pytorch
一、基础环境准备
1.安装Anaconda
这个可以管理python的环境,包含了多个package。直接到官网下载,一顿无脑安装。
2.创建自己使用的python环境
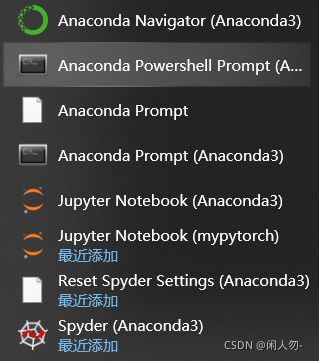
选择Anaconda Powershell Prompt,进入到命令行模式。这里可以直接执行conda命令,如果直接CMD,打开命令行窗口,除非在安装的时候已经添加到Path中(安装时候,软件会提示不推荐),否则无法执行。如果你开始没有添加到Path,还非得用CMD打开,还非得要执行成功,那么在系统环境变量中,添加以下两个路径即可(当然是根据你实际安装目录来了)。

接着,创建自己的python执行环境
conda create -n mypytorch python=3.7 #创建自己随意命为mytorch的python环境,指定的版本为3.7
conda activate mypytorch #激活自己创建的环境
conda remove -n mypytorch --all #删除环境操作

3.下载pytorch
进入pytorch官网,选择相应的选项,复制代码到自己创建的python环境中
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
pip list #查看是否安装完成
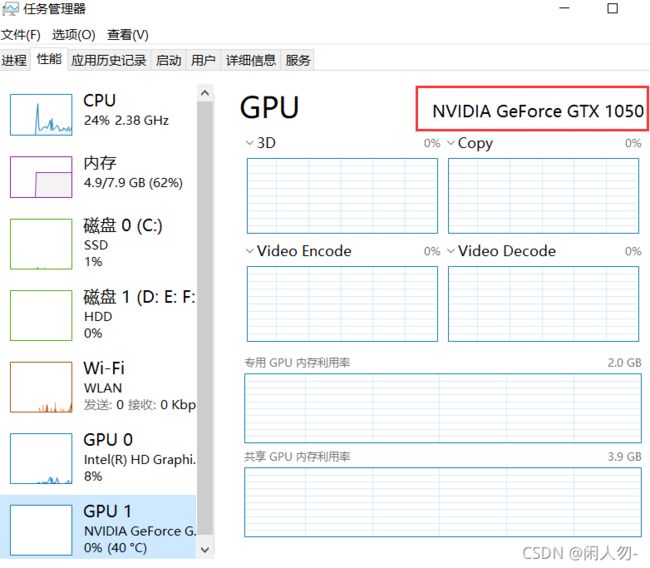
4.查看显卡是否支持GPU
torch.cuda.is_available()
若是true即可,如果是false,则是因为未安装相应的显卡驱动。通过任务管理器可以查询到自己的GPU型号,到相应的官网下载安装即可。
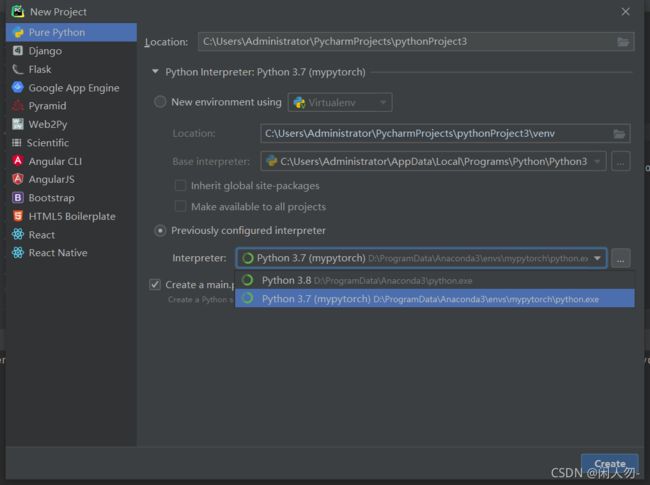
5.设置pycharm中python环境
进入setting,设置开发的环境为我们刚刚设置好的环境mypytorch,安装相应的安装路径去找即可,默认是base。
这里有个坑,如果进入项目后,点击terminal,没有显示(mypytorch),则要进入setting,将里面的terminal的选项变成cmd。

6.安装jupyter
(mypytorch) PS C:\Users\Administrator> conda install nb_conda #安装jupyter
(mypytorch) PS C:\Users\Administrator> jupyter notebook #启动jupyter
二、pytorch使用基础
1.数据几种类型
1)Type check
>>> import torch
>>> a = torch.randn(2,3) # Returns a tensor filled with random numbers from a normal distribution with mean 0 and variance 1
>>> a
tensor([[ 2.5393, -0.7969, -0.4391],
[-1.1970, 1.2156, 0.6645]])
>>> a.type() #方式一
'torch.FloatTensor'
>>> type(a) #方式二
<class 'torch.Tensor'>
>>> isinstance(a,torch.Tensor) #方式三
True
>>> a = a.cuda() #a可以放到gpu上,返回一个gpu的引用
>>> isinstance(a,torch.cuda.FloatTensor)
True
>>> a
tensor([[ 2.5393, -0.7969, -0.4391],
