06_Hudi案例实战
本文来自"黑马程序员"hudi课程
6.第六章 Hudi案例实战
6.1 案例架构
6.2 业务数据
6.2.1 消息数据格式
6.2.2 数据生成
6.3 七陌数据采集
6.3.1 Apache Flume 是什么
6.3.2 Apache Flume 运行机制
6.3.3 Apache Flume 安装部署
6.3.4 Apache Flume 入门程序
6.3.5 七陌社交数据采集
6.3.5 七陌社交数据采集
6.4.1 创建模块
6.4.2 封装实体类
6.4.3 编写流式程序
6.4.3.1 构建SparkSession实例对象
6.4.3.2 消费Kafka数据
6.4.3.3 打印控制台
6.4.3.4 数据解析转换
6.4.3.5 保存Hudi表
6.4.4 流式程序运行
6.5 集成Hive指标分析
6.5.1 创建Hive表
6.5.2 业务指标分析
6.6 Spark 离线指标分析
6.6.1 需求说明
6.6.2 创建数据库表
6.6.3 编写指标分析程序
6.6.3.1 加载Hudi表数据
6.6.3.2 解析IP地址及选择字段
6.6.3.3 业务指标分析
6.6.4 报表程序运行
6.7 FineBI 报表可视化
6.7.1 安装FineBI
6.7.2 配置数据源
6.7.3 添加数据集
6.7.4 创建仪表盘
6.7.5 柱形图:Top10用户发送信息量
6.7.6 饼图:Top10省份发送信息量
6.7.7 地图:各省份信息量
6. 第六章 Hudi案例实战
七陌社交是一家专门做客服系统的公司, 传智教育是基于七陌社交构建客服系统,每天都有非常多的的用户进行聊天, 传智教育目前想要对这些聊天记录进行存储, 同时还需要对每天的消息量进行实时统计分析, 请您来设计如何实现数据的存储以及实时的数据统计分析工作。
需求如下:
-
- 选择合理的存储容器进行数据存储, 并让其支持基本数据查询工作
-
- 进行实时统计消息总量
-
- 进行实时统计各个地区收 发 消息的总量
-
- 进行实时统计每一位客户发送和接收消息数量
6.1 案例架构
实时采集七陌用户聊天信息数据,存储消息队列Kafka,再实时将数据处理转换,将其消息存储Hudi表中,最终使用Hive和Spark业务指标统计,基于FanBI可视化报表展示。

-
1、Apache Flume:分布式实时日志数据采集框架
由于业务端数据在不断的在往一个目录下进行生产, 我们需要实时的进行数据采集, 而flume就是一个专门用于数据采集工具,比如就可以监控某个目录下文件, 一旦有新的文件产生即可立即采集。 -
2、Apache Kafka:分布式消息队列
Flume 采集过程中, 如果消息非常的快, Flume也会高效的将数据进行采集, 那么就需要一个能够快速承载数据容器, 而且后续还要对数据进行相关处理转换操作, 此时可以将flume采集过来的数据写入到Kafka中,进行消息数据传输,而Kafka也是整个集团中心所有业务线统一使用的消息系统, 用来对接后续的业务(离线或者实时)。 -
3、Apache Spark:分布式内存计算引擎,离线和流式数据分析处理
整个七陌社交案例, 需要进行实时采集,那么此时也就意味着数据来一条就需要处理一条, 来一条处理一条, 此时就需要一些流式处理的框架,Structured Streaming或者Flink均可。
此外,七陌案例中,对每日用户消息数据按照业务指标分析,最终存储MySQL数据库中,选择SparkSQL。 -
4、Apache Hudi:数据湖框架
七陌用户聊天消息数据,最终存储到Hudi表(底层存储:HDFS分布式文件系统),统一管理数据文件,后期与Spark和Hive集成,进行业务指标分析。 -
5、Apache Hive:大数据数仓框架
与Hudi表集成,对七陌聊天数据进行分析,直接编写SQL即可。 -
6、MySQL:关系型数据库
将业务指标分析结果存储在MySQL数据库中,后期便于指标报表展示。 -
7、FineBI:报表工具
帆软公司的一款商业图表工具, 让图表制作更加简单
6.2 业务数据
本次案例, 直接提供专门用于生产七陌社交消息数据的工具, 可以直接部署在业务端进行数据生成即可,接下来部署用于生产数据的工具jar包。
6.2.1 消息数据格式
用户聊天数据以文本格式存储日志文件中,包含20个字段,下图所示:

样本数据:

上述数据各个字段之间分割符号为:\001
6.2.2 数据生成
运行jar包:7Mo_DataGen.jar,指定参数信息,模拟生成用户聊天信息数据,写入日志文件。

- 第一步、创建原始文件目录
mkdir -p /export/data/7mo_init
- 第二步、上传模拟数据程序
cd /export/data/7mo_init
rz

- 第三步、创建模拟数据目录
mkdir -p /export/data/7mo_data
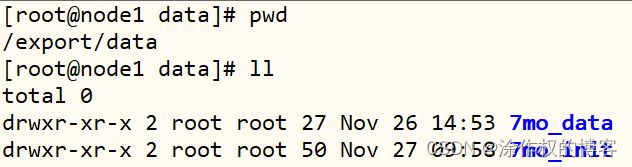
- 第四步、运行程序生成数据
# 1. 语法
java -jar /export/data/7mo_init/7Mo_DataGen.jar 原始数据路径 模拟数据路径 随机产生数据间隔ms时间
# 2. 测试:每500ms生成一条数据
java -jar /export/data/7mo_init/7Mo_DataGen.jar \
/export/data/7mo_init/7Mo_Data.xlsx \
/export/data/7mo_data \
500
- 第五步、查看产生数据

6.3 七陌数据采集
由于七陌用户比较多和活跃度很高,聊天信息数据比较大(每日增量:25GB至30GB),采用实时方式采集数据,此处选择框架:Apache Flume。
6.3.1 Apache Flume 是什么
Aapche Flume是由Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的软件,网址:http://flume.apache.org/

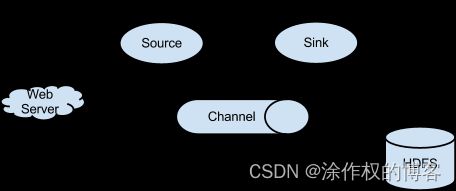
Flume的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。
当前Flume有两个版本:
- Flume 0.9X版本的统称Flume OG(original generation)
- Flume1.X版本的统称Flume NG(next generation)
由于Flume NG经过核心组件、核心配置以及代码架构重构,与Flume OG有很大不同。改动的另一原因是将Flume纳入 apache 旗下,Cloudera Flume 改名为 Apache Flume。
6.3.2 Apache Flume 运行机制
Flume系统中核心的角色是agent,agent本身是一个Java进程,一般运行在日志收集节点。

