WebServer项目的亮点和难点
文章目录
- 一、亮点
-
- 1.采用了Reactor设计模式
-
- 为什么选择Reactor?
- WebServer选择的Reactor方案
- WebServer对Reactor的具体实现
- 2.EPOLLONESHOT
- 3.基于小根堆实现了定时器
- 4.实现了可以自动增长的缓冲区
-
- 5.线程池
- 二、难点
- 三、有待改进的地方
面试被问到了这个问题,答得稀烂…但是我觉得这个问题真的问的很好,还是要好好想一想总结一下。
亮点:
并发模型为Reactor
使用Epoll水平触发+EPOLLONESHOT,非阻塞IO
为充分利用多核CPU的性能,以多线程的形式实现服务器,并实现线程池避免线程频繁创建销毁造成的系统开销
实现基于小根堆的定时器,用于断开超时连接
实现可以自动增长的缓冲区,作为HTTP连接的输入和输出缓冲区
一、亮点
1.采用了Reactor设计模式
为什么选择Reactor?
我们的目的是实现一个高并发的WebServer。
传统的方式(让服务器为每个客户端的连接都创建一个进程或线程)会存在两个主要问题:
1.线程或进程处理完连接上的业务逻辑后,就需要进行销毁,这样不停的创建和销毁,会造成服务器性能的开销和资源的浪费。
2.如果有几万个客户端请求,要创建几万个线程或进程去处理也是不现实的。
引入I/O多路复用技术:
I/O 多路复用技术会用一个系统调用函数来监听我们所有关心的连接,也就说可以在一个监控线程里面监控很多的连接。内核提供给了我们select、poll、epoll等多路复用的系统调用。
具体的处理三种方法不太一样,这里主要说一下epoll的方式。
我们把需要检测的事件注册到工作在内核里的epoll对象上,epoll以红黑树的方式组织需要检测的事件,epoll内有回调函数,当有新事件到来时就会调用回调函数,把就绪事件添加到就绪事件链表上,内核会返回就绪事件,我们的主进程就会在用户态中处理这些事件对应的业务。
Reactor 模式就是基于I/O 多路复用技术,Reactor 对I/O多路复用技术作了一层封装,让使用者不用考虑底层网络 API 的细节,只需要关注应用代码的编写。
WebServer选择的Reactor方案
wiki上的定义:
The reactor design pattern is an event handling pattern for handling service requests delivered concurrently to a service handler by one or more inputs. The service handler then demultiplexes the incoming requests and dispatches them synchronously to the associated request handlers.
从上述文字中我们可以看出以下关键点 :
- 是一种设计模式(design pattern)
- 事件驱动(event handling)
- 可以处理一个或多个(one or more inputs)同时到达(delivered concurrently)的输入源
- 通过Service Handler同步的将输入事件(Event)采用多路复用分发给相应的Request Handler(多个)处理
本项目采用的是单 Reactor 多线程方案的思想。
为什么说是思想呢?项目确实只有一个Reactor,以及线程池。但是实际实现和「单 Reactor 多线程」方案不完全一样。
「单 Reactor 多线程」方案的示意图如下:
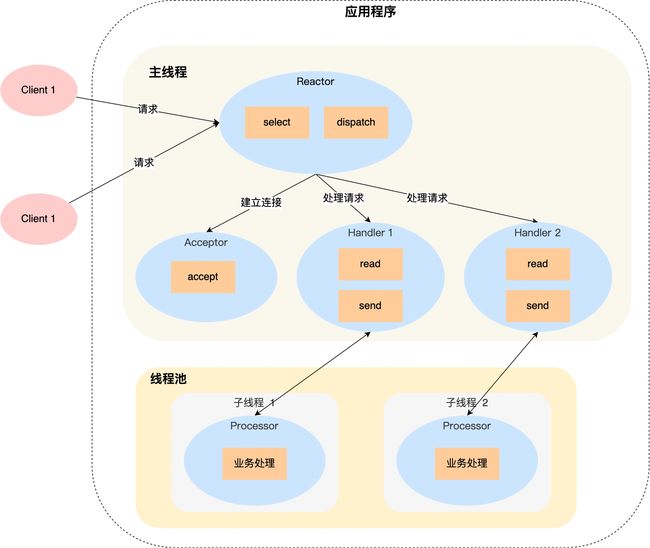
先详细说一下这个方案:
Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 根据收到事件的类型进行分发,具体分发给 Acceptor 对象或者Handler 对象;
如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
如果不是连接建立事件, 则交由当前连接对应的 Handler 对象来进行响应;
Handler 对象只负责数据的接收和发送,Handler 对象通过 read 读取到数据后,会将数据发给子线程里的 Processor 对象进行业务处理;
子线程里的 Processor 对象就进行业务处理,处理完后,将结果发给主线程中的 Handler 对象,接着由 Handler 通过 send 方法将响应结果发送给 client;
WebServer对Reactor的具体实现
先直接说区别吧,「单 Reactor 多线程」方案里Handler对象负责数据的接收和发送,也就是(read,write),子线程的Processor对象负责业务处理。但是项目里边对数据的接收和发送以及业务处理全都是子线程完成的。相当于Handler和Processor的职能全由子线程完成了。
具体的看项目:
首先,一个主进程负责监听,然后根据事件类型分别调用不同的函数进行处理。
int eventCnt = epoller_->Wait(timeMS);
for(int i = 0; i < eventCnt; i++) {
/* 处理事件 */
int fd = epoller_->GetEventFd(i);
uint32_t events = epoller_->GetEvents(i);
if(fd == listenFd_) {
DealListen_();//处理监听的操作,接受客户端连接
}
else if(events & (EPOLLRDHUP | EPOLLHUP | EPOLLERR)) {
