[]<>/\\+@*~#%&;\"\'");
while(itr.hasMoreTokens()){
String token = itr.nextToken().toLowerCase(); // 改为小写,防止重复
// 对非停止词处理
if(!stopWords.contains(token)) {
if (token.startsWith("t")) {
// t或T开头出现则+1
Counter c = context.getCounter("mycounters", "t_prefix_counter");
c.increment(1);
}
// 总词数
Counter c1 = context.getCounter("mycounters", "word_num_counter");
c1.increment(1);
context.write(new Text(token), new IntWritable(1));
}
}
// 切割路径,获取文件名,以filename_为前缀传入key
String path = ((FileSplit)context.getInputSplit()).getPath().toString();
int index = path.lastIndexOf("/");
String fileName = path.substring(index+1);
context.write(new Text("filename_" + fileName), new IntWritable(1));
}
利用StringTokenizer进行字符串的切割,将可能出现的符号全部进行分词处理。
为了获得干净的分词结果,在每个token处理前对stopword进行判断,非停止词进入后续处理。
为了实现任务中任务2统计功能,利用startswith进行开头字符的判断,并将统计结果利用 t_prefix_counter计数,方便结果输出。
为了实现任务中任务4文件数量统计,在map方法的最后一段,利用getInputSplit()进行分片后获取文件名,以filename_为前缀将词频统计文件名作为key存入map任务,方便reduce中进行调用。
WordCountReducer类
该类继承Reducer类,实现词频统计功能。
统计词频:
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 对key判断,文件名或正常词汇
if(key.toString().startsWith("filename_")){
System.out.println(key.toString());
// 文件名,直接计数
Counter c = context.getCounter("mycounters", "file_num_counter");
c.increment(1);
}else{
// 正常处理
int valueNum = 0;
for(IntWritable v:values){
valueNum += v.get();
}
if(valueNum < 5){
// 出现次数小于5,计数
Counter c = context.getCounter("mycounters", "less_5_counter");
c.increment(1);
}
// 不同词汇计数
Counter c = context.getCounter("mycounters", "voc_num_counter");
c.increment(1);
context.write(new Text(key.toString()), new IntWritable(valueNum));
}
}
对key相同的map任务输出结果,reduce方法中进行两种判断处理:文件名与非文件名。当key为filename_开头时,表示其为文件名,进行一次counter计数,完成任务4文件数统计,存放至 file_num_counter 中。
对正常单词key,对values进行遍历,统计词频,为了完成任务1,利用counter计数,将总词汇数存入voc_num_counter中。对词频进行判断,词频小于5时,进行计数,存入less_5_counter中进行统计。
最终输出单词-词频值键对。
倒序输出部分
该部分思路为利用mapper输出自动按照key排序的机制,将key与value倒置,并将顺序排序转为倒序,最终在reducer中转为正常值键对输出。
SortMapper类
该类继承自Mapper,主要进行值键互换功能。
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] keyValueStrings = line.split("\t");
int outKey = Integer.parseInt(keyValueStrings[1]);
String outValue = keyValueStrings[0];
context.write(new IntWritable(outKey), new Text(outValue));
}
SortReducer类
该类继承自Reducer,把值键对再换回来。
protected void reduce(IntWritable key, Iterable<Text> values,Context context)throws IOException, InterruptedException {
for(Text value : values){
context.write(value, key);
}
}
DecresingCompare类
该类继承自IntWritable.Comparator,即为hadoop对整型数据的排序类,将其返回值变为负数,实现倒序输出。
public class DecreasingCompare extends IntWritable.Comparator {
public int compare(WritableComparable a, WritableComparable b){
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
任务执行部分
main函数写在ShakespeareWordCount类中。
首先,进行第一个job,对wordcount进行任务处理。
Configuration hadoopConfig = new Configuration();
try {
Job job = Job.getInstance(hadoopConfig, ShakespeareWordCount.class.getSimpleName());
job.setJarByClass(ShakespeareWordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 输出已存在则删除
Path outPath = new Path(dstOut);
outPath.getFileSystem(hadoopConfig).delete(outPath, true);
//job执行作业时输入和输出文件的路径
FileInputFormat.addInputPath(job, new Path(dst));
FileOutputFormat.setOutputPath(job, new Path(dstOut));
//执行job,直到完成
job.waitForCompletion(true);
System.out.println("Finished task1");
判断输出文件是否存在,存在则删除,防止出错。
执行排序任务。
// 排序
Job jobSort =Job.getInstance(hadoopConfig, ShakespeareWordCount.class.getSimpleName() + " sort");
jobSort.setJarByClass(ShakespeareWordCount.class);
jobSort.setMapperClass(SortMapper.class);
jobSort.setReducerClass(SortReducer.class);
jobSort.setMapOutputKeyClass(IntWritable.class);
jobSort.setMapOutputValueClass(Text.class);
jobSort.setOutputKeyClass(Text.class);
jobSort.setOutputValueClass(IntWritable.class);
jobSort.setSortComparatorClass(DecreasingCompare.class);
FileInputFormat.addInputPath(jobSort, new Path(dstOut));
Path result=new Path(sortedOut);
result.getFileSystem(hadoopConfig).delete(result, true);
FileOutputFormat.setOutputPath(jobSort, result);
jobSort.waitForCompletion(false);
System.out.println("Finished task2");
排序任务实现类似,多产生一个排序后的值键对文件。
结果展示
数据集
stop_word.txt
停止词集合,格式为每一行一个词,存入hdfs的/input文件夹中进行取用。
利用hdfs相关命令进行查看前20行:
hadoop fs -cat /input/stop_word.txt|head -20
shakespeare_corpus
莎士比亚数据集,选取莎士比亚喜剧合集共17个文档。
利用hdfs相关命令进行查看文件信息:
hadoop fs -ls /input/shakespeare_corpus

运行结果
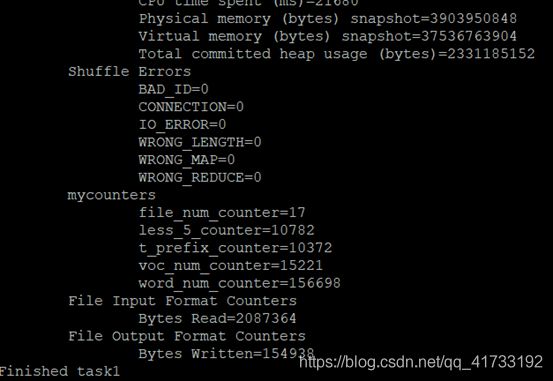
查看结果信息:
hadoop fs -cat /output/shakespeare_word_count_sorted_result/part-r-00000|head -10

统计结果
-
统计唯一词汇数量
根据输出信息,词汇数为voc_num_counter的值,结果为15221。 -
统计以字母T/t开头的单词
根据输出信息,其值为t_prefix_counter的值,结果为10372。 -
统计出现次数少于5次的术语数
根据输出信息,其值为less_5_counter的值,结果为10782。 -
统计读取的文件数
根据输出信息,其值为file_num_counter的值,结果为10782。 -
统计最常出现的5个术语与词频
根据输出信息,去除停止词后,前5个词分别为thou,sir,good,love和lord,词频分别为2087,1950,1300,1144,1062。
项目地址
已上传至github,包括数据集与停止词文档,有兴趣可以看看。
https://github.com/huiluczP/shakespeare_count