grpc protoBuf 编码/解码原理
本文合适对Dubbo、Grpc、Protobuf有一定了解的童鞋阅读。目前Dubbo最新的版本为3,新增了很多特性,最让人兴奋的莫过于新的通讯协议Triple, 兼容了grpc协议,解决了Dubbo2中私有通讯协议带来的封闭性问题。由于兼容grpc协议,因此triple天然支持跨语言数据通通信,如python、golang、C++等等。
grpc协议底层使用protobuf进行数据编码、解码操作,相比于其他序列化工具,它的性能是遥遥领先的。Dubbo、Grpc、Protobuf三者的关系图如下:

我们从内往外,逐步学习下他们的内部原理。现在开始学习 Protobuf 编码篇
阅读这篇文章,可能需要实现了解以下知识内容:
- 计算机存储之 大端模式、小端模式
- 计算机基础知识 原码、反码、补码的原理
- Protobuf 基础使用
- 进制转换 如2进制转换为16进制;16进制转换为2进制
基础篇
测试代码
syntax = "proto3";
option go_package = "./api";
package api;
message Test1 {
int32 data = 1;
}
以上最简单的代码,使用protoc工具生成golang代码,然后分析下 protobuf如何进行编码,编译脚本如下
protoc --go_out=. --go-triple_out=. Test1.proto
测试代码
package main
import (
"fmt"
"github.com/apache/dubbo-go-samples/probuf/protocal/api"
"github.com/golang/protobuf/proto"
)
func main() {
var data int32
data = 150
msg := &api.Test1{
Data: data,
}
buffer, _ := proto.Marshal(msg)
fmt.Println(fmt.Sprintf("%x", buffer))
}
// console 输出为
// 089601
可以看到通过ProtoBuf对数据进行编码后输出16进制 089601 占用三个字节,比原来int32数据类型(占用4个字节)少了一个字节的数据。现在来分析下它的编码原理
// 16进制 089601 转换成二进制如下
00001000 10010110 00000001
编码原理
MSB
在进行数据分析之前,先讲解一下MSB(Most Significant Bit)的概念, Protobuf规定:每一个字节(8个bit)的最高位0、1具有特殊的含义
- 0 表示该字节是一个单独的字节,可以独立解析
- 1 表示该字节不是一个单独的字节,需要跟后面的字节组成使用 才能进行解析
// 16进制 089601 转换成二进制如下
00001000 10010110 00000001
// 1. 第一个字节 00001000, 高位为0,可以单独解析
// 2. 第二个字节 10010110,高位为1, 不可单独解析 跟后面 00000001 进行组合
// 3. 第三个字节 00000001,高位为0, 表示该字节已经结束 不需要跟后面的字节组合使用(实际上后面也没有数据了)
结论:
- 可以得出上述二进制信息 可以分成两部分:
- 00001000 - 元数据
- 10010110 00000001 - 真实数据
- 根据MSB的特性可以分析出,一个字节(8位),去除最高位,真实有效的数据只占据7个bit
从上面的分析出已经解析出数据的元数据、真实数据。现在来进一步分析下这两个数据编码的原理。
元数据
元数据可以解析出字段的类型,以及是哪一个字段,现在将 00001000 拆分成三部分
| MSB | Field Number | Type |
|---|---|---|
| 0 | 0001 | 000 |
-
Field Number - 代表该字段在Message中的序号
int32 data = 1; // 表示 1,可以用过该序号定义字段的名称. 因此protobuf 的语法也明确规则 该序号唯一 -
Type - 代表该字段的数据类型, 可以看出Type占3个bit,因此最多只能支持7个类型。如下图
| ID | Name | Used For |
|---|---|---|
| 0 | VARINT | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | I64 | fixed64, sfixed64, double |
| 2 | LEN | string, bytes, embedded messages, packed repeated fields |
| 3 | SGROUP | group start (deprecated) |
| 4 | EGROUP | group end (deprecated) |
| 5 | I32 | fixed32, sfixed32, float |
结论: 通过元数据可以得出 该字段代表Message里面序号为1,且Type = 0的字段类型 (int32, int64, uint32, uint64, sint32, sint64, bool, enum)
备注: Type = 0,代表了8种类型,后面一一讲解,目前先简单粗暴的理解为int32即可。
真实数据
原始数据: 10010110 00000001
去掉MSB: 0010110 0000001
采用小端模式进行存储 因此数据需要进行替换顺序: 0000001 0010110 => 10010110
最终结果为(十进制): 128 + 16 + 4 + 2 = 150
至此,完成了一个最简单数据编码的原理分析工作。
Field Number 限制
现在我们修改下之前Message中的字段顺序,从1改成222,再来分析下编码
syntax = "proto3";
option go_package = "./api";
package api;
message Test1 {
int32 data = 222;
}
//重新编译 并执行main函数
控制台输出为:
f00d9601
-
二进制:11110000 00001101 10010110 00000001
-
元数据:11110000 00001101
-
真实数据:10011011 00000001 (跟之前一样 不做解析)
元数据分析
原始数据: 11110000 00001101
去掉MSB: 1110000 0001101
采用小端模式进行存储 因此数据需要进行替换顺序: 11011110000
去掉后三位(Type字段): 11011110
最终结果为(十进制): 128 + 64 + 16 + 8 + 4 + 2 = 222
限制
如上通过更改Filed,得到不同编码结果,那么Field Number 是否可以随便输入呢,答案是否定的:
-
一个Message内部的Field Number 必须唯一 不能重复
-
一旦指定(占用) 请不要随便更改、删除
// 考虑业务升级 新的消息可能不需要否则字段(对应的字段) // 特别需要注意使用旧的Field Number 放在新的字段上 (可能会导致报错,或者业务出现歧义) // 因此需要对删除字段对应Field Number 进行预留,语法如下 message Foo { reserved 2, 15, 9 to 11; reserved "foo", "bar"; } -
19000 到 19999被预留 不允许使用,否则报错如下
Test1.proto:6:16: Field numbers 19000 through 19999 are reserved for the protocol buffer library implementation. -
从1开始,最大536,870,911 不允许为负数
升级篇-负数编码
| ID | Name | Used For |
|---|---|---|
| 0 | VARINT | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
之前提到0对应8中数据类型,其中使用sint32、sint64类型对负数进行编码。假设使用int64定义一个变量-2,理论上int64 占用8个字节,但是在protobuf编码中由于存在MSB的关系,每一个字节有效的数据实际只有7个bit,因此需要10字节才能满足。64 / 7 = 9 向上取整 即10,这一点非常非常关键。
编码推算