每一个agent相当于一个数据传递员,内部有三个组件:
- Source:采集源,用于跟数据源对接,以获取数据;
- Sink:下沉地,采集数据的传送目的,用于往下一级agent或者往最终存储系统传递数据;
- Channel:agent内部的数据传输通道,用于从source将数据传递到sink;
在整个数据的传输的过程中,流动的是event,它是Flume内部数据传输的最基本单元。

event将传输的数据进行封装,如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。

一个完整的event包括:event headers、event body,其中event body是flume收集到的日记记录。
6.3.3 Apache Flume 安装部署
Apache Flume 的安装非常简单,直接解压,然后配置JDK环境变量即可。
第一步、上传解压
# 上传
cd /export/software
rz apache-flume-1.9.0-bin.tar.gz
# 解压,重命名及创建软链接
tar -zxf apache-flume-1.9.0-bin.tar.gz -C /export/server
cd /export/server
mv apache-flume-1.9.0-bin flume-1.9.0-bin
ln -s flume-1.9.0-bin flume
第二步、修改flume-env.sh
cd /export/server/flume/conf
mv flume-env.sh.template flume-env.sh
vim flume-env.sh
# 22行:修改JDK路径
export JAVA_HOME=/export/server/jdk

6.3.4 Apache Flume 入门程序
需求说明: 监听服务器上某一个端口号(例如: 44444), 采集发向此端口的数据。

- 第1步、确定三大组件
-
source组件: 需要一个能够监听端口号的组件(网络组件)
使用Apache Flume提供的 : NetCat TCP Source

-
channel组件: 需要一个传输速度更快的管道(内存组件)
使用Apache Flume提供的 : Memory Channel -
sink组件 : 此处我们只需要打印出来即可(日志组件)
使用Apache Flume提供的 : Logger Sink
- 第2步、编写采集配置文件:netcat_source_logger_sink.properties
cd /export/server/flume/conf
vim netcat_source_logger_sink.properties
内容如下:
# 第一部分: 定义这个agent中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#第二部分: 描述和配置source组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = node1.itcast.cn
a1.sources.r1.port = 44444
# 第三部分: 描述和配置sink组件:k1
a1.sinks.k1.type = logger
# 第四部分: 描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 第五部分: 描述和配置source channel sink之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 第3步、启动flume: 指定采集配置文件
/export/server/flume/bin/flume-ng agent -n a1 \
-c conf -f /export/server/flume/conf/netcat_source_logger_sink.properties \
-Dflume.root.logger=INFO,console
参数说明:
-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.con 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字
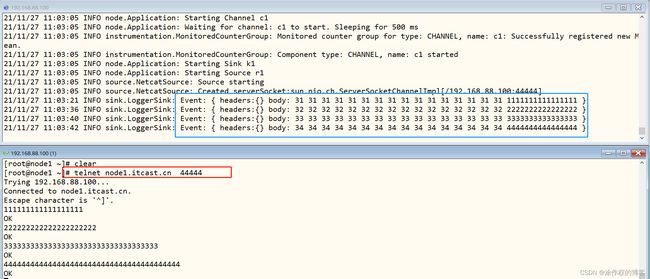
- 第4步、接下来进行测试: 一定要启动之后, 连接测试
先要往agent采集监听的端口上发送数据,让agent有数据可采。
- 安装telnet
yum -y install telnet
- 随便在一个能跟agent节点通信的机器上,执行如下命令
telnet node1.itcast.cn 44444
6.3.5 七陌社交数据采集
七陌社交数据源特点:持续不断的向某一个目录下得一个文件输出消息。功能要求:实时监控某一个目录下的文件, 一旦发现有新的文件,立即将其进行采集到Kafka中。

- 第1步、确定三大组件
- source组件: 能够监控某个目录的文件source组件
使用Apache Flume提供的 : taildir - channel组件: 一般都是选择 内存组件 (更高效)
使用Apache Flume提供 : Memory Channel - sink组件: 输出到 Kafka的sink组件
使用Apache Flume提供:Kafka Sink
- 第2步、编写采集配置文件:7mo_mem_kafka.properties
vim /export/server/flume/conf/7mo_mem_kafka.properties
内容如下:
# define a1
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#define s1
a1.sources.s1.type = TAILDIR
#指定一个元数据记录文件
a1.sources.s1.positionFile = /export/server/flume/position/taildir_7mo_kafka.json
#将所有需要监控的数据源变成一个组
a1.sources.s1.filegroups = f1
#指定了f1是谁:监控目录下所有文件
a1.sources.s1.filegroups.f1 = /export/data/7mo_data/.*
#指定f1采集到的数据的header中包含一个KV对
a1.sources.s1.headers.f1.type = 7mo
a1.sources.s1.fileHeader = true
#define c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
#define k1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = 7MO-MSG
a1.sinks.k1.kafka.bootstrap.servers = node1.itcast.cn:9092
a1.sinks.k1.kafka.flumeBatchSize = 10
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 100
#bind
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
- 第3步、启动ZK服务和Kafka服务
/export/server/zookeeper/bin/zkServer.sh start
/export/server/kafka/bin/kafka-server-start.sh -daemon /export/server/kafka/config/server.properties
- 第4步、创建topic
/export/server/kafka/bin/kafka-topics.sh --create \
--topic 7MO-MSG --partitions 3 --replication-factor 2 \
--bootstrap-server node1.itcast.cn:9092
- 第5步、启动flume: 指定采集配置文件
/export/server/flume/bin/flume-ng agent \
-n a1 -c /export/server/flume/conf/ \
-f /export/server/flume/conf/7mo_mem_kafka.properties \
-Dflume.root.logger=INFO,console
- 第6步、启动模拟数据
java -jar /export/data/7mo_init/7Mo_DataGen.jar \
/export/data/7mo_init/7Mo_Data.xlsx \
/export/data/7mo_data \
5000
观察Kafka Topic中是否有数据:

6.4 实时存储七陌数据
编写Spark中流式程序:StructuredStreaming,实时从Kafka消费获取社交数据,经过转换(数据字段提取等)处理,最终保存到Hudi表中,表的格式:ROM。

