springboot mongo 使用
nosql对我来说,就是用它的变动列,如果列是固定的,我为什么不用mysql这种关系型数据库呢?
所以,现在网上搜出来的大部分,用实体类去接的做法,并不适合我的需求。
所以,整理记录一下,我收集到的springboot,自由,使用mongo的信息。
目录
前置
依赖引入
配置
代码引入
使用
插入
单行插入
批量插入
查询
查询全部(无条件)
条件查询
排序
DBObject更加自由的查询
聚合
某些列有值,并且只返回选中的列,并且聚合
其他工具包,像客户端一样写查询
mongodb的java驱动MongoClient
前置
依赖引入
org.springframework.boot
spring-boot-starter-data-mongodb
版本就根据自己的spring版本来好了,不需要额外加
配置
spring.data.mongodb.uri=mongodb://localhost:27017/myTest我用的本地版本的mongo,没配用户名+密码,如果配了,就需要加下。
本地mongodb的安装,我使用了菜鸟 MongoDB 安装介绍,并安装了mongoDB compass客户端,用来直连查看mongodb里的数据库数据
代码引入
@Resource private MongoTemplate template;上述配置完成后,直接依赖注入,就可以使用了
使用
插入
单行插入
template.insert(singleObject, "multi_1242");上述代码中
singleObject 为 json字符串 {"_id": 3, "1": "1.1", "2": "2.1", "amount": 2.1}"multi_1242" 为集合名称,我的需求是,不同的集合,里面document的键名,是会完全不同的
批量插入
boolean product = template.collectionExists("multi_1242");
if (!product) {
template.createCollection("multi_1242");
}
Gson gson = new Gson();
JsonObject jsonObject = new JsonObject();
jsonObject.addProperty("_id", 1);
jsonObject.addProperty("1", "1.1");
jsonObject.addProperty("2", "2.2");
jsonObject.addProperty("amount", 10.12);
// template.save(gson.toJson(jsonObject), "multi_1242");
JsonObject jsonObject1 = new JsonObject();
jsonObject1.addProperty("_id", 2);
jsonObject1.addProperty("1", "1.2");
jsonObject.addProperty("2", "2.2");
jsonObject1.addProperty("3", "3.1");
jsonObject1.addProperty("amount", 1.13);
// template.save(gson.toJson(jsonObject1), "multi_1242");
List list = new ArrayList<>();
list.add(gson.toJson(jsonObject));
list.add(gson.toJson(jsonObject1));
template.insert(list, "multi_1242"); 这里我使用了google的Json化的工具包,我没有使用ali的fastjson,是因为它的JSON对象转JSON字符串曾经坑过我(它会把一些特殊字符,转换成别的字符)
com.google.code.gson
gson
2.10.1
import com.google.gson.Gson;
import com.google.gson.JsonObject;上述动作完成插入后,mongo那边显示的结果为

从上述的实验,可以得出几个结论
1、springboot插入mongo的话,也是用json字符串去插入的,我曾经试过,直接用jsonObject类型去插入,document查出来,会有很多不需要的字段都被插进去了(这并不是我想要的),所以你想插入什么样子,就组装成什么样子后,json字符串后,再传入进去。下图为错误示范。
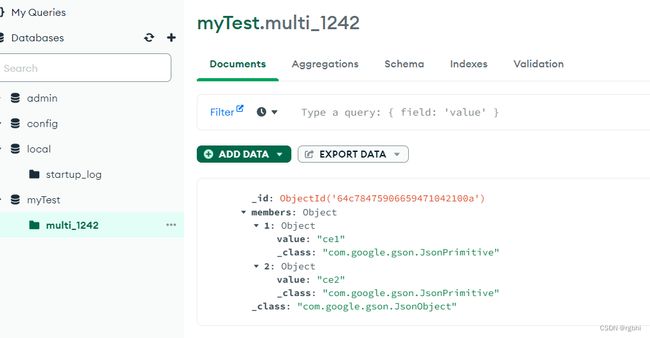
2、_id这个键,是默认的主键名称,如果你想控制主键多少,可以设置后,再进行插入
查询
查询全部(无条件)
Query query = new Query();
List list = template.find(query, String.class, "multi_1242");
//查看测试结果
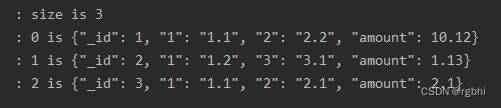
LoggerUtils.info("size is " + list.size());
for (int i = 0; i < list.size(); i++) {
//使用了封装类,打印了一下查出来的结果
LoggerUtils.info(i + " is " + list.get(i));
} 不需要传入查询条件,传个空的query进去就行了
下图为输出结果
条件查询
2个and的查询条件
Query query = new Query();
Criteria criteria = new Criteria();
criteria.where("1").is("1.1");
criteria.and("2").is("2.1");
query.addCriteria(criteria);
List list = template.find(query, String.class, "multi_1242"); 查询结果

