ElasticSearch安装与启动
ElasticSearch安装与启动
【服务端安装】
1.1、下载ES压缩包
目前ElasticSearch最新的版本是7.6.2(截止2020.4.1),我们选择6.8.1版本,建议使用JDK1.8及以上。
ElasticSearch分为Linux和Window版本,基于我们主要学习的是ElasticSearch的Java客户端的使用,所以我们课程中使用的是安装较为简便的Window版本,项目上线后,公司的运维人员会安装Linux版的ES供我们连接使用。
ElasticSearch的官方地址:https://www.elastic.co/cn/
下载6.8.1:https://www.elastic.co/cn/downloads/past-releases#elasticsearch

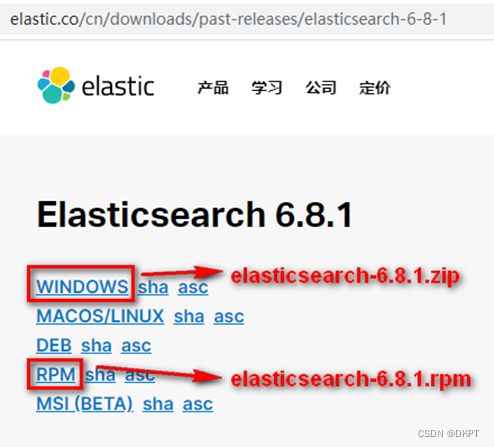
1.2、安装ES服务(Window版)
Window版的ElasticSearch的安装很简单,解压开即安装完毕,解压后的ElasticSearch的目录结构如下:

1.3、启动ES服务
点击ElasticSearch下的bin目录下的elasticsearch.bat启动,控制台显示的日志信息如下:

注意:9300是TCP通讯端口,集群间和TCP Client都执行该端口,9200是http协议的RESTful接口 。
通过浏览器访问ElasticSearch服务器,看到如下返回的json信息,代表服务启动成功:

注意事项一:
ElasticSearch是使用java开发的,且本版本的ES需要JDK版本要是1.8以上,所以安装ElasticSearch之前保证JDK1.8+安装完毕,并正确的配置好JDK环境变量,否则启动ElasticSearch失败。
注意事项二:
出现闪退,通过路径访问发现“空间不足”
修改jvm.options文件的22行23行,把2改成1,让Elasticsearch启动的时候占用1个G的内存。
-Xmx512m:设置JVM最大可用内存为512M。
-Xms512m:设置JVM初始内存为512m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
【客户端安装】
2.1、安装Kibana
1. 什么是Kibana
https://www.elastic.co/cn/products/kibana
Kibana是ElasticSearch的数据可视化和实时分析的工具,利用ElasticSearch的聚合功能,生成各种图表,如柱形图,线状图,饼图等。

2. 下载地址
https://www.elastic.co/cn/downloads/past-releases#kibana
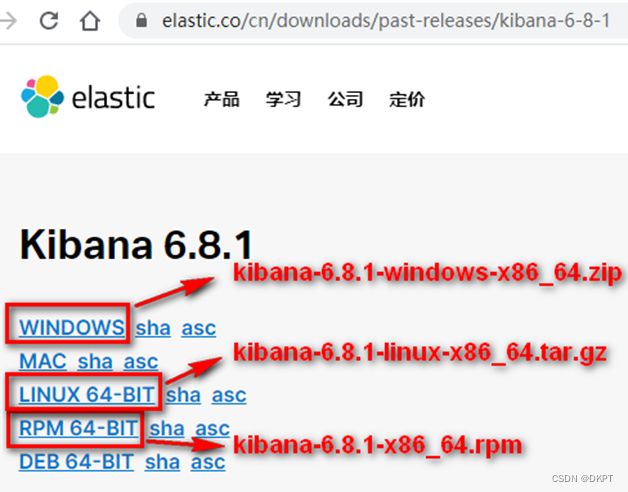
3. 安装配置
kibana-6.8.1-windows-x86_64.zip解压即安装成功

进入安装目录下的config目录的kibana.yml文件
Kibana默认端口:5601

Kibana连接elasticsearch服务器的地址:elasticsearch.url: [“http://localhost:9200”]

修改kibana配置支持中文:i18n.locale: “zh-CN”

4. 运行访问
执行kibana-6.8.1-windows-x86_64\bin\kibana.bat
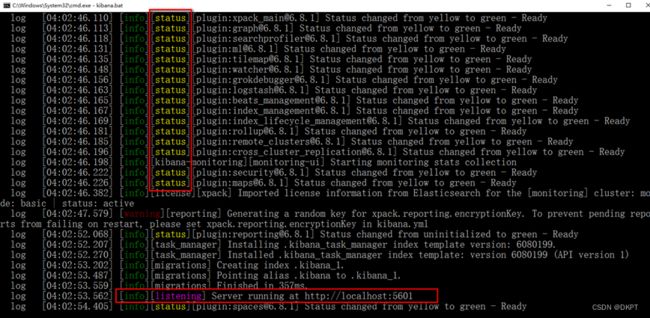
5. 发现kibana的监听端口是5601
我们访问:http://127.0.0.1:5601

2.2、安装Postman
Postman中文版是Postman这款强大网页调试工具的windows客户端,提供功能强大的Web API 和 HTTP 请求调试。软件功能强大,界面简洁明晰、操作方便快捷,设计得很人性化。Postman中文版能够发送任何类型的HTTP 请求 (GET, HEAD, POST, PUT…),不仅能够表单提交,且可以附带任意类型请求体。
Postman官网:https://www.getpostman.com
安装:6.6.1版本
![]()
2.3、IK 分词器和ElasticSearch集成使用
1. IK分词器简介
IKAnalyzer是一个开源的,基于Java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出 了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IK分词器3.0的特性如下:
1)采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力。
2)采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
3)对中英联合支持不是很好,在这方面的处理比较麻烦.需再做一次查询,同时是支持个人词条的优化的词典存储,更小的内存占用。
4)支持用户词典扩展定义。
5)针对Lucene全文检索优化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
2. IK分词器的安装
1) 下载:
GitHub仓库地址:https://github.com/medcl/elasticsearch-analysis-ik

2) 解压安装IK插件
直接解压到plugins\ik\目录下,注意目录结构,解压后的zip不要放在plugins目录下,删除掉

3) 重新启动ElasticSearch之后,看到如下日志代表安装成功

4) 测试
在kibana中测试:
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
ik_max_word:会将文本做最细粒度的拆分
ik_smart:会做最粗粒度的拆分,智能拆分
GET _analyze
{
"analyzer": "ik_max_word",
"text": ["我是中国人"]
}
请求方式:GET
请求url:http://127.0.0.1:9200/_analyze
请求体:
{
"analyzer": "ik_max_word",
"text": ["我是中国人"]
}
最细粒度的拆分结果:

5) 在postman中测试