6.4.1 创建模块
创建Maven Module模块,基于Spark框架编写程序,添加相关依赖,工程结构如下:
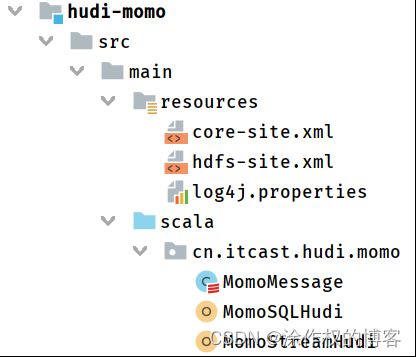
Module模块中pom.xml依赖:
<repositories>
<repository>
<id>aliyunid>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
repository>
<repository>
<id>clouderaid>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
<repository>
<id>jbossid>
<url>http://repository.jboss.com/nexus/content/groups/publicurl>
repository>
repositories>
<properties>
<scala.version>2.12.10scala.version>
<scala.binary.version>2.12scala.binary.version>
<spark.version>3.0.0spark.version>
<hadoop.version>2.7.3hadoop.version>
<hudi.version>0.9.0hudi.version>
<mysql.version>5.1.48mysql.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql-kafka-0-10_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.hudigroupId>
<artifactId>hudi-spark3-bundle_2.12artifactId>
<version>${hudi.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-avro_2.12artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hudigroupId>
<artifactId>hudi-hive-syncartifactId>
<version>${hudi.version}version>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpcoreartifactId>
<version>4.4.13version>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
<version>4.5.12version>
dependency>
<dependency>
<groupId>org.lionsoulgroupId>
<artifactId>ip2regionartifactId>
<version>1.7.2version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>${mysql.version}version>
dependency>
dependencies>
<build>
<outputDirectory>target/classesoutputDirectory>
<testOutputDirectory>target/test-classestestOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resourcesdirectory>
resource>
resources>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.0version>
<configuration>
<source>1.8source>
<target>1.8target>
<encoding>UTF-8encoding>
configuration>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.0version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
Hudi表数据存储在HDFS目录上, 将HDFS文件系统配置文件,放入模块Module资源目录resources下。

6.4.2 封装实体类
七陌社交数据解析封装实体类:MomoMessage ,基于Scala语言定义Case Class 样例类。
package cn.itcast.hudi.momo
/**
* 封装Momo聊天记录实体样例类CaseClass
*/
case class MomoMessage(
msg_time: String,
sender_nickyname: String,
sender_account: String,
sender_sex: String,
sender_ip: String,
sender_os: String,
sender_phone_type: String,
sender_network: String,
sender_gps: String,
receiver_nickyname: String,
receiver_ip: String,
receiver_account: String,
receiver_os: String,
receiver_phone_type: String,
receiver_network: String,
receiver_gps: String,
receiver_sex: String,
msg_type: String,
distance: String,
message: String
)
后续,将Kafka消费社交数据,解析封装到实体类对象中。
6.4.3 编写流式程序
创建对象object:MomoStreamHudi,编写MAIN方法,按照编写流式程序5个步骤,写出代码结构,如下所示:
package cn.itcast.hudi.momo
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.types.StringType
/**
* 编写StructuredStreaming流式程序:
实时消费Kafka中Momo聊天数据,进行转换处理,保存至Hudi表,并且自动同步至Hive表
*/
object MomoStreamHudi {
def main(args: Array[String]): Unit = {
// step1、构建SparkSession实例对象
val spark: SparkSession = createSparkSession(this.getClass)
// step2、从Kafka实时消费数据
val kafkaStreamDF: DataFrame = readFromKafka(spark, "7mo-msg")
// step3、提取数据,转换数据类型
val streamDF: DataFrame = process(kafkaStreamDF)
// step4、保存数据至Hudi表中:MOR(读取时保存)
//printToConsole(streamDF)
saveToHudi(streamDF)
// step5、流式应用启动以后,等待终止
spark.streams.active.foreach(
query => println(s"Query: ${query.name} is Running .............")
)
spark.streams.awaitAnyTermination()
}
}
6.4.3.1 构建SparkSession实例对象
从Spark2.x开始,程序入口SparkSession,无论SparkSQL批处理还是StructuredStreaming流计算,程序首先创建SparkSession对象,封装方法:createSparkSession
/**
* 创建SparkSession会话实例对象,基本属性设置
*/
def createSparkSession(clazz: Class[_]): SparkSession = {
SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 设置序列化方式:Kryo
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 设置属性:Shuffle时分区数和并行度
.config("spark.default.parallelism", 2)
.config("spark.sql.shuffle.partitions", 2)
.config("spark.sql.streaming.forceDeleteTempCheckpointLocation", "true")
.getOrCreate()
}
6.4.3.2 消费Kafka数据
封装方法:readFromKafka,从Kafka消费Topic数据,指定名称和Kafka Brokers地址信息。
/**
* 指定Kafka Topic名称,实时消费数据
*/
def readFromKafka(spark: SparkSession, topicName: String): DataFrame = {
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node1.itcast.cn:9092")
.option("subscribe", topicName)
.option("startingOffsets", "latest")
.option("maxOffsetsPerTrigger", 100000)
.option("failOnDataLoss", "false")
.load()
}
6.4.3.3 打印控制台
流式数据打印控制台,封装方法:printToConsole,便于开发过程中测试使用。
def printToConsole(streamDF: DataFrame): Unit = {
streamDF.writeStream
.outputMode(OutputMode.Append())
.queryName("query-hudi-momo")
.format("console")
.option("numRows", "10")
.option("truncate", "false")
.option("checkpointLocation", "/datas/hudi-struct-ckpt-0")
.start()
}
6.4.3.4 数据解析转换
对Kafka消费数据,先解析封装到实体类MomoMessage,再添加字段构建Hudi表中三大核心字段值:message_id 每条数据主键、day 分区字段及ts 数据合并字段。
/**
* 对Kafka获取数据,进行转换操作,获取所有字段的值,转换为String,以便保存Hudi表
*/
def process(streamDF: DataFrame): DataFrame = {
import streamDF.sparkSession.implicits._
/*
2021-11-25 20:52:58牛星海17870843110女156.35.36.204IOS 9.0华为 荣耀Play4T4G91.319474,29.033363成紫57.54.100.313946849234Android 6.0OPPO A11X4G84.696447,30.573691 女TEXT78.22KM有一种想见不敢见的伤痛,这一种爱还埋藏在我心中,让我对你的思念越来越浓,我却只能把你你放在我心中。
*/
// 1-提取Message消息数据
val messageStreamDF: DataFrame = streamDF.selectExpr("CAST(value AS STRING) message")
// 2-解析数据,封装实体类
val momoStreamDS: Dataset[MomoMessage] = messageStreamDF
.as[String] // 转换为Dataset
.map(message => {
val array = message.split("\001")
val momoMessage = MomoMessage(
array(0), array(1), array(2), array(3), array(4), array(5), array(6), array(7),
array(8), array(9),array(10), array(11), array(12), array(13), array(14),
array(15), array(16), array(17), array(18), array(19)
)
// 返回实体类
momoMessage
})
// 3-为Hudi表添加字段:主键id、数据聚合字段ts、分区字段day
val hudiStreamDF = momoStreamDS.toDF()
.withColumn("ts", unix_timestamp($"msg_time").cast(StringType))
.withColumn(
"message_id",
concat($"sender_account", lit("_"), $"ts", lit("_"), $"receiver_account")
)
.withColumn("day", substring($"msg_time", 0, 10))
hudiStreamDF
}
6.4.3.5 保存Hudi表
将流式数据集Stream DataFrame,使用foreachBatch方法,将每批次数据保存到Hudi表中,需要指定必要属性字段。
/**
* 将流式数据集DataFrame保存至Hudi表,分别表类型:COW和MOR
*/
def saveToHudi(streamDF: DataFrame): Unit = {
streamDF.writeStream
.outputMode(OutputMode.Append())
.queryName("query-hudi-momo")
// 针对每微批次数据保存
.foreachBatch((batchDF: Dataset[Row], batchId: Long) => {
println(s"============== BatchId: $batchId start ==============")
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.keygen.constant.KeyGeneratorOptions._
batchDF.write
.format("hudi")
.mode(SaveMode.Append)
.option(TBL_NAME.key, "7mo_msg_hudi")
.option(TABLE_TYPE.key(), "MERGE_ON_READ")
.option(RECORDKEY_FIELD_NAME.key(), "message_id")
.option(PRECOMBINE_FIELD_NAME.key(), "ts")
.option(PARTITIONPATH_FIELD_NAME.key(), "day")
.option(HIVE_STYLE_PARTITIONING_ENABLE.key(), "true")
// 插入数据,产生shuffle时,分区数目
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// 表数据存储路径
.save("/hudi-warehouse/7mo_msg_hudi")
})
.option("checkpointLocation", "/datas/hudi-struct-ckpt")
.start()
}
至此,流式程序StructuredStreaming编写完成,接下来启动各个组件服务,进行测试。
6.4.4 流式程序运行
启动服务:ZK服务、Kafka服务和HDFS服务,其次运行流式应用程序,最后运行Flume Agent和模拟数据程序,查看Hudi表数据存储目录。
# NameNode和DataNode
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
# ZK服务和Kafka服务
/export/server/zookeeper/bin/zkServer.sh start
/export/server/kafka/bin/kafka-server-start.sh -daemon /export/server/kafka/config/server.properties
# Flume Agent
/export/server/flume/bin/flume-ng agent \
-c conf/ \
-n a1 \
-f /export/server/flume/conf/7mo_mem_kafka.properties \
-Dflume.root.logger=INFO,console
# 模拟数据程序
java -jar /export/data/7mo_init/7Mo_DataGen.jar \
/export/data/7mo_init/7Mo_Data.xlsx \
/export/data/7mo_data/ \
5000
Hudi存储目录结构:
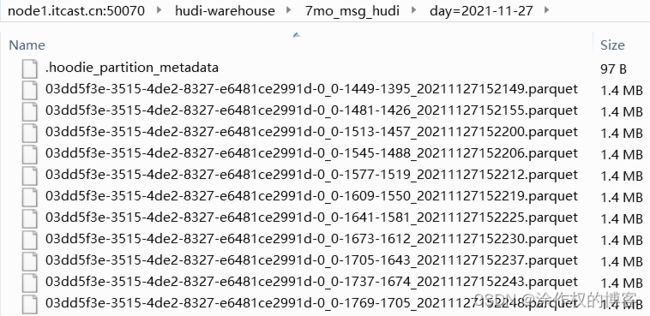
至此,实时存储七陌社交数据至Hudi表,整个链路已经完成:

6.5 集成Hive指标分析
将Hudi表数据,与Hive表进行关联,使用beeline等客户端,编写SQL分析Hudi表数据。

6.5.1 创建Hive表
启动Hive MetaStore服务和HiveServer2服务,再启动beeline客户端:
/export/server/hive/bin/start-metastore.sh
/export/server/hive/bin/start-hiveserver2.sh
/export/server/hive/bin/start-beeline.sh
编写DDL语句,创建Hive表,关联Hudi表,其中设置InputFormat实现类。
# 创建Hive表,映射到Hudi表
CREATE EXTERNAL TABLE db_hudi.tbl_7mo_hudi(
msg_time String,
sender_nickyname String,
sender_account String,
sender_sex String,
sender_ip String,
sender_os String,
sender_phone_type String,
sender_network String,
sender_gps String,
receiver_nickyname String,
receiver_ip String,
receiver_account String,
receiver_os String,
receiver_phone_type String,
receiver_network String,
receiver_gps String,
receiver_sex String,
msg_type String,
distance String,
message String,
message_id String,
ts String
)
PARTITIONED BY (day string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION '/hudi-warehouse/7mo_msg_hudi' ;
由于Hudi是分区表,需要手动添加分区信息:
alter table db_hudi.tbl_7mo_hudi
add if not exists partition(day = '2021-11-27') location '/hudi-warehouse/7mo_msg_hudi/day=2021-11-27' ;

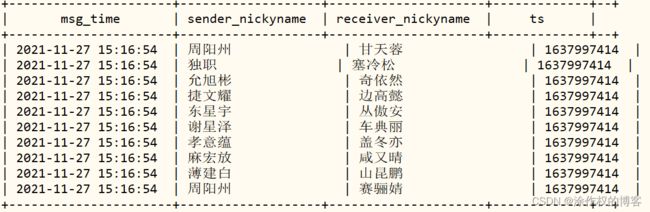
查询Hive表前10条数据:
SELECT
msg_time, sender_nickyname, receiver_nickyname, ts
FROM db_hudi.tbl_7mo_hudi
WHERE day = '2021-11-27'
limit 10 ;
6.5.2 业务指标分析
编写SQL,对七陌社交数据进行简易指标统计分析,由于数据流较小,设置本地模式执行。
set hive.exec.mode.local.auto=true;
set hive.mapred.mode=nonstrict;
- 指标1:统计总消息量
WITH tmp AS (
SELECT COUNT(1) AS momo_total FROM db_hudi.tbl_7mo_hudi WHERE day = '2021-11-27'
)
SELECT "全国" AS momo_name, momo_total FROM tmp;

- 指标2:统计各个用户, 发送消息量
WITH tmp AS (
SELECT
sender_nickyname, COUNT(1) momo_total
FROM db_hudi.tbl_7mo_hudi
WHERE day = '2021-11-27' GROUP BY sender_nickyname
)
SELECT
sender_nickyname AS momo_name, momo_total
FROM tmp
ORDER BY momo_total DESC LIMIT 10;

