故障树手册(Fault Tree handbook)(4)
第六章 概率理论:关于事件的数学描述
6.1 概述
通过学习前边的内容我们已经奠定了故障树的基础,我么几乎已经可以开始进入一些真实的故障树案例教学。但是,因为我们在第八章和第九章的例子中不仅有故障树的构建,还有故障树的评估,所以我们必须在第六章和第七章先把评估涉及的数学概念讲清楚。
第六章讲解了定量评估故障树所涉及的基础的数学知识:概率理论。概率论是故障树分析的基础,因为它提供了对事件的分析处理,而事件是故障树的基本组成部分。我们将讨论的概率论的主题包括结果集合和相对频率的概念、概率论的代数、组合分析和一些集合论。我们从结果集合的概念开始,它可以方便地用随机实验及其结果来描述。
6.2 随机试验和随机试验结果
随机试验被定义为可能获得的结果是不确定的观测活动。如果一个观测总是出现相同的结果,那么这个结果就是确定性的。如果结果是许多可能性中的一种,那么这个结果就是非确定的。因此,如果我们抛一个硬币来猜是“人头”还是“国徽”,我们就在进行一个抛硬币的随机试验。如果我们的硬币“有猫腻”,我们知道它两面都是“国徽”,我们就不是在进行随机试验,因为结果肯定是“国徽”。类似的,掷骰子是一个随机的实验,除非骰子在每次试验中都给出完全相同的结果。“随机试验”这个术语十分常见,读者可以举出大量的例子。测量某个弹簧的刚度、电机的故障时间、测量陨石中的铁含量等。很明显,我们周边许多观测都是随机试验。
随机试验的特点是把所有可能的结果一一列出。当结果不是很多时,列出所有结果相对容易,但是如果结果的数量非常大,清单或许将是大到无法实现。随机实验结果的项目化在数学上被称为结果空间,但我们认为“结果集合”这个术语更具有描述性。符号 E 1 , E 2 , . . . E n {E_1,E_2,...E_n} E1,E2,...En将被用于表示事件 E 1 , E , 2 , . . . E n E_1,E,2,...En E1,E,2,...En的结果集合。结果空间的概念将用几个例子进行说明。
| 名称 | 内容 |
|---|---|
| 随机试验 | 一次抛硬币 |
| 目标 | 判定是正面还是反面 |
| 结果集合 | { T , H } \{T,H\} {T,H} |
注意,如果当前存在有硬币掉进附近的缝隙中找不到的情况,则应该把这种情况加入到结果集合中。
| 名称 | 内容 |
|---|---|
| 随机试验 | 把硬币抛向一个有标尺的平面 |
| 目标 | 判定硬币不动后的坐标 |
| 结果集合 | { { x 1 , y 1 } , { x 2 , y 2 } , . . . } \{\{x_1,y_1\},\{x_2,y_2\},...\} {{x1,y1},{x2,y2},...}, { x , y } \{x,y\} {x,y}是硬币的笛卡尔坐标。 |
注意,这个结果集合有无穷多的元素。
| 名称 | 内容 |
|---|---|
| 随机试验 | 启动柴油机 |
| 目标 | 判定柴油机能否正常启动 |
| 结果集合 | { S , F } \{S,F\} {S,F} |
| 名称 | 内容 |
|---|---|
| 随机试验 | 掷色子 |
| 目标 | 色子静止后的数字是多少 |
| 结果集合 | { 1 , 2 , 3 , 4 , 5 , 6 } \{1,2,3,4,5,6\} {1,2,3,4,5,6} |
| 名称 | 内容 |
|---|---|
| 随机试验 | 一次关闭阀门的尝试 |
| 目标 | 判定阀门关闭©还是保持开启(O) |
| 结果集合 | { C , O } \{C,O\} {C,O} |
此外,如果我们考虑到部分故障模式,那么结果集合可能包含例如“阀门打开不到一半”,“阀门关闭后又自己打开了”之类的事件。
| 名称 | 内容 |
|---|---|
| 随机试验 | 系统运行规定长度的时间。系统中存在两个关键部件A和B,如果A和B之中任何一个有问题,系统就会发生故障。(因此A和B是单一故障) |
| 目标 | 判定在时间 t t t内系统会如何出问题 |
| 结果集合 | {系统没出问题,A故障导致系统故障,B故障导致系统故障,A和B都故障了导致系统故障} |
注意,我们在结果集合中没有包含故障发生的时间,因为我们只关心系统在规定的时间内有没有发生故障。
| 名称 | 内容 |
|---|---|
| 随机试验 | 两个并行系统的运行,如果两个系统分别被指定为A和B,我们定义 F i = F_i= Fi= 系统i故障的事件, O i = O_i= Oi= 系统i没有失效的事件 ( i = A , B ) (i=A,B) (i=A,B)。 |
| 目标 | 判定在规定的时间区间系统是否失效 |
| 结果集合 | { ( F A , O B ) , ( O A , F B ) ( O A , O B ) ( F A , F B ) } \{(F_A,O_B),(O_A,F_B)(O_A,O_B)(F_A,F_B)\} {(FA,OB),(OA,FB)(OA,OB)(FA,FB)} |
在本例中,系统总体故障只存在事件 ( F A , F B ) (F_A,F_B) (FA,FB)。
6.3 概率的相对频率定义
假设一些随机试验,其结果集合是 E 1 , E 2 , E 3 . . . E n E_1,E_2,E_3...E_n E1,E2,E3...En。假设我们重复N次试验,观察结果 E 1 E_1 E1出现的次数。在重复N次后, E 1 E_1 E1出现了 N 1 N_1 N1次,我们就可以设定该结果出现的几率为
N 1 N \frac{N_1}{N} NN1
这个结果表示在进行该项随机试验N次,结果 E 1 E_1 E1出现的频率。现在我们进一步探索这个问题:如果试验重复的次数N变成无穷大( N → ∞ N\to \infty N→∞),那么这个几率是否会趋近于一个极限值?如果这个极限值存在,我们将这个极限值叫做事件 E 1 E_1 E1相关的概率,用符号 P ( E 1 ) P(E_1) P(E1)表示。因此
P ( E 1 ) = lim N → ∞ ( N 1 N ) (VI-1) P(E_1)=\lim_{N \to \infty}(\frac{N_1}{N}) \tag{VI-1} P(E1)=N→∞lim(NN1)(VI-1)
从这个定义中我们可以轻松得到如下的性质:
- 0 < P ( E 1 ) < 1 0
- 如果 P ( E 1 ) = 1 P(E_1)=1 P(E1)=1, E 1 E_1 E1一定会发生。
- 如果 P ( E 1 ) = 0 P(E_1)=0 P(E1)=0,则 E 1 E_1 E1一定不会发生。
概率更正式的定义涉及到集合的原理,在这里不多做叙述,公式VI-1作为实用中使用的定义已经足够了。
6.4 概率的数学运算
我们从一个随机试验中选择A与B两个可能出现的结果,假设A与B是互斥的。这就意味着在试验的一次操作中A和B不会同时发生。举个例子,我们抛硬币只能得到“正面”或“反面”两个结果中的一个。我们不可能在一次抛硬币中同时获得正面和反面。如果A和B是互斥的,我们可以列出A与B概率间的数学表达:
P ( A o r B ) = P ( A ) + P ( B ) (VI-2) P(A\ or \ B)=P(A)+P(B) \tag{VI-2} P(A or B)=P(A)+P(B)(VI-2)
这种关系有时被称为“概率的加法规则”,适用于互斥的事件。这个公式可以很容易的扩展到任意数量的互斥事件A,B,C,D,E,……
P ( A o r B o r C o r D o r E ) = P ( A ) + P ( B ) + P ( C ) + P ( D ) + P ( E ) (VI-3) P(A\ or\ B \ or \ C \ or\ D\ or \ E)=P(A)+P(B)+P(C)+P(D)+P(E) \tag{VI-3} P(A or B or C or D or E)=P(A)+P(B)+P(C)+P(D)+P(E)(VI-3)
而对于那些不是完全互斥的事件,我们就需要一个更加通用的公式。例如,假设一个掷色子的随机试验,我们定义如下两个事件:
- A——“数字是2”
- B——“数字是偶数”
很明显这两个事件不是完全互斥的,因为如果结果是2,那么A和B都符合。则现在 P ( A o r B ) P(A\ or\ B) P(A or B)的通用表达为
P ( A o r B ) = P ( A ) + P ( B ) − P ( A a n d B ) (VI-4) P(A\ or \ B)=P(A)+P(B)-P(A \ and \ B) \tag{VI-4} P(A or B)=P(A)+P(B)−P(A and B)(VI-4)
如果A和B是完全互斥的,那么 P ( A a n d B ) = 0 P(A \ and \ B)=0 P(A and B)=0,公式VI-4就变成了公式VI-2, 读者还应该注意到当事件并不互斥的情况下,公式VI-2总是对真实概率VI-4的一个上边界。现在让我们回到刚才的抛色子问题,我们通过数学方法计算 P ( A o r B ) P(A\ or\ B) P(A or B):
P ( A o r B ) = 1 / 6 + 1 / 2 − 1 / 6 = 1 / 2 P(A \ or \ B)=1/6+1/2-1/6=1/2 P(A or B)=1/6+1/2−1/6=1/2
公式IV-4能被扩展到任意数量的事件。举个例子,对于A,B,C三个事件:
P ( A o r B o r C ) = P ( A ) + P ( B ) + P ( C ) − P ( A a n d B ) − P ( A a n d C ) − P ( B a n d C ) + P ( A a n d B a n d C ) (VI-5) P(A \ or \ B \ or \ C)=P(A)+P(B)+P(C)-P(A \ and \ B) - P(A \ and \ C) - P(B \ and \ C)+P(A \ and \ B \ and \ C) \tag{VI-5} P(A or B or C)=P(A)+P(B)+P(C)−P(A and B)−P(A and C)−P(B and C)+P(A and B and C)(VI-5)
对于n个事件 E 1 , E 2 , . . . . , E n E_1,E_2,....,E_n E1,E2,....,En,通用的公式可以表示为:
P ( E 1 o r E 2 o r . . . E n ) = ∑ i = 1 n P ( E i ) − ∑ i = 1 n − 1 ∑ j = i + 1 n P ( E i a n d E j ) + ∑ i = 1 n − 2 ∑ j = i + 1 n − 1 ∑ k = j + 1 n P ( E i a n d E j a n d E k ) . . . + ( − 1 ) n P ( E 1 a n d E 2 a n d . . . a n d E n ) (VI-6) \begin{aligned} P(E_1 \ or \ E_2 \ or ...E_n)&= \sum_{i=1}^{n}P(E_i)-\sum_{i=1}^{n-1}\sum_{j=i+1}^{n}P(E_i \ and \ E_j) + \\ &\sum_{i=1}^{n-2}\sum_{j=i+1}^{n-1}\sum_{k=j+1}^{n}P(E_i \ and \ E_j \ and \ E_k)... + \\ &(-1)^n P(E_1 \ and \ E_2 and \ ...\ and \ E_n) \tag{VI-6}\end{aligned} P(E1 or E2 or...En)=i=1∑nP(Ei)−i=1∑n−1j=i+1∑nP(Ei and Ej)+i=1∑n−2j=i+1∑n−1k=j+1∑nP(Ei and Ej and Ek)...+(−1)nP(E1 and E2and ... and En)(VI-6)
(CSDN的公式渲染引擎是Katax,不支持split公式格式,怎么解决啊?)
