Hudi 集成 Spark 数据分析示例(含代码流程与测试结果)
文章目录
- 数据集
- 数据处理目标
- 整体项目结构
- 数据ETL与保存
-
- 代码编写
- 测试结果
- 指标查询分析
-
- 代码编写
- 测试结果
- 集成Hive查询
-
- 创建Hive连接
- 使用hql 进行查询
- 参考资料
数据集
数据为2017年5月1日-10月31日(半年)海口市每天的订单数据,包含订单的起终点经纬度以及订单类型
、出行品类、乘车人数的订单属性数据。
百度网盘连接:
链接:https://pan.baidu.com/s/1e1hhf0Aag1ukWiRdMLnU3w
提取码:i3x4
数据处理目标
依据海口滴滴出行数据,按照如下需求统计分析:

整体项目结构
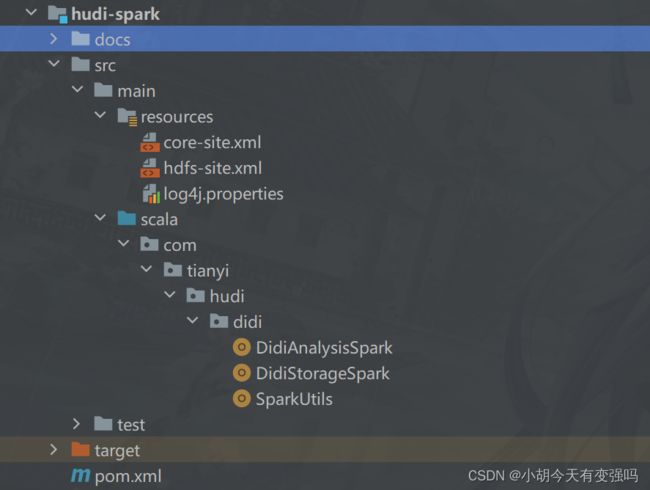
数据ETL与保存
代码编写
resources 包下的三个配置文件是Hadoop的配置文件,直接复制过来就好。

- pom文件依赖
<repositories>
<repository>
<id>aliyunid>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
repository>
<repository>
<id>clouderaid>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
<repository>
<id>jbossid>
<url>http://repository.jboss.com/nexus/content/groups/publicurl>
repository>
repositories>
<properties>
<scala.version>2.12.10scala.version>
<scala.binary.version>2.12scala.binary.version>
<spark.version>3.0.0spark.version>
<hadoop.version>2.7.3hadoop.version>
<hudi.version>0.9.0hudi.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql-kafka-0-10_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.hudigroupId>
<artifactId>hudi-spark3-bundle_2.12artifactId>
<version>${hudi.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-avro_2.12artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive-thriftserver_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpcoreartifactId>
<version>4.4.13version>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
<version>4.5.12version>
dependency>
dependencies>
<build>
<outputDirectory>target/classesoutputDirectory>
<testOutputDirectory>target/test-classestestOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resourcesdirectory>
resource>
resources>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.0version>
<configuration>
<source>1.8source>
<target>1.8target>
<encoding>UTF-8encoding>
configuration>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.0version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
- 工具类SparkUtils
import org.apache.spark.sql.SparkSession
/**
* SparkSQL 操作数据(加载读取和保存写入)时工具类,比如获取SparkSession实例对象等等
*/
object SparkUtils {
def createSpakSession(clazz: Class[_], master: String = "local[4]", partitions: Int = 4): SparkSession = {
SparkSession.builder()
.appName(clazz.getSimpleName.stripSuffix("$"))
.master(master)
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.sql.shuffle.partitions", partitions)
.getOrCreate()
}
def main(args: Array[String]): Unit = {
val spark = createSpakSession(this.getClass)
println(spark)
Thread.sleep(10000000)
spark.stop()
}
}
- DidiStorageSpark.scala
package com.tianyi.hudi.didi
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.sql.functions._
/**
* 滴滴海口出行运营数据分析,使用SparkSQL操作数据,先读取CSv文件,保存至Hudi表中。
* step1. 构建SparkSession实例对象(集成Hudi和HDFS)
* step2. 加载本地CSV文件格式滴滴出行数据
* step3. 滴滴出行数据ETL处理
* stpe4. 保存转换后数据至Hudi表
* step5. 应用结束关闭资源
*/
object DidiStorageSpark {
//滴滴数据路径
//file 表示本地文件系统
def datasPath : String = "file:///D:/BigData/Hudi/heima/ExerciseProject/hudi-learning/datas/didi/dwv_order_make_haikou_1.txt"
//Hudi表中的属性
val hudiTableName : String = "tbl_didi_haikou"
val hudiTablePath : String = "/hudi-warehouse/tbl_didi_haikou"