[-1.1970, 1.2156, 0.6645]], device='cuda:0') #0代表索引,可以用数字指定不同的gpu
2)dim0,rank0
创建scalar,即标量,所以返回的size为空。
>>> b = torch.tensor(2.2)
>>> b.shape
torch.Size([])
>>> len(b)
0
>>> b.size()
torch.Size([])
3)dim1,rank1
这个才是返回一个一维的tensor张量,一般用于nerual network的bias。
>>> c = torch.tensor([1.1])
>>> c.shape
torch.Size([1])
>>> c.size()
torch.Size([1])
>>> len(c)
1
>>> a = torch.FloatTensor(1) #the value of a is random as you can see
>>> a
tensor([0.])
>>> a = torch.FloatTensor(1)
>>> a
tensor([2.8072e-25])
#从numpy转到tensor
>>> import numpy as np
>>> data = np.ones(2)
>>> data
array([1., 1.])
>>> type(data)
numpy.ndarray
>>> import torch
>>> torch.from_numpy(data)
tensor([1., 1.], dtype=torch.float64)
4)dim2,rank2
例如,要输入4张图片,每张图片是512个像素点,就需要一个2维的tensor。[4,512],“4”means the batches,“512”means the pixels。
>>> a= torch.randn(2,3)
>>> a
tensor([[-1.2851, 0.8597, -0.4564],
[-0.1959, 0.7506, 0.9920]])
>>> a.shape
torch.Size([2, 3])
>>> a.size()
torch.Size([2, 3])
>>> len(a)
2
>>> a.size(1)
3
>>> a.size(0)
2
>>> a.shape[0]
2
>>> a.shape[1]
3
5)dim3,rank3
例如在RNN中,[10,20,100],可以分别表示输入句子的单词数,输入的句子数,以及每个句子的数字表示形式。
>>> a= torch.randn(2,3,4)
>>> atensor([[[ 0.8534, 2.2986, -1.2692, -0.5413], [-0.9082, 0.3824, 1.2512, -0.8332], [-0.0730, 0.0394, -0.9881, -1.1090]], [[-0.3941, 0.1149, 0.1178, -0.1802], [-2.0267, -0.5384, 0.9194, 0.0735], [-0.1890, 0.3173, 0.0026, -1.0254]]])
>>> a.shapetorch.Size([2, 3, 4])
>>> list(a.shape)[2, 3, 4]
6)dim4,rank4
在4维中,[2,3,32,32],在CNN(conv0lution neural network)中,可以表示batch,channel,pixel*pixel。
>>> a= torch.randn(2,3,4,4)
>>> a