如果我们忽略两个或以上事件 E i E_i Ei同时发生的可能性概率,公式VI-6可以化简成
P ( E 1 o r E 2 o r . . . E n ) = ∑ i = 1 n P ( E i ) (VI-7) P(E_1 \ or \ E_2 \ or \ ... \ E_n) = \sum_{i=1}^{n}P(E_i) \tag{VI-7} P(E1 or E2 or ... En)=i=1∑nP(Ei)(VI-7)
公式VI-7被称为“稀有事件近似法则(rare event approximation)”,当 P ( E i ) < 0.1 P(E_i)<0.1 P(Ei)<0.1时,它与真实概率之间的误差将小于10%。进一步说,任何误差都是保守的,因为真实概率会比公式VI-7的结果略低一些。稀有事件近似法则在故障树的量化中具有十分重要的作用,它将在第十一章中进一步论述。
现在有两个事件A和B,它们互相独立。这意味着实验中的几次重复期间,A的发生(不发生)对于随后B的发生没有任何影响,反之亦然。如果一个平衡性很好的钱币被随机抛起,第一次出现正面并不会对第二次出现反面的概率有任何影响,都是1/2。所以连续的抛硬币的结果是被看成是互相独立的。同样的,如果两个部件并行运行,它们互相间是隔离的,其中一个的故障并不会对另外一个造成影响。在这种情况下,部件的故障就是独立事件。如果A和B是互相独立的两个事件,我们可以写成
P ( A a n d B ) = P ( A ) P ( B ) (VI-8) P(A \ and \ B)=P(A)P(B) \tag{VI-8} P(A and B)=P(A)P(B)(VI-8)
这经常被称作“概率的乘法原理”,我们也可以轻易的得到多个事件的扩展。
P ( A a n d B a n d C a n d D ) = P ( A ) P ( B ) P ( C ) P ( D ) (VI-9) P(A \ and \ B \ and \ C \ and \ D)=P(A)P(B)P(C)P(D) \tag{VI-9} P(A and B and C and D)=P(A)P(B)P(C)P(D)(VI-9)
我们经常会遇到事件间并不是互相独立的,换句话说,它们是互相依赖的。举个例子,电路中过热的电阻会影响边上电感或其他电路的故障概率。星期二下雨的概率很大程度上受到星期一天气整体情况的影响。为了更好的探讨这一概念,我们将介绍条件概率的概念,我们引入条件概率的符号: P ( B ∣ A ) P(B|A) P(B∣A),它表示A事件已经发生的条件下,B事件发生的概率。A和B都发生的概率会变成如下形式
P ( A a n d B ) = P ( A ) P ( B ∣ A ) = P ( B ) P ( A ∣ B ) (VI-10) P(A \ and \ B)=P(A)P(B|A) = P(B)P(A|B) \tag{VI-10} P(A and B)=P(A)P(B∣A)=P(B)P(A∣B)(VI-10)
如果A和B是互相独立的,那么 P ( A ∣ B ) = P ( A ) a n d P ( B ∣ A ) = P ( B ) P(A|B)=P(A) \ and P(B|A) = P(B) P(A∣B)=P(A) andP(B∣A)=P(B),公式VI-10就简化成了公式VI-8。公式VI-10构成了事件A和B联合发生的概率通用表示形式。
对于A、B、C三个事件,我们有
P ( A a n d B a n d C ) = P ( A ) P ( B ∣ A ) P ( C ∣ A a n d B ) (VI-11) P(A \ and \ B \ and \ C) = P(A)P(B|A)P(C|A \ and \ B) \tag{VI-11} P(A and B and C)=P(A)P(B∣A)P(C∣A and B)(VI-11)
其中 P ( C ∣ A a n d B ) P(C|A \ and \ B) P(C∣A and B)是A和B已经发生时C发生的概率。对于n个事件 E 1 , E 2 , E 3 . . . E n E_1,E_2,E_3...E_n E1,E2,E3...En,
P ( E 1 a n d E 2 a n d E 3 . . . E n ) = P ( E 1 ) P ( E 2 ∣ E 1 ) P ( E 3 ∣ E 1 a n d E 2 ) . . . P ( E n ∣ E 1 a n d E 2 . . . a n d E n − 1 ) (VI-12) P(E_1 \ and \ E_2 \ and \ E_3 \ ...E_n) = P(E_1)P(E_2|E_1)P(E_3|E_1 \ and \ E_2) \\ ... P(E_n|E_1 \ and \ E_2 ... \ and E_{n-1}) \tag{VI-12} P(E1 and E2 and E3 ...En)=P(E1)P(E2∣E1)P(E3∣E1 and E2)...P(En∣E1 and E2... andEn−1)(VI-12)
我们举一个非常有用的例子,考虑如下的随机试验:我们从52张打乱规则的牌中选择一张。我们记下牌面(如7或者Q等等),并把它放在一边(我们并不把它放进牌堆里——这就是“不重复抽样”)。然后我们从余下的51张牌中再抽取一张并记录牌面。现在我们计算在这两次抽牌中,我们抽中A的概率是多少。这有三个互相独立的概率数据
- 第一张抽到A然后第二张不是A
- 第一张不是A然后第二张抽到A
- 第一张和第二张都抽到了A
我们用数学进行表达,这样看起来更加简洁:
P ( 两 次 抽 牌 至 少 有 一 张 A ) = P ( A ) = P ( A 1 a n d A ‾ 2 ) + P ( A ‾ 1 a n d A 2 ) + P ( A 1 a n d A 2 ) = P ( A 1 ) P ( A ‾ 2 ∣ A 1 ) + P ( A 1 ‾ ) P ( A 2 ∣ A 1 ‾ ) + P ( A 1 ) P ( A 2 ∣ A 1 ) \begin{aligned} P(两次抽牌至少有一张A) &= P(A) \\ &= P(A_1 \ and \ \overline{A}_2)+P(\overline{A}_1 \ and \ A_2)+P(A_1 and A_2) \\ &= P(A_1)P(\overline{A}_2|A_1)+P(\overline{A_1})P(A_2|\overline{A_1})+P(A_1)P(A_2|A_1) \end{aligned} P(两次抽牌至少有一张A)=P(A)=P(A1 and A2)+P(A1 and A2)+P(A1andA2)=P(A1)P(A2∣A1)+P(A1)P(A2∣A1)+P(A1)P(A2∣A1)
在这里字母的下标指的是第几次抽牌, A A A用于指代“抽到A”, A ‾ \overline{A} A用于指代“没有抽到A”。我们能求出这个表达式的值为
P ( A ) = ( 4 52 ) ( 48 51 ) + ( 48 52 ) ( 4 51 ) + ( 4 52 ) ( 3 51 ) = 396 52 × 51 = 33 221 = 0.149 \begin{aligned} P(A) = (\frac{4}{52})(\frac{48}{51})+(\frac{48}{52})(\frac{4}{51})+(\frac{4}{52})(\frac{3}{51})=\frac{396}{52\times 51}=\frac{33}{221}=0.149 \end{aligned} P(A)=(524)(5148)+(5248)(514)+(524)(513)=52×51396=22133=0.149
现在让我们计算得到一张A和一张K的概率:
$$ P ( A a n d K ) = P ( A 1 ) P ( K 2 ∣ A 1 ) + P ( K 1 ) P ( A 2 ∣ K 1 ) = ( 4 52 ) ( 4 51 ) + ( 4 52 ) ( 4 51 ) = 0.012 \begin{aligned} P(A \ and \ K) &=P(A_1)P(K_2|A_1)+P(K_1)P(A_2|K_1) \\ &=(\frac{4}{52})(\frac{4}{51})+(\frac{4}{52})(\frac{4}{51}) \\ &=0.012 \end{aligned} P(A and K)=P(A1)P(K2∣A1)+P(K1)P(A2∣K1)=(524)(514)+(524)(514)=0.012
我们现在指出一个很重要的观点。如果事件“抽到一张A”和事件“抽到一张K”是互相独立的,那么
P ( A a n d K ) = P ( A ) P ( K ) = ( 0.149 ) 2 = 0.022 P(A \ and\ K)=P(A)P(K)=(0.149)^2 = 0.022 P(A and K)=P(A)P(K)=(0.149)2=0.022
但是我们刚算出 P ( A a n d K ) = 0.012 ≠ 0.022 P(A \ and \ K)=0.012 \neq 0.022 P(A and K)=0.012=0.022。这是因为该问题涉及的两件事并不互相独立。在这一点上,读者应该能够提出一个论点,即如果抽到的第一张牌后放回排堆里,并且在第二次抽之前洗牌,那么所讨论的事件将是独立的。
故障树分析中的一个重要应用就是,计算在一个互相独立的事件集合中的一个及以上事件的发生概率。
假设一个互相独立的事件 E 1 , E 2 , E 3 , . . . E n {E_1,E_2,E_3,...E_n} E1,E2,E3,...En,我们定义 E 1 ‾ \overline{E_1} E1表示 E 1 E_1 E1的未发生事件,同样方法表示 E 2 E_2 E2到 E n E_n En。因为任何一个事件的结果都可能是发生或未发生。我们可以得到
P ( E i ‾ ) + P ( E i ) = 1 (VI-13) P(\overline{E_i})+P(E_i)=1 \tag{VI-13} P(Ei)+P(Ei)=1(VI-13)
P ( E i ‾ ) = 1 − P ( E i ) (VI-14) P(\overline{E_i}) = 1- P(E_i) \tag{VI-14} P(Ei)=1−P(Ei)(VI-14)
现在关于事件 E i E_i Ei我们可以得到两个概率,事件 E i E_i Ei至少发生一次,或这 E i E_i Ei一次也没发生。因此
P ( E i 至 少 发 生 一 次 ) = 1 − P ( E i 一 次 都 没 发 生 ) = 1 − P ( E 1 ‾ a n d E 2 ‾ a n d . . . E n ‾ ) P(E_i至少发生一次) =1-P(E_i一次都没发生) \\ =1-P(\overline{E_1} \ and \overline{E_2} \ and \ ... \ \overline{E_n}) P(Ei至少发生一次)=1−P(Ei一次都没发生)=1−P(E1 andE2 and ... En)
我们知道E是互相独立的,根据这一点,我们其实也能直观的得到 E ‾ \overline{E} E也是互相独立的。事实上,这一点也能轻易的证明。因此