如果有的document缺少查询条件里的一些键呢,结果是如何呢? 然后我增加了一个查询条件
Query query = new Query();
Criteria criteria = new Criteria();
criteria.where("1").is("1.1");
criteria.and("2").is("2.1");
//增加一条查询条件
criteria.and("3").is("3.1");
query.addCriteria(criteria);
List list = template.find(query, String.class, "multi_1242"); ![]()
结果是没有查出来,如果写在where里,明确某个键=某个值的话,那么查出来的document,必然是有该键的。
但是order却不一定,为此,我多插了一行{"_id": 4, "1": "1.1", "2": "2.1","3": "3.1", "amount": 2.1}
排序
Query query = new Query();
Criteria criteria = new Criteria();
criteria.where("1").is("1.1");
criteria.and("2").is("2.1");
query.addCriteria(criteria);
//增加一条排序条件
query.with(Sort.by("3"));
List list = template.find(query, String.class, "multi_1242"); 结果

可以看到order依赖的属性不存在,也是可以被查出来的,并且正常排序还排在前面
DBObject更加自由的查询
上述用这个Query类构造还是束手束脚的,不过我又查到了,跟客户端类似的方法
DBObject obj = new BasicDBObject();
obj.put("1", "1.1");
obj.put("2", "2.1");
Query query = new BasicQuery(obj.toString());
List list = template.find(query, String.class, "multi_1242"); 仿照着写,查询结果是ok的

如果是复杂的查询,可以自己用DBObject,BasicDBList构造嵌套起来
聚合
某些列有值,并且只返回选中的列,并且聚合
如果是客户端的话,可以先过滤出来后,再进行聚合
例如,我想找到“1”列,“2”列有值,并且根据这两列进行合并的,并且返回的结果只包含这2列作为_id,意味着,如果有(1.1,2.1,3.1)和(1.1,2.1)的组合,将会合并到一起
db.multi_1242.aggregate([
#先过滤一波需要的数据
{$match:
{
"1":{$exists:true},
"2":{$exists:true}
}
},
#然后进行合并,_id使用要合并的字段组成
# mytotal这个键是我随便起的,就是group后面跟的对象,就是将会输出的数据格式
{$group:
{
_id:{"1":"$1","2":"$2"},
mytotal:{$sum:"$amount"}
}
}
])原始数据如图