/**
* 读取csv格式文本文件数据,封装到DataFrame中
*/
def readCsvFile(spark: SparkSession, path: String): DataFrame = {
spark.read
//设置分隔符为制表符
.option("sep", "\\t")
//文件首行为列名称
.option("header", true)
//依据数值自动推断类型
.option("inferSchema", "true")
//指定文件路径
.csv(path)
}
/**
* 对滴滴出行海口数据进行ETL转换操作:指定ts和partitionpath列
*/
def procevss(dataFrame: DataFrame): DataFrame = {
dataFrame
//添加hudi表的分区字段,三级分区 -> yyyy-MM-dd
.withColumn(
"partitionpath",
concat_ws("-", col("year"), col("month"), col("day"))
)
.drop("year", "month", "day")
//添加timestamp列,作为Hudi表记录数据合并时字段,使用发车时间
//departure_time 是String类型,需要将其转换成Long类型
.withColumn(
"ts",
unix_timestamp(col("departure_time"), "yyyy-MM-dd HH:mm:ss")
)
}
/**
* 将数据集DataFrame保存至Hudi表中,表的类型为COW,属于批量保存数据,写少读多
*/
def saveToHudi(dataframe: DataFrame, table: String, path: String): Unit = {
//导入包
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
//保存数据
// 保存数据
dataframe.write
.mode(SaveMode.Overwrite)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性值设置
.option(RECORDKEY_FIELD.key(), "order_id")
.option(PRECOMBINE_FIELD.key(), "ts")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
}
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME","hty")
//step1. 构建SparkSession实例对象(集成Hudi和HDFS)
val spark: SparkSession = SparkUtils.createSpakSession(this.getClass)
//step2. 加载本地CSV文件格式滴滴出行数据
val didiDF = readCsvFile(spark, datasPath)
// didiDF.printSchema()
// didiDF.show(10, truncate = false)
//step3. 滴滴出行数据ETL处理
val etlDF: DataFrame = procevss(didiDF)
etlDF.printSchema()
etlDF.show(10,truncate = false)
//stpe4. 保存转换后数据至Hudi表
saveToHudi(etlDF, hudiTableName, hudiTablePath)
}
}
注意:
def datasPath : String = “file:///D:/BigData/Hudi/heima/ExerciseProject/hudi-learning/datas/didi/dwv_order_make_haikou_1.txt”
修改为数据集存放的位置
测试结果
root
|-- order_id: long (nullable = true)
|-- product_id: integer (nullable = true)
|-- city_id: integer (nullable = true)
|-- district: integer (nullable = true)
|-- county: integer (nullable = true)
|-- type: integer (nullable = true)
|-- combo_type: integer (nullable = true)
|-- traffic_type: integer (nullable = true)
|-- passenger_count: integer (nullable = true)
|-- driver_product_id: integer (nullable = true)
|-- start_dest_distance: integer (nullable = true)
|-- arrive_time: string (nullable = true)
|-- departure_time: string (nullable = true)
|-- pre_total_fee: double (nullable = true)
|-- normal_time: string (nullable = true)
|-- bubble_trace_id: string (nullable = true)
|-- product_1level: integer (nullable = true)
|-- dest_lng: double (nullable = true)
|-- dest_lat: double (nullable = true)
|-- starting_lng: double (nullable = true)
|-- starting_lat: double (nullable = true)
|-- year: integer (nullable = true)
|-- month: integer (nullable = true)
|-- day: integer (nullable = true)
+--------------+----------+-------+--------+------+----+----------+------------+---------------+-----------------+-------------------+-------------------+-------------------+-------------+-----------+--------------------------------+--------------+--------+--------+------------+------------+----+-----+---+
