ClickHouse入门到精通
一 clickhouse-简介
ClickHouse是俄罗斯的Yandex于2016年开源的一个用于联机分析(OLAP:Online Analytical Processing)的列式数据库管理系统(DBMS:Database Management System) , 主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。 ClickHouse的全称是Click Stream,Data WareHouse,简称ClickHouse
ClickHouse是一个完全的列式分布式数据库管理系统(DBMS),允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器,支持线性扩展,简单方便,高可靠性,容错。它的系统在生产环境中可以应用到比较大的规模,因为它的线性扩展能力和可靠性保障能够原生支持 shard + replication 这种解决方案。它还提供了一些 SQL 直接接口,有比较丰富的原生 client。
补充OLAP概念
OLAP(OnLine Analytical Processing),即联机分析处理。OLAP对业务数据执行多维分析,并提供复杂计算,趋势分析和复杂数据建模的能力。它主要用于支持企业决策管理分析,是许多商务智能(BI)应用程序背后的技术。OLAP使最终用户可以对多个维度的数据进行即席分析,从而获取他们所需知识,以便更好地制定决策。OLAP技术已被定义为实现“快速访问共享的多维信息”的能力。
1 优点
-
灵活的MPP架构(将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果),支持线性扩展,简单方便,高可靠性
-
多服务器分布式处理数据 ,完备的DBMS系统
-
底层数据列式存储,支持压缩,优化数据存储,优化索引数据 优化底层存储
-
容错跑分快:比Vertica快5倍,比Hive快279倍,比MySQL快800倍,其可处理的数据级别已达到10亿级别
-
功能多:支持数据统计分析各种场景,支持类SQL查询,异地复制部署
海量数据存储,分布式运算,快速闪电的性能,几乎实时的数据分析 ,友好的SQL语法,出色的函数支持
2 缺点
- 不支持事务,不支持真正的删除/更新
- 不支持高并发,官方建议qps为100,可以通过修改配置文件增加连接数,但是在服务器足够好的情况下
- 不支持二级索引
- 不擅长多表join *** 大宽表
- 元数据管理需要人为干预 ***
- 尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作
3 应用场景
1.绝大多数请求都是用于读访问的, 要求实时返回结果
2.数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作
3.数据只是添加到数据库,没有必要修改
4.读取数据时,会从数据库中提取出大量的行,但只用到一小部分列
5.表很“宽”,即表中包含大量的列
6.查询频率相对较低(通常每台服务器每秒查询数百次或更少)
7.对于简单查询,允许大约50毫秒的延迟
8.列的值是比较小的数值和短字符串(例如,每个URL只有60个字节)
9.在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)
10.不需要事务
11.数据一致性要求较低 [原子性 持久性 一致性 隔离性]
12.每次查询中只会查询一个大表。除了一个大表,其余都是小表
13.查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小
4 概念
1) 列式存储
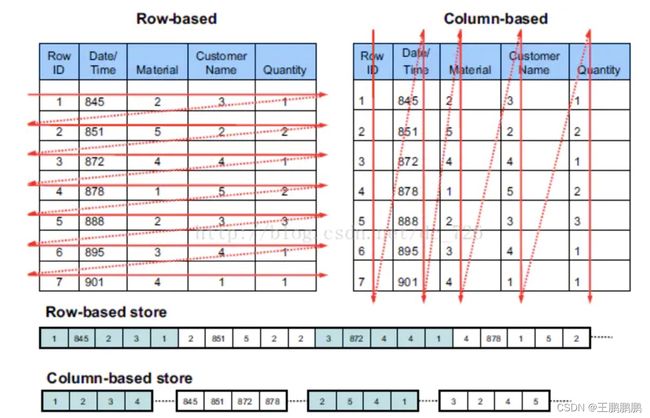
1)分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个块中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO时间,加速了查询。
- 查询时只有涉及到的列会被读取
- 任何列都能作为索引
2)同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
3)更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
官方数据显示,通过使用列存,在某些分析场景下,能够获得100倍甚至更高的加速效应。

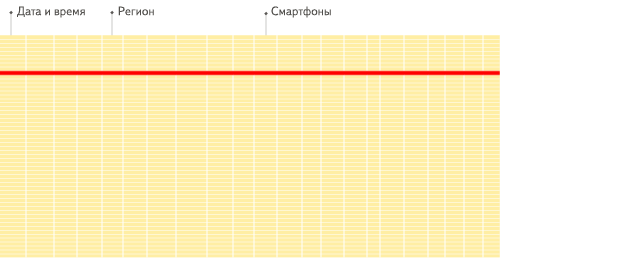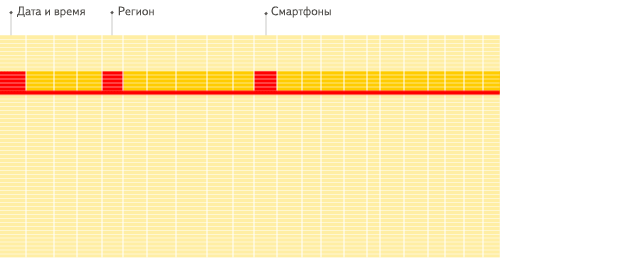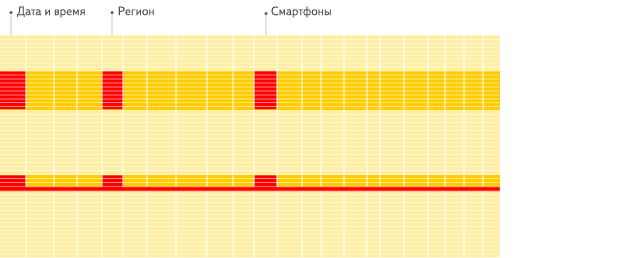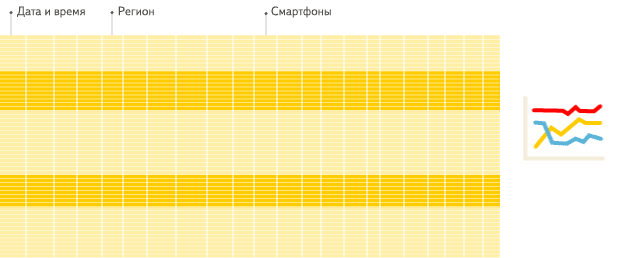
2)多索引
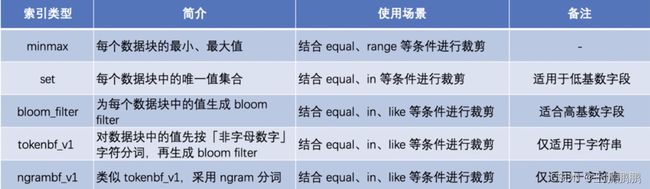
列存用于裁剪不必要的字段读取,而索引则用于裁剪不必要的记录读取。ClickHouse 支持丰富的索引,从而在查询时尽可能的裁剪不必要的记录读取,提高查询性能。
ClickHouse 中最基础的索引是主键索引。前面我们在物理存储模型中介绍,ClickHouse 的底层数据按建表时指定的 ORDER BY 列进行排序,并按 index_granularity 参数切分成数据块,然后抽取每个数据块的第一行形成一份稀疏的排序索引。
用户在查询时,如果查询条件包含主键列,则可以基于稀疏索引进行快速的裁剪。
说明:

当用户查询 CounterID equal ‘h’ 的数据时,根据索引信息,只需要读取 Mark number 为 6 和 7 的两个数据块。
3) 向量化
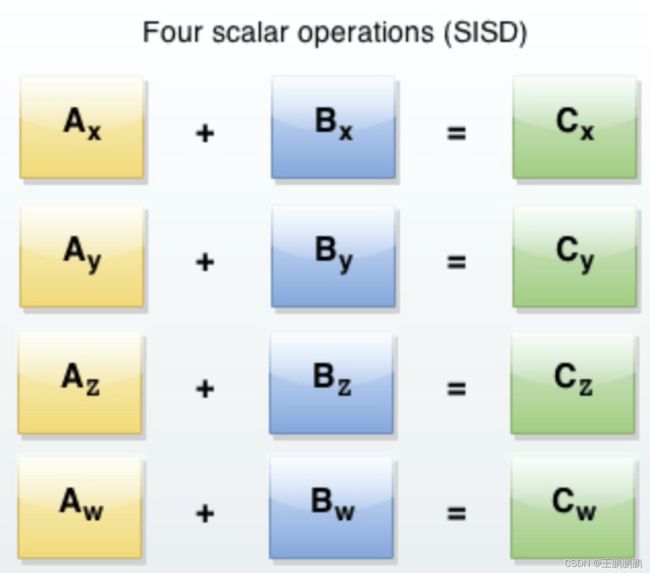
ClickHouse实现了向量执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
(SIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。以同步方式,在同一时间内执行同一条指令。)
以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使SIMD特别适合于多媒体应用等数据密集型运算。
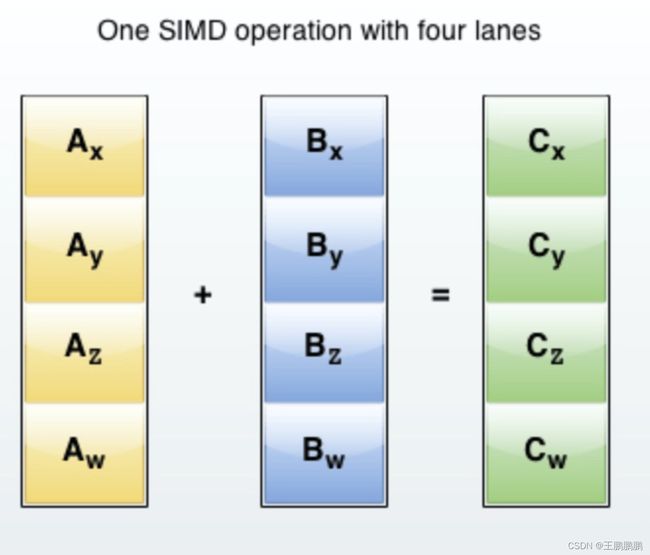
使用实例:
simd.js
a = SIMD.Float32x4(1, 2, 3, 4);
b = SIMD.Float32x4(5, 6, 7, 8);
c = SIMD.Float32x4.add(a,b);
Chrome / Firefox 对提供了特殊的加速,直接利用 CPU 的 SIMD 功能
c
#include
int SumAarray(int *buf,int N)
{
int i;
I32vec4 *vec4 = (I32vec4 *)buf;
I32vec4 sum(0,0,0,0);
for(i=0;i自动矢量化
c嵌入汇编
3) 分区与分片
分区是表的分区,具体的DDL操作关键词是 PARTITION BY,指的是一个表按照某一列数据(比如日期)进行分区,对应到最终的结果就是不同分区的数据会写入不同的文件中。
分片复用了数据库的分区,相当于在原有的分区下,作为第二层分区, 是在不同节点/机器上的体现。
具体关系如下:
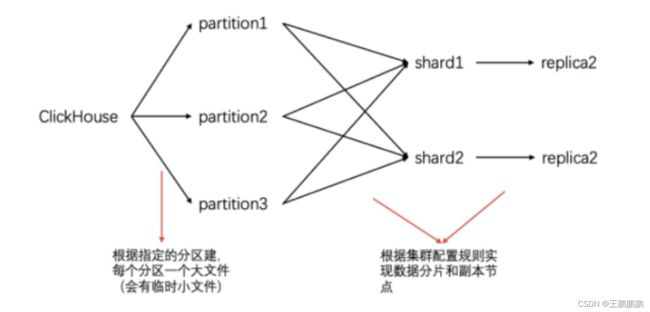
数据分区-允许查询在指定了分区键的条件下,尽可能的少读取数据
数据分片-允许多台机器/节点同并行执行查询,实现了分布式并行计算
4) 副本
数据存储副本,在集群模式下实现高可用 , 简单理解就是相同的数据备份,在CK中通过复制集,我们实现保障了数据可靠性外,也通过多副本的方式,增加了CK查询的并发能力。
7) 引擎
不同的引擎决定了表数据的存储特点,位置和表数据的操作行为:
-
决定表存储在哪里以及以何种方式存储
-
支持哪些查询以及如何支持
-
并发数据访问
-
索引的使用
-
是否可以执行多线程请求
-
数据复制参数
表引擎决定了数据在文件系统中的存储方式,常用的也是官方推荐的存储引擎是MergeTree系列,如果需要数据副本的话可以使用ReplicatedMergeTree系列,相当于MergeTree的副本版本。读取集群数据需要使用分布式表引擎Distribute。
二 引擎详解
表引擎是ClickHouse设计实现中的一大特色 ,数据表拥有何种特性、数据以何 种形式被存储以及如何被加载。ClickHouse拥有非常庞大的表引擎体系,其共拥有合并树、外部存储、内存、文件、接口 和其他6大类20多种表引擎。而在这众多的表引擎中,又属合并树 (MergeTree)表引擎及其家族系列(*MergeTree)最为强大,在生产 环境的绝大部分场景中,都会使用此系列的表引擎。因为只有合并树系 列的表引擎才支持主键索引、数据分区、数据副本和数据采样这些特 性,同时也只有此系列的表引擎支持ALTER相关操作。
