基于 Flink 的 OLAP 分析及实时数仓实践
摘要:本文整理自 BIGO Staff Engineer 邹云鹤在 Flink Forward Asia 2021 的分享。主要内容包括:
业务背景
落地实践 & 特色改进
应用场景
未来规划
一、业务背景
BIGO 是一家面向海外的以短视频直播业务为主的公司, 目前公司的主要业务包括 BigoLive (全球直播服务),Likee (短视频创作分享平台),IMO (免费通信工具) 三部分,在全球范围内拥有 4 亿用户。伴随着业务的发展,对数据平台处理能力的要求也是越来越高,平台所面临的问题也是日益凸显,接下来将介绍 BIGO 大数据平台及其所面临的问题。BIGO 大数据平台的数据流转图如下所示:
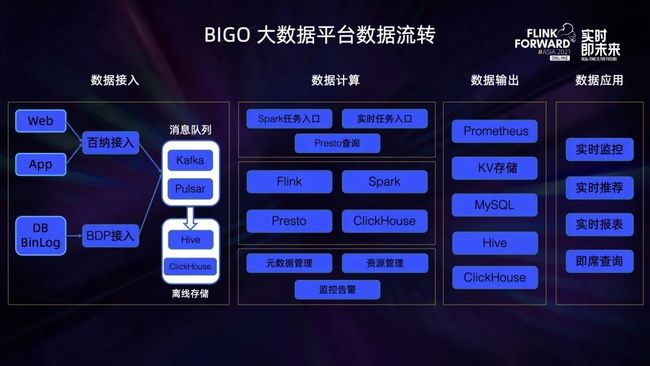
用户在 APP,Web 页面上的行为日志数据,以及关系数据库的 Binlog 数据会被同步到 BIGO 大数据平台消息队列,以及离线存储系统中,然后通过实时的,离线的数据分析手段进行计算,以应用于实时推荐、监控、即席查询等使用场景。然而存在以下几个问题:
OLAP 分析平台入口不统一:Presto/Spark 分析任务入口并存,用户不清楚自己的 SQL 查询适合哪个引擎执行,盲目选择,体验不好;另外,用户会在两个入口同时提交相同查询,以更快的获取查询结果,导致资源浪费;
离线任务计算时延高,结果产出太慢:典型的如 ABTest 业务,经常计算到下午才计算出结果;
各个业务方基于自己的业务场景独立开发应用,实时任务烟囱式的开发,缺少数据分层,数据血缘。
面对以上的问题,BIGO 大数据平台建设了 OneSQL OLAP 分析平台,以及实时数仓。
通过 OneSQL OLAP 分析平台,统一 OLAP 查询入口,减少用户盲目选择,提升平台的资源利用率;
通过 Flink 构建实时数仓任务,通过 Kafka/Pulsar 进行数据分层;
将部分离线计算慢的任务迁移到 Flink 流式计算任务上,加速计算结果的产出;
另外建设实时计算平台 Bigoflow 管理这些实时计算任务,建设实时任务的血缘关系。
二、落地实践 & 特色改进
2.1 OneSQL OLAP 分析平台实践和优化
OneSQL OLAP 分析平台是一个集 Flink、Spark、Presto 于一体的 OLAP 查询分析引擎。用户提交的 OLAP 查询请求通过 OneSQL 后端转发到不同执行引擎的客户端,然后提交对应的查询请求到不同的集群上执行。其整体架构图如下:

该分析平台整体结构从上到下分为入口层、转发层、执行层、资源管理层。为了优化用户体验,减少执行失败的概率,提升各集群的资源利用率,OneSQL OLAP 分析平台实现了以下功能:
统一查询入口:入口层,用户通过统一的 Hue 查询页面入口以 Hive SQL 语法为标准提交查询;
统一查询语法:集 Flink、Spark、Presto 等多种查询引擎于一体,不同查询引擎通过适配 Hive SQL 语法来执行用户的 SQL 查询任务;
智能路由:在选择执行引擎的过程中,会根据历史 SQL 查询执行的情况 (在各引擎上是否执行成功,以及执行耗时),各集群的繁忙情况,以及各引擎对该 SQL 语法的是否兼容,来选择合适的引擎提交查询;
失败重试:OneSQL 后台会监控 SQL 任务的执行情况,如果 SQL 任务在执行过程中失败,将选择其他的引擎执行重试提交任务;
如此一来,通过 OneSQL OLAP 分析平台,BIGO 大数据平台实现了 OLAP 分析入口的统一,减少用户的盲目选择,同时充分利用各个集群的资源,减少资源空闲情况。