|order_id |product_id|city_id|district|county|type|combo_type|traffic_type|passenger_count|driver_product_id|start_dest_distance|arrive_time |departure_time |pre_total_fee|normal_time|bubble_trace_id |product_1level|dest_lng|dest_lat|starting_lng|starting_lat|year|month|day|
+--------------+----------+-------+--------+------+----+----------+------------+---------------+-----------------+-------------------+-------------------+-------------------+-------------+-----------+--------------------------------+--------------+--------+--------+------------+------------+----+-----+---+
|17592880231474|3 |83 |898 |460106|0 |0 |0 |0 |3 |3806 |2017-05-26 00:04:47|2017-05-26 00:02:43|11.0 |14 |d88a957f7f1ff9fae80a9791103f0303|3 |110.3463|20.0226 |110.3249 |20.0212 |2017|5 |26 |
|17592880435172|3 |83 |898 |460106|0 |0 |0 |0 |3 |3557 |2017-05-26 00:16:07|2017-05-26 00:13:12|11.0 |8 |a692221c507544783a0519b810390303|3 |110.3285|20.0212 |110.3133 |20.0041 |2017|5 |26 |
|17592880622846|3 |83 |898 |460108|0 |0 |0 |0 |3 |3950 |2017-05-26 01:05:53|2017-05-26 01:03:25|12.0 |8 |c0a80166cf3529b8a11ef1af10440303|3 |110.3635|20.0061 |110.3561 |20.0219 |2017|5 |26 |
|17592880665344|3 |83 |898 |460106|0 |0 |0 |0 |3 |2265 |2017-05-26 00:51:31|2017-05-26 00:48:24|9.0 |6 |6446aa1459270ad8255c9d6e26e5ff02|3 |110.3172|19.9907 |110.3064 |20.0005 |2017|5 |26 |
|17592880763217|3 |83 |898 |460106|0 |0 |0 |0 |3 |7171 |0000-00-00 00:00:00|2017-05-26 00:55:16|20.0 |NULL |64469e3e59270c7308f066ae2187a102|3 |110.3384|20.0622 |110.3347 |20.0269 |2017|5 |26 |
|17592880885186|3 |83 |898 |460107|0 |0 |0 |0 |3 |8368 |2017-05-26 02:00:15|2017-05-26 01:54:26|24.0 |15 |6446a13459271a517a8435b41aa8a002|3 |110.3397|20.0395 |110.3541 |19.9947 |2017|5 |26 |
|17592881134529|3 |83 |898 |460106|0 |0 |0 |0 |3 |4304 |2017-05-26 03:38:13|2017-05-26 03:33:24|13.0 |NULL |64469e3b59273182744d550020dd6f02|3 |110.3608|20.027 |110.3435 |20.0444 |2017|5 |26 |
|17592881199105|3 |83 |898 |460108|0 |0 |0 |0 |3 |6247 |2017-05-26 03:18:04|2017-05-26 03:15:36|17.0 |12 |64469c3159272d57041f9b782352e802|3 |110.3336|20.001 |110.3461 |20.0321 |2017|5 |26 |
|17592881962918|3 |83 |898 |460106|0 |0 |0 |0 |3 |5151 |2017-05-26 07:13:13|2017-05-26 07:03:29|14.0 |13 |c0a800655927626800006caf8c764d23|3 |110.3433|19.9841 |110.3326 |20.0136 |2017|5 |26 |
|17592882308885|3 |83 |898 |460108|0 |0 |0 |0 |3 |7667 |2017-05-26 07:29:18|2017-05-26 07:23:13|19.0 |20 |c0a8030376f0685e4927c11310330303|3 |110.3121|20.0252 |110.3577 |20.0316 |2017|5 |26 |
+--------------+----------+-------+--------+------+----+----------+------------+---------------+-----------------+-------------------+-------------------+-------------------+-------------+-----------+--------------------------------+--------------+--------+--------+------------+------------+----+-----+---+
only showing top 10 rows
root
|-- order_id: long (nullable = true)
|-- product_id: integer (nullable = true)
|-- city_id: integer (nullable = true)
|-- district: integer (nullable = true)
|-- county: integer (nullable = true)
|-- type: integer (nullable = true)
|-- combo_type: integer (nullable = true)