assert(users_.count(fd) > 0);
CloseConn_(&users_[fd]);
}
else if(events & EPOLLIN) {
assert(users_.count(fd) > 0);
DealRead_(&users_[fd]); //处理读操作
}
else if(events & EPOLLOUT) {
assert(users_.count(fd) > 0);
DealWrite_(&users_[fd]); //处理写操作
} else {
LOG_ERROR("Unexpected event");
}
若是新连接就直接调用函数进行处理
void WebServer::DealListen_() {
struct sockaddr_in addr; //保持连接的客户端信息
socklen_t len = sizeof(addr);
do {
int fd = accept(listenFd_, (struct sockaddr *)&addr, &len);
if(fd <= 0) {
return;
}
else if(HttpConn::userCount >= MAX_FD) {
SendError_(fd, "Server busy!");
LOG_WARN("Clients is full!");
return;
}
AddClient_(fd, addr);
} while(listenEvent_ & EPOLLET);
}
若是读写事件,就交由线程池处理。
void WebServer::DealRead_(HttpConn* client) {
assert(client);
ExtentTime_(client);
threadpool_->AddTask(std::bind(&WebServer::OnRead_, this, client));
}
void WebServer::DealWrite_(HttpConn* client) {
assert(client);
ExtentTime_(client);
threadpool_->AddTask(std::bind(&WebServer::OnWrite_, this, client));
}
2.EPOLLONESHOT
epoll有两种触发的方式即LT(水平触发)和ET(边缘触发)两种,在前者,只要存在着事件就会不断的触发,直到处理完成,而后者只触发一次相同事件或者说只在从非触发到触发两个状态转换的时才触发。
这会出现下面一种情况,如果是多线程在处理,一个SOCKET事件到来,数据开始解析,这时候这个SOCKET又来了同样一个这样的事件,而你的数据解析尚未完成,那么程序会自动调度另外一个线程或者进程来处理新的事件,这造成一个很严重的问题,不同的线程或者进程在处理同一个SOCKET的事件,这会使程序的健壮性大降低而编程的复杂度大大增加!!即使在ET模式下也有可能出现这种情况!!
这里用EPOLLONESHOT这种方法进行解决,可以在epoll上注册这个事件,注册这个事件后,如果在处理写成当前的SOCKET后不再重新注册相关事件,那么这个事件就不再响应了或者说触发了。要想重新注册事件则需要调用epoll_ctl重置文件描述符上的事件,这样前面的socket就不会出现竞态这样就可以通过手动的方式来保证同一SOCKET只能被一个线程处理,不会跨越多个线程。
3.基于小根堆实现了定时器
实现了高并发的服务器通常会面临的一个问题就是有大量的连接建立,但是实际活跃的连接并不多,这样会造成服务器端的资源浪费,因此我们选择为每个连接添加一个定时器,如果该连接超过了定时时间仍然没有时间到达,服务器就主动关闭这个连接。
4.实现了可以自动增长的缓冲区
主要使用了散布读和集中写
#include 成员iov_base指向一个缓冲区,这个缓冲区是存放readv所接收的数据或是writev将要发送的数据。
成员iov_len确定了接收的最大长度以及实际写入的长度。
ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
ssize_t writev(int fd, const struct iovec *iov, int iovcnt);
参数:
fd是要在其上进行读或是写的文件描述符;
iov是读或写所用的I/O向量;
iovcnt是要使用的向量元素个数。
返回值:
readv所读取的字节数或writev所写入的字节数;
如果有错误发生,就会返回-1,错误代码存在errno中。
在项目的实现中根据readv()函数的返回值来进行相应操作,比如返回错误、返回下一次内存读入的位置或者用临时数组实现缓冲区的增长。writev()函数也同理。
5.线程池
采用生产者消费者模型。
用互斥量和条件变量实现了线程池。unique_lock与lock_guard的区别
而且notify_one()不会导致惊群。
二、难点
也许不是项目的难点而是我自己认为难的地方。
- Reactor思想的运用
- 为什么选择了socket非阻塞与epollET模式
这里我之前也写过一篇博文WebServer为什么需要将socket设置为非阻塞?
三、有待改进的地方
「单 Reactor」的模式存在一个问题,因为一个 Reactor 对象承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。这个也是WebServer这个项目存在的瓶颈之一。
参考链接:
【项目】高性能web服务器
C++11实现的高性能静态web服务器
高性能网络模式:Reactor 和 Proactor
Reactor详解
epoll的LT和ET使用EPOLLONESHOT