查询后的结果如下
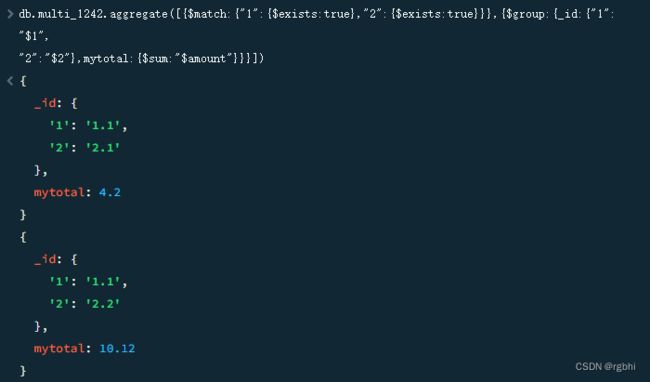
可以看到我的_id设置的只有“1”列和“2”列,所以合并也是根据我的要求来合的。
如果我的_id加入了“3”列,那么,有的document行有3这个键值,有的没有,又该如何?
查询如下:
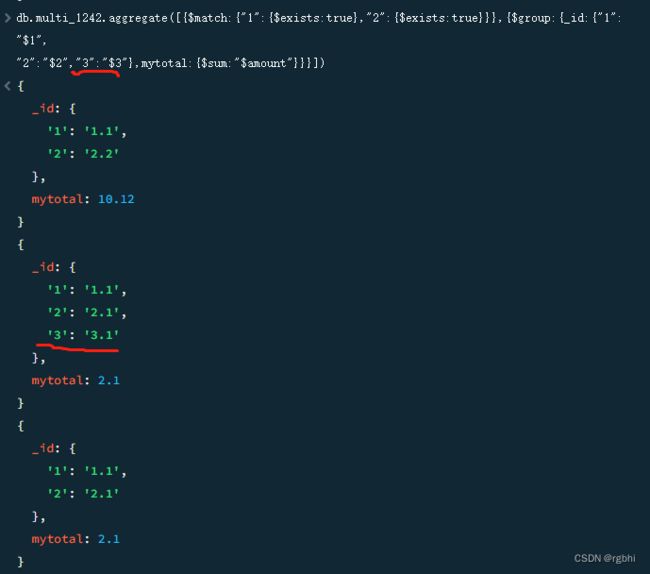
可以发现,有“3” 列的就有,没有“3”列的,就没有。
客户端是这样,那么如何在项目中使用聚合来查询?
Aggregation aggregation =
Aggregation.newAggregation(
Aggregation.match(new Criteria().where("1").is(obj1).and("2").is(obj1)),
Aggregation.group("1", "2").sum("amount").as("mytotal"));
AggregationResults results = template.aggregate(aggregation, "multi_1242", String.class);
List mappedResults = results.getMappedResults(); 打印得到的结果

这个group查多组合,需要传 Fields
import org.springframework.data.mongodb.core.aggregation.Fields;
DBObject obj1 = new BasicDBObject();
obj1.put("$exists", true);
Fields fields = Fields.fields("1");
fields = fields.and("2");
fields = fields.and("3");
Aggregation aggregation =
Aggregation.newAggregation(
Aggregation.match(new Criteria().where("1").is(obj1).and("2").is(obj1)),
Aggregation.group(fields).sum("amount").as("mytotal"));
AggregationResults results = template.aggregate(aggregation, "multi_1242", String.class);
List mappedResults = results.getMappedResults(); 查询结果

这个Fields还真是难造,看了下源码,才知道怎么造出来。
然后,如果不想调用各种聚合函数,比如sum,count也是可以的。
比如我把上面的聚合查询,改为这样。
Aggregation aggregation =
Aggregation.newAggregation(
Aggregation.match(new Criteria().where("1").is(obj1).and("2").is(obj1)),
Aggregation.group(fields));结果如下

只会查出聚合的键,这也是我需要的内容
其他工具包,像客户端一样写查询
mongodb的java驱动MongoClient
mongoClient的参考文章
其中的这种写法,我是比较赞赏的,因为都是字符串拼接,很自由,引用一下。
Document match = Document.parse("{$match:{$or:[{\"组织机构代码\":\"" + id + "\"}, {\"单位名称\":\"" + id + "\"}]}}");
Document unwind = Document.parse("{$unwind:\"$公司人员\"}");
Document group = Document.parse("{$group : {_id : \"$公司人员." + arrayFiled + "\", count : {$sum : 1}}}");
List conditions = new ArrayList<>();
conditions.add(match);
conditions.add(unwind);
conditions.add(group);
List result = new ArrayList<>();
AggregateIterable resultSet = this.collection.aggregate(conditions);
try (MongoCursor cursor = resultSet.iterator()) {
while (cursor.hasNext()) {
Document item_doc = cursor.next();
result.add(item_doc);
}
} Bson的话,两种工具包好像都可以进行使用,我这边就不赘述了。