|-- traffic_type: integer (nullable = true)
|-- passenger_count: integer (nullable = true)
|-- driver_product_id: integer (nullable = true)
|-- start_dest_distance: integer (nullable = true)
|-- arrive_time: string (nullable = true)
|-- departure_time: string (nullable = true)
|-- pre_total_fee: double (nullable = true)
|-- normal_time: string (nullable = true)
|-- bubble_trace_id: string (nullable = true)
|-- product_1level: integer (nullable = true)
|-- dest_lng: double (nullable = true)
|-- dest_lat: double (nullable = true)
|-- starting_lng: double (nullable = true)
|-- starting_lat: double (nullable = true)
|-- partitionpath: string (nullable = false)
|-- ts: long (nullable = true)
+--------------+----------+-------+--------+------+----+----------+------------+---------------+-----------------+-------------------+-------------------+-------------------+-------------+-----------+--------------------------------+--------------+--------+--------+------------+------------+-------------+----------+
|order_id |product_id|city_id|district|county|type|combo_type|traffic_type|passenger_count|driver_product_id|start_dest_distance|arrive_time |departure_time |pre_total_fee|normal_time|bubble_trace_id |product_1level|dest_lng|dest_lat|starting_lng|starting_lat|partitionpath|ts |
+--------------+----------+-------+--------+------+----+----------+------------+---------------+-----------------+-------------------+-------------------+-------------------+-------------+-----------+--------------------------------+--------------+--------+--------+------------+------------+-------------+----------+
|17592880231474|3 |83 |898 |460106|0 |0 |0 |0 |3 |3806 |2017-05-26 00:04:47|2017-05-26 00:02:43|11.0 |14 |d88a957f7f1ff9fae80a9791103f0303|3 |110.3463|20.0226 |110.3249 |20.0212 |2017-5-26 |1495728163|
|17592880435172|3 |83 |898 |460106|0 |0 |0 |0 |3 |3557 |2017-05-26 00:16:07|2017-05-26 00:13:12|11.0 |8 |a692221c507544783a0519b810390303|3 |110.3285|20.0212 |110.3133 |20.0041 |2017-5-26 |1495728792|
|17592880622846|3 |83 |898 |460108|0 |0 |0 |0 |3 |3950 |2017-05-26 01:05:53|2017-05-26 01:03:25|12.0 |8 |c0a80166cf3529b8a11ef1af10440303|3 |110.3635|20.0061 |110.3561 |20.0219 |2017-5-26 |1495731805|
|17592880665344|3 |83 |898 |460106|0 |0 |0 |0 |3 |2265 |2017-05-26 00:51:31|2017-05-26 00:48:24|9.0 |6 |6446aa1459270ad8255c9d6e26e5ff02|3 |110.3172|19.9907 |110.3064 |20.0005 |2017-5-26 |1495730904|
|17592880763217|3 |83 |898 |460106|0 |0 |0 |0 |3 |7171 |0000-00-00 00:00:00|2017-05-26 00:55:16|20.0 |NULL |64469e3e59270c7308f066ae2187a102|3 |110.3384|20.0622 |110.3347 |20.0269 |2017-5-26 |1495731316|
|17592880885186|3 |83 |898 |460107|0 |0 |0 |0 |3 |8368 |2017-05-26 02:00:15|2017-05-26 01:54:26|24.0 |15 |6446a13459271a517a8435b41aa8a002|3 |110.3397|20.0395 |110.3541 |19.9947 |2017-5-26 |1495734866|
|17592881134529|3 |83 |898 |460106|0 |0 |0 |0 |3 |4304 |2017-05-26 03:38:13|2017-05-26 03:33:24|13.0 |NULL |64469e3b59273182744d550020dd6f02|3 |110.3608|20.027 |110.3435 |20.0444 |2017-5-26 |1495740804|