合并树家族自身也拥有多种表引擎的变种。其中MergeTree作为家 族中最基础的表引擎,提供了主键索引、数据分区、数据副本和数据采 样等基本能力,而家族中其他的表引擎则在MergeTree的基础之上各有 所长。例如ReplacingMergeTree表引擎具有删除重复数据的特性,而 SummingMergeTree表引擎则会按照排序键自动聚合数据。如果给合并树 系列的表引擎加上Replicated前缀,又会得到一组支持数据副本的表引 擎,例如ReplicatedMergeTree、ReplicatedReplacingMergeTree、 ReplicatedSummingMergeTree等。
公司默认:MergeTree
还支持通过编写视图的方式指定引擎
去重ReplacingMergeTree
聚合AggregatingMergeTree
求和SummingMergeTree暂不支持
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kKpDTaoj-1641804074975)(assets/16262562608384.jpg)]
表引擎(即表的类型)决定了:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数,是否可以存储数据副本。
… …
2.1 Log系列引擎
Log家族具有最小功能的[轻量级引擎。当您需要快速写入许多小表(最多约100万行)并在以后整体读取它们时,该类型的引擎是最有效的。
1.1 TinyLog引擎
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中,写入时,数据将附加到文件末尾。该引擎没有并发控制
1、最简单的引擎
2、没有索引,没有标记块
3、写是追加写
4、数据以列字段文件存储
5、不允许同时读写
-- 建表
create table test_tinylog(
id UInt8 ,
name String ,
age UInt8
)engine=TinyLog ;
-- 插入数据
insert into test_tinylog values(1,'liubei',45),(2,'guanyu',43),(3,'zhangfei',41) ;
SELECT *
FROM test_tinylog
┌─id─┬─name─────┬─age─┐
│ 1 │ liubei │ 45 │
│ 2 │ guanyu │ 43 │
│ 3 │ zhangfei │ 41 │
└────┴──────────┴─────┘
查看数底层存储
[root@doit01 test_tinylog]# pwd
/var/lib/clickhouse/data/default/test_tinylog
-rw-r-----. 1 clickhouse clickhouse 29 May 19 15:29 age.bin
-rw-r-----. 1 clickhouse clickhouse 29 May 19 15:29 id.bin
-rw-r-----. 1 clickhouse clickhouse 50 May 19 15:29 name.bin
-rw-r-----. 1 clickhouse clickhouse 90 May 19 15:29 sizes.json
-- 当再次插入数据以后 , 在每个文件中追加写入的
-rw-r-----. 1 clickhouse clickhouse 58 May 19 15:31 age.bin
-rw-r-----. 1 clickhouse clickhouse 58 May 19 15:31 id.bin
-rw-r-----. 1 clickhouse clickhouse 100 May 19 15:31 name.bin
-rw-r-----. 1 clickhouse clickhouse 91 May 19 15:31 sizes.json
insert into t select * from t 会将表存储结构损坏 : 删除表目录 删除元数据
1.2 StripeLog引擎
1、data.bin存储所有数据
2、index.mrk 对数据建立索引
3、size.json 数据大小
4、并发读写
create table test_stripelog(
id UInt8 ,
name String ,
age UInt8
)engine=StripeLog ;
-- 插入数据
insert into test_stripelog values(1,'liubei',45),(2,'guanyu',43),(3,'zhangfei',41) ;
查看底层数据
/var/lib/clickhouse/data/default/test_stripelog
-rw-r-----. 1 clickhouse clickhouse 167 May 19 15:43 data.bin 存储所有列的数据
-rw-r-----. 1 clickhouse clickhouse 75 May 19 15:43 index.mrk 记录数据的索引信息
-rw-r-----. 1 clickhouse clickhouse 68 May 19 15:43 sizes.json 记录文件内容的大小
1.3 Log引擎
日志与 TinyLog 的不同之处在于,«标记» 的小文件与列文件存在一起。这些标记写在每个数据块上,并且包含偏移量,这些偏移量指示从哪里开始读取文件以便跳过指定的行数。这使得可以在多个线程中读取表数据。对于并发数据访问,可以同时执行读取操作,而写入操作则阻塞读取和其它写入。Log 引擎不支持索引。同样,如果写入表失败,则该表将被破坏,并且从该表读取将返回错误。Log 引擎适用于临时数据,write-once 表以及测试或演示目的。
1、*.bin存储每个字段的数据
2、mark.mrk 数据块标记
3、支持多线程处理
4、并发读写
create table test_log(
id UInt8 ,
name String ,
age UInt8
)engine=Log ;
insert into test_log values(1,'liubei',45),(2,'guanyu',43),(3,'zhangfei',41) ;
查看数据
-rw-r-----. 1 clickhouse clickhouse 29 May 19 15:46 age.bin
-rw-r-----. 1 clickhouse clickhouse 29 May 19 15:46 id.bin
-rw-r-----. 1 clickhouse clickhouse 48 May 19 15:46 __marks.mrk
-rw-r-----. 1 clickhouse clickhouse 50 May 19 15:46 name.bin
-rw-r-----. 1 clickhouse clickhouse 120 May 19 15:46 sizes.json
Log 和 StripeLog 引擎支持:
并发访问数据的锁。
INSERT 请求执行过程中表会被锁定,并且其他的读写数据的请求都会等待直到锁定被解除。如果没有写数据的请求,任意数量的读请求都可以并发执行。
并行读取数据。
在读取数据时,ClickHouse 使用多线程。 每个线程处理不同的数据块。
Log 引擎为表中的每一列使用不同的文件。StripeLog 将所有的数据存储在一个文件中。因此 StripeLog 引擎在操作系统中使用更少的描述符,但是 Log 引擎提供更高的读性能。
TinyLog 引擎是该系列中最简单的引擎并且提供了最少的功能和最低的性能。TingLog 引擎不支持并行读取和并发数据访问,并将每一列存储在不同的文件中。它比其余两种支持并行读取的引擎的读取速度更慢,并且使用了和 Log 引擎同样多的描述符。你可以在简单的低负载的情景下使用它。
2.2 MergeTree系列引擎
MergeTree系列的表引擎是ClickHouse数据存储功能的核心。它们提供了用于弹性和高性能数据检索的大多数功能。
基本MergeTree表引擎可以被认为是单节点ClickHouse实例的默认表引擎,因为它在各种用例中通用且实用。
除了基础表引擎MergeTree之 外,常用的表引擎还有ReplacingMergeTree、SummingMergeTree、 AggregatingMergeTree、CollapsingMergeTree和 VersionedCollapsingMergeTree。每一种合并树的变种,在继承了基 础MergeTree的能力之后,又增加了独有的特性。其名称中的“合并” 二字奠定了所有类型MergeTree的基因,它们的所有特殊逻辑,都是在 触发合并的过程中被激活的。
主要特点:
-
存储按主键排序的数据。
-
如果指定了[分区键]则可以使用分区。
ClickHouse支持的某些分区操作比对相同数据,相同结果的常规操作更有效。ClickHouse还会自动切断在查询中指定了分区键的分区数据。这也提高了查询性能。
- 数据复制支持。
ReplicatedMergeTree表族提供数据复制。有关更多信息.