可以看出-2的最终编码为:
11111110 11111111 11111111 11111111 11111111
11111111 11111111 11111111 11111111 00000001
占用了10个字节,一点都不满足ProtoBuf占用内存低、编解码效率高的初衷,因此ProtoBuf对负数采用ZigZag算法。
ZigZag算法
对于数值类型,大部分采用int32、int64位表示,占用4或者8个字节。大多数情况下需要传输的数值并不会特别大,假设int32 类型 1,二进制为:
00000000 00000000 00000000 00000001
这种情况下,真实有效的负载数据为1,可以压缩为一个字节 00000001(甚至1bit),那么数据传输就变了少了(少了3倍)。ZigZag算法就是解决这种问题。
正数传输可以使用去除前面的0,减小数据体积。但是负数就变得尴尬,如计算机中-1的补码为:
11111111 11111111 11111111 11111111
每一个bit上的值都是1,因此不能采用跟正数一样的压缩方式。由于1阻碍了数据的压缩,那么能不能使用某种方式/算法消除掉1不就可以了吗。ZigZag提出了一种很巧妙的方式解决这个问题:
负数算法
- 负数高位1为标志位 右移到最后一位
- 其他位向左移动一位
- 标示位不变 其余位取反
正数算法
- 负数高位1为标志位 右移到最后一位
- 其他位向左移动一位

至此,数字无论正负,都有了统一的表示方法,因此就可以采用去掉高位0的方式来压缩数据
算法代码
package main
import "fmt"
func main() {
var data int32
data = 1
encode1 := int32ToZigZag(data)
fmt.Printf("正数编码: %032b\n", encode1)
data = -1
encode2 := int32ToZigZag(data)
fmt.Printf("负数编码: %032b\n", encode2)
fmt.Printf("正数解码: %d\n", toInt32(encode1))
fmt.Printf("负数解码: %d\n", toInt32(encode2))
fmt.Println("--------------- zigzag 64位算法 --------------- ")
var data1 int64
data1 = 1
encode3 := int64ToZigZag(data1)
fmt.Printf("64位正数编码: %064b\n", encode3)
data1 = -1
encode4 := int64ToZigZag(data1)
fmt.Printf("64位负数编码: %064b\n", encode4)
fmt.Printf("64位正数解码: %d\n", toInt64(encode3))
fmt.Printf("64位负数解码: %d\n", toInt64(encode4))
}
func int64ToZigZag(n int64) int64 {
return (n << 1) ^ (n >> 63)
}
func toInt64(zz int64) int64 {
return int64(uint64(zz)>>1) ^ -(zz & 1)
}
func int32ToZigZag(n int32) int32 {
return (n << 1) ^ (n >> 31)
}
func toInt32(zz int32) int32 {
return int32(uint32(zz)>>1) ^ -(zz & 1)
}
控制台输出日志(跟手动推算的结果一致)
正数编码: 00000000000000000000000000000010
负数编码: 00000000000000000000000000000001
正数解码: 1
负数解码: -1
--------------- zigzag 64位算法 ---------------
64位正数编码: 0000000000000000000000000000000000000000000000000000000000000010
64位负数编码: 0000000000000000000000000000000000000000000000000000000000000001
64位正数解码: 1
64位负数解码: -1
ZigZag-数据对应关系
| Signed Original | Encoded As |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 3 |
| … | … |
| 0x7fffffff | 0xfffffffe |
| -0x80000000 | 0xffffffff |
字符编码
proto文件
syntax = "proto3";
option go_package = "./api";
package api;
message Test2 {
string data = 1;
}
测试代码
package main
import (
"fmt"
"github.com/apache/dubbo-go-samples/probuf/protocal/api"
"github.com/golang/protobuf/proto"
)
func main() {
var data int32
data = 150
msg := &api.Test1{
Data: data,
}
buffer, _ := proto.Marshal(msg)
fmt.Println(fmt.Sprintf("%x", buffer))
}
控制台输出
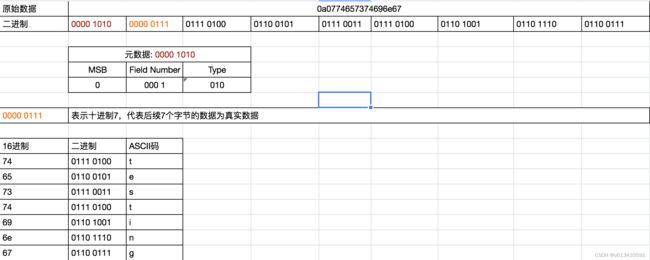
0a0774657374696e67
数据分析
文章参考:
https://studygolang.com/articles/35309
https://developers.google.com/protocol-buffers/docs/encoding