P ( E 1 ‾ a n d E 2 ‾ a n d E 3 ‾ . . . E n ‾ ) = P ( E 1 ‾ ) P ( E 2 ‾ ) P ( E 3 ‾ ) . . . P ( E n ‾ ) (VI-15) P(\overline{E_1} \ and \ \overline{E_2} \ and \overline{E_3} ... \ \overline{E_n})=P(\overline{E_1})P(\overline{E_2})P(\overline{E_3})...P(\overline{E_n}) \tag{VI-15} P(E1 and E2 andE3... En)=P(E1)P(E2)P(E3)...P(En)(VI-15)
但是从公式VI-14可以得出,它等同于
[ 1 − P ( E 1 ) ] [ 1 − P ( E 2 ) ] . . . [ 1 − P ( E n ) ] (VI-16) [1-P(E_1)][1-P(E_2)]...[1-P(E_n)] \tag{VI-16} [1−P(E1)][1−P(E2)]...[1−P(En)](VI-16)
于是最终的结果是
P ( E 1 o r E 2 o r E 3 o r . . . E n ) = 1 − { [ 1 − P ( E 1 ) ] [ 1 − P ( E 2 ) ] [ 1 − P ( E 3 ) ] . . . [ 1 − P ( E n ) ] } (VI-17) \begin{aligned} &P(E_1 \ or \ E_2 \ or \ E_3 \ or ... \ E_n) \\ &= 1-\{[1-P(E_1)][1-P(E_2)][1-P(E_3)]...[1-P(E_n)]\} \tag{VI-17}\end{aligned} P(E1 or E2 or E3 or... En)=1−{[1−P(E1)][1−P(E2)][1−P(E3)]...[1−P(En)]}(VI-17)
在这个简答的例子里, E i E_i Ei发生的概率都等于 p p p,公式VI-17右边部分可以化简为 1 − ( 1 − p ) n 1-(1-p)^n 1−(1−p)n。
公式VI-17常用于故障树计算。例如,一个系统如果在事件 E 1 , E 2 , . . . E n E_1,E_2,...E_n E1,E2,...En发生时会故障,假设这些事件之间是互相独立的,系统的故障概率就能从公式VI-17得出。举例来说,事件 E 1 , E 2 . . . E n E_1,E_2...E_n E1,E2...En是系统关键部件的故障,任何一个关键部件故障都会导致系统故障。如果部件故障之间是互相独立的,公式VI-17就是适用的。在通常情况下,事件 E 1 , E 2 . . . E_1,E_2... E1,E2...表示系统故障(故障树的顶层事件)可能发生的模式。如果它们是独立的,这些模式被称为故障树的最小切割集(minimal cut sets of the fault tree),例如,没有最小切割集具有普通部件故障,然后公式VI-17适用。我们将在后续章节的适合之处继续讨论最小切割集。
在本节中,我们回归到了结果集合的概念,因为我们需要将它定义的更细致些。结果集合的元素具有一些重要的特点:
- 结果集合之间的元素都是互相独立的。
- 结果集合是总体上详尽的。这就意味着我们包含了实验中所有可以想象到的结果。
- 结果空间的元素可以是连续的,也可以是离散的;例如,某些系统的故障时间是连续事件,当一张牌被抽出时,52张可能的牌面就是离散事件。
6.5 组合分析
组合分析可以用于评估许多种类的不同事件组合在一起的概率,比如冗余系统的概率。作为一个简单的介绍,我们回顾下“组合”和“排列”的区别。假设一个集合有四个实体: { A , B , C , D } \{A,B,C,D\} {A,B,C,D}。我们从四个当中随机选出三个,例如我们选择了ABD三个元素。这三个元素可以排列为六种不同的方式:ABD,ADB,BAD,BDA,DAB,DBA。因此,根据单一的组合ABD,我们有六种排列方式。
简要来说,当我们谈论“排列”时,我们关注次序;当我们谈论“组合”时,我们并不关注次序。我们是否关注次序取决于问题的特性。对于一个指定的冗余系统故障,我们或许只需要特定数量的部件故障,而不需要关注它们发生的次序。举个例子,在一个“三取二逻辑系统”里,我们需要任何“三取二”部件的故障来推测系统故障。在这个例子里我们关注事件的组合。但是,当一个事件的特定序列确定会发生,我们通常会关注排列。例如,安全壳喷淋的失败必然意味着安全壳喷淋再循环的失败,因此这里我们关心的是顺序,即注射,然后再循环。
现在我们寻找一个可以计算排列或组合的数量的简单方法。假设我们需要从数量n中抽样数量为r的样本集合。这个过程可以通过两种方式进行:(a)在放回的条件下,(b)在不放回的条件下。如果样本被放回,我们就在记录完所需特征之后将元素放回总体中去。如果样本不放回,我们将在记录后将其放在总体之外的其他地方。读者应该还记得,在我们的例子中曾经简单地提到过这个概念,其中包括从一张桌子中抽出两张卡片。
如果我们选择将样本放回,那么每次抽样的时候样本总量有什么变化?我们在第一次时有n种选择,第二次有n种选择,数量一直到我们抽完r次都不变。因此,在样本放回的规则下,我们有 n r n^r nr种可能的抽样。注意,在样本放回的策略下,复制抽样中的物体是可行的。
如果我们抽样不放回,我们第一个物体有n种选择,第二个物体有n-1个选额,第三个物体有n-2种选择,第r个物体有(n-r+1)种选择。因此,在抽样不放回的策略下,从总量为n里进行数量r的不同抽样的数量是
( n ) ( n − 1 ) ( n − 2 ) . . . ( n − r + 1 ) ≡ ( n ) r (VI-18) (n)(n-1)(n-2)...(n-r+1)\equiv (n)_r \tag{VI-18} (n)(n−1)(n−2)...(n−r+1)≡(n)r(VI-18)
在公式VI-18中,用到一个特殊的标记 ( n ) r (n)_r (n)r(中国国内一般用 P n r P_n^r Pnr表示)。这个符号可以用更熟悉的方式写成:
( n ) r = ( n ) ( n − 1 ) ( n − 2 ) . . . ( n − r + 1 ) ( n − r ) ( n − r − 1 ) . . . 3 × 2 × 1 ( n − r ) ( n − r − 1 ) . . . 3 × 2 × 1 = n ! ( n − r ) ! (VI-19) \begin{aligned}(n)_r &= \frac{(n)(n-1)(n-2)...(n-r+1)(n-r)(n-r-1)...3\times 2\times 1}{(n-r)(n-r-1)...3\times 2\times 1}\\& = \frac{n!}{(n-r)!} \tag{VI-19}\end{aligned} (n)r=(n−r)(n−r−1)...3×2×1(n)(n−1)(n−2)...(n−r+1)(n−r)(n−r−1)...3×2×1=(n−r)!n!(VI-19)
这里用到的阶乘的定义。
公式VI-19构成了我们探索的一种基本关系。它能算出从n个物体中一次拿出r个的排列的数量。当 r = n r=n r=n,我们得到 ( n ) n = n ! 0 ! = n ! (n)_n=\frac{n!}{0!}=n! (n)n=0!n!=n!因为 0 ! ≡ 1 0!\equiv 1 0!≡1。因此在它们中重新排列n个物体的所有方式的总数是 n ! n! n!。
如果我们对组合而不是排列有兴趣,那么我们就不需要的“ r ! 种 方 式 r!种方式 r!种方式”,它表示抽样中的r个物体可以自己重新排列。因此从n个物体中一次选择r个的组合数量为
n ! ( n − r ) ! r ! ≡ ( n r ) (VI-20) \frac{n!}{(n-r)!r!} \equiv \begin{pmatrix} n \\ r \\ \end{pmatrix} \tag{VI-20} (n−r)!r!n!≡(nr)(VI-20)
这里 ( n r ) \begin{pmatrix} n\\r\\ \end{pmatrix} (nr)代表该量(中国常用 C n r C_n^r Cnr)。如果我们从集合 A , B , C , D {A,B,C,D} A,B,C,D中随机选择三个元素,我们有 4 ! 3 ! = 4 \frac{4!}{3!}=4 3!4!=4个可能的组合,它们是ABC,ABD,ACD和BCD。它们每一个都有6种排列,所以它们应该有24种排列,这和
n ! ( n − r ) ! = 24 \frac{n!}{(n-r)!}=24 (n−r)!n!=24
也是一致的。
假设有一个总体里有n个物体,其中里边分成三种,每种的数量分别是 p , q , r p,q,r p,q,r,且 ( p + q + r ) = n (p+q+r)=n (p+q+r)=n。例如,我们需要从三个供应商那里采购电阻,从供应商A那里采购了p个,供应商B那里采购了q个,供应商C那里采购了r个。因为品牌关系,我们能轻易的区分电阻是哪个供应商生产的,但是同一个供应商生产的电阻我们无法区分。因此,在 n ! n! n!种可能的排列中,有一些排列我们是无法区分它们的不同的。供应商A的电阻自身的重新排列是无法区分的,供应商B和供应商C也面临同样的情况。因此,不同排列的总数为
n ! p ! q ! r ! (VI-21) \frac{n!}{p!q!r!} \tag{VI-21} p!q!r!n!(VI-21)
总的来说,对于 n n n个物体的集合,其中有 k k k种完全一样的物品,数量分别是 n 1 n_1 n1, n 2 , n 3 , . . . n k n_2,n_3,...n_k n2,n3,...nk,且 ( n 1 + n 2 + n 3 + . . . + n k = n ) (n_1+n_2+n_3+...+n_k=n) (n1+n2+n3+...+nk=n),则可区分的排列的数量为
n ! n 1 ! n 2 ! n 3 ! . . . n k ! (VI-22) \frac{n!}{n_1!n_2!n_3!...n_k!} \tag{VI-22} n1!n2!n3!...nk!n!(VI-22)
我们用个例子来说明这个公式如何解决实际问题。我们来算一下在传统五张扑克中获得一个FULL HOUSE(对子和一个三张)的概率是多少。
拿到一手牌(该例子中的一手牌为五张扑克)的所有可能组合,是简单的“52选5”的问题。
( 52 5 ) = 52 ! 47 ! 5 ! = N P H \begin{pmatrix} 52 \\ 5 \\ \end{pmatrix} = \frac{52!}{47!5!}=N_{PH} (525)=47!5!52!=NPH
这里,PH是“poker hands”的缩写,表示一手牌。如果我们能找出一手牌的中FULL HOUSE的数量,那么 N F H N P H \frac{N_{FH}}{N_{PH}} NPHNFH的比率就是得到FULL HOUSE的概率。首先我们要确定 N F H N_{FH} NFH的数量。我们把它记作XXXYY,其中X和Y是13个牌面(2,3,4,5,…J,Q,K,A)中的两种。那么X和Y到底有多少种选择?很明显,我们若先选X有13种选择,那么之后Y就有12种选择,于是 13 × 12 13\times 12 13×12就表示X和Y的所有选择数量。现在对于XXX我们有四种花色可以选择,这个数量是 C 4 1 = 4 C_4^1=4 C41=4(原谅我选择这样的写法吧,用Latex写矩阵麻烦死了)。类似的,一个对子YY也是同样的方式 C 4 2 = 6 C_4^2=6 C42=6。最终结果 N F H = 13 × 12 × 4 × 6 N_FH=13\times12\times4\times6 NFH=13×12×4×6,则
