分布式 - 消息队列Kafka:Kafka消费者的分区分配策略
文章目录
-
-
- 1. 环境准备
- 2. range 范围分区策略介绍
- 3. round-robin 轮询分区策略
- 4. sticky 粘性分区策略
- 5. 自定义分区分配策略
-
1. 环境准备
创建主题 test 有5个分区,准备 3 个消费者并进行消费,观察消费分配情况。然后再停止其中一个消费者,再次观察消费分配情况。
① 创建主题 test,该主题有5个分区,2个副本:
[root@master01 kafka01]# bin/kafka-topics.sh --zookeeper localhost:2183 --create --partitions 5 --replication-factor 2 --topic test
Created topic test.
[root@master01 kafka01]# bin/kafka-topics.sh --zookeeper localhost:2183 --describe --topic test
Topic:test PartitionCount:5 ReplicationFactor:2 Configs:
Topic: test Partition: 0 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: test Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: test Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: test Partition: 3 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: test Partition: 4 Leader: 0 Replicas: 0,2 Isr: 0,2
② 创建3个消费者CustomConsumer01, CustomConsumer02, CustomConsumer03,消费者组名相同,这样3个消费者属于同一个组:
public class CustomConsumer01 {
private static final String brokerList = "10.65.132.2:9093";
private static final String topic = "test";
public static Properties initConfig(){
Properties properties = new Properties();
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,brokerList);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test-consumer-group");
return properties;
}
public static void main(String[] args) {
Properties properties = initConfig();
// 创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
// 订阅主题 test
ArrayList<String> topics = new ArrayList<>();
topics.add(topic);
consumer.subscribe(topics);
// 消费数据
while (true){
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println("分区"+consumerRecord.partition()+"消费数据:"+consumerRecord.value());
}
}
}
}
③ 创建生产者用来向主题 test 发送消息,随机发送到不同的分区:
public class CustomProducer01 {
private static final String brokerList = "10.65.132.2:9093";
private static final String topic = "test";
public static Properties initConfig(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,brokerList);
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
return properties;
}
public static void main(String[] args) throws InterruptedException {
// kafka生产者属性配置
Properties properties = initConfig();
// kafka生产者发送消息
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for(int i=0;i<50;i++){
kafkaProducer.send(new ProducerRecord<>(topic ,"hello,kafka"), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception exception) {
if(exception==null){
System.out.println("recordMetadata 发往的分区:"+recordMetadata.partition());
}else{
exception.printStackTrace();
}
}
});
Thread.sleep(2);
}
kafkaProducer.close();
}
}
在分区再均衡时消费者组下所有的消费者都会协调在一起共同参与分区分配,这是如何完成的呢?Kafka 新版本 消费者默认提供了3种分配策略,分别是 range 策略、round-robin策略和sticky策略。所谓的分配策略决定了订阅主题的每个分区会被分配给哪个消费者。
① range 策略主要是基于范围的思想。它将单个主题的所有分区按照顺序排列,然后把这些分区划分成固定大小的分区段并依次分配给每个消费者;
② round-robin 策略则会把所有主题的所有分区顺序摆开,然后轮询式地分配给各个消费者。
③ sticky 策略有效地避免了上述两种策略完全无视历史分配方案的缺陷,采用了“有黏性”的策略对所有消费者实例进行分配,可以规避极端情况下的数据倾斜并且在两次rebalance间最大限度地维持了之前的分配方案。
2. range 范围分区策略介绍
RangeAssignor 分配策略的原理是按照消费者总数和分区总数进行整除运算来获得一个跨度,然后将分区按照跨度进行平均分配,以保证分区尽可能均匀地分配给消费者组内所有的消费者。
针对每一个主题而言,RangeAssignor策略会将订阅这个主题的消费组内的所有消费者按照名称的字典序排序,然后为每个消费者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配一个分区。