- 数据采样支持。
如有必要,可以在表中设置数据采样方法。
2.1 MergeTree引擎
MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成 一个新的片段。这种数据片段往复合并的特点,也正是合并树名称的由来。
MergeTree表引擎除了常规参数之外,还拥有一些独有的配置选 项。接下来会着重介绍其中几个重要的参数,
(1)PARTITION BY [选填]:分区键,用于指定表数据以何种标 准进行分区。分区键既可以是单个列字段,也可以通过元组的形式使 用多个列字段,同时它也支持使用列表达式。如果不声明分区键,则 ClickHouse会生成一个名为all的分区。合理使用数据分区,可以有效 减少查询时数据文件的扫描范围。
(2)ORDER BY [必填]:排序键,用于指定在一个数据片段内, 数据以何种标准排序。默认情况下主键(PRIMARY KEY)与排序键相 同。排序键既可以是单个列字段,例如ORDER BY CounterID,也可以 通过元组的形式使用多个列字段,例如ORDER BY(CounterID,EventDate)。当使用多个列字段排序时,以ORDER BY(CounterID,EventDate)为例,在单个数据片段内,数据首先会以 CounterID排序,相同CounterID的数据再按EventDate排序。(3)PRIMARY KEY [选填]:主键,顾名思义,声明后会依照主键 字段生成一级索引,用于加速表查询。默认情况下,主键与排序键 (ORDER BY)相同,所以通常直接使用ORDER BY代为指定主键,无须刻 意通过PRIMARY KEY声明。所以在一般情况下,在单个数据片段内,数 据与一级索引以相同的规则升序排列。与其他数据库不同,MergeTree 主键允许存在重复数据(ReplacingMergeTree可以去重)。
(4)SAMPLE BY [选填]:抽样表达式,用于声明数据以何种标准 进行采样。如果使用了此配置项,那么在主键的配置中也需要声明同 样的表达式,例如:
省略... ) ENGINE = MergeTree() ORDER BY (CounterID, EventDate, intHash32(UserID) SAMPLE BY intHash32(UserID)(5)SETTINGS:index_granularity对于MergeTree而言是一项非常重要的参数,它表 示索引的粒度,默认值为8192。也就是说,MergeTree的索引在默认情 况下,每间隔8192行数据才生成一条索引,其具体声明方式如下所 示:
省略... ) ENGINE = MergeTree() 省略... SETTINGS index_granularity = 8192;
1) 创建表
create table tb_merge_tree(
id Int8 ,
city String ,
ctime Date
)
engine=MergeTree()
order by id
partition by city ;
2)导入数据
insert into tb_merge_tree values(1,'BJ',now()) ,(2,'NJ',now()),(3,'DJ',now());
insert into tb_merge_tree values(4,'BJ',now()) ,(5,'NJ',now()),(6,'DJ',now());
insert into tb_merge_tree values(7,'BJ',now()) ,(8,'NJ',now()),(9,'DJ',now());
insert into tb_merge_tree values(10,'BJ',now()) ,(11,'NJ',now()),(12,'DJ',now());
3)合并数据
┌─id─┬─city─┬──────ctime─┐
│ 9 │ DJ │ 2021-05-19 │
└────┴──────┴────────────┘
┌─id─┬─city─┬──────ctime─┐
│ 2 │ NJ │ 2021-05-19 │
└────┴──────┴────────────┘
┌─id─┬─city─┬──────ctime─┐
│ 5 │ NJ │ 2021-05-19 │
└────┴──────┴────────────┘
┌─id─┬─city─┬──────ctime─┐
│ 12 │ DJ │ 2021-05-19 │
└────┴──────┴────────────┘
┌─id─┬─city─┬──────ctime─┐
│ 8 │ NJ │ 2021-05-19 │
└────┴──────┴────────────┘
┌─id─┬─city─┬──────ctime─┐
│ 11 │ NJ │ 2021-05-19 │
└────┴──────┴────────────┘
┌─id─┬─city─┬──────ctime─┐
│ 1 │ BJ │ 2021-05-19 │
└────┴──────┴────────────┘
┌─id─┬─city─┬──────ctime─┐
│ 3 │ DJ │ 2021-05-19 │
└────┴──────┴────────────┘
┌─id─┬─city─┬──────ctime─┐
│ 4 │ BJ │ 2021-05-19 │
└────┴──────┴────────────┘
┌─id─┬─city─┬──────ctime─┐
│ 6 │ DJ │ 2021-05-19 │
└────┴──────┴────────────┘
┌─id─┬─city─┬──────ctime─┐
│ 7 │ BJ │ 2021-05-19 │
└────┴──────┴────────────┘
┌─id─┬─city─┬──────ctime─┐
│ 10 │ BJ │ 2021-05-19 │
└────┴──────┴────────────┘
optimize table tb_merge_tree final ; 一次性按照分区合并所有的数据
SELECT *
FROM tb_merge_tree
┌─id─┬─city─┬──────ctime─┐
│ 3 │ DJ │ 2021-05-19 │
│ 6 │ DJ │ 2021-05-19 │
│ 9 │ DJ │ 2021-05-19 │
│ 12 │ DJ │ 2021-05-19 │
└────┴──────┴────────────┘
┌─id─┬─city─┬──────ctime─┐
│ 2 │ NJ │ 2021-05-19 │
│ 5 │ NJ │ 2021-05-19 │
│ 8 │ NJ │ 2021-05-19 │
│ 11 │ NJ │ 2021-05-19 │
└────┴──────┴────────────┘
┌─id─┬─city─┬──────ctime─┐
│ 1 │ BJ │ 2021-05-19 │
│ 4 │ BJ │ 2021-05-19 │
│ 7 │ BJ │ 2021-05-19 │
│ 10 │ BJ │ 2021-05-19 │
└────┴──────┴────────────┘
CK内部会自动的合并分区的数据, 也会删除多余的文件夹中的数据
4)数据存储原理
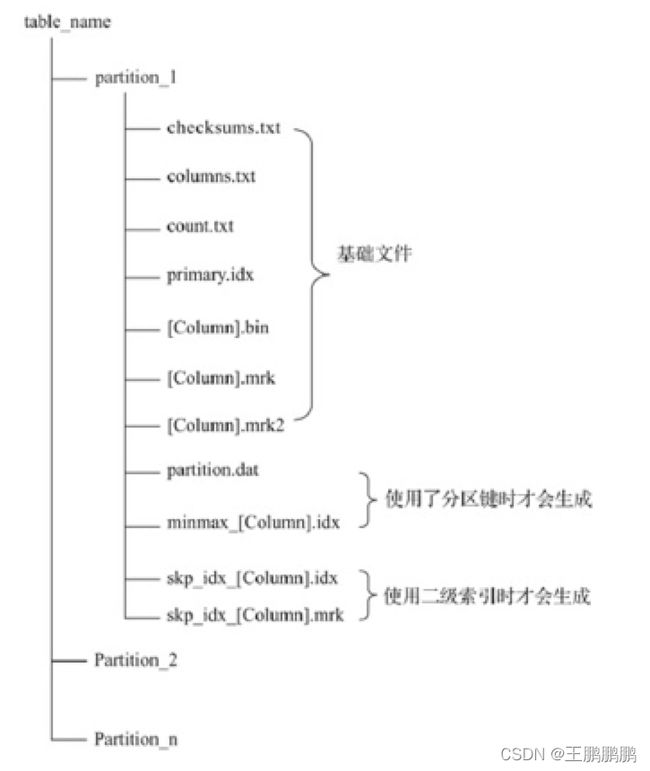
(1)partition:分区目录,余下各类数据文件(primary.idx、 [Column].mrk、[Column].bin等)都是以分区目录的形式被组织存放 的,属于相同分区的数据,最终会被合并到同一个分区目录,而不同分 区的数据,永远不会被合并在一起。
(2)checksums.txt:校验文件,使用二进制格式存储。它保存了余下各类文件(primary.idx、count.txt等)的size大小及size的哈希值,用于快速校验文件的完整性和正确性。
(3)columns.txt:列信息文件,使用明文格式存储。用于保存此数据分区下的列字段信息
(4)count.txt:计数文件,使用明文格式存储。用于记录当前数 据分区目录下数据的总行数
(5)primary.idx:一级索引文件,使用二进制格式存储。用于存放稀疏索引,一张MergeTree表只能声明一次一级索引(通过ORDER BY 或者PRIMARY KEY)。借助稀疏索引,在数据查询的时能够排除主键条 件范围之外的数据文件,从而有效减少数据扫描范围,加速查询速度。
(6)[Column].bin:数据文件,使用压缩格式存储,默认为LZ4压缩格式,用于存储某一列的数据。由于MergeTree采用列式存储,所以每一个列字段都拥有独立的.bin数据文件,并以列字段名称命名(例如 CounterID.bin、EventDate.bin等)。
(7)[Column].mrk:列字段标记文件,使用二进制格式存储。标记文件中保存了.bin文件中数据的偏移量信息。标记文件与稀疏索引对齐,又与.bin文件一一对应,所以MergeTree通过标记文件建立了 primary.idx稀疏索引与.bin数据文件之间的映射关系。即首先通过稀疏索引(primary.idx)找到对应数据的偏移量信息(.mrk),再通过 偏移量直接从.bin文件中读取数据。由于.mrk标记文件与.bin文件一一对应,所以MergeTree中的每个列字段都会拥有与其对应的.mrk标记文件(例如CounterID.mrk、EventDate.mrk等)。
(8)[Column].mrk2:如果使用了自适应大小的索引间隔.则标记 文件会以.mrk2命名。它的工作原理和作用与.mrk标记文件相同。
2.2 ReplacingMergeTree
这个引擎是在 MergeTree 的基础上,添加了“处理重复数据”的功能,该引擎和MergeTree的不同之处在于它会删除具有相同(区内)排序一样的重复项。数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。因此,ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
1 无版本参数
-- 主键oid 排序字段两个 验证去重规则是按主键还是排序字段
drop table if exists test_replacingMergeTree2 ;
create table test_replacingMergeTree2(