P ( F u l l H o u s e ) = N F H N P H = 13 × 12 × 4 × 6 C 52 5 = 6 4168 ≈ 1 700 P(Full \ House)=\frac{N_{FH}}{N_{PH}}=\frac{13\times 12\times 4\times 6}{C_{52}^5}=\frac{6}{4168} \approx \frac{1}{700} P(Full House)=NPHNFH=C52513×12×4×6=41686≈7001
举个和可靠性分析更相关的例子,假设一个系统包含n个相似的部件,系统会在其中m个部件故障后失效。比如系统有三个传感器,其中两个或以上传感器故障,系统就发生故障(3选2逻辑)。系统故障的形式的数量为 C m n C_m^n Cmn,也就是n个物品中一次拿走m个的组合的数量。如果其中任何一个部件的失效概率都是 p p p,那么任何一个组合导致系统故障的概率是
p m ( 1 − p ) n − m p^m(1-p)^{n-m} pm(1−p)n−m
因此,从m个部件中引发系统故障的概率是
C m n × p m ( 1 − p ) n − m C_m^n\times p^m(1-p)^{n-m} Cmn×pm(1−p)n−m
除了m个部件失效外,系统失效还会发生在m+1个部件失效,或者更多部件失效,直到所有n个部件失效。k个部件导致系统失效的形式数量可以表示为 C n k C_n^k Cnk,其中 k = m + 1 , m + 2 , . . . , k k=m+1,m+2,...,k k=m+1,m+2,...,k。k个失效的组合的概率是
p k ( 1 − p ) n − k k = m + 1 , m + 2 , . . . n p^k(1-p)^{n-k} \ \ \ \ \ \ \ k=m+1,m+2,...n pk(1−p)n−k k=m+1,m+2,...n
因此,k个部件失效引发的系统失效的概率是
C n k × p k ( 1 − p ) n − k k = m + 1 , m + 2 , . . . n C_n^k \times p^k(1-p)^{n-k} \ \ \ \ \ \ \ k=m+1,m+2,...n Cnk×pk(1−p)n−k k=m+1,m+2,...n
为了获得总的系统失效概率,我们把m个部件失效概率,m+1个部件失效概率等都加起来,于是总的系统失效概率是
C n m P m ( 1 − p ) n − m + C n m + 1 p m + 1 ( 1 − p ) n − m − 1 + . . . + C n n P n ( 1 − p ) 0 C_n^mP^m(1-p)^{n-m}+C_n^{m+1}p^{m+1}(1-p)^{n-m-1}+...+C_n^nP^n(1-p)^0 CnmPm(1−p)n−m+Cnm+1pm+1(1−p)n−m−1+...+CnnPn(1−p)0
它也能写成
∑ k = m n C n k p k ( 1 − p ) n − k \sum_{k=m}^nC_n^kp^k(1-p)^{n-k} k=m∑nCnkpk(1−p)n−k
这个概率是个二项分布的例子,这一知识点我们将在后边详细介绍。
6.6 集合的理论:事件的数学处理应用
如前一节所示,组合分析允许我们确定与感兴趣的事件相关的组合的数量。集合理论是一种更一般的方法,它允许我们“组织”实验的结果事件来确定适当的概率。从最一般的意义上说,集合是一组物品的集合,这些物品具有一些可识别的共同特征,因此它们可以从不同物种的其他事物中区分出来。例如:质数、继电器、紧急停堆系统、贝塞尔方程的解等。我们对集合论的应用涉及到相当大的特殊化。我们感兴趣的是随机实验的结果事件,我们对集合论基本概念的发展将局限于事件概念。
我们可以把事件看作是元素的集合。例如,考虑与掷骰子相关的下列可能事件:
- A-结果是2
- B-结果是偶数
- C-结果小于4
- D-某个数字出现了
- E-结果能被7整除
每个事件都可以被看成是一个集合,这些集合的元素取材于试验的基本结果集合 1 , 2 , 3 , 4 , 5 , 6 {1,2,3,4,5,6} 1,2,3,4,5,6。
我们可以得到:
- A={2}
- B={2,4,6}
- C={1,2,3}
- D = {1,2,3,4,5,6}
- E = ϕ \phi ϕ(空集)
其中,“{}”用来表示集合,括号里边内容表示集合中的元素。
事件A表示有一个元素(数字2)的集合,B和C表示有3个元素的集合。事件D含有实验所有的元素,因此它与试验的结果集合相一致。任何这样包含试验所有结果的集合,被认为是全局集合(universal set),一般用符号 Ω \Omega Ω或者 I I I表示(一些不正式的场合也有用数字1表示的)。E是一个不可能发生的事件,它的集合里没有任何元素,所以我们把它叫做空集,用拉丁字母 ϕ \phi ϕ表示。
回到我们的掷色子例子,我们说元素“1”属于C和D,但是不属于A或B。这个情况用符号可以表示为:
1 ∈ C , 1 ∈ D , 1 ∉ A , 1 ∉ B 1\in C,\ 1 \in D, \ 1\notin A , \ 1 \notin B 1∈C, 1∈D, 1∈/A, 1∈/B
其中符号 ∈ \in ∈表示“属于”,符号 ∉ \notin ∈/表示“不属于”。
我们还需要说明的是D集合中包含A,B,C三个集合的所有元素,这种情况我们称之为A,B,C是D集合的子集,写作 A ∈ D A \in D A∈D, B ∈ D B \in D B∈D, C ∈ D C \in D C∈D。还需要注意到A是B和C的子集。如果X和Y是两个集合,X是Y的子集,同时Y也是X的子集,这种情况下X和Y是相等的。(或者说,它们是同样的集合)
另一个例子,考虑一个柴油机的失效时间以及如下的集合:
- A = { t = 0 } A = \{t = 0\} A={t=0}
- B = { t i , 0 < t ≤ 1 } B = \{t_i,0
- C = { t i , t > 1 } C = \{t_i,t>1\} C={ti,t>1}
启动故障(无法启动)柴油机可以用A表示。B表示故障时间大于0小时小于1小时。C表示故障时间大于1个小时。如果发生故障,每个集合(事件)都可以和不同的事件相联系。(例如外部电源失效)
一个简单的图形过程可以将集合的概念用图形化的方式简单的呈现,这就是维恩图。全局集合用某种几何图形表示(一般是矩形),其他任何相关子集(事件)画在其内部。图VI-1表示掷色子的例子的维恩图。

集合(事件)上的操作可以在维恩图的帮助下定义。并集(union)的操作如图VI-2所示:
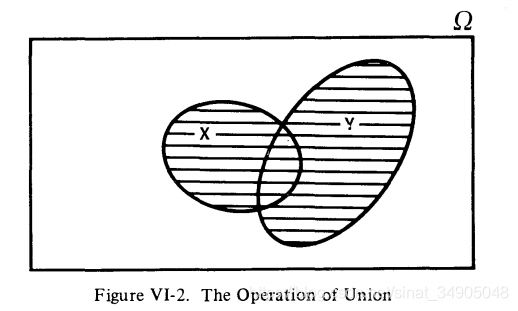
[
集合X,Y的并集是包含在X,Y两个集合的所有元素的集合,写作 X ⋃ Y X\bigcup Y X⋃Y,在图VI-2中用阴影部分表示。返回掷色子的例子,集合B和C的并集是
B ⋃ C = { 1 , 2 , 3 , 4 , 5 , 6 } B\bigcup C=\{1,2,3,4,5,6\} B⋃C={1,2,3,4,5,6}
注意,我们可以用“或”来表示符号“ ⋃ \bigcup ⋃”。
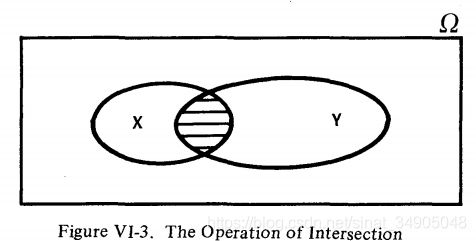
交集的操作如图VI-3。交集是含有X,Y两个集合所共有的元素的集合,被写作“ X ⋂ Y X\bigcap Y X⋂Y”,在图VI-3中用阴影来表示。在掷色子的例子中, B ⋂ C = { 2 } = A B\bigcap C=\{2\}=A B⋂C={2}=A。注意我们一般用“和”来表示符号“ ⋂ \bigcap ⋂”。
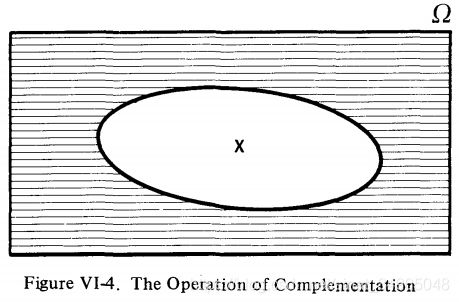
补集的操作如图VI-4。X的补集是指一个集合含有所有不在X内的元素,被写作 X ‾ \overline X X(或者 X ′ X' X′),在图VI-4中用阴影表示。在掷色子的例子中, B ⋃ C B\bigcup C B⋃C的补集是 ( B ⋃ C ) ′ = B ⋃ C ‾ = { 5 } (B\bigcup C)'=\overline{B\bigcup C}=\{5\} (B⋃C)′=B⋃C={5}。
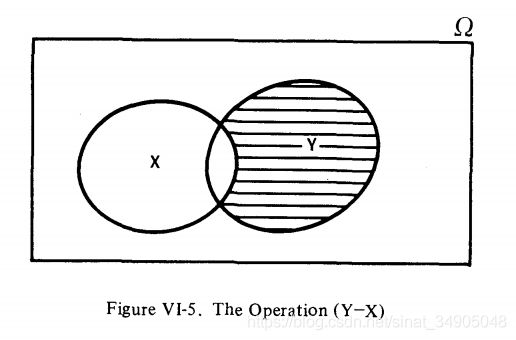
有时还会定义另一个操作(未命名的),但它与我们已经给出的操作无关。操作如图VI-5。如果我们从集合Y中移除X和Y共有的元素,就会得到如图VI-5所示的阴影区域。这个过程偶尔会被写成(Y-X),但是读者可以很容易地看到
Y − X = Y ⋂ X ′ Y-X=Y\bigcap X' Y−X=Y⋂X′
因此标记 ( Y − X ) (Y-X) (Y−X)的定义并不是必要的,后续研究也不会被用到。
假如有这样的一个系统,当系统中有两个或以上的部件故障,系统就会发生故障。那么事件相应的系统故障可以表示为:
S 1 ‾ = A B C ‾ S 2 ‾ = A ‾ B C ‾ S 3 ‾ = A B ‾ C S 4 ‾ = A B C ‾ \begin{aligned} \overline{S_1}=A\overline{BC} \\ \overline{S_2}=\overline{A}B\overline{C} \\ \overline{S_3}=\overline{AB}C \\ \overline{S_4}=\overline{ABC} \\ \end{aligned} S1=ABCS2=ABCS3=ABCS4=ABC
系统故障的事件S,可以用子集表示: S ‾ = S 1 ‾ ⋃ S 2 ‾ ⋃ S 3 ‾ ⋃ S 4 ‾ = { A B C ‾ , A ‾ B C ‾ , A B ‾ C , A B C ‾ } \overline{S}=\overline{S_1}\bigcup \overline{S_2} \bigcup \overline{S_3} \bigcup \overline{S_4} = \{A\overline{BC},\overline{A} B \overline{C},\overline{AB}C,\overline{ABC}\} S=S1⋃S2⋃S3⋃S4={ABC,ABC,ABC,ABC}。我们以枚举的方式列举了系统可能失败的所有方式。该信息可以在很多场景中得到应用。例如,知道部件的故障概率,我们就能计算系统的故障概率。同样的方式,我们可以取全集的任何基本元素(简单事件)的交集和并集来生成其他事件,这些事件可以表示为由特定元素组成的集合。
这个枚举结果事件的方法有时会在系统分析的归纳法中得到应用(通过列举组件操作或非操作的所有可能组合,并确定每种可能性对系统行为的影响。)。这是这种叫“矩阵方法”的性质。如果我们的系统相对简单,或者部件(子系统)相对明确,这些归纳法就是有效的。在全局集合中的组合数量就会相对较小。我们也能利用归纳法推断哪种组合具有最严重的后果和影响。然后,通过故障树分析可以更全面地分析后一事件。