tensor([[[[-7.3867e-01, 1.0451e+00, 1.2081e+00, -9.4706e-01], [ 7.5026e-01, -8.3781e-01, -1.2996e+00, 2.6039e-01], [ 1.3351e+00, 1.1809e-01, -9.9116e-01, 1.6582e-01], [-6.1353e-01, -4.0407e-01, 6.6712e-01, 6.4560e-01]], [[ 2.1307e+00, 3.5750e-01, 2.6827e-02, -1.6091e+00], [ 3.1073e-01, -4.0742e-02, 1.5866e+00, -3.3350e-01], [ 4.7144e-01, 5.1743e-01, 1.2810e+00, 9.1368e-01], [-6.1274e-01, -4.4615e-01, -1.7262e+00, 1.6291e-01]], [[-5.3089e-01, -4.4679e-01, 4.5259e-01, -9.3356e-01], [-6.1651e-01, -7.2001e-01, 3.3486e-01, 6.0413e-01], [-1.4439e+00, -6.2363e-01, -1.6444e-02, 1.3210e+00], [-1.7065e-01, 4.9214e-01, -1.3391e+00, 1.7251e+00]]], [[[ 1.9581e-01, -4.0493e-01, -1.6156e-01, 1.4016e-01], [-4.7948e-01, -6.3849e-01, 1.6590e+00, 8.1804e-04], [-6.4810e-01, 2.6479e-01, 8.9475e-01, 1.5257e+00], [-1.1387e+00, -2.0899e-01, -1.5342e+00, 8.5398e-01]], [[ 2.9230e-01, -1.9475e+00, -1.8211e+00, 1.3643e+00], [-1.1113e+00, -1.0395e+00, -7.5311e-01, -1.8436e+00], [-9.3728e-01, 1.0142e+00, 1.0069e+00, 1.5017e+00], [-2.5276e-01, 1.9375e+00, -7.5054e-01, 1.5652e+00]], [[ 5.4638e-01, -6.7265e-01, -1.7653e+00, -4.4864e-01], [ 4.3882e-01, 3.3457e-01, -8.9273e-01, -2.9781e-01], [ 2.6450e-03, 5.3783e-01, -1.4012e+00, 5.0192e-01], [ 1.1387e+00, 7.0935e-01, -1.6405e+00, -4.7739e-02]]]])
>>> a.dim() #the dimension of tensor4
>>> a.numel() # the number of the elements96
2.创建tensor数据
1)import from numpy
>>> a = np.array([2,3,4])
>>> a = torch.from_numpy(a)
>>> atensor([2, 3, 4], dtype=torch.int32)
>>> a = np.ones([2,3])
>>> a = torch.from_numpy(a)
>>> atensor([[1., 1., 1.], [1., 1., 1.]], dtype=torch.float64)010627834
2)import from list
>>> torch.tensor([2.,3.2])
tensor([2.0000, 3.2000])
>>> a=torch.Tensor([1,2])
tensor([1., 2.])