oid Int8 ,
ctime DateTime ,
cost Decimal(10,2)
)engine = ReplacingMergeTree()
primary key oid
order by (oid ,ctime)
partition by toDate(ctime) ;
insert into test_replacingMergeTree2 values(1,'2021-01-01 11:11:11',10) ;
insert into test_replacingMergeTree2 values(1,'2021-01-01 11:11:11',20) ;
insert into test_replacingMergeTree2 values(1,'2021-01-01 11:11:11',30);
insert into test_replacingMergeTree2 values(1,'2021-01-01 11:11:12',40) ;
insert into test_replacingMergeTree2 values(1,'2021-01-01 11:11:13',50) ;
-- 由此可见 去重并不是根据主键,而知根据区内排序相同的数据会被删除
┌─oid─┬───────────────ctime─┬──cost─┐
│ 1 │ 2021-01-01 11:11:11 │ 10.00 │
│ 1 │ 2021-01-01 11:11:12 │ 40.00 │
│ 1 │ 2021-01-01 11:11:13 │ 50.00 │
└─────┴─────────────────────┴───────┘
2 有版本参数
- 版本字段可以是数值
- 版本字段可以是时间
drop table if exists test_replacingMergeTree3 ;
create table test_replacingMergeTree3(
oid Int8 ,
ctime DateTime ,
cost Decimal(10,2)
)engine = ReplacingMergeTree(ctime)
order by oid
partition by toDate(ctime) ;
insert into test_replacingMergeTree3 values(1,'2021-01-01 11:11:11',10) ;
insert into test_replacingMergeTree3 values(1,'2021-01-01 11:11:12',20) ;
insert into test_replacingMergeTree3 values(1,'2021-01-01 11:11:10',30);
insert into test_replacingMergeTree3 values(1,'2021-01-01 11:11:19',40) ;
insert into test_replacingMergeTree3 values(1,'2021-01-01 11:11:13',50) ;
-- 合并数据以后 保留的是时间最近的一条数据
┌─oid─┬───────────────ctime─┬──cost─┐
│ 1 │ 2021-01-01 11:11:19 │ 40.00 │
└─────┴─────────────────────┴───────┘
总结:
(1)使用ORDER BY排序键作为判断重复数据的唯一依据。
(2)只有在合并分区的时候才会触发删除重复数据的逻辑。
(3)以数据分区为单位删除重复数据。当分区合并时,同一分区内的重复数据会被删除;不同分区之间的重复数据不会被删除。
(4)在进行数据去重时,因为分区内的数据已经基于ORBER BY进行了排序,所以能够找到那些相邻的重复数据。
(5)数据去重策略有两种:
- 如果没有设置ver版本号,则保留同一组重复数据中的最后一行。
- 如果设置了ver版本号,则保留同一组重复数据中ver字段取值 最大的那一行。
2.3 CollapsingMergeTree
CollapsingMergeTree就是一种通过以增代删的思路,支持行级数 据修改和删除的表引擎。它通过定义一个sign标记位字段,记录数据行 的状态。如果sign标记为1,则表示这是一行有效的数据;如果sign标 记为-1,则表示这行数据需要被删除。当CollapsingMergeTree分区合 并时,同一数据分区内,sign标记为1和-1的一组数据会被抵消删除。 这种1和-1相互抵消的操作,犹如将一张瓦楞纸折叠了一般。这种直观 的比喻,想必也正是折叠合并树(CollapsingMergeTree)名称的由来,
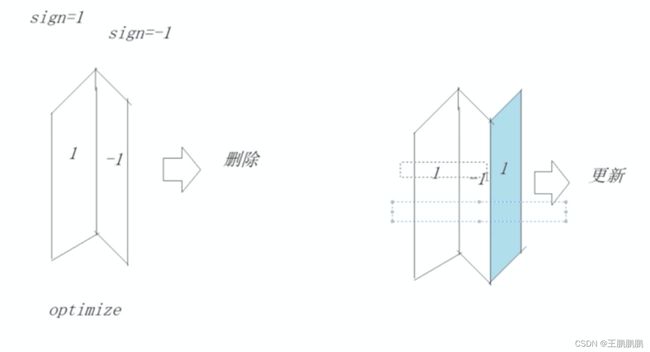
多行的排序相同的状态为1的数据会折叠成一行
ENGINE = CollapsingMergeTree(sign)
drop table if exists tb_cps_merge_tree1 ;
CREATE TABLE tb_cps_merge_tree1
(
user_id UInt64,
name String,
age UInt8,
sign Int8
)
ENGINE = CollapsingMergeTree(sign)
ORDER BY user_id;
-- 插入数据
insert into tb_cps_merge_tree1 values(1,'xiaoluo',23,1),(2,'xiaoyu',24,1),(3,'xiaofeng',25,1) ;
insert into tb_cps_merge_tree1 values(1,'xiaoluo_',23,-1),(2,'xiaoyu_',24,-1),(3,'xiaofeng2',25,1) ;
-- 合并优化
optimize table tb_cps_merge_tree1 ;
-- 实现了数据的删除和已经存在数据的更新
SELECT *
FROM tb_cps_merge_tree1
┌─user_id─┬─name──────┬─age─┬─sign─┐
│ 3 │ xiaofeng2 │ 25 │ 1 │
└─────────┴───────────┴─────┴──────┘
2.4 SummingMergeTree
假设有这样一种查询需求:终端用户只需要查询数据的汇总结果,不关心明细数据,并且数据的汇总条件是预先明确的(GROUP BY 条件明确,且不会随意改变)。
对于这样的查询场景,在ClickHouse中如何解决呢?最直接的方 案就是使用MergeTree存储数据,然后通过GROUP BY聚合查询,并利用 SUM聚合函数汇总结果。这种方案存在两个问题。
- 存在额外的存储开销:终端用户不会查询任何明细数据,只关心汇总结果,所以不应该一直保存所有的明细数据。
- 存在额外的查询开销:终端用户只关心汇总结果,虽然 MergeTree性能强大,但是每次查询都进行实时聚合计算也是一种性能消耗。
SummingMergeTree就是为了应对这类查询场景而生的。顾名思义,它能够在合并分区的时候按照预先定义的条件聚合汇总数据,将同一分组下的多行数据汇总合并成一行,这样既减少了数据行,又降低了后续汇总查询的开销。
CREATE TABLE summing_table2(
id String,
city String,
money UInt32,
num UInt32,
ctime DateTime
)ENGINE = SummingMergeTree(money)
PARTITION BY toDate(ctime)
ORDER BY city ;
--每个城市每天的销售总额
insert into summing_table2 values(1,'BJ',100,11,now()),
(2,'BJ',100,11,now()),
(3,'BJ',100,11,now()),
(4,'NJ',100,11,now()),
(5,'NJ',100,11,now()),
(6,'SH',100,11,now()),
(7,'BJ',100,11,'2021-05-18 11:11:11'),
(8,'BJ',100,11,'2021-05-18 11:11:11') ;
SELECT *
FROM summing_table2 ;
┌─id─┬─city─┬─money─┬─num─┬───────────────ctime─┐
│ 1 │ BJ │ 300 │ 11 │ 2021-05-19 21:53:49 │
│ 4 │ NJ │ 200 │ 11 │ 2021-05-19 21:53:49 │
│ 6 │ SH │ 100 │ 11 │ 2021-05-19 21:53:49 │
└────┴──────┴───────┴─────┴─────────────────────┘
┌─id─┬─city─┬─money─┬─num─┬───────────────ctime─┐
│ 7 │ BJ │ 200 │ 11 │ 2021-05-18 11:11:11 │
└────┴──────┴───────┴─────┴─────────────────────┘
2.5 AggregatingMergeTree
AggregatingMergeTree就有些许数据立方体的意思,它能够在合并分区的时候,按照预先定义的条件聚合数据。同时,根据预先定义的聚合函数计算数据并通过二进制的格式存入表内。将同一分组下的多行数据聚合成一行,既减少了数据行,又降低了后续聚合查询的开销。可以说,AggregatingMergeTree 是SummingMergeTree的升级版,它们的许多设计思路是一致的,例如同时定义 ORDER BY与PRIMARY KEY的原因和目的。但是在使用方法上,两者存在明显差异,应该说AggregatingMergeTree的定义方式是MergeTree家族中最为特殊的一个。
2.3 外部存储引擎
3.1 HDFS引擎
Clickhouse可以直接从HDFS中指定的目录下加载数据 , 自己根本不存储数据, 仅仅是读取数据
ENGINE = HDFS(hdfs_uri,format)
·hdfs_uri表示HDFS的文件存储路径;
·format表示文件格式(指ClickHouse支持的文件格式,常见的有 CSV、TSV和JSON等)。
我们一般期望的是数据有其他方式写入到HDFS系统中, 使用CK的HDFS引擎加载处理分析数据.