利用我们学过的集合的概念,我们能将概率公式转换成集合公式的形式。例如:
P ( A o r B ) = P ( A ) + P ( B ) − P ( A a n d B ) → P ( A ⋃ B ) = P ( A ) + P ( B ) − P ( A ⋂ B ) (VI-23) \begin{aligned}&P(A \ or \ B)=P(A)+P(B)-P(A \ and \ B) \ \\ \to \ &P(A \bigcup B) = P(A)+P(B)-P(A\bigcap B) \end{aligned}\tag{VI-23} → P(A or B)=P(A)+P(B)−P(A and B) P(A⋃B)=P(A)+P(B)−P(A⋂B)(VI-23)
P ( A a n d B ) = P ( A ∣ B ) P ( B ) = P ( B ∣ A ) P ( A ) → P ( A ⋂ B ) = P ( A ∣ B ) P ( B ) = P ( B ∣ A ) P ( A ) (VI-24) \begin{aligned} &P(A \ and\ B)=P(A|B)P(B)=P(B|A)P(A) \\ \to &P(A \bigcap B)=P(A|B)P(B)=P(B|A)P(A) \\ \end{aligned} \tag{VI-24} →P(A and B)=P(A∣B)P(B)=P(B∣A)P(A)P(A⋂B)=P(A∣B)P(B)=P(B∣A)P(A)(VI-24)
我们介绍了一个新的数学方法——集合(或者说是事件的集合)。基于已定义的并、交、补运算的代数称为布尔代数。通过使用并、交和补的基本运算,布尔代数允许我们用其他基本事件来表示事件。在我们的故障树应用中,通过将故障树转换为等价的布尔方程,可以将系统故障表示为基本组件故障。我们可以对这些方程进行处理,从而得到导致系统失效的组件失效的组合(最小切割集),然后根据构件失效的概率计算系统失效的概率。我们将在后面几节中进一步讨论这些主题。
6.7 符号学
布尔代数是关于事件的代数方法,它们利用各类符号处理事件操作。不幸的是,集合的符号理论并不统一,数学,逻辑和工程领域所用的符号都不一样,具体如下表所示:
| 操作 | 概率 | 数学 | 逻辑 | 工程 |
|---|---|---|---|---|
| 并集 | A o r B A\ or \ B A or B | A ⋃ B A\bigcup B A⋃B | A ⋁ B A \bigvee B A⋁B | A + B A+B A+B |
| 交集 | A a n d B A\ and \ B A and B | A ⋂ B A \bigcap B A⋂B | A ⋀ B A\bigwedge B A⋀B | A B AB AB or A ⋅ B A\cdot B A⋅B |
| 补集 | $not \ A $ | A ′ A' A′ 或 A ‾ \overline{A} A | − A -A −A | A ′ A' A′或 A ‾ \overline{A} A |
数学中的符号和逻辑中的符号比较接近。逻辑的符号相对老一些;实际上符号“V”是拉丁文“vel”的缩写,表示“或”。不幸的是工程领域并没有沿用这些方式,而是采用加号代表并集,并采用乘号代表交集。该方式导致了加号和乘号的滥用。我们可以举这样一个例子,当加号代表 ⋃ \bigcup ⋃时,会引起理解的混乱。
P ( A ⋃ B ) = P ( A ) + P ( B ) − P ( A ⋂ B ) P(A\bigcup B)=P(A)+P(B)-P(A\bigcap B) P(A⋃B)=P(A)+P(B)−P(A⋂B)
如果我们用加号来取代等式左边的 ⋂ \bigcap ⋂,我们有一个方程,“+”带入后左边是一个东西,右边是一个完全不同的东西。
尽管在符号学中存在这些困难和令人困惑的因素,工程符号学现在在工程文献中相当普遍,任何回归数学或逻辑符号的期望似乎都是徒劳的。在故障树分析中,工程表示法得到了广泛的应用。我将在本书后面用到它。如果读者不熟悉事件代数方法,我们还是强烈建议适当的使用这些方法直到完全熟悉。这将提醒我们,不要将集合代数运算与普通代数的运算混淆,在普通代数中,操纵的是数字而不是事件。
6.8 附加的集合概念
我们将进一步讲述集合的其他概念,讲述简单事件和复合事件的区别。这将是一些要遵循的错误树概念的有用基础,并将导致对“概率”的更严格定义。
再次考虑掷一个色子。事件 A = { 2 } A=\{2\} A={2}是一个简单事件;事实上,它构成了结果集合的一个元素。与之相反,事件 B = { 2 , 4 , 6 } B=\{2,4,6\} B={2,4,6}和 C = { 1 , 2 , 3 } C=\{1,2,3\} C={1,2,3}是复合事件。它们不能组成结果集合的元素,即使它们是由结果集合的元素构成的。B和C有一个共有元素;因此,它们的交集不为空(它们不是“不相交”的子集,或者用概率论的语言来说,它们也不是互斥的)。根据定义,结果集合的所有元素都是互斥的,因此,所有元素都是互不关联的。
复合事件(如B和C)通常是现实世界中最重要的事件,由于它们不包括在结果集合中,因此有必要定义一个包含它们的数学实体。这样的数学实体被叫做类( c l a s s ‾ \underline{class} class,用带下划线的字符表示)。类是一个集合,其元素本身就是集合,而这些元素是通过枚举原始结果集合中所有成员的可能组合而生成的。
举一个例子,考虑一个四元素的结果集合 S = { 1 , 3 , 5 , 7 } S=\{1,3,5,7\} S={1,3,5,7}。如果我们列举四元素所有可能的组合,我们将生成由原始集合 S S S定义的类$\underline{S} $,如下所示:
S ‾ = { 1 } , { 3 } , { 5 } , { 7 } , { 1 , 3 } , { 1 , 5 } { 1 , 7 } , { 3 , 5 } , { 3 , 7 } , { 5 , 7 } , { 1 , 3 , 5 } { 1 , 5 , 7 } , { 1 , 3 , 7 } , { 3 , 5 , 7 } , { 1 , 3 , 5 , 7 } , { ϕ } \begin{aligned} \underline{S} =& \{1\},\{3\},\{5\},\{7\},\{1,3\},\{1,5\} \\ &\{1,7\},\{3,5\},\{3,7\},\{5,7\},\{1,3,5\} \\ &\{1,5,7\},\{1,3,7\},\{3,5,7\},\{1,3,5,7\},\{\phi\} \end{aligned} S={1},{3},{5},{7},{1,3},{1,5}{1,7},{3,5},{3,7},{5,7},{1,3,5}{1,5,7},{1,3,7},{3,5,7},{1,3,5,7},{ϕ}
注意,空集 ϕ \phi ϕ被认为是类的一个元素来提供对“不可能事件”的数学表达。如果我们来计算类 S ‾ \underline{S} S的元素个数,我们会发现是16个,它是2的4次方,这里4是原始集合S的元素个数。总的来说,如果原始集合有n个元素,那么对应的类应该有 2 n 2^n 2n个元素。
类概念的用途很简单,类将包含作为元素的每一个可以想到的实验结果(包括简单的和复合的)。因此,在掷色子的实验中, S S S有6个元素,而 S ‾ \underline{S} S有 2 6 = 64 2^6=64 26=64个元素,其中两个是 B = { 2 , 4 , 6 } B=\{2,4,6\} B={2,4,6}和 C = { 1 , 2 , 3 } C=\{1,2,3\} C={1,2,3}。如果扔两个色子, S S S将包含36个元素,而 S ‾ \underline{S} S将有 2 36 2^{36} 236个元素,在这个庞大的子集中,我们找到了和等于7的复合事件,可表示为:
E = { ( 1 , 6 ) , ( 2 , 5 ) , ( 3 , 4 ) , ( 4 , 3 ) ( 5 , 2 ) ( 6 , 1 ) } E=\{(1,6),(2,5),(3,4),(4,3)(5,2)(6,1)\} E={(1,6),(2,5),(3,4),(4,3)(5,2)(6,1)}
重新考虑三个部件A、B、C构成的系统,系统会因两个或以上部件的故障而产生故障。在这个例子中,一个全局集合包含8个元素,而这八个元素构成了所有系统故障的模式和操作。该集合的类含有256个元素,其中就有如下的事件:
- “一个正确的操作”: { A B C , A B C ‾ , A B ‾ C , A B C ‾ } \{ABC,AB\overline{C},A\overline{B}C,A\overline{BC}\} {ABC,ABC,ABC,ABC}
- “B和C同时故障”: { A B C ‾ , A B C ‾ } \{A\overline{BC},\overline{ABC}\} {ABC,ABC}
- “五个部件故障”: ϕ \phi ϕ
- “系统故障”: { A B C ‾ , A ‾ B C ‾ , A B ‾ C , A B C ‾ } \{A\overline{BC},\overline{A}B\overline{C},\overline{AB}C,\overline{ABC}\} {ABC,ABC,ABC,ABC}
读者应该还记得类中的元素都是集合。因此,事件ABC是原始全局集合中的一个元素,但是 { A , B , C } \{A,B,C\} {A,B,C}是是一个含有一个元素ABC的集合,它是一个从全局集合生成的类所包含的一个元素。利用类的概念可以让我们相对轻易的利用正规的办法来处理复合事件,因为类中会包含所有可能的复合事件。
或许类中最有用的特性是提供给我们一个建立概率函数的适合的数学定义的基础。概率函数的集合理论定义如图VI-6所示:
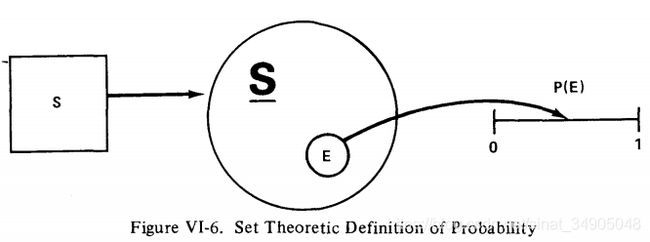
在图VI-6中,标记S的方块代表某随机试验的结果集合。例如,它能表示两个色子实验的总共36中可能的结果。标记着 S ‾ \underline{S} S的圆表示从集合S通过枚举所有可能的元素组合生成的类。在两个色子的例子中,类 S ‾ \underline{S} S拥有一个巨大的( 1 0 1 0 10^10 1010个)元素数量。这些元素表示所有在实验中能想象到的结果(简单的和复合的)。事件 E = " 总 数 是 7 " E="总数是7" E="总数是7"是 S ‾ \underline{S} S的一个成员。它们用图形的方式表示在图VI-6中。一个0-1的坐标系在边上绘出。一个函数能通过映射E在坐标系中的位置来定义。这个函数就是概率函数 P ( E ) P(E) P(E)。
映射的概念可能不熟悉。出于我们的目的,映射可以简单地看作是一种功能关系。例如, y = x 2 y=x^2 y=x2映射所有x到一个抛物线。 y = x y=x y=x映射所有x到一个与y轴45度夹角的直线。在这些例子中,一个范围的数字映射到另一个范围的数字,我们叙述的都是点函数。函数 P ( E ) P(E) P(E)相对更加复杂一些;它映射一个集合到一段数字,我们在这里讲的是集合函数而不再是点函数。然而,简单地说,概率函数只是为每个事件分配一个唯一的数字,即概率。