>>> torch.FloatTensor([2.0,3.2])
tensor([2.0000, 3.2000])
>>> torch.tensor([[2.,3.2],[1.,22.3]])
tensor([[ 2.0000, 3.2000], [ 1.0000, 22.3000]])
3)torch.Tensor和torch.tensor
torch.Tensor()是Python类,是默认张量类型torch.FloatTensor()的别名,torch.Tensor([1,2]) 会调用Tensor类的构造函数__init__,生成单精度浮点类型的张量。
>>> a=torch.Tensor([1,2])
>>> a.type()
'torch.FloatTensor'
>>> torch.FloatTensor(2,3) #FloatTensor如果没有加[],这个就代表2*3的张量
tensor([[8.4490e-39, 1.1112e-38, 1.1112e-38], [1.0194e-38, 9.0919e-39, 8.4490e-39]])
torch.tensor()仅仅是Python的函数,函数原型是:
torch.tensor(data, dtype=None, device=None, requires_grad=False)
其中data可以是:list, tuple, array, scalar等类型。torch.tensor()可以从data中的数据部分做拷贝(而不是直接引用),根据原始数据类型生成相应的torch.LongTensor,torch.FloatTensor,torch.DoubleTensor。
所以尽量使用tensor,这样不容易引起混淆。
4)uninitialized
>>> a = torch.empty(2,3) # 未初始化数据,但其中其实也是有数据的,就是很随机
>>> atensor([[8.4490e-39, 1.1112e-38, 1.1112e-38], [1.0194e-38, 9.0919e-39, 8.4490e-39]])
>>> torch.IntTensor(1,2,4) #初始化2*4类型为int的tensor张量tensor([[[0, 0, 0, 0], [0, 0, 0, 0]]], dtype=torch.int32)
未初始化的数据,后续一定要跟数据的写入操作,否则容易引起错误。例如ifinite。
5)set default type和类型转换
>>> torch.tensor([1.2,3]).type()
>>>'torch.FloatTensor'
>>> torch.set_default_tensor_type(torch.DoubleTensor)
>>> torch.tensor([1.2,3]).type()
>>>'torch.DoubleTensor'
my_tensor = torch.randn(2, 4) # 默认为float32类型my_tensor.type(torch.float16)
print(my_tensor.type(torch.float16))
print(my_tensor.type(torch.float32))
print(my_tensor.type(torch.int32))
print(my_tensor.type(torch.long))
6)rand,randint,rand_like,randn
>>> a=torch.rand(3,3) #分布为0-1
>>> atensor([[0.4414, 0.6422, 0.5690],
[0.6165, 0.8499, 0.8019],
[0.7556, 0.6540, 0.3777]])
>>> torch.rand_like(a)tensor([[0.4849, 0.6793, 0.2483],
[0.9683, 0.0073, 0.4381],
[0.8378, 0.7043, 0.6529]])
>>> torch.randint(1,10,[3,3])
tensor([[9, 5, 3],
[6, 3, 2],
[2, 2, 4]])
>>> a = orch.normal(mean=torch.full([10],0.),std=torch.arange(1,0,-0.1)) #生成一维长度为10的张量,指定mean和方差,使用不多>>> atensor([-0.8503, -0.7255, 0.4011, -0.1893, -0.2654, -0.5096, -1.0296, 0.0800, -0.2995, 0.0595])
7)full
>>> torch.full([2,3],7)
tensor([[7, 7, 7],
[7, 7, 7]])
>>> torch.full([],7)
tensor(7)
>>> torch.full([1],7)
tensor([7])
8)arange,range
>>> torch.arange(0,10) #not include 10tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])>>> torch.arange(0,10,2)tensor([0, 2, 4, 6, 8])>>> torch.range(0,10)#要淘汰了__main__:1: UserWarning: torch.range is deprecated and will be removed in a future release because its behavior is inconsistent with Python's range builtin. Instead,use torch.arange, which produces values in [start, end).tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
9)linspace,logspace
>>> torch.linspace(0,10,steps=10) # include 10tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
>>> torch.linspace(0,10,steps=4)
tensor([ 0.0000, 3.3333, 6.6667, 10.0000])
>>> torch.linspace(0,10,steps=10)