这种形式类似Hive的外挂表,由其他系统直接将文件写入HDFS。通过HDFS表引擎的hdfs_uri和format参数分别与HDFS的文件路径、文件格式建立映射。其中,hdfs_uri支持以下几种常见的配置方法:
-
绝对路径:会读取指定路径的单个文件,例如/clickhouse/hdfs_table1。
-
通配符:匹配所有字符,例如路径为/clickhouse/hdfs_table/,则会读取/click-house/hdfs_table路径下的所有文件。
-
?通配符:匹配单个字符,例如路径为/clickhouse/hdfs_table/organization_?.csv,则会读取/clickhouse/hdfs_table路径下与organization_?.csv匹配的文件,其中?代表任意一个合法字符。
-
{M…N}数字区间:匹配指定数字的文件,例如路径为/clickhouse/hdfs_table/organization_{1…3}.csv,则会读取/clickhouse/hdfs_table/路径下的文件organization_1.csv、organization_2.csv和organization_3.csv。
create table test_hdfs1(
id Int8 ,
name String ,
age Int8
)engine=HDFS('hdfs://linux01:8020/ck/test1/*' ,CSV) ;
创建文件,将文件上传到指定的目录下
1.txt
1,zss,21
2,ww,22
2.txt
3,lss,33
4,qaa,32
3.txt
5,as,31
6,ghf,45
--匹配单个字符
create table test_hdfs2(
id Int8 ,
name String ,
age Int8
)engine=HDFS('hdfs://linux01:8020/ck/test1/?.txt' ,CSV) ;
-- 匹配数字之间的文件
create table test_hdfs3(
id Int8 ,
name String ,
age Int8
)engine=HDFS('hdfs://linux01:8020/ck/test1/a_{1..2}.txt' ,CSV) ;
3.2 mysql引擎
MySQL表引擎可以与MySQL数据库中的数据表建立映射,并通过SQL向其发起远程查询, 包括SELECT和INSERT
它的声明方式如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
) ENGINE = MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause']);
那么在正式使用MySQL引擎之前首先当前机器要有操作MySQL数据的权限 ,开放MySQL的远程连连接权限
- 支持查询数据
- 支持插入数据
- 不支持删除和更新操作
3.3 File引擎
File表引擎能够直接读取本地文件的数据,通常被作为一种扩充手段来使用。例如:它可以读取由其他系统生成的数据文件,如果外部系统直接修改了文件,则变相达到了数据更新的目的;它可以将 ClickHouse数据导出为本地文件;它还可以用于数据格式转换等场景。除此以外,File表引擎也被应用于clickhouse-local工具
ENGINE = File(format)
drop table if exists test_file1 ;
create table test_file1(
id String ,
name String ,
age UInt8
)engine=File("CSV") ;
在默认的目录下回生成一个文件夹 , 文件夹中可以写入文件 ,但是文件的名字必须是data.CSV
insert into test_file1 values('u001','hangge',33) ;
file表函数
– 去指定的路径下加载本地的数据
select * from file('/ck/user.txt','CSV','id Int8 , name String ,gender String,age UInt8') ;
2.4 内存引擎
接下来将要介绍的几款表引擎,都是面向内存查询的,数据会从内存中被直接访问,所以它们被归纳为内存类型。但这并不意味着内存类表引擎不支持物理存储,事实上,除了Memory表引擎之外,其余的几款表引擎都会将数据写入磁盘,这是为了防止数据丢失,是一种故障恢复手段。而在数据表被加载时,它们会将数据全部加载至内存,以供查询之用。将数据全量放在内存中,对于表引擎来说是一把双刃剑:一方面,这意味着拥有较好的查询性能;而另一方面,如果表内装载的数据量过大,可能会带来极大的内存消耗和负担!
4.1 Memory
Memory表引擎直接将数据保存在内存中,数据既不会被压缩也不会被格式转换,数据在内存中保存的形态与查询时看到的如出一辙。 正因为如此,当ClickHouse服务重启的时候,Memory表内的数据会全部丢失。所以在一些场合,会将Memory作为测试表使用,很多初学者在学习ClickHouse的时候所写的Hello World程序很可能用的就是Memory表。由于不需要磁盘读取、序列化以及反序列等操作,所以Memory表引擎支持并行查询,并且在简单的查询场景中能够达到与MergeTree旗鼓相当的查询性能(一亿行数据量以内)。Memory表的创建方法如下所示:
CREATE TABLE memory_1 (
id UInt64
)ENGINE = Memory() ;
Memory表更为广 泛的应用场景是在ClickHouse的内部,它会作为集群间分发数据的存储载体来使用。例如在分布式IN查询的场合中,会利用Memory临时表保存IN子句的查询结果,并通过网络将它传输到远端节点。
4.2 Set
Set表引擎是拥有物理存储的,数据首先会被写至内存,然后被同步到磁盘文件中。所以当服务重启时,它的数据不会丢失,当数据表被重新装载时,文件数据会再次被全量加载至内存。众所周知,在Set
数据结构中,所有元素都是唯一的。Set表引擎具有去重的能力,在数据写入的过程中,重复的数据会被自动忽略。然而Set表引擎的使用场景既特殊又有限,它虽然支持正常的INSERT写入,但并不能直接使用SELECT对其进行查询,Set表引擎只能间接作为IN查询的右侧条件被查询使用
Set表引擎的存储结构由两部分组成,它们分别是:
[num].bin数据文件:保存了所有列字段的数据。其中,num是 一个自增id,从1开始。伴随着每一批数据的写入(每一次INSERT),都会生成一个新的.bin文件,num也会随之加1。
tmp临时目录:数据文件首先会被写到这个目录,当一批数据写入完毕之后,数据文件会被移出此目录。
create table test_set(
id Int8 ,
name String
)engine=Set();
发现在数据库的目录下是还有对应的目录的,可见数据会被存储到磁盘上的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ri7j78y4-1641804074979)(clickhouse.assets/wps1.jpg)]
这种表不允许我们直接查询,Set表引擎作为IN查询的右侧条件。
三 分布式
- 依赖ZooKeeper:在执行INSERT和ALTER查询的时候,ReplicatedMergeTree需要借助ZooKeeper的分布式协同能力,以实现多个副本之间的同步。但是在查询副本的时候,并不需要使用 ZooKeeper。
- 多主架构(Multi Master):可以在任意一个副本上执行INSERT和ALTER查询,它们的效果是相同的。这些操作会借助ZooKeeper的协同能力被分发至每个副本以本地形式执行。
- Block数据块:在执行INSERT命令写入数据时,会依据 max_insert_block_size的大小(默认1048576行)将数据切分成若干个Block数据块。所以Block数据块是数据写入的基本单元,并且具有 写入的原子性和唯一性。
- 原子性:在数据写入时,一个Block块内的数据要么全部写入成功,要么全部失败。
- 唯一性:在写入一个Block数据块的时候,会按照当前Block数据块的数据顺序、数据行和数据大小等指标,计算Hash信息摘要并记录在案。这项设计可以预防由异常原因引起的Block数据块重复写入的问题。
3.1 分布式协同原理
副本协同的核心流程主要有INSERT、MERGE、MUTATION和ALTER四种,分别对应了数据写入、分区合并、数据修改和元数据修改。INSERT和ALTER查询是分布式执行的。借助 ZooKeeper的事件通知机制,多个副本之间会自动进行有效协同,但是它们不会使用ZooKeeper存储任何分区数据。而其他查询并不支持分布式执行,包括SELECT、CREATE、DROP、RENAME和ATTACH。例如,为了创建多个副本,我们需要分别登录每个ClickHouse节点。接下来,会依次介绍上述流程的工作机理。为了便于理解,我先来整体认识一下各个流程的介绍方法。
3.1.1 insert原理
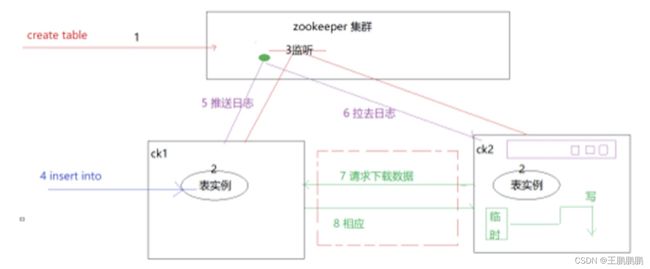
- Insert into ck1,推送到zookeper
- 从zookeper找到repliation节点下的所有主机,发送到ck2的队列
- ck2主动拉取ck1的数据到temp目录
- ck2从temp目录写入
3.1.2 mutation原理
alter table x update name=zss where
alter table x delete where
当对ReplicatedMergeTree执行ALTER DELETE或者ALTER UPDATE操作的时候,即会进入MUTATION部分的逻辑,它的核心流程如图
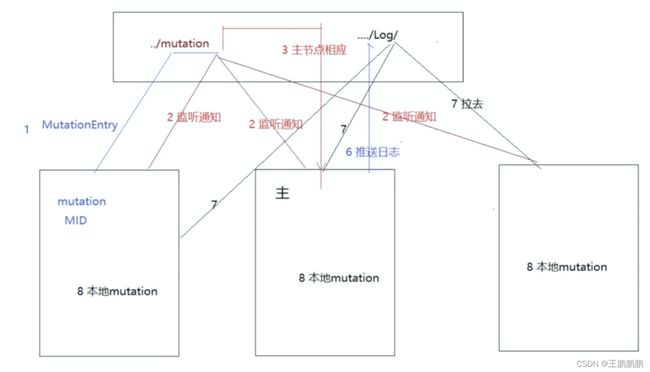
- 执行mutation操作
- 写入./mutation文件
- 通知所有节点,选举主节点
- 主节点拉取执行命令
- 主节点同步数据到副节点
四 数据类型与基础语法
基本语法演示
-- show databases ;
-- create database if not exists test1 ;
-- use test1 ;
-- select currentDatabase() ;
-- drop database test1 ;
4.0 视图
1) 普通视图
ClickHouse拥有普通和物化两种视图,其中物化视图拥有独立的存储,而普通视图只是一层简单的查询代理
普通视图不会存储任何数据,它只是一层单纯的SELECT查询映射,起着简化查询、明晰语义的作用,对查询性能不会有任何增强。
2) 物化视图
物化视图支持表引擎,数据保存形式由它的表引擎决定,创建物化视图的完整语法如下所示
create materialized view mv_log engine=Log populate as select * from log ;
物化视图创建好之后,如果源表被写入新数据,那么物化视图也会同步更新。POPULATE修饰符决定了物化视图的初始化策略:如果使用了POPULATE修饰符,那么在创建视图的过程中,会连带将源表中已存在的数据一并导入,如同执行了INTO SELECT 一般;反之,如果不使用POPULATE修饰符,那么物化视图在创建之后是没有数据的,它只会同步在此之后被写入源表的数据。物化视图目前并不支持同步删除,如果在源表中删除了数据,物化视图的数据仍会保留。
<font color='red'><b>使用物化视图同步聚合数据</b></font>
```sql
-- 建立明细表
CREATE TABLE orders
(
uid UInt64,
money UInt64,
ctime Date,
Sign Int8
)
ENGINE = CollapsingMergeTree(Sign)
ORDER BY uid;
--插入数据
insert into orders values(1,100,toDate(now()),1) ;
insert into orders values(1,100,toDate(now()),1) ;
insert into orders values(2,200,toDate(now()),1) ;
insert into orders values(2,200,toDate(now()),1) ;
-- 将聚合逻辑创-- 将聚合逻辑创建成物化视图
CREATE MATERIALIZED VIEW orders_agg_view
ENGINE = AggregatingMergeTree()
PARTITION BY toDate(ctime)
ORDER BY uid
populate
as select
uid ,
ctime ,
sumState(money) as mm -- 注意别名
from
orders
group by uid , ctime;
-- 查询物化视图数据
select uid,ctime,sumMerge(mm) from orders_agg_view group by uid, ctime ;
-- 更新明细数据, 物化视图中的数据实时计算更新
┌─uid─┬──────ctime─┬─sumMerge(mm)─┐
│ 2 │ 2021-05-19 │ 400 │
│ 1 │ 2021-05-19 │ 200 │
└─────┴────────────┴──────────────┘
insert into orders values(1,100,toDate(now()),1);
┌─uid─┬──────ctime─┬─sumMerge(mm)─┐
│ 2 │ 2021-05-19 │ 400 │
│ 1 │ 2021-05-19 │ 300 │
└─────┴────────────┴──────────────┘
其实物化视图就是一种特殊的表
4.1 数据类型
4.1.1 数值类型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eMFxpexP-1641804074983)(assets/16261664889370.jpg)]
注意在CK中关键字严格区分大小写
1) IntX和UIntX
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NYzxMVgn-1641804074984)(assets/16261666855827.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-70qaKo0f-1641804074985)(assets/16261666943942.jpg)]
2) FloatX
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-30uGoQoJ-1641804074986)(assets/16261667323447.jpg)]
注意: 和我以前的认知是一样的,这种数据类型在数据特别精准的情况下可能出现数据精度问题!
