如何批量查询自己的CSDN博客质量分
批量查询自己的CSDN博客质量分
- 一:故事背景
- 二:具体实现
-
- 2.1 csdn 接口分析
- 2.2 apiPost调用接口
- 2.2 RestTemplate进行接口调用
-
- 2.2.1 需要引入的Maven依赖
- 2.2.2 调用
- 2.2.2 两个接口
- 2.2.3 导出Excel到自己的电脑
- 2.2.4 效果
- 三:总结提升
git地址: csdn质量分
一:故事背景
最近在申请博客专家。之前没有注重过博客质量分,申请的时候由于博客质量分较低,惨遭拒接。于是下定决定,一边产出高质量博客的同时一边改进之前的博客。提升自己的博客质量分。
二:具体实现
2.1 csdn 接口分析
想要实现批量查询自己csdn的质量分,主要涉及到2个接口。第一个肯定是我们的查询质量分的接口。另一个我们要拿到自己博客的所有url地址才能进行对应的信息查询。让我们来找一下这两个接口。
- CSDN查询质量分接口
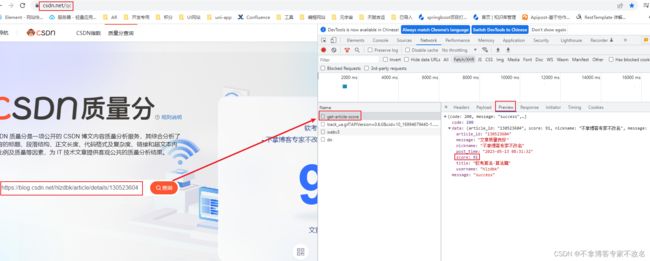
我们直接打开CSDN查询博客质量分的地址,输入自己的某篇博客地址,点击确定,触发查询博客质量分的接口,打开控制台找一找。发现第一个接口就是我需要的,因为我只想输入一个csdn博客的url地址,获取对应的博客质量分。 - 获取自己所有信息接口
分析到上面,我们需要的结果已经找到了,那么下一步就是需要去找到自己博客的url地址了。找之前,我们可以想一下方向,什么地方可能有自己所有博客的url地址。自己的所有博客地址,自己的主页上是不是可能返回这些信息。我们找一下对应接口

通过主页的接口返回值,我们找到了这个接口,接口的地址是:
https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=hlzdbk
这个接口是一个分页查询,我测试了一下,每次最多只能返回一百条。我们可以根据自己的博客数量,修改page和size的大小。分页查询自己的博客地址。当然username别忘了改成你自己的。
2.2 apiPost调用接口
我们想要通过代码批量调用csdn的接口,就要先确保在APIPost调用通。当然postMan也可以。在这些工具上调用通说明接口是没问题的,是支持我们调用的,有这样的依据才能写代码。

这里自己去看对应的接口的请求头,请求头里都放了什么东西,并且尝试哪些是必须的,哪些不是必须的,不断尝试,指导对应接口调通为止。
例如以获取所有博客为例

到这里,整个过程我们就分析完了,剩下的就是如何通过代码实现此功能。
2.2 RestTemplate进行接口调用
我这里使用的是spring的RestTemplate进行的接口调用,因为之前做个这方面的研究,正好有个自己测试的小项目,不用在新建项目,直接进行开发就ok了。这里把代码给到大家。
2.2.1 需要引入的Maven依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.3.12.RELEASEversion>
<relativePath/>
parent>
<groupId>com.examplegroupId>
<artifactId>RestTemplateartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>RestTemplatename>
<description>RestTemplatedescription>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.73version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poiartifactId>
<version>4.1.2version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-ooxmlartifactId>
<version>4.1.2version>
dependency>
<dependency>
<groupId>commons-beanutilsgroupId>
<artifactId>commons-beanutilsartifactId>
<version>1.9.4version>
dependency>
dependencies>
project>
这里主要引入了springboot的依赖,还有分析json的依赖,和导出Excel需要的依赖。
我这里就给出主要核心实现的代码,至于从controller一路到service的代码,就不在这里贴了。
2.2.2 调用
public String csdn(UserModel2 userModel2){
Integer blogNum = userModel2.getBlogNum();
Integer pageNum = 100;
Integer page = blogNum/pageNum + 1 ;
List<ScoreModel> modelList = new ArrayList<>();
for (int i = 1; i <= page; i++) {
List<ScoreModel> scoreModels = csdnCheck(String.valueOf(i), userModel2.getUserId());
modelList.addAll(scoreModels);
}
save(modelList, userModel2.getUserId());
return "success";
}
这里的userModel2放了两个属性,一个是csdn用户id,一个是其博客总数量