■ 2.1.1 Flink OLAP 分析系统建设
在 OneSQL 分析平台上,Flink 也作为 OLAP 分析引擎的一部分。Flink OLAP 系统分成两个组成部分:Flink SQL Gateway 和 Flink Session 集群;SQL Gateway 作为 SQL 提交的入口,查询 SQL 经过 Gateway 提交到 Flink Session 集群上执行,同时获取 SQL 执行查询的进度,以及返回查询的结果给客户端。其执行 SQL 查询的流程如下:
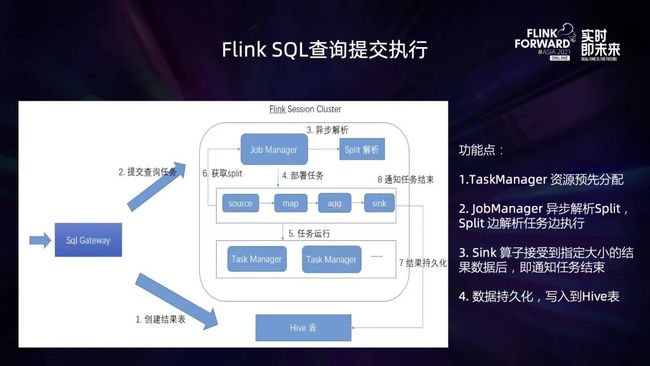
首先用户提交过来的 SQL,在 SQL Gateway 进行判断:是否需要将结果持久化写入到 Hive 表,如果需要,则会先通过 HiveCatalog 的接口创建一个 Hive 表,用于持久化查询任务的计算结果;之后,任务通过 SQL Gateway 上执行 SQL 解析,设置作业运行的并行度,生成 Pipeline 并提交到 Session 集群上执行。
为了保证整个 Flink OLAP 系统的稳定性,以及高效的执行 SQL 查询,在这个系统中,进行了以下功能增强:
稳定性:
基于 zookeeper HA 来保证 Flink Session 集群的可靠性,SQL Gateway 监听 Zookeeper 节点,感知 Session 集群;
控制查询扫描 Hive 表的数据量,分区个数,以及返回结果数据量,防止 Session 集群的 JobManager,TaskManager 因此出现 OOM 情况;
性能:
Flink Session 集群预分配资源,减少作业提交后申请资源所需的时间;
Flink JobManager 异步解析 Split,Split 边解析任务边执行,减少由于解析 Split 阻塞任务执行的时间;
控制作业提交过程中扫描分区,以及 Split 最大的个数,减少设置任务并行所需要的时间;
Hive SQL 兼容:
针对 Flink 对于 Hive SQL 语法的兼容性进行改进,目前针对 Hive SQL 的兼容性大致为 80%;
监控告警:
监控 Flink Session 集群的 JobManager,TaskManager,以及 SQL Gateway 的内存,CPU 使用情况,以及任务的提交情况,一旦出现问题,及时告警和处理;
■ 2.1.2 OneSQL OLAP 分析平台取得的成果
基于以上实现的 OneSQL OLAP 分析平台,取得了以下几个收益:
统一查询入口,减少用户的盲目选择,用户执行出错率下降 85.7%,SQL 执行的成功率提升 3%;
SQL 执行时间缩短 10%,充分利用了各个集群的资源,减少任务排队等待的时间;
Flink 作为 OLAP 分析引擎的一部分,实时计算集群的资源利用率提升了 15%;
2.2 实时数仓建设和优化
为了提升 BIGO 大数据平台上某些业务指标的产出效率,以及更好的管理 Flink 实时任务,BIGO 大数据平台建设了实时计算平台 Bigoflow,并将部分计算慢的任务迁移到实时计算平台上,通过 Flink 流式计算的方式来执行,通过消息队列 Kafka/Pulsar 来进行数据分层,构建实时数仓;在 Bigoflow 上针对实时数仓的任务进行平台化管理,建立统一的实时任务接入入口,并基于该平台管理实时任务的元数据,构建实时任务的血缘关系。
■ 2.2.1 建设方案
BIGO 大数据平台主要基于 Flink + ClickHouse 建设实时数仓,大致方案如下:
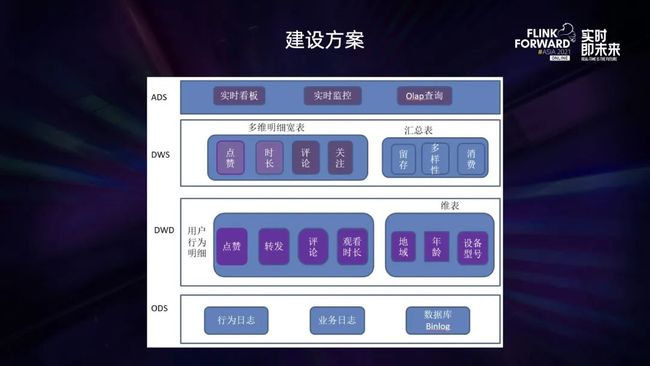
按照传统数据仓库的数据分层方法,将数据划分成 ODS、DWD、DWS、ADS 等四层数据:
ODS 层:基于用户的行为日志,业务日志等作为原始数据,存放于 Kafka/Pulsar 等消息队列中;
DWD 层:这部分数据根据用户的 UserId 经过 Flink 任务进行聚合后,形成不同用户的行为明细数据,保存到 Kafka/Pulsar 中;
DWS 层:用户行为明细的 Kafka 流表与用户 Hive/MySQL 维表进行流维表 JOIN,然后将 JOIN 之后产生的多维明细数据输出到 ClickHouse 表中;
ADS 层:针对 ClickHouse 中多维明细数据按照不同维度进行汇总,然后应用于不同的业务中。
按照以上方案建设实时数据仓库的过程中,遇到了一些问题:
将离线任务转为实时计算任务后,计算逻辑较为复杂 (多流 JOIN,去重),导致作业状态太大,作业出现 OOM (内存溢出) 异常或者作业算子背压太大;
维表 Join 过程中,明细流表与大维表 Join,维表数据过多,加载到内存后 OOM,作业失败无法运行;
Flink 将流维表 Join 产生的多维明细数据写入到 ClickHouse,无法保证 Exactly-once,一旦作业出现 Failover,就会导致数据重复写入。
■ 2.2.2 问题解决 & 优化
优化作业执行逻辑,减小状态
离线的计算任务逻辑较为复杂,涉及多个 Hive 表之间的 Join 以及去重操作,其大致逻辑如下:

当将离线的作业转为 Flink 的流式任务之后,原先离线 Join 多个 Hive 表的场景就转变为 Join 多个 Kafka Topic 的场景。由于 Join 的 Kafka topic 的流量较大,且 Join 的窗口时间较长 (窗口最长的为 1 天),当作业运行一段时间内,Join 算子上就积累了大量的状态 (一小时后状态就接近 1T),面对如此大的状态,Flink 作业采取 Rocksdb State Backend 来存放状态数据,但是仍然避免不了 Rocksdb 内存使用超过导致被 YARN kill 的问题,或者是 Rocksdb State 上存的状态太多,吞吐下降导致作业严重背压。
针对这个问题,我们将这多个 Topic,按照相同的 Schema 进行 Unoin all 处理,得到一个大的数据流,然后在这个大的数据流中,再根据不同事件流的 event_id 进行判断,就能知道这条数据来自哪一个事件流的 Topic,再进行聚合计算,获取对应事件流上的计算指标。
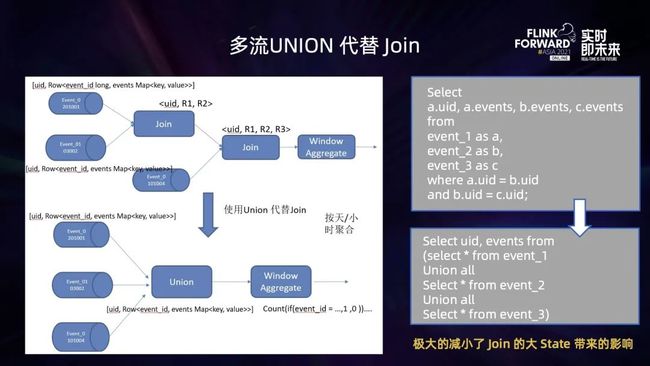
这样一来,通过 UNION ALL 代替 JOIN,避免了因为 JOIN 计算带来的大 State 带来的影响。
另外,在计算任务中还存在有比较多的 count distinct 计算,类似如下:
select
count(distinct if(events['a'] = 1, postid, null))
as cnt1,
count(distinct if(events['b'] = 1, postid, null))
as cnt2
……
count(distinct if(events['x'] = 1, postid, null))
As cntx
From table_a
Group by uid这些 count distinct 计算在同一个 group by 中,并基于相同的 postid 进行去重计算,因而可以让这些 distinct state 可以共享一组 key 来进行去重计算,那么就可以通过一个 MapState 来存储这若干个 count distinct 的状态,如下:
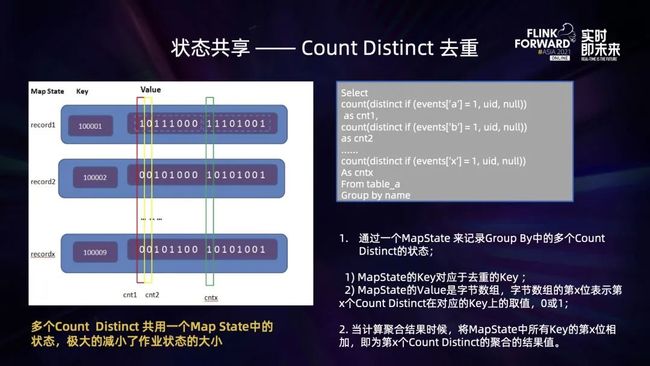
这些 count distinct 函数去重的 key 相同,因而可以共享 MapState 中的 key 值,从而优化存储空间;而 MapState 的 Value 是 Byte 数组,每个 Byte 8 个 bit,每个 bit 为 0 或者 1,第 n 个 bit 对应了 n 个 count distinct 函数在该 key 上的取值:1 表示该 count disitnct 函数在对应的 key 上需要进行计数,0 表示不需要计数;当计算聚合结果的时候,则将所有 key 第 n 位的数字相加,即为第 n 个 count distinct 的取值,这样一来,就更进一步节约了状态的存储空间。
通过以上优化,成功的将 ABTest 的离线任务迁移到 Flink 流式计算任务上,将作业的状态控制在 100GB 以内,让作业正常的运行起来。
流维表 JOIN 优化
生成多维明细宽表的过程中,需要进行流维表 JOIN, 使用了 Flink Join Hive 维表的功能:Hive 维表的数据会被加载到任务的 HashMap 的内存数据结构中,流表中的数据再根据 Join Key 与 HashMap 中的数据进行 Join。但是面对上亿,十亿行的 Hive 大维表,加载到内存的数据量太大,很容易导致 OOM (内存溢出)。针对以上问题,我们将 Hive 大维表按照 Join Key 进行 Hash 分片,如下图:

这样一来,Hive 大维表的数据经过 Hash 函数计算后分布到 Flink 作业的不同并行子任务的 HashMap 中,每个 HashMap 只存放大维表的一部分数据,只要作业的并行度够大,就能够将大维表的数据拆分成足够多份,进行分片保存;对于一些太大的维表,也可以采取 Rocksdb Map State 来保存分片数据。
Kafka 流表中的数据,当要下发到不同的 subtask 上进行 Join 时,也通过相同的 Join Key 按照相同的 Hash 函数进行计算,从而将数据分配到对应的 subtask 进行 Join,输出 Join 后的结果。
通过以上优化,成功 Join 了一些 Hive 大维表任务来执行流维表 Join 计算,最大的维表超过 10 亿行。
ClickHouse Sink 的 Exactly-Once 语义支持
将流维表 Join 生成的多维明细数据输出到 ClickHouse 表的过程中,由于社区的 ClickHouse 不支持事务,所以没办法保证数据 sink 到 ClickHouse 过程中的 Exactly-Once 语义。在此过程中,一旦出现作业 Failover,数据就会重复写入到 ClickHouse。
针对这个问题,BIGO ClickHouse 实现了一个二阶段提交事务机制:当需要写入数据到 ClickHouse 时,可以先设置写入的模式为 temporary,表明现在写入的数据是临时数据;当数据执行插入完成后,返回一个 Insert id,然后根据该 Insert id 执行 Commit 操作,那么临时数据就转为正式数据。
基于 BIGO ClickHouse 的二阶段提交事务机制,并结合 Flink 的 checkpoint 机制,实现了一个 ClickHouse Connector,保证 ClickHouse Sink 的 Exactly Once 写入语义,如下:
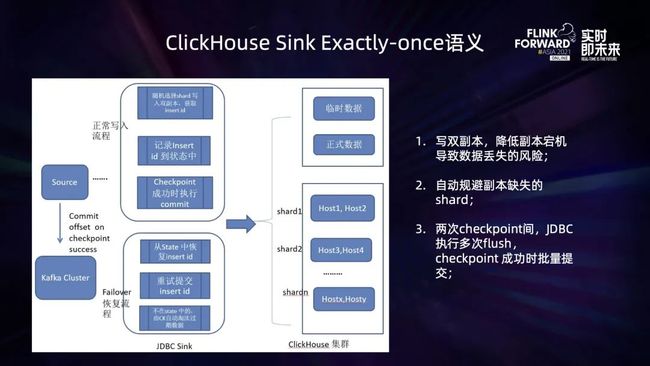
在正常写入的情况下,Connector 随机选择 ClickHouse 的某一个 shard 写入,根据用户配置写单副本,或者双副本来执行 insert 操作,并记录写入后的 insert id;在两次 checkpoint 之间就会有多次这种 insert 操作,从而产生多个 insert id,当 checkpoint 完成时,再将这些 insert id 批量提交,将临时数据转为正式数据,即完成了两次 checkpoint 间数据的写入;
一旦作业出现 Failover,Flink 作业 Failover 重启完成后,将从最近一次完成的 checkpoint 来恢复状态,此时 ClickHouse Sink 中的 Operator State 可能会包含上一次还没有来得及提交完成的 Insert id,针对这些 insert id 进行重试提交;针对那些数据已经写入 ClickHouse 中之后,但是 insert id 并没有记录到 Opeator State 中的数据,由于是临时数据,在 ClickHouse 中并不会被查询到,一段时间后,将会由 ClickHouse 的过期清理机制,被清理掉,从而保证了状态回滚到上一次 checkpoint 之后,数据不会重复。
通过以上机制,成功保证了数据从 Kafka 经过 Flink 计算后写入到 ClickHouse 整个链路中端到端的 Exactly-Once 语义,数据不重复也不丢失。
■ 2.2.3 平台建设
为了更好的管理 BIGO 大数据平台的实时计算任务,公司内部建设了 BIGO 实时计算平台 Bigoflow,为用户提供统一的 Flink实时任务接入,平台建设如下:
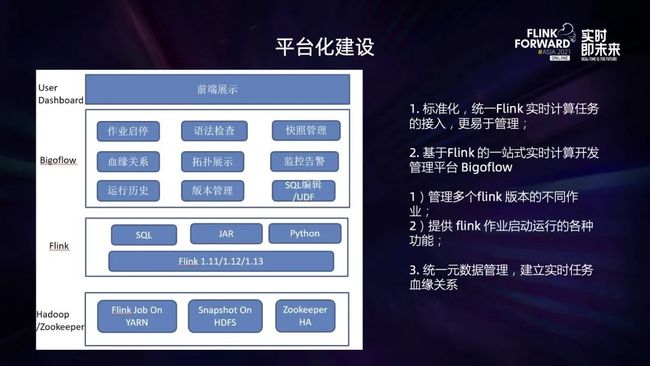
支持 Flink JAR、SQL、Python 等多种类型作业;支持不同的 Flink 版本,覆盖公司内部大部分实时计算相关业务;
一站式管理:集作业开发、提交、运行、历史展示、监控、告警于一体,便于随时查看作业的运行状态和发现问题;
血缘关系:方便查询每个作业的数据源、数据目的、数据计算的来龙去脉。
三、应用场景
3.1 Onesql OLAP 分析平台应用场景
Onesql OLAP 分析平台在公司内部的应用场景是:应用于 AdHoc 查询,如下:

用户通过 Hue 页面提交的 SQL,通过 OneSQL 后端转发给 Flink SQL Gateway,并提交到 Flink Session 集群上执行查询任务,Flink SQL Gateway 获取查询任务的执行进度返回给 Hue 页面,并返回查询结果。
3.2 实时数据仓库应用场景
实时数据仓库应用场景目前主要是 ABTest 业务,如下:

用户的原始行为日志数据经过 Flink 任务聚合后生成用户明细数据,然后与维表数据进行流维表 JOIN,输出到 ClickHouse 生成多维明细宽表,按照不同维度汇总后,应用于不同的业务。通过改造 ABTest 业务,将该业务的结果指标的生成时间提前了 8 个小时,同时减少了使用资源一倍以上。
四、未来规划
为了更好的建设 OneSQL OLAP 分析平台以及 BIGO 实时数据仓库,实时计算平台的规划如下:
完善 Flink OLAP 分析平台,完善 Hive SQL 语法支持,以及解决计算过程中出现的 JOIN 数据倾斜问题;
完善实时数仓建设,引入数据湖技术,解决实时数仓中任务数据的可重跑回溯范围小的问题;
基于 Flink 打造流批一体的数据计算平台。