- 指标3:统计各个用户, 接收消息量
WITH tmp AS (
SELECT
receiver_nickyname, COUNT(1) momo_total
FROM db_hudi.tbl_7mo_hudi
WHERE day = '2021-11-27' GROUP BY receiver_nickyname
)
SELECT
receiver_nickyname AS momo_name, momo_total
FROM tmp
ORDER BY momo_total DESC LIMIT 10;

- 指标4:统计男女发送信息量
SELECT
sender_sex, receiver_sex, COUNT(1) momo_total
FROM db_hudi.tbl_7mo_hudi
WHERE day = '2021-11-27' GROUP BY sender_sex, receiver_sex;

6.6 Spark 离线指标分析
编写SparkSQL程序,加载Hudi表数据封装到DataFrame中,按照业务指标需要,编写SQL分析数据,最终保存到MySQL数据库表中,流程示意图如下:

6.6.1 需求说明
对七陌社交消息数据的实时统计操作, 如下统计需求:
- 1)、统计消息的总条数
- 2)、根据IP地址统计各个地区(省) 发送的消息数和接收的消息数
- 3)、统计七陌社交消息中各个用户发送多少条和接收多少条
6.6.2 创建数据库表
将上述业务需求,最终结果存储到MySQL数据库1张表中:7mo.7mo_report。

其中字段:7mo_category 表示指标类型:
- 1:表示全国信息量统计
- 2:表示各省份发送信息量统计
- 3:表示各省份接收信息量统计
- 4:表示用户发送信息量统计
- 5:表示用户接收信息量统计
在MySQL数据库,创建数据库:7mo,表:7mo_reprot,对应DDL语句如下:
-- 创建数据库
CREATE DATABASE IF NOT EXISTS 7mo ;
-- 创建表
CREATE TABLE IF NOT EXISTS `7mo`.`7mo_report` (
`7mo_name` varchar(100) NOT NULL,
`7mo_total` bigint(20) NOT NULL,
`7mo_category` varchar(100) NOT NULL,
PRIMARY KEY (`7mo_name`, `7mo_category`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ;
6.6.3 编写指标分析程序
创建对象object:MomoSQLHudi,编写MAIN方法,按照编写流式程序5个步骤,写出代码结构,如下所示:
package cn.itcast.hudi.momo
import org.apache.spark.sql.{DataFrame, Dataset, Row, SaveMode, SparkSession}
import org.lionsoul.ip2region.{DataBlock, DbConfig, DbSearcher}
/**
* 编写SparkSQL程序,基于DSL和SQL分析Hudi表数据,最终保存值MySQL数据库表中
*/
object MomoSQLHudi {
def main(args: Array[String]): Unit = {
// step1、构建SparkSession实例对象
val spark: SparkSession = createSparkSession(this.getClass)
// step2、加载Hudi表数据,指定Hudi数据存储路径
val hudiDF: DataFrame = loadHudiTable(spark, "/hudi-warehouse/7mo_msg_hudi")
//println(s"Count = ${hudiDF.count()}")
//hudiDF.printSchema()
//hudiDF.show(numRows = 10, truncate = false)
// step3、数据ETL转换:提取字段,解析IP为省份和城市
val etlDF: DataFrame = etl(hudiDF)
//println(s"Count = ${etlDF.count()}")
//etlDF.printSchema()
//etlDF.show(numRows = 100, truncate = false)
// step4、业务指标分析
process(etlDF)
// 应用结束,关闭资源
spark.stop()
}
}
其中创建SparkSession对象,封装方法:createSparkSession,前面实时存储中一样。
6.6.3.1 加载Hudi表数据
使用Spark DataSource外部数据源接口方式,加载Hudi表数据,指定数据存储路径,封装方法:loadHudiTable。
/**
* 指定Hudi表数据存储path,加载Hudi表数据,返回DataFrame
*/
def loadHudiTable(spark: SparkSession, tablePath: String): DataFrame = {
val dataframe = spark.read
.format("hudi")
.load(tablePath)
// 返回数据
dataframe
}
6.6.3.2 解析IP地址及选择字段
解析IP地址为【省份】,推荐使用【ip2region】第三方工具库,官网网址:https://gitee.com/lionsoul/ip2region/,引入使用IP2Region第三方库:
-
第一步、复制IP数据集【ip2region.db】到工程下的【dataset】目录

-
第二步、在Maven中添加依赖
<dependency>
<groupId>org.lionsoulgroupId>
<artifactId>ip2regionartifactId>
<version>1.7.2version>
dependency>
- 第三步、ip2region的使用

采用自定义UDF函数方式,传递IP地址数据,解析返回Province省份:

除了解析IP地址为省份,还需要将业务需求中涉及到字段选择,封装方法:etl,代码如下:
/**
* 提取字段数据和转换经纬度为省份城市
*/
def etl(dataframe: DataFrame): DataFrame = {
val session: SparkSession = dataframe.sparkSession
// 1-自定义UDF函数,解析IP地址为省份和城市
session.udf.register(
"ip_to_province",
(ip: String) => {
// 构建DbSearch对象
val dbSearcher = new DbSearcher(new DbConfig(), "dataset/ip2region.db")
// 依据IP地址解析
val dataBlock: DataBlock = dbSearcher.btreeSearch(ip)
// 中国|0|海南省|海口市|教育网
val region: String = dataBlock.getRegion
// 分割字符串,获取省份和城市
val Array(_, _, province, _, _) = region.split("\\|")
// 返回Region对象
province
}
)
// 2-提取字段和解析IP
dataframe.createOrReplaceTempView("view_tmp_momo")
val etlDF: DataFrame = session.sql(
"""
|SELECT
| day, sender_nickyname, receiver_nickyname,
| ip_to_province(sender_ip) AS sender_province,
| ip_to_province(receiver_ip) AS receiver_province
|FROM
| view_tmp_momo
|""".stripMargin
)
// 返回结果数据
etlDF
}
6.6.3.3 业务指标分析
注册DataFrame为临时视图,编写SQL语句进行分析,最终将所有指标结果合并,进行保存。
/**
* 按照业务指标分析数据
*/
def process(dataframe: DataFrame): Unit = {
val session: SparkSession = dataframe.sparkSession
// 1-将DataFrame注册为临时视图
dataframe.createOrReplaceTempView("view_tmp_etl")
// 2-指标1:统计总消息量
val reportAllTotalDF: DataFrame = session.sql(
"""
|WITH tmp AS (
| SELECT COUNT(1) AS 7mo_total FROM view_tmp_etl
|)
|SELECT "全国" AS 7mo_name, 7mo_total, "1" AS 7mo_category FROM tmp;
|""".stripMargin
)
// 2-指标2:统计各省份发送消息量
val reportSenderProvinceTotalDF: DataFrame = session.sql(
"""
|WITH tmp AS (
| SELECT sender_province, COUNT(1) AS 7mo_total FROM view_tmp_etl GROUP BY sender_province
|)
|SELECT sender_province AS 7mo_name, 7mo_total, "2" AS 7mo_category FROM tmp;
|""".stripMargin
)
// 2-指标3:统计各省份接收消息量
val reportReceiverProvinceTotalDF: DataFrame = session.sql(
"""
|WITH tmp AS (
| SELECT receiver_province, COUNT(1) AS 7mo_total FROM view_tmp_etl GROUP BY receiver_province
|)
|SELECT receiver_province AS 7mo_name, 7mo_total, "3" AS 7mo_category FROM tmp;
|""".stripMargin
)
// 2-指标4:统计各个用户, 发送消息量
val reportSenderNickyNameTotalDF: DataFrame = session.sql(
"""
|WITH tmp AS (
| SELECT sender_nickyname, COUNT(1) AS 7mo_total FROM view_tmp_etl GROUP BY sender_nickyname
|)
|SELECT sender_nickyname AS 7mo_name, 7mo_total, "4" AS 7mo_category FROM tmp;
|""".stripMargin
)
// 2-指标5:统计各个用户, 接收消息量
val reportReceiverNickyNameTotalDF: DataFrame = session.sql(
"""
|WITH tmp AS (
| SELECT receiver_nickyname, COUNT(1) AS 7mo_total FROM view_tmp_etl GROUP BY receiver_nickyname
|)
|SELECT receiver_nickyname AS 7mo_name, 7mo_total, "5" AS 7mo_category FROM tmp;
|""".stripMargin
)
// 3-保存报表至MySQL数据库
val reportTotalDF: Dataset[Row] = reportAllTotalDF
.union(reportSenderProvinceTotalDF)
.union(reportReceiverProvinceTotalDF)
.union(reportSenderNickyNameTotalDF)
.union(reportReceiverNickyNameTotalDF)
// reportTotalDF.show(500, truncate = false)
reportTotalDF
.coalesce(1)
.write
.mode(SaveMode.Append)
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url",
"jdbc:mysql://node1.itcast.cn:3306/?useUnicode=true&characterEncoding=utf-8&useSSL=false")
.option("dbtable", "7mo.7mo_report")
.option("user", "root")
.option("password", "123456")
.save()
}
其中,直接使用SparkSQL中外部数据源JDBC方式,将结果保存到MySQL数据库表中。
6.6.4 报表程序运行
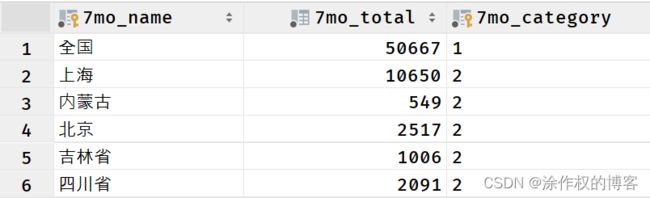
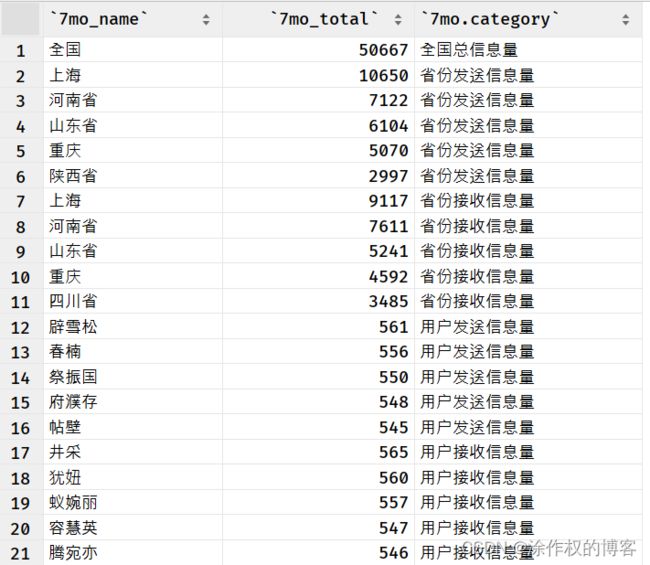
执行开发完成,Spark程序,加载Hudi表数据,按照业务指标计算,结果存储MySQL数据库。
-
查看MySQL数据库表数据

-
查询各个指标前5条数据
(SELECT 7mo_name, 7mo_total, "全国总信息量" AS "7mo.category"
FROM 7mo.7mo_report WHERE 7mo_category = 1)
UNION
(SELECT 7mo_name, 7mo_total, "省份发送信息量" AS "7mo.category"
FROM 7mo.7mo_report WHERE 7mo_category = 2 ORDER BY 7mo_total DESC LIMIT 5)
UNION
(SELECT 7mo_name, 7mo_total, "省份接收信息量" AS "7mo.category"
FROM 7mo.7mo_report WHERE 7mo_category = 3 ORDER BY 7mo_total DESC LIMIT 5)
UNION
(SELECT 7mo_name, 7mo_total, "用户发送信息量" AS "7mo.category"
FROM 7mo.7mo_report WHERE 7mo_category = 4 ORDER BY 7mo_total DESC LIMIT 5)
UNION
(SELECT 7mo_name, 7mo_total, "用户接收信息量" AS "7mo.category"
FROM 7mo.7mo_report WHERE 7mo_category = 5 ORDER BY 7mo_total DESC LIMIT 5);
6.7 FineBI 报表可视化
使用FineBI,连接数据MySQL数据库,加载业务指标报表数据,以不同图表展示。

6.7.1 安装FineBI
FineBI 是帆软软件有限公司推出的一款商业智能(Business Intelligence)产品。FineBI 是定位于自助大数据分析的 BI 工具,能够帮助企业的业务人员和数据分析师,开展以问题导向的探索式分析。官网:https://www.finebi.com/
FineBI的安装:参考《FineBI Windows版安装手册》,安装完成以后,启动登录,认识基本页面。
-
启动登录

-
目录:首页大屏及帮助文档

 - 仪表盘:用于构建所有可视化报表
- 仪表盘:用于构建所有可视化报表
-
数据准备:用于配置各种报表的数据来源
 - 管理系统:用于管理整个FineBI的使用:用户管理、数据源管理、插件管理、权限管理等
- 管理系统:用于管理整个FineBI的使用:用户管理、数据源管理、插件管理、权限管理等