|17592881199105|3 |83 |898 |460108|0 |0 |0 |0 |3 |6247 |2017-05-26 03:18:04|2017-05-26 03:15:36|17.0 |12 |64469c3159272d57041f9b782352e802|3 |110.3336|20.001 |110.3461 |20.0321 |2017-5-26 |1495739736|
|17592881962918|3 |83 |898 |460106|0 |0 |0 |0 |3 |5151 |2017-05-26 07:13:13|2017-05-26 07:03:29|14.0 |13 |c0a800655927626800006caf8c764d23|3 |110.3433|19.9841 |110.3326 |20.0136 |2017-5-26 |1495753409|
|17592882308885|3 |83 |898 |460108|0 |0 |0 |0 |3 |7667 |2017-05-26 07:29:18|2017-05-26 07:23:13|19.0 |20 |c0a8030376f0685e4927c11310330303|3 |110.3121|20.0252 |110.3577 |20.0316 |2017-5-26 |1495754593|
+--------------+----------+-------+--------+------+----+----------+------------+---------------+-----------------+-------------------+-------------------+-------------------+-------------+-----------+--------------------------------+--------------+--------+--------+------------+------------+-------------+----------+
only showing top 10 rows
可以看到数据以想要的方式进行转化并存储。
再到HDFS查看是否成功存储:
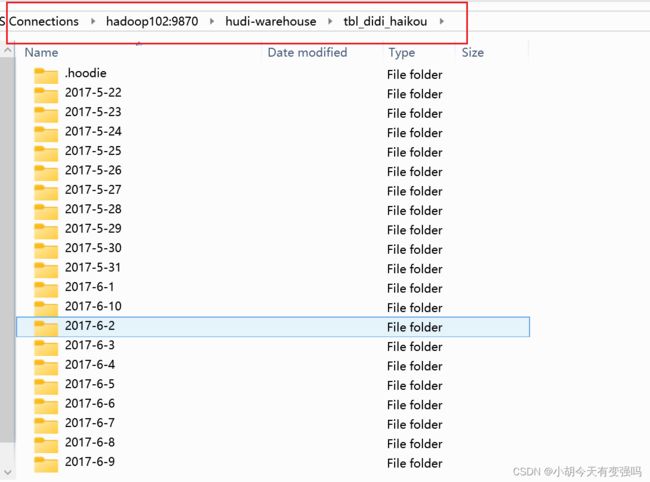
HDFS上成功将数据以Hudi表的形式存入。
指标查询分析
代码编写
- DidiAnalysisSpark.scala
import java.util.{Calendar, Date}
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.sql.functions._
/**
* 滴滴海口出行运营数据分析,使用SparkSQL操作数据,加载Hudi表数据,按照业务需求统计。
*/
object DidiAnalysisSpark {
//Hudi表属性,存储HDFS路径
val hudiTablePath = "/hudi-warehouse/tbl_didi_haikou"
/**
* 加载Hudi表数据,封装到DataFrame中
*/
def readFromHudi(spark: SparkSession, path: String): DataFrame = {
val didDF: DataFrame = spark.read.format("hudi").load(path)
//选择字段
didDF.select(
"product_id", "type", "traffic_type", "pre_total_fee", "start_dest_distance", "departure_time"
)
}
/**
* 订单类型统计,字段:product_id
*/
def reportProduct(dataframe: DataFrame): Unit = {
//a.按照产品线id分组统计即可
val reportDF: DataFrame = dataframe.groupBy("product_id").count()
//b.自定义UDF函数,转换名称
val to_name = udf(
//匿名函数
(productId: Int) => {
productId match {
case 1 => "滴滴专车"
case 2 => "滴滴企业专车"
case 3 => "滴滴快车"
case 4 => "滴滴企业专车"
}
}
)
//c.转换名称
val resultDF: DataFrame = reportDF.select(
to_name(col("product_id")).as("order_type"),
col("count").as("total")
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
/**
* 订单时效性统计,字段:type
*/
def reportType(dataframe: DataFrame): Unit = {
// a. 按照时效性id分组统计即可
val reportDF: DataFrame = dataframe.groupBy("type").count()
// b. 自定义UDF函数,转换名称
val to_name = udf(
(realtimeType: Int) => {
realtimeType match {
case 0 => "实时"
case 1 => "预约"
}
}
)
// c. 转换名称
val resultDF: DataFrame = reportDF.select(
to_name(col("type")).as("order_realtime"),
col("count").as("total")
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
def reportTraffic(dataframe: DataFrame): Unit = {
// a. 按照交通类型id分组统计即可
val reportDF: DataFrame = dataframe.groupBy("traffic_type").count()
// b. 自定义UDF函数,转换名称
val to_name = udf(
(trafficType: Int) => {
trafficType match {
case 0 => "普通散客"
case 1 => "企业时租"
case 2 => "企业接机套餐"
case 3 => "企业送机套餐"
case 4 => "拼车"
case 5 => "接机"
case 6 => "送机"
case 302 => "跨城拼车"
case _ => "未知"
}
}
)
// c. 转换名称
val resultDF: DataFrame = reportDF.select(
to_name(col("traffic_type")).as("traffic_type"),
col("count").as("total")
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
/**
* 订单价格统计,先将订单价格划分阶段,再统计各个阶段数目,使用字段:pre_total_fee