① 消费者组1订阅了主题A,则对主题A内的分区按照序号进行排序,对消费者组1内的消费者按照名称的字典序进行排序。然后用分区的总数除以消费者总数即5/4=1余1,则分区分配结果如图①:前1个消费者消费2个分区,其余消费者消费1个分区。
② 消费者组2订阅了主题B,则对主题B内的分区按照序号进行排序,对消费者组2内的消费者按照名称的字典序进行排序。然后用分区的总数除以消费者总数即5/3=1余2,则分区分配结果如图②:前 2个消费者消费2个分区,其余消费者消费1个分区。
注意:如果只是针对 1 个主题而言,consumer0 消费者多消费1个分区影响不是很大。但是如果有 N 多个主题,那么每个主题,消费者 consumer0 都将多消费 1 个分区,最终 consumer0 消费者会比其他消费者多消费 N 个分区,则有可能出现部分消费者过载的情况。
range 分区分配策略演示:
Kafka提供了消费者客户端参数 partition.assignment.strategy 来设置消费者与订阅主题之间的分区分配策略。默认情况下,此参数的值为 org.apache.kafka.clients.consumer.RangeAssignor,即采用RangeAssignor分配策略。
① 先启动3个消费者,然后启动生产者发送消息,查看每个消费者消费的分区:
consumer02 消费者消费分区0和分区1:
分区0消费数据:hello,kafka
分区1消费数据:hello,kafka
...
consumer03 消费者消费分区2和分区3:
分区2消费数据:hello,kafka
分区3消费数据:hello,kafka
...
consumer01 消费者消费的分区4:
分区4消费数据:hello,kafka
...
② 停止掉 consumer01 消费者,等待45s 以后再次重新发送消息观看结果:
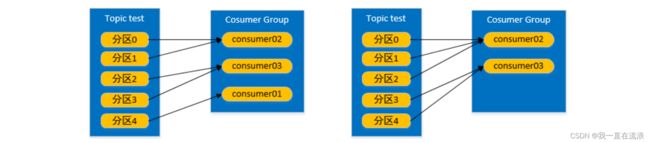
consumer02 消费者消费的分区:
分区0消费数据:hello,kafka
分区1消费数据:hello,kafka
分区2消费数据:hello,kafka
...
consumer03 消费者消费的分区:
分区3消费数据:hello,kafka
分区4消费数据:hello,kafka
...
consumer01 消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,时间到了 45s 后,判断它真的退出后就会重新按照 range 方式分配分区给消费者。
3. round-robin 轮询分区策略
round-robin 轮询分区策略针对集群中所有主题而言,它的原理是将消费组内所有消费者及消费者订阅的所有主题的分区按照字典序排序,然后通过轮询方式逐个将分区依次分配给每个消费者。

消费者组1订阅了主题A和主题B,则对主题A和主题B内的所有分区按照序号进行排序,对消费者1内的所有消费者按照名称字典序进行排序,然后通过轮询方式逐个将分区依次分配给每个消费者,则分区分配结果如图所示。
round-robin 轮询分区策略演示:
① 修改消费者 consumer01、consumer02、consumer03的分区分配策略为 RoundRobinAssignor,同时修改消费者组名为 test-group
// 设置分区分配策略为 round-robin
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, RoundRobinAssignor.class.getName());
② 启动三个消费者,然后启动生产者发送消息,查看分区分配结果:
consumer02 消费者消费分区0和分区3:
分区0消费数据:hello,kafka
分区3消费数据:hello,kafka
...
consumer03 消费者消费分区1和分区4:
分区1消费数据:hello,kafka
分区4消费数据:hello,kafka
...
consumer01 消费者消费的分区2:
分区2消费数据:hello,kafka
...
③ 停止掉 consumer01 消费者,等待45s 以后再次重新发送消息观看结果:

consumer02 消费者消费的分区:
分区0消费数据:hello,kafka
分区2消费数据:hello,kafka
分区4消费数据:hello,kafka
...
consumer03 消费者消费的分区:
分区1消费数据:hello,kafka
分区3消费数据:hello,kafka
...
consumer01 消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,时间到了 45s 后,判断它真的退出后就会重新按照 round-robin 方式分配分区给消费者。
4. sticky 粘性分区策略
粘性策略是 Kafka 从 0.11.x 版本开始引入,首先会尽量均衡的放置分区到消费者上面,在同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化。