2.2.2 两个接口
public List<ScoreModel> csdnCheck(String page,String userId){
//首先查询所有的文章
String url = "https://blog.csdn.net/community/home-api/v1/get-business-list?page="+page+"&size=500&businessType=blog&orderby=&noMore=false&year=&month=&username="+userId;
System.out.println(url);
JSONObject forObject = restTemplate.getForObject(url, JSONObject.class);
LinkedHashMap data = (LinkedHashMap)forObject.get("data");
ArrayList list = (ArrayList)data.get("list");
List<String> urlList = new ArrayList<>();
for (Object o : list) {
LinkedHashMap one = (LinkedHashMap) o;
urlList.add(String.valueOf(one.get("url")));
}
//
// //循环调用csdn接口查询所有的博客质量分
String urlScore = "https://bizapi.csdn.net/trends/api/v1/get-article-score";
//
//请求头
HttpHeaders headers = new HttpHeaders();
headers.set("accept","application/json, text/plain, */*");
headers.set("x-ca-key","203930474");
headers.set("x-ca-nonce","22cd11a0-760a-45c1-8089-14e53123a852");
headers.set("x-ca-signature","RaEczPkQ22Ep/k9/AI737gCtn8qX67CV/uGdhQiPIdQ=");
headers.set("x-ca-signature-headers","x-ca-key,x-ca-nonce");
headers.set("x-ca-signed-content-type","multipart/form-data");
headers.setContentType(MediaType.MULTIPART_FORM_DATA);
//调用接口获取数据
List<ScoreModel> scoreModels = new ArrayList<>();
for (String bkUrl : urlList) {
MultiValueMap<String,String> requestBody = new LinkedMultiValueMap<>();
requestBody.put("url", Collections.singletonList(bkUrl));
HttpEntity<MultiValueMap<String, String>> requestEntity = new HttpEntity<>(requestBody, headers);
URI uri = URI.create(urlScore);
ResponseEntity<String> responseEntity = restTemplate.postForEntity(uri, requestEntity, String.class);
JSONObject data1 = JSON.parseObject(responseEntity.getBody(),JSONObject.class) ;
ScoreModel scoreModel = JSONObject.parseObject(data1.get("data").toString(),ScoreModel.class);
scoreModels.add(scoreModel);
System.out.println("名称: "+scoreModel.getTitle() +"分数: " + scoreModel.getScore() +"时间: " + scoreModel.getPost_time());
}
return scoreModels;
}
这里自己定义了一个model,这个model是我想要查询到的数据项,分别是 成绩,名称,发布时间。剩下的就是通过RestTemplate发送对应的接口请求,先查到所有的url地址,然后通过url地址查询到所有的分数,将其数据放到我创建的model,组装成一个list返回。
2.2.3 导出Excel到自己的电脑
public void save(List<ScoreModel> scoreModels ,String userId){
//创建Excel工作簿对象
Workbook workbook = new XSSFWorkbook();
String sheetName = "Sheet1";
workbook.createSheet(sheetName);
// 将数据写入工作表中
int rowIndex = 0;
Row row = workbook.getSheet(sheetName).createRow(rowIndex++);
Cell cell1 = row.createCell(0);
cell1.setCellValue("名称");
Cell cell2 = row.createCell(1);
cell2.setCellValue("成绩");
Cell cell3 = row.createCell(2);
cell3.setCellValue("时间");
for (ScoreModel person : scoreModels) {
row = workbook.getSheet(sheetName).createRow(rowIndex++);
try {
BeanUtils.setProperty(person, "title", person.getTitle());
BeanUtils.setProperty(person, "score", person.getScore());
BeanUtils.setProperty(person, "post_time", person.getPost_time());
row.createCell(0).setCellValue(person.getTitle());
row.createCell(1).setCellValue(person.getScore());
row.createCell(2).setCellValue(person.getPost_time());
} catch (Exception e) {
e.printStackTrace();
}
}
// 保存 Excel 文件到本地磁盘
try (FileOutputStream outputStream = new FileOutputStream("D:\\DeskTop\\"+userId+".xlsx")) {
workbook.write(outputStream);
} catch (IOException e) {
e.printStackTrace();
}
这里创建一个Excel工作簿对象,将对应的数据保存到Excel内,如果大家想要用的话,不要忘记修改本地导出的路径,我这里是直接导出到了桌面上
2.2.4 效果

三:总结提升
不将就是发现的原动力。将自己的url地址一个一个的CV到CSDN给的查询博客质量分的界面上也可以查询自己的博客质量分。如果我选择了将就,那我就不会研究如何去通过代码实现批量查询自己的博客质量分的功能,也就少去了一个学习的机会,学习RestTemplate怎么使用,怎么导出Excel表的机会。
大家可以通过这篇文章,批量查询自己的博质量,帮助我们修改我们原有博客的平均质量。