TDengine 助力西门子轻量级数字化解决方案

小 T 导读:SIMICAS® OEM 设备远程运维套件是由 SIEMENS DE&DS DSM 团队开发的一套面向设备制造商的数字化解决方案。在确定选择 TDengine 作为系统的时序数据库后,他们在 SIMICAS® OEM 2.0 版本中移除了 Flink、Kafka 以及 Redis,大大简化了系统架构。
项目背景
IIoT(Industrial Internet of Things)是工业物联网的简称,它将具有感知、监控能力的各类采集、控制传感器或控制器,以及移动通信、智能分析等技术不断融入到工业生产过程的各个环节,从而大幅提高制造效率,改善产品质量,降低产品成本和资源消耗,最终实现将传统工业提升到智能化的新阶段。
通过新的互联网连接设备获取的数据可用于提高效率、实时决策、解决关键问题,并最终创造新的创新体验。然而随着相互连接的设备越来越多,公司所面临的碎片化和新挑战也越来越多。为了获取和利用数据的力量,他们需要解决方案来提供可互操作的端到端协作,从而在互联网和设备之间架起桥梁,同时驾驭即将到来的创新浪潮。
SIMICAS® OEM 设备远程运维套件是由 SIEMENS DE&DS DSM 团队开发的一套面向设备制造商的数字化解决方案,该方案借助物联网实现设备的高效远程运维,对售后服务数据进行智能分析,从而真正实现整体售后环节的降本增效。
在 IIoT 大背景的发展浪潮下,SIMICAS 为企业提供了一个踏入数字化世界的灵活选择,帮助企业根据自身发展需求定制数字化发展路径。SIMICAS 解决方案由四个部分组成:SIMICAS 智能网关、SIMICAS 组态工具,以及两个在西门子基于云的开放式物联网操作系统 MindSphere 基础上开发的 APP——SIMICAS 生产透镜和 SIMICAS 产效分析。
一、系统架构
在其 1.0 版中,我们使用了 Flink + Kafka + PostgreSQL + Redis 的架构。该系统的数据流如下:
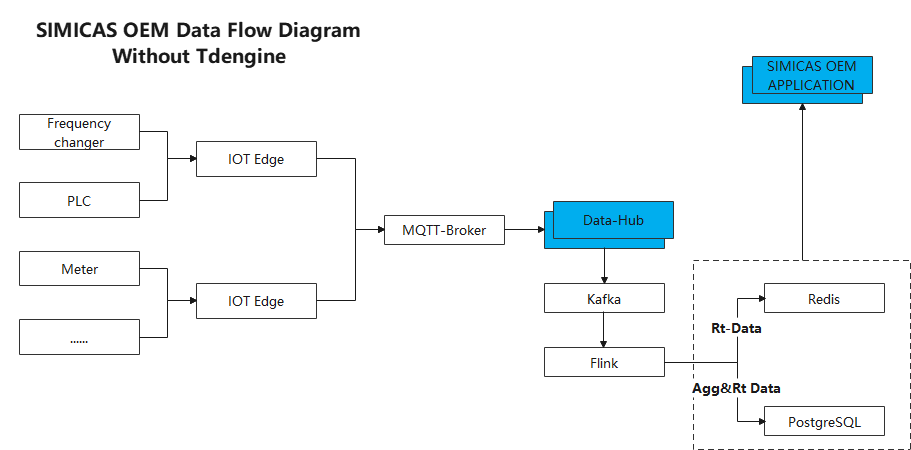
设备数据通过部署至现场的网关上传至物联网接入组件,组件根据配置对数据进行解析处理后,将其写入 Kafka 队列,Flink 从 Kafka 中消费数据并进行计算,原始值及计算后的指标数据都会被写入 PostgreSQL 中,最新值还会存一份到 Redis 中,以便更快地响应前端实时的数据查询,设备历史数据则从 PostgreSQL 中查询。
二、业务挑战
1.0 系统落地之后,我们遇到了两大挑战,一个是部署繁琐,一个是应用复杂。
具体来说,因为引入了 Flink 和 Kafka,导致系统部署时非常繁琐,服务器开销巨大;同时为了满足大量数据的存储问题,PostgreSQL 中不得不做分库分表操作,应用程序较为复杂。
如何降低系统复杂度、减少硬件资源开销,帮助客户减少成本,成为研发团队的核心任务。
三、技术选型
从产品的实际痛点出发,结合未来产品的发展规划,我们团队计划对产品的数据处理部分进行重构,在技术选型时主要考虑了如下几个方面:
- 高性能,可以支持百万级别的并发写入、万级的并发读取,大量聚合查询时依然有高性能表现
- 高可用,可支持集群部署,可横向扩展,不存在单点故障
- 低成本,数据库对硬件资源要求低,数据压缩率高
- 高度一体化,在具备以上三个特点的基础上,是否具备一定的消息队列、流式计算和缓存的功能
本着以上几个需求,在对各种开源数据平台、时序数据库(Time Series Database)进行选型对比后,我们发现 TDengine 正好符合产品重构所有的要求,尤其是低成本和高度一体化这两个点,这是目前绝大部分数据平台或时序数据库都不具备的,所以团队果断选择了 TDengine。
四、落地实践
数据流程
在确定选择 TDengine 作为系统的序数据库后,我们在 SIMICAS® OEM 2.0 版本中移除了Flink、Kafka 以及 Redis,新系统的数据流如下:

数据建模
创建数据库
数据默认保存 2 年,数据库采用 3 节点集群,数据采用 3 副本存储,保留 update 能力;
create database if not exists simicas_data keep 712 replica 3 update 2;创建实时数据表格
为平台中的每种设备类型创建一个独立的超级表(super table),为每种设备类型下的每个具体设备创建独立的设备子表。
create stable if not exists product_${productKey} (ts timestamp,linestate bool,${device_properties}) tags (device_code binary(64));
create table if not exists device_${device_code} using product_${productKey} tags (${device_code})创建状态表
为平台中所有设备创建一个共同的超级表。
create stable if not exists device_state (ts timestamp,linestate bool,run_status int,error_code binary(64),run_total_time int,stop_total_time int,error_total_time int) tags (device_code binary(64),product_key binary(64));
create table if not exists device_state_${device_code} using device_state tags (${device_code},${productKey})指标计算
我们基于 JEXL 表达式 + 实时查询的方式实现了系统中的指标计算。我们使用 JEXL 表达式来定义指标的计算表达式,系统解析后将变量替换成 SQL 查询任务,在查询返回结果后再到系统中进行计算,返回至前端。
比如计算某项目下所有设备当前电压的平均值,其表达式为 avg(voltage,run_status=1 && project=abc),它会被分解为:1)查询 run_status=1 && project=abc 的所有设备;2)查询第一步结果中所有设备 voltage 字段的最新值;3)计算第二步所有设备最新结果的平均值。
得益于多线程和 TDengine 高效的查询表现,单个 KPI 的查询 P99 表现小于 100ms。

五、遇到的问题
在 TDengine 官方推荐的最佳实践中,数据表建模建议使用多列模式,我们团队在一开始选择了这种方式,但是在实际使用中发现,部分客户的设备测点非常多,甚至超过 2000 列,这样可能会因为单行数据过大而导致插入数据 SQL 过长的问题[1] ;另一个问题是现场设备是按照“OnChange(突发上送)”方式进行数据上传,导致非常多的 NULL 值出现,在执行 select last(*) from device_xxx 时效率较低[2]。

在与 TDengine 官方的技术人员沟通后,我们了解到,last 函数是对每列进行查找,直到最近一条非 NULL 值为止,在当时的版本下,cache 对 last 函数是无效的。
后来,团队通过对项目中单个设备参数的最大数量进行限制,解决了问题[1];又通过修改设备数据的上传方式,解决了问题[2]。
但是在根本上,还是我们在最初建模时,没有充分考虑到客户的业务场景,从而导致了以上问题。因此,我们团队后续在系统中实现了同时支持多列模式和单列模式,这样客户就可以根据现场的实际情况,自由切换建模方式。
六、写在最后
与其他开源数据平台或数据库相比,目前 TDengine 的运维监控能力还不算强大,不过前段时间发布的 TDinsight 已经带来了很多改进,我们团队也规划在下一阶段试用一下。
特别感谢涛思数据的陈伟灿及其他同事在产品开发过程给予的支持,虽然在过程中遇到一些问题,但整体而言,TDengine 的各项优异表现给了我们团队很多惊喜。
最后期待 TDengine越来越好,帮助更多客户、更多场景降本增效!
想了解更多 TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。