① 消费者组1订阅了主题A和主题B,则对主题A和主题B内的所有分区按照序号进行排序,对消费者1内的所有消费者按照名称字典序进行排序,然后通过轮询方式逐个将分区依次分配给每个消费者。则分区分配结果如图①
这样初看上去似乎与采用round-robin 分配策略所分配的结果相同,但事实是否真的如此呢?假设此时消费者consumer1 脱离了消费组,那么消费组就会执行再均衡操作,进而消费分区会重新分配。
② 如果采用round-robin 分配策略,那么此时的分配结果如图②
③ 如果采用round-robin 分配策略,那么此时的分配结果如图③
可以看到分配结果中保留了上一次分配中对消费者 consumer0 和 consumer2 的所有分配结果,并将原来消费者consumer1 的“负担”分配给了剩余的两个消费者 consumer0 和 consumer2 ,最终 consumer0 和 consumer2 的分配还保持了均衡。
如果发生分区重分配,那么对于同一个分区而言,有可能之前的消费者和新指派的消费者不是同一个,之前消费者进行到一半的处理还要在新指派的消费者中再次复现一遍,这显然很浪费系统资源。StickyAssignor 分配策略如同其名称中的“sticky”一样,让分配策略具备一定的“黏性”,尽可能地让前后两次分配相同,进而减少系统资源的损耗及其他异常情况的发生。
sticky 轮询分区策略演示:
① 修改消费者 consumer01、consumer02、consumer03的分区分配策略为 StickyAssignor,同时修改消费者组名为 test-group-1
// 设置分区分配策略为sticky
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, StickyAssignor.class.getName());
② 启动三个消费者,然后启动生产者发送消息:
consumer01 消费者消费分区0和分区3:
分区0消费数据:hello,kafka
分区3消费数据:hello,kafka
...
consumer03 消费者消费分区1和分区4:
分区1消费数据:hello,kafka
分区4消费数据:hello,kafka
...
consumer02 消费者消费的分区2:
分区2消费数据:hello,kafka
...
③ 停止掉 consumer01 消费者,等待45s 以后再次重新发送消息观看结果:

consumer02 消费者消费的分区:
分区2消费数据:hello,kafka
分区0消费数据:hello,kafka
...
consumer03 消费者消费的分区:
分区1消费数据:hello,kafka
分区4消费数据:hello,kafka
分区3消费数据:hello,kafka
...
consumer01 消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,时间到了 45s 后,判断它真的退出后就会重新按照 sticky 方式分配分区给消费者。
5. 自定义分区分配策略
Kafka提供了消费者客户端参数 partition.assignment.strategy 来设置消费者与订阅主题之间的分区分配策略。默认情况下,此参数的值为 org.apache.kafka.clients.consumer.RangeAssignor,即采用RangeAssignor分配策略。除此之外,Kafka还提供了另外两种分配策略:RoundRobinAssignor 和 StickyAssignor。消费者客户端参数partition.assignment.strategy可以配置多个分配策略,彼此之间以逗号分隔。
public class MyAssignor extends AbstractPartitionAssignor {
@Override
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionPerTopic, Map<String, Subscription> subscriptions) {
Map<String,List<String>> consumersPerTopic = consumersPerTopic(subscriptions);
Map<String,List<TopicPartition>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet()) {
assignment.put(memberId,new ArrayList<>());
}
//针对每一个主题进行分区分配
for (Map.Entry<String, List<String>> topicEntry : consumersPerTopic.entrySet()) {
String topic = topicEntry.getKey();
List<String> consumersForTopic = topicEntry.getValue();
int consumerSize = consumersForTopic.size();
Integer numPartitionsForTopic = partitionPerTopic.get(topic);
if(numPartitionsForTopic == null){
continue;
}
// 当前主题下所有的分区
List<TopicPartition> partitions = AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic);
for (TopicPartition partition : partitions) {
int rand = new Random().nextInt(consumerSize);
String randomConsumer = consumersForTopic.get(rand);
assignment.get(randomConsumer).add(partition);
}
}
return assignment;
}
// 获取每个主题对应的消费者列表
private Map<String, List<String>> consumersPerTopic(Map<String, Subscription> consumerMetadata) {
Map<String, List<String>> res = new HashMap<>();
for (Map.Entry<String, Subscription> stringSubscriptionEntry : consumerMetadata.entrySet()) {
String consumerId = stringSubscriptionEntry.getKey();
for (String topic : stringSubscriptionEntry.getValue().topics()) {
put(res,topic,consumerId);
}
}
return res;
}
@Override
public String name() {
return "my-assignor";
}
}
在消费者中使用自定义的分区分配策略:
public class CustomConsumer01 {
private static final String brokerList = "10.65.132.2:9093";
private static final String topic = "test";
public static Properties initConfig(){
Properties properties = new Properties();
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,brokerList);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test-group-1");
// 设置分区分配策略为 round-robin
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, MyAssignor.class.getName());
return properties;
}
public static void main(String[] args) {
Properties properties = initConfig();
// 创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
// 订阅主题 test
ArrayList<String> topics = new ArrayList<>();
topics.add(topic);
consumer.subscribe(topics);
// 消费数据
while (true){
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println("分区"+consumerRecord.partition()+"消费数据:"+consumerRecord.value());
}
}
}
}