Select 8.0/0 -->inf 正无穷
Select -8.0/0 -->inf 负无穷
Select 0/0 -->nan 非数字
3) Decimal
如果要求更高精度的数值运算,则需要使用定点数。ClickHouse提 供了Decimal32、Decimal64和Decimal128三种精度的定点数。可以通过 两种形式声明定点:简写方式有Decimal32(S)、Decimal64(S)、
Decimal128(S)三种,原生方式为Decimal(P,S),其中:
·P代表精度,决定总位数(整数部分+小数部分),取值范围是1 ~38;·S代表规模,决定小数位数,取值范围是0~P
create table test_decimal(
id Int8 ,
sal Decimal(5,2)
)engine=Memory ;
4.1.2 字符串类型
符串类型可以细分为String、FixedString和UUID三类。从命名来看仿佛不像是由一款数据库提供的类型,反而更像是一门编程语言的设计,没错CK语法具备编程语言的特征(数据+运算)
1) String
字符串由String定义,长度不限。因此在使用String的时候无须声明大小。它完全代替了传统意义上数据库的Varchar、Text、Clob和Blob等字符类型。String类型不限定字符集,因为它根本就没有这个概念,所以可以将任意编码的字符串存入其中。但是为了程序的规范性和可维护性,在同一套程序中应该遵循使用统一的编码,例如“统一保持UTF-8编码”就是一种很好的约定。所以在对数据操作的时候我们不在需要区关注编码和乱码问题!
2) FixedString
FixedString类型和传统意义上的Char类型有些类似,对于一些字符有明确长度的场合,可以使用固定长度的字符串。定长字符串通过
3) UUID
UUID是一种数据库常见的主键类型,在ClickHouse中直接把它作为一种数据类型。UUID共有32位,它的格式为8-4-4-4-12。如果一个UUID类型的字段在写入数据时没有被赋值,则会依照格式使用0填充
CREATE TABLE test_uuid
(
`uid` UUID,
`name` String
)
ENGINE = Memory ;
insert into test_uuid select generateUUIDv4() , 'zss' ;
┌──────────────────────────────────uid─┬─name─┐
│ 47e39e22-d2d6-46fd-8014-7cd3321f4c7b │ zss │
└──────────────────────────────────────┴──────┘
-------------------------UUID类型的字段默认补位0-----------------------------
insert into test_uuid (name) values('hangge') ;
┌──────────────────────────────────uid─┬─name───┐
│ 00000000-0000-0000-0000-000000000000 │ hangge │
└──────────────────────────────────────┴────────┘
4.1.3 时间类型
1) Date
Date类型不包含具体的时间信息,只精确到天,支持字符串形式写入:
CREATE TABLE test_date
(
`id` int,
`ct` Date
)
ENGINE = Memory ;
insert into test_date vlaues(1,'2021-09-11'),(2,now()) ;
┌─id─┬─────────ct─┐
│ 1 │ 2021-09-11 │
│ 2 │ 2021-05-17 │
└────┴────────────┘
2) DateTime
DateTime类型包含时、分、秒信息,精确到秒,支持字符串形式写入:
3)DateTime64
DateTime64可以记录亚秒,它在DateTime之上增加了精度的设置
4.1.4 复杂类型
1) Enum
ClickHouse支持枚举类型,这是一种在定义常量时经常会使用的数据类型。ClickHouse提供了Enum8和Enum16两种枚举类型,它们除了取值范围不同之外,别无二致。枚举固定使用(String:Int)Key/Value键值对的形式定义数据,所以Enum8和Enum16分别会对应(String:Int8)和(String:Int16)!
create table test_enum(id Int8 , color Enum('red'=1 , 'green'=2 , 'blue'=3)) engine=Memory ;
insert into test_enum values(1,'red'),(1,'red'),(2,'green');
也可以使用这种方式进行插入数据:
insert into test_enum values(3,3) ;
在定义枚举集合的时候,有几点需要注意。首先,Key和Value是不允许重复的,要保证唯一性。其次,Key和Value的值都不能为Null,但Key允许是空字符串。在写入枚举数据的时候,只会用到Key字符串部分,
注意: 其实我们可以使用字符串来替代Enum类型来存储数据,那么为什么是要使用枚举类型呢?这是出于性能的考虑。因为虽然枚举定义中的Key属于String类型,但是在后续对枚举的所有操作中(包括排序、分组、去重、过滤等),会使用Int类型的Value值 ,提高处理数据的效率!
- 限制枚举类型字段的值
- 底层存储的是对应的Int类型的数据
- 可以使用String
2) Array(T)
CK支持数组这种复合数据类型 , 并且数据在操作在今后的数据分析中起到非常便利的效果!数组的定义方式有两种 : array(T) [e1,e2…] , 我们在这里要求数组中的数据类型是一致的!
create table test_array(
id Int8 ,
hobby Array(String)
)engine=Memory ;
insert into test_array values(1,['eat','drink','la']),(2,array('sleep','palyg','sql'));
┌─id─┬─hobby───────────────────┐
│ 1 │ ['eat','drink','la'] │
│ 2 │ ['sleep','palyg','sql'] │
└────┴─────────────────────────┘
3) Tuple
元组类型由1~n个元素组成,每个元素之间允许设置不同的数据类型,且彼此之间不要求兼容。元组同样支持类型推断,其推断依据仍然以最小存储代价为原则。与数组类似,元组也可以使用两种方式定义,常规方式tuple(T):元组中可以存储多种数据类型,但是要注意数据类型的顺序
注意:建表的时候使用元组的需要制定元组的数据类型
CREATE TABLE test_tuple (
c1 Tuple(UInt8, String, Float64)
) ENGINE = Memory;
SELECT
(1, 'asb', 12.23) AS x,
toTypeName(x)
┌─x───────────────┬─toTypeName(tuple(1, 'asb', 12.23))─┐
│ (1,'asb',12.23) │ Tuple(UInt8, String, Float64) │
└─────────────────┴────────────────────────────────────┘
4) Nested
Nested是一种嵌套表结构。一张数据表,可以定义任意多个嵌套类型字段,但每个字段的嵌套层级只支持一级,即嵌套表内不能继续使用嵌套类型。对于简单场景的层级关系或关联关系,使用嵌套类型也是一种不错的选择。
create table test_nested(
uid Int8 ,
name String ,
props Nested(
pid Int8,
pnames String ,
pvalues String
)
)engine = Memory ;
desc test_nested ;
┌─name──────────┬─type──────────┬
│ uid │ Int8 │
│ name │ String │
│ props.pid │ Array(Int8) │
│ props.pnames │ Array(String) │
│ props.pvalues │ Array(String) │
└───────────────┴───────────────┴
嵌套类型本质是一种多维数组的结构。嵌套表中的每个字段都是一个数组,在同一行数据内每个数组字段的长度必须相等。
insert into test_nested values(1,'hadoop',[1,2,3],['p1','p2','p3'],['v1','v2','v3']);
-- 行和行之间的属性的个数可以不一致 ,但是当前行的Nested类型中的数组个数必须一致
insert into test_nested values(2,'spark',[1,2],['p1','p2'],['v1','v2']);
SELECT *
FROM test_nested
┌─uid─┬─name───┬─props.pid─┬─props.pnames─────┬─props.pvalues────┐
│ 1 │ hadoop │ [1,2,3] │ ['p1','p2','p3'] │ ['v1','v2','v3'] │
└─────┴────────┴───────────┴──────────────────┴──────────────────┘
6) GEO
- Point(点)
SET allow_experimental_geo_types = 1;
CREATE TABLE geo_point (p Point) ENGINE = Memory();
INSERT INTO geo_point VALUES((10, 10));
SELECT p, toTypeName(p) FROM geo_point;
┌─p───────┬─toTypeName(p)─┐
│ (10,10) │ Point │
└─────────┴───────────────┘
- Ring(圆)
SET allow_experimental_geo_types = 1;
CREATE TABLE geo_ring (r Ring) ENGINE = Memory();
INSERT INTO geo_ring VALUES([(0, 0), (10, 0), (10, 10), (0, 10)]);
SELECT r, toTypeName(r) FROM geo_ring;
┌─r─────────────────────────────┬─toTypeName(r)─┐
│ [(0,0),(10,0),(10,10),(0,10)] │ Ring │
└───────────────────────────────┴───────────────┘
- Polygon(多边形)
SET allow_experimental_geo_types = 1;
CREATE TABLE geo_polygon (pg Polygon) ENGINE = Memory();
INSERT INTO geo_polygon VALUES([[(20, 20), (50, 20), (50, 50), (20, 50)], [(30, 30), (50, 50), (50, 30)]]);
SELECT pg, toTypeName(pg) FROM geo_polygon;
- MultiPolygon
SET allow_experimental_geo_types = 1;
CREATE TABLE geo_multipolygon (mpg MultiPolygon) ENGINE = Memory();
INSERT INTO geo_multipolygon VALUES([[[(0, 0), (10, 0), (10, 10), (0, 10)]], [[(20, 20), (50, 20), (50, 50), (20, 50)],[(30, 30), (50, 50), (50, 30)]]]);
SELECT mpg, toTypeName(mpg) FROM geo_multipolygon;
7)IPV4
域名类型分为IPv4和IPv6两类,本质上它们是对整型和字符串的进一步封装。IPv4类型是基于UInt32封装的
(1)出于便捷性的考量,例如IPv4类型支持格式检查,格式错误的IP数据是无法被写入的,例如:
INSERT INTO IP4_TEST VALUES (‘www.51doit.com’,‘192.0.0’)
Code: 441. DB::Exception: Invalid IPv4 value.