*/
def reportPrice(dataframe: DataFrame): Unit = {
val resultDF: DataFrame = dataframe
.agg(
// 价格 0 ~ 15
sum(
when(col("pre_total_fee").between(0, 15), 1).otherwise(0)
).as("0~15"),
// 价格 16 ~ 30
sum(
when(col("pre_total_fee").between(16, 30), 1).otherwise(0)
).as("16~30"),
// 价格 31 ~ 50
sum(
when(col("pre_total_fee").between(31, 50), 1).otherwise(0)
).as("31~50"),
// 价格 51 ~ 100
sum(
when(col("pre_total_fee").between(51, 100), 1).otherwise(0)
).as("51~100"),
// 价格 100+
sum(
when(col("pre_total_fee").gt(100), 1).otherwise(0)
).as("100+")
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
/**
* 订单距离统计,先将订单距离划分为不同区间,再统计各个区间数目,使用字段:start_dest_distance
*/
def reportDistance(dataframe: DataFrame): Unit = {
val resultDF: DataFrame = dataframe
.agg(
// 距离: 0 ~ 10km
sum(
when(col("start_dest_distance").between(0, 10000), 1).otherwise(0)
).as("0~10km"),
// 距离: 10 ~ 20km
sum(
when(col("start_dest_distance").between(10001, 20000), 1).otherwise(0)
).as("10~20km"),
// 距离: 20 ~ 20km
sum(
when(col("start_dest_distance").between(20001, 30000), 1).otherwise(0)
).as("20~30"),
// 距离: 30 ~ 50km
sum(
when(col("start_dest_distance").between(30001, 50000), 1).otherwise(0)
).as("30~50km"),
// 距离: 50km+
sum(
when(col("start_dest_distance").gt(50001), 1).otherwise(0)
).as("50+km")
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
/**
* 订单星期分组统计,先将日期转换为星期,再对星期分组统计,使用字段:departure_time
*/
def reportWeek(dataframe: DataFrame): Unit = {
// a. 自定义UDF函数,转换日期为星期
val to_week: UserDefinedFunction = udf(
(dateStr: String) => {
val format: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")
val calendar: Calendar = Calendar.getInstance();
val date: Date = format.parse(dateStr)
calendar.setTime(date)
val dayWeek = calendar.get(Calendar.DAY_OF_WEEK) match {
case 1 => "星期日"
case 2 => "星期一"
case 3 => "星期二"
case 4 => "星期三"
case 5 => "星期四"
case 6 => "星期五"
case 7 => "星期六"
}
// 返回星期即可
dayWeek
}
)
//b. 对数据进行处理
val reportDF: DataFrame = dataframe
.select(
to_week(col("departure_time")).as("week")
)
.groupBy("week").count()
.select(
col("week"), col("count").as("total")
)
reportDF.printSchema()
reportDF.show(10, truncate = false)
}
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "hty")
//step1、构建SparkSession实例对象(集成Hudi和HDFS)
val spark: SparkSession = SparkUtils.createSpakSession(this.getClass, partitions = 8)
//step2、加载Hudi表的数据,指定字段
val hudiDF: DataFrame = readFromHudi(spark, hudiTablePath)
//hudiDF.printSchema()
//hudiDF.show(10, truncate = false)
//由于数据使用多次,所以建议缓存
hudiDF.persist(StorageLevel.MEMORY_AND_DISK)
// step3、按照业务指标进行统计分析
// 指标1:订单类型统计
reportProduct(hudiDF)
// 指标2:订单时效统计
reportType(hudiDF)
// 指标3:交通类型统计
reportTraffic(hudiDF)
// 指标4:订单价格统计
reportPrice(hudiDF)
// 指标5:订单距离统计
reportDistance(hudiDF)
// 指标6:日期类型 -> 星期,进行统计
reportWeek(hudiDF)
//数据不存在时,释放资源
hudiDF.unpersist()
// step4、应用结束,关闭资源
spark.stop()
}
}
测试结果
root
|-- order_type: string (nullable = true)
|-- total: long (nullable = false)
+----------+-------+
|order_type|total |
+----------+-------+
|滴滴快车 |1298383|
|滴滴专车 |15615 |
+----------+-------+
root
|-- order_realtime: string (nullable = true)
|-- total: long (nullable = false)