有两件事需要注意,一是概率现在已经被定义了,但是没有使用比率的极限。第二,这个定义没有告诉我们如何计算概率;相反,它描述了概率函数的数学性质。如果 E E E代表“和为7”的事件,我们已经了解怎么样去计算他的概率,它假设结果集合中的所有36个结果都是等可能的:
P ( E ) = 6 36 = 1 6 P(E)=\frac{6}{36}=\frac{1}{6} P(E)=366=61
当然,这是一个特殊的简单的例子。其他情况我们或许不得不调查问题的物理性质,从而开展事件概率的研究。
6.9 贝叶斯定理
贝叶斯公式在概率中扮演非常重要的角色,对于我们有着很重要的意义,因为它描述了一种故障树特性分析的思考方法。我们首先利用集合的方法研究这个公式,然后讨论结果的含义。
图VI-7描述了全局集合 Ω \Omega Ω到子集合 A 1 , A 2 , A 3 , A 4 , A 5 A_1,A_2,A_3,A_4,A_5 A1,A2,A3,A4,A5的分区方式。
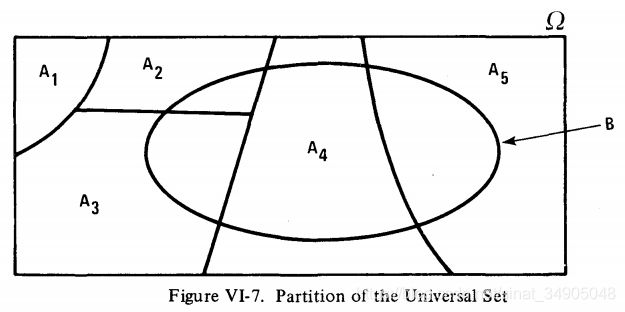
这些集合有如下的性质:
A 1 ⋃ A 2 ⋃ A 3 ⋃ A 4 ⋃ A 5 = ⋃ i = 1 i = 5 A i = Ω (VI-25) A_1\bigcup A_2 \bigcup A_3 \bigcup A_4 \bigcup A_5 = \bigcup_{i=1}^{i=5}A_i=\Omega \tag{VI-25} A1⋃A2⋃A3⋃A4⋃A5=i=1⋃i=5Ai=Ω(VI-25)
A i ⋂ A j = ϕ f o r i ≠ j A_i\bigcap A_j=\phi \ for \ i\neq j Ai⋂Aj=ϕ for i=j
A的任何具备公式VI-25的性质的A的集合都被称为全集的一个划分。另外在图VI-7中还有一个子集合B。读者能发现(通过韦恩图中进行适当的阴影描绘):
( B ⋂ A 1 ) ⋃ ( B ⋂ A 2 ) ⋃ ( B ⋂ A 3 ) ⋃ ( B ⋂ A 4 ) ⋃ ( B ⋂ A 5 ) = B (B\bigcap A_1)\bigcup(B\bigcap A_2)\bigcup(B\bigcap A_3)\bigcup(B\bigcap A_4)\bigcup(B\bigcap A_5)=B (B⋂A1)⋃(B⋂A2)⋃(B⋂A3)⋃(B⋂A4)⋃(B⋂A5)=B
(实际上, B ⋂ A 1 = ϕ B\bigcap A_1=\phi B⋂A1=ϕ但是 ϕ ⋃ X = X \phi \bigcup X=X ϕ⋃X=X,其中X是任何集合)。B的表达式可以写成更加简明的数学形式:
B = ⋃ i = 1 i = 5 B ⋂ A i (VI-26) B=\bigcup_{i=1}^{i=5}B\bigcap A_i \tag{VI-26} B=i=1⋃i=5B⋂Ai(VI-26)
其中,大的并集符号表示连续的并集操作,和 ∑ \sum ∑一样。同样的,大的交集符号表示连续的交集运算。
现在考虑一个交集的概率方程。
P ( A ⋂ B ) = P ( A ∣ B ) P ( B ) = P ( B ∣ A ) P ( A ) P(A\bigcap B)=P(A |B)P(B)=P(B|A)P(A) P(A⋂B)=P(A∣B)P(B)=P(B∣A)P(A)
这对任意事件A,B都适用。特别是对于图VI-7中的任何A都是正确的。因此,我们能得到
P ( A k ⋂ B ) = P ( A k ∣ B ) P ( B ) = P ( B ∣ A k ) P ( A k ) (VI-27) P(A_k\bigcap B)=P(A_k|B)P(B)=P(B|A_k)P(A_k) \tag{VI-27} P(Ak⋂B)=P(Ak∣B)P(B)=P(B∣Ak)P(Ak)(VI-27)
或者
P ( A k ∣ B ) = P ( A k ⋂ B ) P ( B ) = P ( B ∣ A k ) P ( A k ) P ( B ) (VI-28) P(A_k|B)=\frac{P(A_k\bigcap B)}{P(B)}=\frac{P(B|A_k)P(A_k)}{P(B)} \tag{VI-28} P(Ak∣B)=P(B)P(Ak⋂B)=P(B)P(B∣Ak)P(Ak)(VI-28)
我们现在能用公式VI-26通过另一种方式来描述 P ( B ) P(B) P(B)。
P ( B ) = P { ⋃ i = 1 i = 5 B ⋂ A i } = ∑ i = 1 i = 5 P ( B ⋂ A i ) = ∑ i = 1 i = 5 P ( B ∣ A i ) P ( A i ) \begin{aligned} P(B)&=P\{\bigcup_{i=1}^{i=5}B\bigcap{A_i}\} \\ &=\sum_{i=1}^{i=5}P(B\bigcap A_i) \\ &= \sum_{i=1}^{i=5}P(B| A_i)P(A_i) \end{aligned} P(B)=P{i=1⋃i=5B⋂Ai}=i=1∑i=5P(B⋂Ai)=i=1∑i=5P(B∣Ai)P(Ai)
在这里我们可以这样做,因为事件 B ∩ A i B\cap A_i B∩Ai是互斥的。如果我们把这个式子代表 P ( B ) P(B) P(B)带入VI-28,我们就能得到
P ( A k ∣ B ) = P ( B ∣ A k ) P ( A k ) ∑ i P ( B ∣ A i ) P ( A i ) (VI-29) P(A_k|B)=\frac{P(B|A_k)P(A_k)}{\sum_i P(B|A_i)P(A_i)} \tag{VI-29} P(Ak∣B)=∑iP(B∣Ai)P(Ai)P(B∣Ak)P(Ak)(VI-29)
这是贝叶斯原理。这个公式对任意数量的事件 A i A_i Ai都有效。这些事件是完整的和互斥的(如公式VI-25)。求和从i = 1延伸到i = n而不是i = 1到i = 5。
我们现在来讨论公式VI-29的含义。假设某事件B被观察,我们能得到一个完整的互斥的事件B的引发原因的列表。这些原因正好是A的。但是注意A通过VI-25得到的限制条件。现在来看B,我们或许会对寻找由 A k A_k Ak导致B发生的概率感兴趣。这就是利用公式VI-29可以计算的,如果我们可以计算右手边的所有项。
贝叶斯方法是一种演绎的方法:给定一个系统事件,它的一个导致因素的概率是多少?这与归纳方法形成对比:给定某些特定的故障,整个系统将如何运行?现在用一个简单的例子来说明贝叶斯公式的用法,这个例子特别容易列举出A的。
假设我们有三个标着I、II、III的装运纸箱。纸箱的大小,形状和一般外观都是一样的,它们包含不同数量的电阻,从公司X, Y, Z,如图VI-8所示。
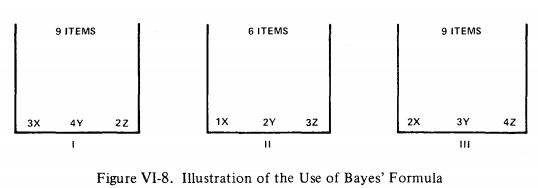
随机实验如下:首先,随机选择一个纸箱。然后从选择的盒子中选择两个电阻。当检查它们时,发现这两个项目都来自z公司。后一个事件在我们对贝叶斯规则的一般发展中与事件B相一致。B的“原因”很容易识别:要么是纸箱I被选中,要么是纸箱II被选中,要么是纸箱III被选中。因此,
- $A_1 = $ 选择纸箱1
- $ A_2 = $ 选择纸箱2
- $ A_3 = $选择纸箱3
现在我们能够计算出给定事件B,最初选择是纸箱1的概率。
P ( A 1 ∣ B ) = P ( B ∣ A 1 ) P ( A 1 ) P ( B ∣ A 1 ) P ( A 1 ) + P ( B ∣ A 2 ) + P ( B ∣ A 3 ) P ( A 3 ) P(A_1|B)=\frac{P(B|A_1)P(A_1)}{P(B|A_1)P(A_1)+P(B|A_2)+P(B|A_3)P(A_3)} P(A1∣B)=P(B∣A1)P(A1)+P(B∣A2)+P(B∣A3)P(A3)P(B∣A1)P(A1)
对于以下集合,该公式看起来很自然
P ( A 1 ) = P ( A 2 ) = P ( A 3 ) = 1 3 P(A_1)=P(A_2)=P(A_3)=\frac{1}{3} P(A1)=P(A2)=P(A3)=31
因为盒子都很相似,且当时是随机选择的。我们现在需要计算 P ( B ∣ A 1 ) , P ( B ∣ A 2 ) 和 P ( B ∣ A 3 ) P(B|A_1),P(B|A_2)和P(B|A_3) P(B∣A1),P(B∣A2)和P(B∣A3)。这很容易从公式VI-8计算得到
P ( B ∣ A 1 ) = 2 9 × 1 8 = 1 36 P ( B ∣ A 2 ) = 3 6 × 2 5 = 1 5 P ( B ∣ A 3 ) = 4 9 × 3 8 = 1 6 \begin{aligned} P(B|A_1)&=\frac{2}{9}\times\frac{1}{8}=\frac{1}{36} \\ P(B|A_2)&=\frac{3}{6}\times\frac{2}{5}=\frac{1}{5} \\ P(B|A_3)&=\frac{4}{9}\times\frac{3}{8}=\frac{1}{6} \\ \end{aligned} P(B∣A1)P(B∣A2)P(B∣A3)=92×81=361=63×52=51=94×83=61
将这些参数带入到贝叶斯公式,我们得到
P ( A 1 ∣ B ) = 1 36 × 1 3 1 36 × 1 3 + 1 5 × 1 3 + 1 6 × 1 3 = 5 71 P(A_1|B)=\frac{\frac{1}{36}\times\frac{1}{3}}{\frac{1}{36}\times\frac{1}{3}+\frac{1}{5}\times\frac{1}{3}+\frac{1}{6}\times\frac{1}{3}}=\frac{5}{71} P(A1∣B)=361×31+51×31+61×31361×31=715
类似的方法,我们能计算出
P ( A 2 ∣ B ) = 36 71 P ( A 3 ∣ B ) = 30 71 \begin{aligned} P(A_2|B)&=\frac{36}{71} \\ P(A_3|B)&=\frac{30}{71} \\ \end{aligned} P(A2∣B)P(A3∣B)=7136=7130
因此,如果事件B确实被观察到,那么最初选择纸箱II的概率大约是50%。
作为另一个例子,请再次参考由三个组件组成的简单系统。我们已经确定,系统可以在四种模式中的任何一种中发生故障,即 S 1 ‾ \overline{S_1} S1、 S 2 ‾ \overline{S_2} S2、 S 3 ‾ \overline{S_3} S3、 S 4 ‾ \overline{S_4} S4。如果系统失败,我们希望知道其失败模式为 S 3 ‾ \overline{S_3} S3的概率,我们可以计算:
P ( S 3 ‾ ∣ S ‾ ) = P ( S ‾ ∣ S 3 ‾ ) P ( S 3 ‾ ) P ( S ‾ ∣ S 1 ‾ ) P ( S 1 ‾ ) + P ( S ‾ ∣ S 2 ‾ ) + P ( S ‾ ∣ S 3 ‾ ) P ( S 3 ‾ ) + P ( S ‾ ∣ S 4 ‾ ) P ( S 4 ‾ ) P(\overline{S_3}|\overline{S}) = \frac{P(\overline{S}|\overline{S_3})P(\overline{S_3})}{P(\overline{S}|\overline{S_1})P(\overline{S_1})+P(\overline{S}|\overline{S_2})+P(\overline{S}|\overline{S_3})P(\overline{S_3})+P(\overline{S}|\overline{S_4})P(\overline{S_4})} P(S3∣S)=P(S∣S1)P(S1)+P(S∣S2)+P(S∣S3)P(S3)+P(S∣S4)P(S4)P(S∣S3)P(S3)