(2)出于性能的考量,同样以IPv4为例,IPv4使用UInt32存储,相比String更加紧凑,占用的空间更小,查询性能更快。IPv6类型是基于FixedString(16)封装的,它的使用方法与IPv4别无二致, 在使用Domain类型的时候还有一点需要注意,虽然它从表象上看起来与String一样,但Domain类型并不是字符串,所以它不支持隐式的自动类型转换。如果需要返回IP的字符串形式,则需要显式调用 IPv4NumToString或IPv6NumToString函数进行转换。
8) Boolean
ck中没有Boolean类型 ,使用1和0来代表true和false
4.2 基本语法
4.2.1 DDL基础
- 建表
目前只有MergeTree、Merge和Distributed这三类表引擎支持 ALTER查询,所以在进行alter操作的时候注意表的引擎!
注意在建表的时候一般要求指定表的引擎
CREATE TABLE tb_test1
(
`id` Int8,
`name` String
)
ENGINE = Memory() ;
-- 只有 MergeTree支持表结构的修改
-- MergeTree一定指定主键和排序字段 order by 代表两个含义
CREATE TABLE test_alter1
(
`id` Int8,
`name` String
)
ENGINE = MergeTree()
order by id ;
-- 查看建表语句 查看引擎类型参数值
show create table test_alter1 ;
-----------------------------------
CREATE TABLE doit23.test_alter1
(
`id` Int8,
`name` String
)
ENGINE = MergeTree()
ORDER BY id
SETTINGS index_granularity = 8192;
- 修改表结构
-- 查看表结构
desc tb_test1 ;
┌─name─┬─type───┬
│ id │ Int8 │
│ name │ String │
└──────┴────────┴
-- 添加字段
alter table tb_test1 add column age UInt8 ;-- 报错 , 因为修改的表引擎是内存引擎,不支持表结构的修改
-- 创建一张MergeTree引擎的表
CREATE TABLE tb_test2
(
`id` Int8,
`name` String
)
ENGINE = MergeTree()
ORDER BY id ;
┌─name─┬─type───┬
│ id │ Int8 │
│ name │ String │
└──────┴────────┴
-- 添加字段
alter table tb_test2 add column age UInt8 ;
┌─name─┬─type───┬
│ id │ Int8 │
│ name │ String │
│ age │ UInt8 │
└──────┴────────┴
alter table tb_test2 add column gender String after name ;
┌─name───┬─type───┬
│ id │ Int8 │
│ name │ String │
│ gender │ String │
│ age │ UInt8 │
└────────┴────────┴
-- 删除字段
alter table tb_test2 drop column age ;
-- 修改字段的数据类型
alter table tb_test2 modify column gender UInt8 default 0 ;
┌─name───┬─type───┬─default_type─┬─default_expression─┬
│ id │ Int8 │ │ │
│ name │ String │ │ │
│ gender │ UInt8 │ DEFAULT │ 0 │
└────────┴────────┴──────────────┴────────────────────┴
-- 作为一个优秀的程序员,表的字段使用注释一种良好的习惯, 所以建议大家在操作的时候使用注释来描述字段的意义
-- 修改 / 添加字段的注释 内部使用的编码默认是UTF8
alter table tb_test2 comment column name '用户名' ;
┌─name───┬─type───┬─default_type─┬─default_expression─┬─comment─┬
│ id │ Int8 │ │ │ │
│ name │ String │ │ │ 用户名 │
│ gender │ UInt8 │ DEFAULT │ 0 │ │
└────────┴────────┴──────────────┴────────────────────┴─────────┴
- 移动表
在Linux系统中,mv命令的本意是将一个文件从原始位置A移动到目标位置B,但是如果位 置A与位置B相同,则可以变相实现重命名的作用。ClickHouse的RENAME查询就与之有着异曲同工之妙,RENAME语句的完整语法如下所示:
-- 修改表名
rename table tb_test1 to t1 ;
-- 修改多张表名
rename table tb_test2 to t2 , t1 to tt1 ;
-- 移动表到另一数据库中
rename table t2 to test1.t ;
-- 查看数据库下的所有的表
show tables ;
show tables from db_name ;
- 设置表属性
-- 设置列的默认值
create table tb_test3(
id Int8 ,
name String comment '用户名' ,
role String comment '角色' default 'VIP'
)engine = Log ;
┌─name─┬─type───┬─default_type─┬─default_expression─┬
│ id │ Int8 │ │ │
│ name │ String │ │ │
│ role │ String │ DEFAULT │ 'VIP' │
└──────┴────────┴──────────────┴────────────────────┴
insert into tb_test3 (id , name) values(1,'HANGGE') ;
SELECT *
FROM tb_test3 ;
┌─id─┬─name───┬─role─┐
│ 1 │ HANGGE │ VIP │
└────┴────────┴──────┘
4.2.2 DML基础
1) 插入数据
INSERT语句支持三种语法范式,三种范式各有不同,可以根据写入的需求灵活运用。
第一种方式
使用VALUES格式的常规语法
INSERT INTO [db.]table [(c1, c2, c3…)] VALUES (v11, v12, v13…), (v21, v22, v23…), …
其中,c1、c2、c3是列字段声明,可省略。VALUES后紧跟的是由元组组成的待写入数据,通过下标位 与列字段声明一一对应。数据支持批量声明写入,多行数据之间使用逗号分隔
第二种方式
静态数据: cat user.txt
1,zss,23,BJ,M
2,lss,33,NJ,M
3,ww,21,SH,F
create table test_load1(
id UInt8 ,
name String ,
age UInt8 ,
city String ,
gender String
)engine=Log ;
-- 将数据导入到表中
cat user.txt | clickhouse-client -q 'insert into default.test_load1 format CSV'
clickhouse-client -q 'insert into default.test_load1 format CSV' < user.txt
上面的两种方式都可以将数据导入到表中
-- 我们还可以执行数据行属性的分割符
clickhouse-client --format_csv_delimiter=',' -q 'insert into default.test_load1 format CSV' < user.txt
第三种方式
INSERT INTO [db.]table [(c1, c2, c3…)] SELECT …
虽然VALUES和SELECT子句的形式都支持声明表达式或函数,但是表达式和函数会带来额外的性能开销,从而导致写入性能的下降。所以如果追求极致的写入性能,就应该尽可能避免使用它们。
create table log3 as log2 ;
Insert into log3 select * from log2 ;
ClickHouse内部所有的数据操作都是面向Block数据块的,所以INSERT查询最终会将数据转换为Block数据块。也正因如此,INSERT语句在单个数据块的写入过程中是具有原子性的。在默认的情况下,每个数据块最多可以写入1048576行数据(由max_insert_block_size参数控制)。也就是说,如果一条INSERT语句写入的数据少于max_insert_block_size行,那么这批数据的写入是具有原子性的,即要么全部成功,要么全部失败。需要注意的是,只有在ClickHouse服务端处理数据的时候才具有这种原子写入的特性,例如使用JDBC或者HTTP接口时。因为max_insert_block_size参数在使用CLI命令行或 者INSERT SELECT子句写入时是不生效的。
2) 更新删除数据
ClickHouse提供了DELETE和UPDATE的能力,这类操作被称为Mutation查询,它可以看作ALTER语句的变种。虽然Mutation能最终实现修改和删除,但不能完全以通常意义上的UPDATE和DELETE来理解,我们必须清醒地认识到它的不同:首先,Mutation语句是一种“很重”的操作,更适用于批量数据的修改和删除;其次,它不支持事务,一旦语句被提交执行,就会立刻对现有数据产生影响,无法回滚;最后, Mutation语句的执行是一个异步的后台过程,语句被提交之后就会立即返回。所以这并不代表具体逻辑已经执行完毕,它的具体执行进度需要通过system.mutations系统表查询。注意数据的修改和删除操作是使用用MergeTree家族引擎:
只有MergeTree引擎的数据才能修改
4.2.3 分区表操作
目前只有MergeTree系列 的表引擎支持数据分区
区内排序 , 合并 ,去重
create table test_partition1(
id String ,
ctime DateTime
)engine=MergeTree()
partition by toYYYYMM(ctime)
order by (id) ;
-- 查看建表语句
│ CREATE TABLE default.test_partition1
(
`id` String,
`ctime` DateTime
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(ctime)
ORDER BY id
SETTINGS index_granularity = 8192 │
-- 插入数据
insert into test_partition1 values(1,now()) ,(2,'2021-06-11 11:12:13') ;
-- 查看数据
SELECT *
FROM test_partition1 ;
┌─id─┬───────────────ctime─┐
│ 2 │ 2021-06-11 11:12:13 │
└────┴─────────────────────┘
┌─id─┬───────────────ctime─┐
│ 1 │ 2021-05-19 13:38:29 │
└────┴─────────────────────┘
-- 查看表中的分区
ClickHouse内置了许多system系统表,用于查询自身的状态信息。 其中parts系统表专门用于查询数据表的分区信息。
SELECT
name,
table,
partition
FROM system.parts
WHERE table = 'test_partition1' ;
┌─name─────────┬─table───────────┬─partition─┐
│ 202105_1_1_0 │ test_partition1 │ 202105 │
│ 202106_2_2_0 │ test_partition1 │ 202106 │
└──────────────┴─────────────────┴───────────┘
insert into test_partition1 values(1,now()) ,(2,'2021-06-12 11:12:13') ;
┌─name─────────┬─table───────────┬─partition─┐
│ 202105_1_1_0 │ test_partition1 │ 202105 │
│ 202105_3_3_0 │ test_partition1 │ 202105 │
│ 202106_2_2_0 │ test_partition1 │ 202106 │
│ 202106_4_4_0 │ test_partition1 │ 202106 │
└──────────────┴─────────────────┴───────────┘
-- 删除分区
alter table test_partition1 drop partition '202105' ;
删除分区以后 , 分区中的所有的数据全部删除
SELECT
name,
table,
partition
FROM system.parts
WHERE table = 'test_partition1'
┌─name─────────┬─table───────────┬─partition─┐
│ 202106_2_2_0 │ test_partition1 │ 202106 │