6.7.2 配置数据源
创建MySQL数据库连接:【管理系统】 -> 【数据连接】 -> 【数据连接管理】
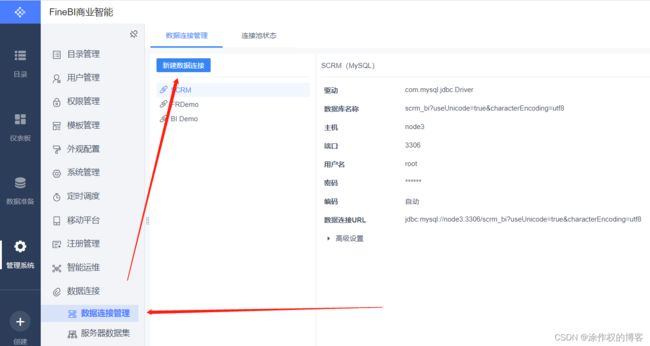

填写MySQL数据库连接信息:
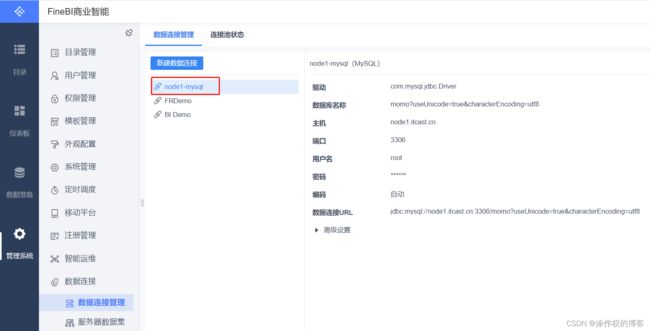
数据连接名称:node1-mysql
用户名:root
密码:123456
数据连接URL:jdbc:mysql://node1.itcast.cn:3306/7mo?useUnicode=true&characterEncoding=utf8

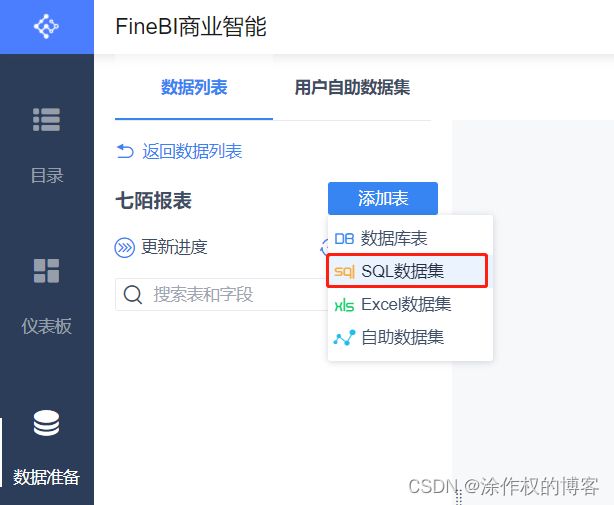
6.7.3 添加数据集
添加MySQL数据库中业务报表:7mo_report,选择【数据准备,添加分组【七陌数据】和业务包【七陌报表】。

点进【七陌报表】,添加表,采用【SQL数据集】方式:
输入表名称和SQL语句
SELECT
7mo_name, 7mo_total,
CASE 7mo_category
WHEN '1' THEN '总消息量'
WHEN '2' THEN '各省份发送量'
WHEN '3' THEN '各省份接收量'
WHEN '4' THEN '各用户发送量'
WHEN '5' THEN '各用户接收量'
END AS 7mo_category
FROM 7mo.7mo_report

6.7.4 创建仪表盘
先建仪表盘,名称为:【七陌社交数据统计报表】,如下图所示:

接下来,为仪表盘选择模板样式【预设样式5】:深蓝色海洋背景。

- 首先添加标题:【其他】 -> 【文本组件】

输入仪表盘名称:七陌社交数据统计报表
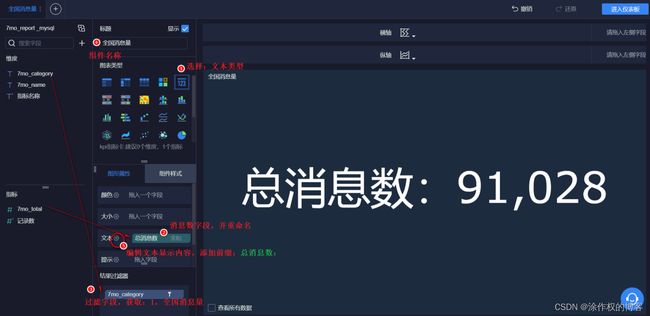
 - 其次,添加文本组件,显示总的消息数目
- 其次,添加文本组件,显示总的消息数目
选择前面添加表:7mo_report_mysql

按照下图所示:选择字段值和过滤字段类别
6.7.5 柱形图:Top10用户发送信息量
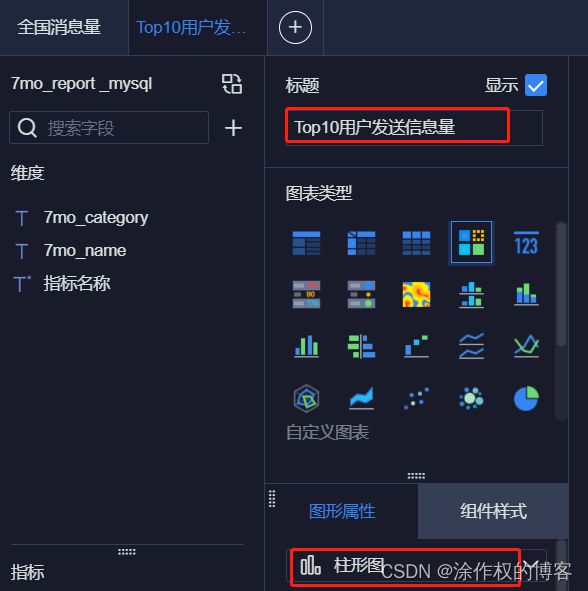
以柱形图方式,展示出发送信息量最多的Top10用户。
- 第1步、添加组件,选择【柱形图】,填写标题名称。
- 第2步、选择不同字段,设置相关过滤和显示

其中,展示的数据为:用户发送信息量统计数据。
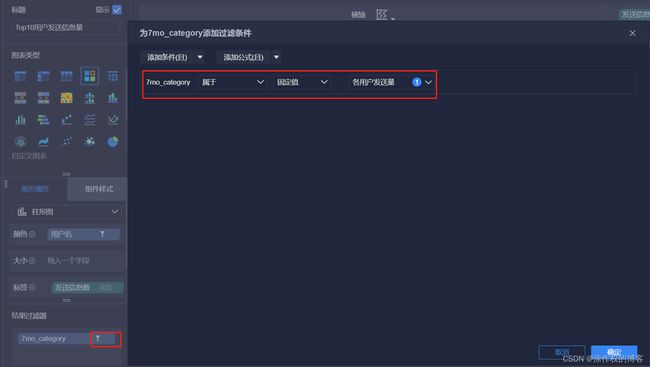
此外,仅仅展示Top10 发送信息量最大,需要过滤操作