+--------------+-------+
|order_realtime|total |
+--------------+-------+
|预约 |28488 |
|实时 |1285510|
+--------------+-------+
root
|-- traffic_type: string (nullable = true)
|-- total: long (nullable = false)
+------------+-------+
|traffic_type|total |
+------------+-------+
|送机 |37469 |
|接机 |19694 |
|普通散客 |1256835|
+------------+-------+
root
|-- 0~15: long (nullable = true)
|-- 16~30: long (nullable = true)
|-- 31~50: long (nullable = true)
|-- 51~100: long (nullable = true)
|-- 100+: long (nullable = true)
+------+------+-----+------+----+
|0~15 |16~30 |31~50|51~100|100+|
+------+------+-----+------+----+
|605354|532553|96559|58172 |4746|
+------+------+-----+------+----+
root
|-- 0~10km: long (nullable = true)
|-- 10~20km: long (nullable = true)
|-- 20~30: long (nullable = true)
|-- 30~50km: long (nullable = true)
|-- 50+km: long (nullable = true)
+-------+-------+-----+-------+-----+
|0~10km |10~20km|20~30|30~50km|50+km|
+-------+-------+-----+-------+-----+
|1102204|167873 |39372|3913 |636 |
+-------+-------+-----+-------+-----+
root
|-- week: string (nullable = true)
|-- total: long (nullable = false)
+------+------+
|week |total |
+------+------+
|星期日|137174|
|星期四|197344|
|星期一|185065|
|星期三|175714|
|星期二|185391|
|星期六|228930|
|星期五|204380|
+------+------+
成功将数据按照要求进行了统计分析。
集成Hive查询
创建Hive连接
点击Database创建hive的连接,填写相关参数
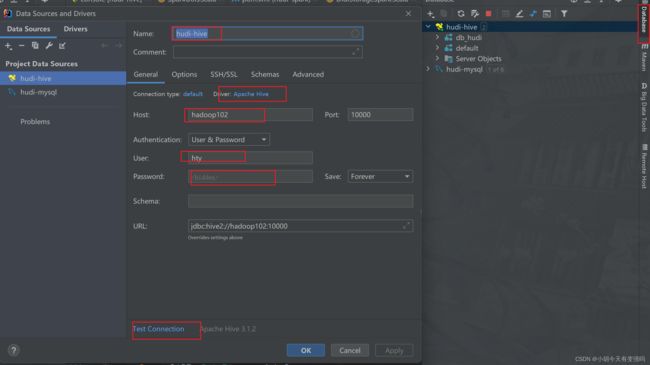
点击 Test Connection 进行测试,下面截图说明连接成功

使用hql 进行查询
hudi-hive-didi.sql
-- 1. 创建数据库database
CREATE DATABASE IF NOT EXISTS db_hudi ;
-- 2. 使用数据库
USE db_hudi ;
-- 3. 创建表
CREATE EXTERNAL TABLE IF NOT EXISTS tbl_hudi_didi(
order_id bigint ,
product_id int ,
city_id int ,
district int ,
county int ,
type int ,
combo_type int ,
traffic_type int ,
passenger_count int ,
driver_product_id int ,
start_dest_distance int ,
arrive_time string ,
departure_time string ,
pre_total_fee double ,
normal_time string ,
bubble_trace_id string ,
product_1level int ,
dest_lng double ,
dest_lat double ,
starting_lng double ,
starting_lat double ,
partitionpath string ,
ts bigint
)
PARTITIONED BY (date_str string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION '/hudi-warehouse/tbl_didi_haikou' ;
-- 查看分区表分区
SHOW PARTITIONS db_hudi.tbl_hudi_didi ;
-- 5. 手动添加分区信息
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-22') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-22' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-23') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-23' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-24') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-24' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-25') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-25' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-26') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-26' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-27') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-27' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-28') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-28' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