│ 202106_4_4_0 │ test_partition1 │ 202106 │
└──────────────┴─────────────────┴───────────┘
SELECT *
FROM test_partition1
┌─id─┬───────────────ctime─┐
│ 2 │ 2021-06-12 11:12:13 │
└────┴─────────────────────┘
┌─id─┬───────────────ctime─┐
│ 2 │ 2021-06-11 11:12:13 │
└────┴─────────────────────┘
-- 复制分区
clickHouse支持将A表的分区数据复制到B表,这项特性可以用于快速数据写入、多表间数据同步和备份等场景,它的完整语法如下:
ALTER TABLE B REPLACE PARTITION partition_expr FROM A
不过需要注意的是,并不是任意数据表之间都能够相互复制,它们还需要满足两个前提 条件:
·两张表需要拥有相同的分区键
·它们的表结构完全相同。
create table test_partition2 as test_partition1 ;
show create table test_partition2 ; -- 查看表2的建表语句
│ CREATE TABLE default.test_partition2
(
`id` String,
`ctime` DateTime
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(ctime)
ORDER BY id
SETTINGS index_granularity = 8192 │ -- 两张表的结构完全一致
-- 复制一张表的分区到另一张表中
SELECT *
FROM test_partition2
┌─id─┬───────────────ctime─┐
│ 2 │ 2021-06-12 11:12:13 │
└────┴─────────────────────┘
┌─id─┬───────────────ctime─┐
│ 2 │ 2021-06-11 11:12:13 │
└────┴─────────────────────┘
┌─id─┬───────────────ctime─┐
│ 2 │ 2021-06-21 11:12:13 │
└────┴─────────────────────┘
----------------------------
alter table test_partition2 replace partition '202106' from test_partition1
SELECT
name,
table,
partition
FROM system.parts
WHERE table = 'test_partition2'
┌─name─────────┬─table───────────┬─partition─┐
│ 202106_2_2_0 │ test_partition2 │ 202106 │
│ 202106_3_3_0 │ test_partition2 │ 202106 │
│ 202106_4_4_0 │ test_partition2 │ 202106 │
└──────────────┴─────────────────┴───────────┘
-- 重置分区数据
如果数据表某一列的数据有误,需要将其重置为初始值,如果设置了默认值那么就是默认值数据,如果没有设置默认值,系统会给出默认的初始值,此时可以使用下面的语句实现:
ALTER TABLE tb_name CLEAR COLUMN column_name IN PARTITION partition_expr ;
注意: 不能重置主键和分区字段
示例:
alter table test_rep clear column name in partition '202105' ;
-- 卸载分区
表分区可以通过DETACH语句卸载,分区被卸载后,它的物理数据并没有删除,而是被转移到了当前数据表目录的detached子目录下。而装载分区则是反向操作,它能够将detached子目录下的某个分区重新装载回去。卸载与装载这一对伴生的操作,常用于分区数据的迁移和备份场景
五 查询语法
5.1 with
ClickHouse支持CTE(Common Table Expression,公共表表达式),以增强查询语句的表达
SELECT pow(2, 2)
┌─pow(2, 2)─┐
│ 4 │
└───────────┘
SELECT pow(pow(2, 2), 2)
┌─pow(pow(2, 2), 2)─┐
│ 16 │
└───────────────────┘
在改用CTE的形式后,可以极大地提高语句的可读性和可维护性,\
with pow(2,2) as a select pow(a,3) ;
1) 定义变量
WITH
1 AS start,
10 AS end
SELECT
id + start,
*
FROM tb_mysql
┌─plus(id, start)─┬─id─┬─name─┬─age─┐
│ 2 │ 1 │ zss │ 23 │
│ 3 │ 2 │ lss │ 33 │
│ 4 │ 3 │ ww │ 44 │
│ 2 │ 1 │ zss │ 23 │
│ 3 │ 2 │ lss │ 33 │
│ 2 │ 1 │ zss │ 23 │
│ 3 │ 2 │ lss │ 33 │
└─────────────────┴────┴──────┴─────┘
2) 调用函数
WITH toDate(birthday) AS bday
SELECT
id,
name,
bday
FROM tb_partition
┌─id─┬─name─┬───────bday─┐
│ 1 │ xl │ 2021-05-20 │
│ 2 │ xy │ 2021-05-20 │
└────┴──────┴────────────┘
┌─id─┬─name─┬───────bday─┐
│ 3 │ xf │ 2021-05-19 │
└────┴──────┴────────────┘
3) 子查询
可以定义子查询 ,但是一定还要注意的是,子查询只能返回一行结果 ,否则会跑出异常
WITH
(
SELECT *
FROM tb_partition
WHERE id = 1
) AS sub
SELECT
*,
sub
FROM tb_partition
5.2 from
SQL是一种面向集合的编程语言 ,from决定了程序从那里读取数据
5.3 array join
ARRAY JOIN子句允许在数据表的内部,与数组或嵌套类型的字段进行JOIN操作,从而将一行数组展开为多行。类似于hive中的explode炸裂函数的功能!
CREATE TABLE test_arrayjoin
(
`name` String,
`vs` Array(Int8)
)
ENGINE = Memory ;
insert into test_arrayjoin values('xw',[1,2,3]),('xl',[4,5]),('xk',[1]);
-- 将数组中的数据展开
SELECT
*,
s
FROM test_arrayjoin
ARRAY JOIN vs AS s
┌─name─┬─vs──────┬─s─┐
│ xw │ [1,2,3] │ 1 │
│ xw │ [1,2,3] │ 2 │
│ xw │ [1,2,3] │ 3 │
│ xl │ [4,5] │ 4 │
│ xl │ [4,5] │ 5 │
│ xk │ [1] │ 1 │
└──────┴─────────┴───┘
-- arrayMap 高阶函数,对数组中的每个元素进行操作
SELECT
*,
arrayMap(x->x*2 , vs) vs2
FROM test_arrayjoin ;
SELECT
*,
arrayMap(x -> (x * 2), vs) AS vs2
FROM test_arrayjoin
┌─name─┬─vs──────┬─vs2─────┐
│ xw │ [1,2,3] │ [2,4,6] │
│ xl │ [4,5] │ [8,10] │
│ xk │ [1] │ [2] │
└──────┴─────────┴─────────┘
六 函数
ClickHouse主要提供两类函数—普通函数和聚合函数。普通函数由IFunction接口定义,拥有数十种函数实现,例如FunctionFormatDateTime、FunctionSubstring等。除了一些常见的函数 ( 诸如四则运算、日期转换等 ) 之外,也不乏一些非常实用的函数,例如网址提取函数、IP地址脱敏函数等。普通函数是没有状态的,函数效果作用于每行数据之上。当然,在函数具体执行的过程中,并不会一行一行地运算,而是采用向量化的方式直接作用于一整列数据。聚合函数由IAggregateFunction接口定义,相比无状态的普通函数,聚合函数是有状态的。以COUNT聚合函数为例,其AggregateFunctionCount的状态使用整UInt64记录。聚合函数的状态支持序列化与反序列化,所以能够在分布式节点之间进行传输,以实现增量计算。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yqel5qjw-1641804074987)(assets/16262452558282.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-48jpahqc-1641804074988)(assets/16262453580866.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4bFa4qlb-1641804074988)(assets/16262453782372.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vpm843sI-1641804074989)(assets/16262453958280.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WKfebh4U-1641804074996)(assets/16262454201145.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AoeAeWzX-1641804074998)(assets/16262457596624.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pyiIVSTq-1641804074999)(assets/16262457792883.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gaKhi6gt-1641804075000)(assets/16262456666225.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9WC3xrcl-1641804075000)(assets/16262456413865.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lFGy4mhQ-1641804075001)(assets/16262456020498.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZUcGJqSl-1641804075002)(assets/16262455567334.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YSH0ljPC-1641804075003)(assets/16262455219483.jpg)]
七 应用案例
7.1 用户行为分析
7.1.1 windowFunnel函数
返回满足在指定滑动窗口内的连续触发条件的最大值
event1,event2比如浏览,加购物车动作。
建如下一张表
uid1 event1 1551398404
uid1 event2 1551398406
uid1 event3 1551398408
uid2 event2 1551398412
uid2 event3 1551398415
uid3 event3 1551398410
uid3 event4 1551398413
select uid,windowFunnel(4)(toDateTime(eventTime),eventid = 'event2',eventid = 'event3') as funnel from funnel_test group by uid;
当我们设置的滑动窗口为4秒,条件链为event2->event3时,上述查询得到的结果为:
uid funnel
uid1 2
uid2 2
uid3 0
下面我们看看他是怎么得到这个结果的,首先将所有的数据根据uid聚合和排序(排序是windowFunnel里自己实现的),得到:
uid1: (event1,1551398404) -> (event2,1551398406) -> (event3,1551398408)
uid2: (event2,1551398412) -> (event3,1551398415)
uid3: (event3 ,1551398410) -> (event4,1551398413)
由上述聚合和排序之后的条件链中,只有uid1和uid2有event2->event3的条件链,且时间差分别为2(1551398408-1551398406) 和 3(1551398415-1551398412),小于滑动窗口4,所以满足条件,故uid1和uid2的结果都为2(event2,event3),而uid3为0(没有满足条件的条件链)
如果滑动窗口改为2
uid funnel
uid1 2
uid2 1
uid3 0
因为uid2的条件链中的event3和event2的时间差是3,大于了滑动窗口时间2,所以只有第一个条件event2满足查询,故结果为1