这可以用更简单的形式来写,因为如果 S 1 ‾ \overline{S_1} S1、 S 2 ‾ \overline{S_2} S2、 S 3 ‾ \overline{S_3} S3、 S 4 ‾ \overline{S_4} S4其中任何一个事件发生,系统肯定会失败。
P ( S 3 ‾ ∣ S ‾ ) = P ( S 3 ‾ ) P ( S 1 ‾ ) + P ( ( ‾ S 2 ) ) + P ( S 3 ‾ ) + P ( S 4 ‾ ) P(\overline{S_3}|\overline{S})=\frac{P(\overline{S_3})}{P(\overline{S_1})+P(\overline(S_2))+P(\overline{S_3})+P(\overline{S_4})} P(S3∣S)=P(S1)+P((S2))+P(S3)+P(S4)P(S3)
推算 P ( S i ‾ ) P(\overline{S_i}) P(Si)可以从可靠性数据估计。 P ( S i ‾ ∣ o v e r l i n e S ) P(\overline{S_i}|overline{S}) P(Si∣overlineS)有时叫做系统故障原因 S i ‾ \overline{S_i} Si的“权重(importance)”。贝叶斯原理有时会用于寻找最佳修复方案,并探求系统故障的最可能的原因。(例如 P ( S i ‾ ∣ S ‾ ) P(\overline{S_i}|\overline{S}) P(Si∣S))
第七章 故障树分析中的布尔代数与应用
7.1 布尔代数的规则
在以前的章节里,我们介绍了集合所应用的基本理论,特别是和事件有关的(随机试验的结果)。在这一章,我们准备进一步介绍事件的代数,称为布尔代数,是一种专门用于故障树分析的技术。布尔代数在涉及到二分法的情况下特别重要:开关是打开还是关闭,阀门是打开还是闭合,事件是发生还是不发生。
本章讨论的布尔技术对于故障树具有直接的实际意义。可以将故障树视为导致顶部事件发生的故障事件之间的布尔关系的图形表示。事实上,一个故障树总是可以被转换成一个完全等价的布尔方程集。因此,对布尔代数规则的理解对故障树的构造和简化具有重要的意义。一旦绘制了故障树,就可以对其进行评估,从而得到定性和定量的特征。这些特征不能从故障树本身获得,但可以从等价的布尔方程获得。在这个评估过程中,我们使用了本章讨论的代数约简技术。
我们在表VII-1中给出了布尔代数的规则,并对每个规则进行了简短的讨论。读者应借助维恩图来检查每个规则的有效性。那些读者数学倾向于将检测规则,如上所述,不构成一组最少的必要且充分的。这里和其他地方,作者有时会牺牲数学优雅的呈现事物的形式更有用的和可以理解的实际系统分析师。
根据(1a)和(1b),并集和交集的操作是可以互换的。用另一种说法,这个互换的规则允许我们交换事件X和Y和“与”操作有关。需要记住的是很多数学实体是不能互换的,例如向量的叉乘和矩阵的叉乘。
(2a)和(2b)的关系和组合率很相似: a ( b c ) = ( a b ) c a(bc)=(ab)c a(bc)=(ab)c、 a + ( b + c ) = ( a + b ) + c a+(b+c)=(a+b)+c a+(b+c)=(a+b)+c。如果我们由一系列的“或”操作或者一系列的“与”操作,相关的规则允许我们来足又组合这些事件。
当我们想要组合一个“与”操作和“或”操作时分配律(3a)和(3b)提供了有效可控的程序。如果我们从左到右看这个公式,我们只是将左边的表达式简化为一个未分解的形式。例如,在(3a)中,我们用X作用于Y和Z来得到右边的表达式。如果方程从右向左,我们只是因式分解。例如,在(3b)中,我们提出X来得到左边。虽然(3a)类似于普通代数中的分配律,(3b)却没有这样的类比。
幂等律(4a)和(4b)允许我们“取消”同一事件的任何冗余。
吸收率(5a)和(5b)可以很容易的通过维恩图得到验证。对于5a,我们能通过下面的方法说明。当X的出现自动意味着Y的出现时,则x是Y的子集。我们可以表示为 X ⊂ Y X\subset Y X⊂Y或者 X → Y X\to Y X→Y。在这种情况下, X + Y = Y X+Y=Y X+Y=Y,并且 X ⋅ Y = X X\cdot Y=X X⋅Y=X。在5a中,如果X发生,然后(X+Y)也发生,且 X ⊂ ( X + Y ) X\subset(X+Y) X⊂(X+Y);所以 X ⋅ ( X + Y ) = X X\cdot (X+Y)=X X⋅(X+Y)=X。至于5b,我们能引发一个简单的论点。
德摩根定理{?a)和(7b)提供了去除括号中质数的一般规则。假如说X表示某部件的故障,则 X ′ X' X′就表示某部件的异常不发生。就此而言,(7a)简单地声明,对于不发生X和Y的双重失败,X一定不能失败或者Y一定不能失败。
应用这个规则,让我们尝试化简这个表达式:
( A + B ) ⋅ ( A + C ) ⋅ ( D + B ) ⋅ ( D + C ) (A+B)\cdot(A+C)\cdot(D+B)\cdot(D+C) (A+B)⋅(A+C)⋅(D+B)⋅(D+C)
我们能利用3b到 ( A + B ) ⋅ ( A + C ) (A+B)\cdot(A+C) (A+B)⋅(A+C),获得
( A + B ) ⋅ ( A + C ) = A + ( B C ) (A+B)\cdot(A+C)=A+(BC) (A+B)⋅(A+C)=A+(BC)
同样
( D + B ) ⋅ ( D + C ) = D + ( B ⋅ C ) (D+B)\cdot(D+C)=D+(B\cdot C) (D+B)⋅(D+C)=D+(B⋅C)
我们因此获得了一个中间结果
( A + B ) ⋅ ( A + C ) ⋅ ( D + B ) ⋅ ( D + C ) = ( A + B ⋅ C ) ⋅ ( D + B ⋅ C ) (A+B)\cdot(A+C)\cdot(D+B)\cdot(D+C)=(A+B\cdot C)\cdot(D+B\cdot C) (A+B)⋅(A+C)⋅(D+B)⋅(D+C)=(A+B⋅C)⋅(D+B⋅C)
如果我们现在用E代表事件$B\cdot C,得到
( A + B C ) ⋅ ( D + B C ) = ( A + E ) ⋅ ( D + E ) = ( E + A ) ⋅ ( E + D ) (A+BC)\cdot(D+BC)=(A+E)\cdot(D+E)=(E+A)\cdot(E+D) (A+BC)⋅(D+BC)=(A+E)⋅(D+E)=(E+A)⋅(E+D)
3b还能得到另一个方程
( E + A ) ⋅ ( E + D ) = E + A ⋅ D = B ⋅ C + A ⋅ D (E+A)\cdot(E+D)=E+A\cdot D=B\cdot C+A\cdot D (E+A)⋅(E+D)=E+A⋅D=B⋅C+A⋅D
我们因此获得最终结果如下
( A + B ) ⋅ ( A + C ) ⋅ ( D + B ) ⋅ ( D + C ) = B ⋅ C + A ⋅ D (A+B)\cdot(A+C)\cdot(D+B)\cdot(D+C)=B\cdot C+A\cdot D (A+B)⋅(A+C)⋅(D+B)⋅(D+C)=B⋅C+A⋅D
为了方便求值,对原始表达式进行了大量简化。
还有一些简化布尔函数的一般规则,我们将在本章后面讨论。目前,我们关心的是通过或多或少不系统地操作代数可以完成什么。下面举几个例子。读者应仔细阅读这些插图,并在每一步确定使用了1-9条规则。
例1:
[ ( A ⋅ B ) + ( A ⋅ B ′ ) + ( A ′ ⋅ B ′ ) ] ′ = A ′ ⋅ B [(A\cdot B)+(A\cdot B')+(A' \cdot B')]'=A'\cdot B [(A⋅B)+(A⋅B′)+(A′⋅B′)]′=A′⋅B
这个表达式能在这个例子可以通过(a)作为第一步删除最外层的质数,或者(b)操作大括号内的项并作为最后一步删除最外层的质数来实现。在这两种情况下,去除素数都是使用(7a)或(7b)来完成的。
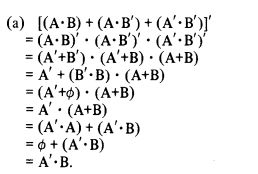

例2:

例3:
[ ( X ⋅ Y ) + ( A ⋅ B ⋅ C ) ] ⋅ [ ( X ⋅ Y ) + ( A ′ + B ′ + C ′ ) ] = X ⋅ Y [(X\cdot Y)+(A\cdot B\cdot C)]\cdot[(X\cdot Y)+(A'+B'+C')]=X\cdot Y [(X⋅Y)+(A⋅B⋅C)]⋅[(X⋅Y)+(A′+B′+C′)]=X⋅Y
将德摩根定理应用到第二项中,我们得到
[ ( X ⋅ Y ) + ( A ⋅ B ⋅ C ) ] ⋅ [ ( X ⋅ Y ) + ( A ⋅ B ⋅ C ) ′ ] [(X\cdot Y)+(A\cdot B\cdot C)]\cdot[(X\cdot Y)+(A\cdot B\cdot C)'] [(X⋅Y)+(A⋅B⋅C)]⋅[(X⋅Y)+(A⋅B⋅C)′]
令 L = X ⋅ Y , M = ( A ⋅ B ⋅ C ) L=X\cdot Y,M=(A\cdot B\cdot C) L=X⋅Y,M=(A⋅B⋅C),我们得到
( L + M ) ⋅ ( L + M ′ ) = L ⋅ ( M + M ′ ) = L + Ω = L = X ⋅ Y (L+M)\cdot(L+M')=L\cdot(M+M')=L+\Omega=L=X\cdot Y (L+M)⋅(L+M′)=L⋅(M+M′)=L+Ω=L=X⋅Y
证明了原命题。注意在这个例子中,A B C是完全多余的。
7.2 故障树分析应用
在本节中,我们将把布尔方法与故障树联系起来。正如我们现在所知道的,故障树是一个逻辑图,它描述了为了使其他事件发生而必须发生的某些事件。如果事件是由其他事件引发的,则称为“故障”;如果事件是基本的引发事件,则称为“故障”。故障树将事件(故障与故障或故障与故障)相互关联,并使用某些符号来描述各种关系(参见第四章)。这个基础的符号是“门”,每个门都有输入和输出,如图VII-1所示。
门输出是正在考虑的“较高”故障事件,而门输入是与输出相关的更基本(“较低”)故障(或故障)事件。当我们绘制一个故障树时,我们从“更高的”故障发展到更基本的故障(例如从输出到输入)。

在第五章,该技术被用于决定哪类门最适用。两类基础门是或门和与门。因为这些门与我们刚才讨论的布尔运算以完全相同的方式关联事件,布尔代数表示与故障树表示之间存在一一对应关系。
7.2.1 或门
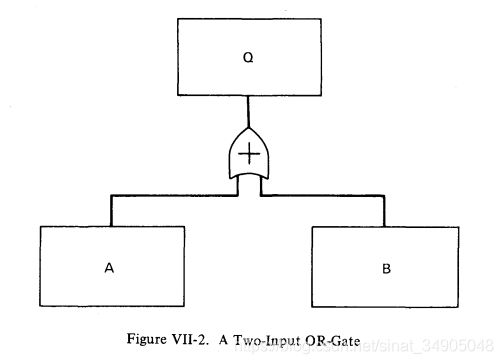