-29') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-29' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-30') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-30' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-31') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-31' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-1') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-1' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-2') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-2' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-3') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-3' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-4') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-4' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-5') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-5' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-6') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-6' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-7') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-7' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-8') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-8' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-9') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-9' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-10') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-10' ;
-- 测试,查询数据
SET hive.mapred.mode = nonstrict ;
SELECT order_id, product_id, type, pre_total_fee, traffic_type, start_dest_distance FROM db_hudi.tbl_hudi_didi LIMIT 20;
-- 开发测试,设置运行模式为本地模式
set hive.exec.mode.local.auto=true;
set hive.exec.mode.local.auto.tasks.max=10;
set hive.exec.mode.local.auto.inputbytes.max=50000000;
set hive.support.concurrency=false;
set hive.auto.convert.join= false;
-- 指标一:订单类型统计
WITH tmp AS (
SELECT product_id, COUNT(1) AS total FROM db_hudi.tbl_hudi_didi GROUP BY product_id
)
SELECT
CASE product_id
WHEN 1 THEN "滴滴专车"
WHEN 2 THEN "滴滴企业专车"
WHEN 3 THEN "滴滴快车"
WHEN 4 THEN "滴滴企业快车"
END AS order_type,
total
FROM tmp ;
-- 指标二:订单时效性统计
WITH tmp AS (
SELECT type, COUNT(1) AS total FROM db_hudi.tbl_hudi_didi GROUP BY type
)
SELECT
CASE type
WHEN 0 THEN "实时"
WHEN 1 THEN "预约"
END AS order_type,
total
FROM tmp ;
-- 指标三:订单交通类型统计
SELECT traffic_type, COUNT(1) AS total FROM db_hudi.tbl_hudi_didi GROUP BY traffic_type ;
-- 指标五:订单价格统计,先将价格划分区间,再统计,此处使用 WHEN函数和SUM函数
SELECT
SUM(
CASE WHEN pre_total_fee BETWEEN 0 AND 15 THEN 1 ELSE 0 END
) AS 0_15,
SUM(
CASE WHEN pre_total_fee BETWEEN 16 AND 30 THEN 1 ELSE 0 END
) AS 16_30,
SUM(
CASE WHEN pre_total_fee BETWEEN 31 AND 50 THEN 1 ELSE 0 END
) AS 31_50,
SUM(
CASE WHEN pre_total_fee BETWEEN 50 AND 100 THEN 1 ELSE 0 END
) AS 51_100,
SUM(
CASE WHEN pre_total_fee > 100 THEN 1 ELSE 0 END
) AS 100_
FROM
db_hudi.tbl_hudi_didi ;
执行示例:


按照 hql 语句的顺序执行就行,结果跟指标查询分析中的测试结果一致。
但是本人进行五个指标查询分析时,报 Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask 的错误。网上有资料室说是Hadoop的内存资源分配少了,按照解决方案进行配置后还是不行。也不知道什么原因,暂且搁置,后面再找找原因。
参考资料
https://www.bilibili.com/video/BV1sb4y1n7hK?p=51&vd_source=e21134e00867aeadc3c6b37bb38b9eee