展示柱形图时,按照发送信息量进行降序排序

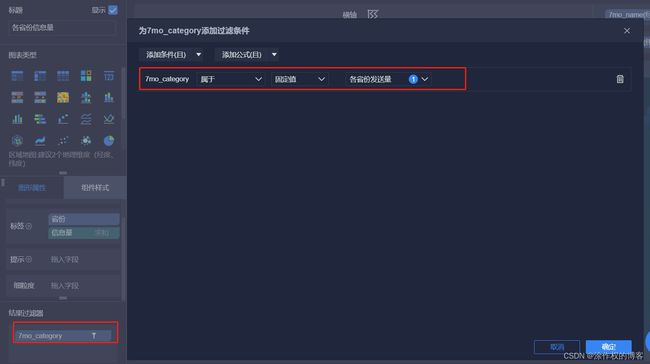
6.7.6 饼图:Top10省份发送信息量
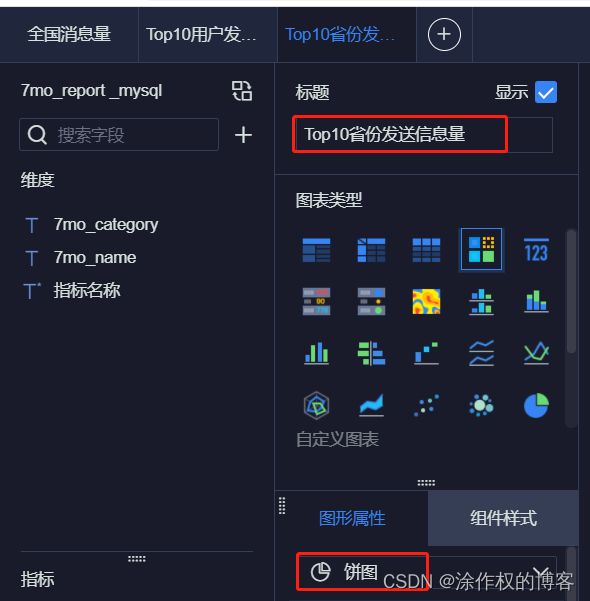
以饼图方式,展示Top10省份发送信息量,具体操作如下所示:
-
第1步、添加组件,选择【饼图】,填写标题名称。
-
第2步、选择不同字段,设置相关过滤和显示
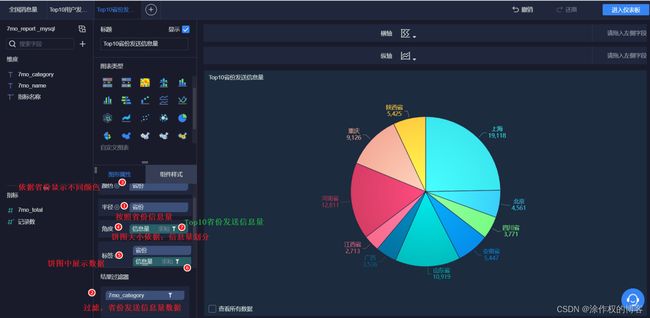
其中,过滤获取各个省份发送信息量统计数据

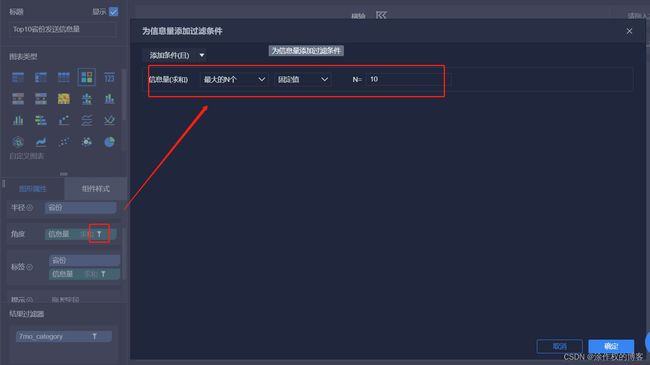
此外,仅仅获取Top10省份,发送信息量最多:
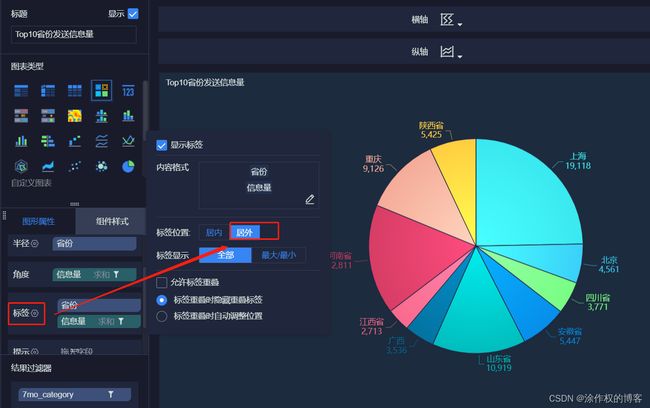
上述饼图中,在外边框显示数据,设置如下所示:
6.7.7 地图:各省份信息量
以地图方式,展示各省份发送信息量,具体操作如下所示:
- 第1步、添加组件,选择【区域地图】,填写标题名称。

- 第2步、选择省份字段映射到地理角色
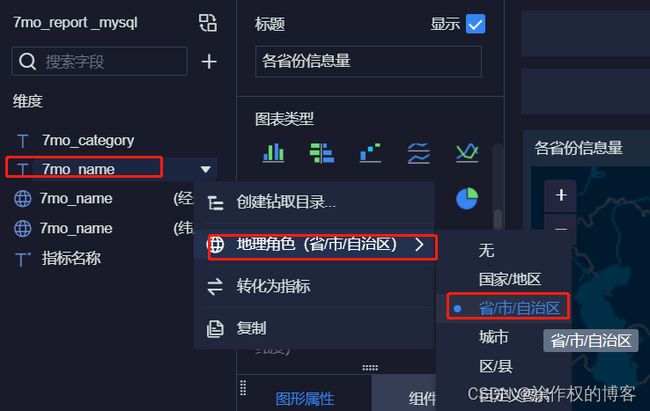
- 第3步、选择不同字段,设置相关过滤和显示

其中,过滤获取各个省份发送信息量统计数据