![]() 这个符号是或门,它表示将连接这个门的事件进行并集操作。任何一个或多个输入事件必须发生,以导致门以上的事件发生。或门等同于逻辑符号“+”。例如,一个有两个输入的或门,输入分别是A和B,两个输入必须发生才能导致Q发生。因为等效于操作“+”,所以或门有时后可以表示为图VII-2那样的里边有个“+”号的图形。如果一个或门有n个输入,那么布尔表达式为 Q = A 1 + A 2 + A 3 . . . + A n Q=A_1+A_2+A_3...+A_n Q=A1+A2+A3...+An。在概率方面,从公式VI-4:
这个符号是或门,它表示将连接这个门的事件进行并集操作。任何一个或多个输入事件必须发生,以导致门以上的事件发生。或门等同于逻辑符号“+”。例如,一个有两个输入的或门,输入分别是A和B,两个输入必须发生才能导致Q发生。因为等效于操作“+”,所以或门有时后可以表示为图VII-2那样的里边有个“+”号的图形。如果一个或门有n个输入,那么布尔表达式为 Q = A 1 + A 2 + A 3 . . . + A n Q=A_1+A_2+A_3...+A_n Q=A1+A2+A3...+An。在概率方面,从公式VI-4:
P ( Q ) = P ( A ) + P ( B ) − P ( A ⋂ B ) 或 者 P ( Q ) = P ( A ) + P ( B ) − P ( A ) P ( B ∣ A ) (VII-1) P(Q)=P(A)+P(B)-P(A\bigcap B)\ 或者\ P(Q)=P(A)+P(B)-P(A)P(B|A) \tag{VII-1} P(Q)=P(A)+P(B)−P(A⋂B) 或者 P(Q)=P(A)+P(B)−P(A)P(B∣A)(VII-1)
从第VI章中,我们能得到如下关于公式VII-1的结论:
- 如果A和B互斥,那么 P ( A ∩ B ) = 0 P(A\cap B)=0 P(A∩B)=0 且 P ( Q ) = P ( A ) + P ( B ) P(Q)=P(A)+P(B) P(Q)=P(A)+P(B)。
- 如果A和B相互独立,那么 P ( B ∣ A ) = P ( B ) P(B|A)=P(B) P(B∣A)=P(B),且 P ( Q ) = P ( A ) + P ( B ) − P ( A ) P ( B ) P(Q)=P(A)+P(B)-P(A)P(B) P(Q)=P(A)+P(B)−P(A)P(B)
- 如果事件B是完全依赖于事件A,也就是说,不论A什么时候发生,B也会发生,那么 P ( B ∣ A ) = 1 P(B|A)=1 P(B∣A)=1,并且 P ( Q ) = P ( A ) + P ( B ) − P ( A ) = P ( B ) P(Q)=P(A)+P(B)-P(A)=P(B) P(Q)=P(A)+P(B)−P(A)=P(B)。
- P ( Q ) ≈ P ( A ) + P ( B ) P(Q) \approx P(A)+P(B) P(Q)≈P(A)+P(B)是在任何情况下输出事件Q的概率的保守估计。例如对于任何A和B,存在: P ( A ) + P ( B ) ≥ P ( A ) + P ( B ) − P ( A ∩ B ) P(A)+P(B) \geq P(A)+P(B)-P(A \cap B) P(A)+P(B)≥P(A)+P(B)−P(A∩B)
- 如果A和B是相互独立,且发生概率很低的事件(概率小于0.1),且 P ( A ∩ B ) P(A\cap B) P(A∩B)相比 P ( A ) + P ( B ) P(A)+P(B) P(A)+P(B)较小,于是 P ( A ) + P ( B ) P(A)+P(B) P(A)+P(B)就近似等于 P ( Q ) P(Q) P(Q),读者将记得 P ( A ) + P ( B ) P(A)+P(B) P(A)+P(B)在第六章作为“稀有事件近似”介绍过。
这些结论,特别是最后两条,在后续的第十一章非常重要。
在第四章,我们大体上介绍了异或门。读者可能记得两个输入A和B,一个输出Q的异或门,事件A或B不同时发生的内容。异或门事件Q的概率表示是:
P ( Q ) 异 或 = P ( A ) + P ( B ) − 2 P ( A ∩ B ) (VII-2) P(Q)_{异或}=P(A)+P(B)-2P(A\cap B) \tag{VII-2} P(Q)异或=P(A)+P(B)−2P(A∩B)(VII-2)
比较公式VII-1和VII-2,我们看到如果A和B是独立的低概率故障,这两个表达式的不同点基本是微不足道的。这也就是为什么在故障树分析时,如果部件故障是独立的,且低概率发生的,同或和异或门的区别并不大的原因。然而,在确实需要专用或逻辑的特殊情况下,以及在输入事件与高故障概率之间有很强相关性的情况下,有时进行区分是有用的。在后一个例子中,交集项必须足够大到对结果造成影响。总之,应该注意的是,在任何情况下,使用同或而不是异或门所产生的错误都会使答案偏向保守一方,因为同或门具有更高的概率。在本文的其余部分,除非另有说明,对或门的所有引用都应被解释为各种同或门。
图VII-3显示了一个用于一组常闭触点的故障条件的与门的实际示例。
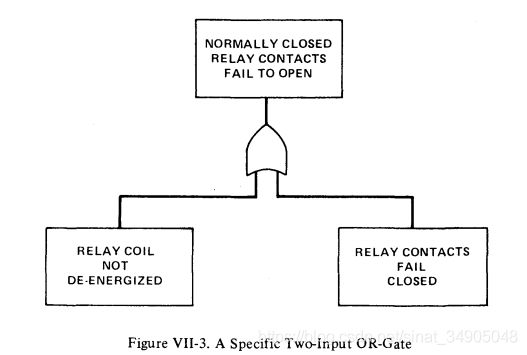
该或门等同于如下的逻辑表达:
继 电 器 接 触 点 无 法 断 开 = 继 电 器 线 圈 无 法 断 开 + 接 触 点 关 闭 失 败 继电器接触点无法断开=继电器线圈无法断开+接触点关闭失败 继电器接触点无法断开=继电器线圈无法断开+接触点关闭失败
相比明确的描述事件,一个独特的标记(Q,A等)常被用于表示各个事件(如图VII-2)。因此,如果用Q标记事件“继电器接触点无法断开”,用A标记“继电器线圈无法断开”,用B标记“接触点关闭失败”,我们能用布尔表达式 Q = A + B Q=A+B Q=A+B来表示这个或门。
一个或门依据基本的输入事件对门上的事件的重述表达。门上的事件包含了所有这些更基本的事件;如果一个或多个基本的事件发生,则B也发生。这个解释是十分重要的,它描述了一个或门的特征,以及将它和与门区分开来。一个或门的输入事件并不是门上边事件的起因;他们门上事件的简单的重述。我们前边已经说过这一点了,但是我们觉得这一点在故障树分析中太重要了,它贯穿了布尔代数的始终,所以我们在这里再次强调它。
考虑串联的两个开关,如图VII-4。A和B是导线上的两个点。如果忽略导线的故障,那么“B点没有电流”这个事件用故障树表达如图VII-5所示:
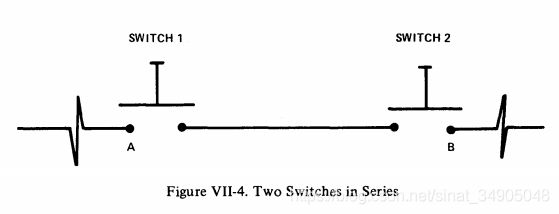
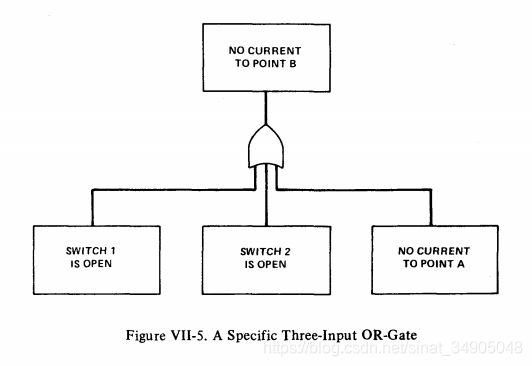
如果事件如下图所示,那么其布尔表达为 B = A 1 + A 2 + A 3 B=A_1+A_2+A_3 B=A1+A2+A3。

如果事件 A 1 或 A 2 或 A 3 A_1或A_2或A_3 A1或A2或A3发生,则事件B发生。事件B仅仅是 A 1 , A 2 , A 3 A_1,A_2,A_3 A1,A2,A3的重新表达。我们将特定的事件 A 1 , A 2 , A 3 A_1, A_2, A_3 A1,A2,A3归类为一般事件B。
7.2.2 与门
![]() 这个符号是与门,与门表示关联事件的并集。它等同于布尔符号“ ⋅ \cdot ⋅”。为了门上层事件的发生,所有和与门相关的事件必须是存在的。。两个事件连接与门,等效的布尔代数表达为 Q = A ⋅ B Q=A\cdot B Q=A⋅B,如图VII-6.因为布尔交集操作的等效表达是符号 ⋅ \cdot ⋅,所以这个符号有时候会在门的符号里绘出,如图VII-6那样。如n个事件连接与门,等效的布尔表达为
这个符号是与门,与门表示关联事件的并集。它等同于布尔符号“ ⋅ \cdot ⋅”。为了门上层事件的发生,所有和与门相关的事件必须是存在的。。两个事件连接与门,等效的布尔代数表达为 Q = A ⋅ B Q=A\cdot B Q=A⋅B,如图VII-6.因为布尔交集操作的等效表达是符号 ⋅ \cdot ⋅,所以这个符号有时候会在门的符号里绘出,如图VII-6那样。如n个事件连接与门,等效的布尔表达为
Q = A 1 ⋅ A 2 ⋅ A 3 . . . A n Q=A_1 \cdot A_2 \cdot A_3 ... A_n Q=A1⋅A2⋅A3...An
在这个例子,事件Q当且仅当所有事件 A i A_i Ai发生时才发生。以概率表示,由式(VI-10)
P ( Q ) = P ( A ) P ( B ∣ A ) = P ( B ) P ( A ∣ B ) P(Q)=P(A)P(B|A)=P(B)P(A|B) P(Q)=P(A)P(B∣A)=P(B)P(A∣B)
依据我们在第VI章讲过的,我们能对方程VII-3做出一些推论:
- 如果A和B是独立的事件,那么 P ( B ∣ A ) = P ( B ) , P ( A ∣ B ) = P ( A ) , P ( Q ) = P ( A ) P ( B ) P(B|A)=P(B),P(A|B)=P(A),P(Q)=P(A)P(B) P(B∣A)=P(B),P(A∣B)=P(A),P(Q)=P(A)P(B)。
- 如果A和B不是互相独立的,那么P(Q)比P(A)P(B)明显大的多。举个例子,在一个极端的情况下,B完全依赖于A,也就是说,当A发生,B也发生,那么$P(B|A)=1, \ P(Q)=P(A)。
读者应该记下这些推论,我们会在后边关于故障树量化的章节里用到它们。

连接到与门的事件是与门上方事件的原因。事件Q只因每个输入事件都发生才会发生。这个因果关系是与门和或门的不同点。如果当任何一个输入事件发生,输出事件就发生,那么这个门就是或门,该输出事件只是输入事件的重述。如果门以上的事件仅在更多基本事件的组合发生时发生,则门为与门,输入为构成门上事件的原因。
我们用一个例子来总结这一节的内容,这个例子表明了如何利用布尔代数来重新构建一个故障树。考虑方程 D = A ⋅ ( B + C ) D=A \cdot (B+C) D=A⋅(B+C)。对应的故障树构建如图VII-7。
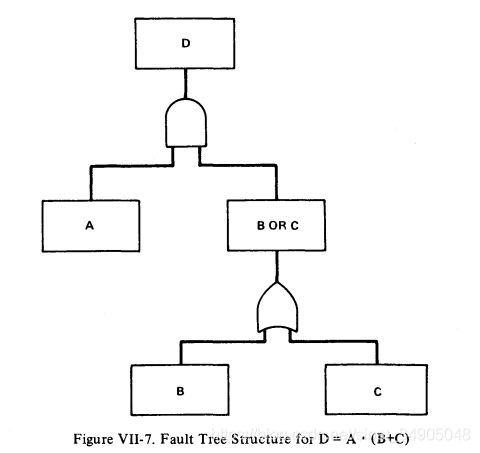
根据规则3a,事件D能表达为 D = ( A ⋅ B ) + ( A ⋅ C ) D=(A \cdot B)+(A \cdot C) D=(A⋅B)+(A⋅C)。故障树关于事件D的等效表达如图VII-8所示:
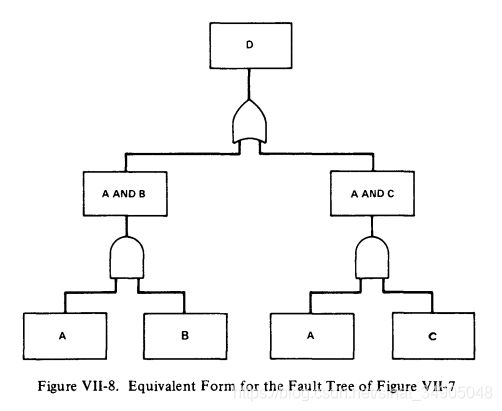
图VII-7和图VII-8的故障树看起来不同,但是,它们是等效的。因此,对于一个问题,不存在一个“正确”的故障树吗,而是有很多正确的故障树,它们之间是相互等效的。布尔代数的规则可以用于重构一个故障树,使其变的更简单,更清晰,更容易理解。稍后,我们将应用布尔代数规则来获得故障树的一种形式,称为最小切割集形式,它允许以直接的方式执行定量和定性评估。
7.3 用标准形式表示布尔方程的香农方法
在上几节的内容里,我们讨论了如何利用本章给出的代数规则的方法来表示布尔方程。在本节里,我们将应用香农方法来扩展布尔方程。这是一种通用的方法,可以用于任何布尔函数。依据香农方法,一个n变量的布尔函数可以扩展为1,2,……或所有n个变量。当扩展完成(所有n个变量),其结果是指“扩展到最小项”。后者构成了一种标准或规范的形式,由所有相关事件的发生和不发生的组合构成。
开始之前我们先回顾一些基础知识。一个布尔变量是一个两个值的变量。例如,如果E表示某件我们感兴趣的事件,那么E=1表示该事件已经发生,而E=0表示该事件没有发生。因此,布尔代数中的定理比普通代数中的定理更容易证明,因为在普通代数中,变量可以取无穷大的值。
考虑一个函数 f