tensor([ 0.0000, 1.1111, 2.2222, 3.3333, 4.4444, 5.5556, 6.6667, 7.7778, 8.8889, 10.0000])
>> torch.logspace(0,-1,steps=10) # -1 to 0, divided to 10 parts,and 10**(results),base can be pointed tensor([1.0000, 0.7743, 0.5995, 0.4642, 0.3594, 0.2783, 0.2154, 0.1668, 0.1292, 0.1000])#torch.logspace(start, end, steps=100, base=10, out=None)
10)ones,zeros,eye
>>> torch.ones(3,3)
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
>>> torch.zeros(3,3)
>>>tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
>>> torch.eye(3,3)
tensor([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
11)randperm
可以随机打散一个张量,为了使得另外一个张量同步进行打散,需要将idx进行传递。每次生成的idx是随机的。
>>> torch.randperm(10)
tensor([0, 8, 1, 7, 2, 9, 4, 3, 6, 5])
>> a = torch.rand(2,3)>>> b = torch.rand(2,3)
>>> idx = torch.randperm(2) #2代表需要shuffle的行数,因此两个张量的行数要相等,否则shuffle无意义
>>> idxtensor([1, 0])
>>> a[idx]
tensor([[0.4346, 0.8989, 0.6416],
[0.9100, 0.4351, 0.5118]])
>>> b[idx]
tensor([[0.1344, 0.4399, 0.4617],
[0.2563, 0.3718, 0.4814]])
>>> a,b
(tensor([[0.9100, 0.4351, 0.5118], [0.4346, 0.8989, 0.6416]]), tensor([[0.2563, 0.3718, 0.4814], [0.1344, 0.4399, 0.4617]]))
3.索引和切片
1)indexing
>>> a = torch.rand(4,3,28,28)
>>> a[0].shapetorch.Size([3, 28, 28])
>>> a[0,0].shapetorch.Size([28, 28])
>>> a[0,0,2,4]tensor(0.8303)
2)slide
>>> a[:2].shapetorch.Size([2, 3, 28, 28])
>>> a[:2,:1,:,:].shapetorch.Size([2, 1, 28, 28])
>>>> a[:2,-1:,:,:].shape # -1代表最后一个位置,即从最后一个位置索引到最后,因此只要1个torch.Size([2, 1, 28, 28])
>>> a[:,:,0:28:2,0:28:2].shape #隔行采样torch.Size([4, 3, 14, 14])
3)指定索引
>>> a.index_select(0,torch.tensor([0,2])).shape #0代表的是第0维度,[0,2]代表在指定维度上的索引值
torch.Size([2, 3, 28, 28])
>>> a.index_select(1,torch.tensor([0,2])).shape
torch.Size([4, 2, 28, 28])
>>> a.index_select(2,torch.arange(8)).shape
torch.Size([4, 3, 8, 28])
4)…
代表全部取,目的就是为了简便:,:,:这样的写法。
>>> a[...].shape
torch.Size([4, 3, 28, 28])
>>> a[0,...].shape
torch.Size([3, 28, 28])
>>> a[:,1,...].shape
torch.Size([4, 28, 28])
>>> a[...,:2].shape
torch.Size([4, 3, 28, 2])
5) mask,take
>>> x = torch.randn(3,4)
>>> xtensor([[-0.0114, 1.7566, 0.6446, -0.1703], [ 1.1333, 1.4878, -1.3025, -0.9525], [-1.5269, -1.5563, 0.5044, -0.5952]])
>>> mask = x.ge(0.5)#greater equal, pick out the items which are bigger than 0.5
>>> masktensor([[False, True, True, False], [ True, True, False, False], [False, False, True, False]])
>>> torch.masked_select(x,mask)tensor([1.7566, 0.6446, 1.1333, 1.4878, 0.5044])
>>> torch.masked_select(x,mask).shape
torch.Size([5])
>>> src = torch.tensor([[4,3,5],[6,7,8]])
>>> torch.take(src,torch.tensor([0,2,5]))#take也是全部打平成一维,然后取值tensor([4, 5, 8])
4.维度变换
1)view,reshape
>>> a = torch.rand(4,1,28,28)
>>> a.shapetorch.Size([4, 1, 28, 28])
>>> a.view(4,28*28) #view的操作,将后面的维度全部展成一维,只要满足前后两个张量的size是一样的即可,但是随意变换会改变物理意义
tensor([[0.3283, 0.0609, 0.5368, ..., 0.3527, 0.6830, 0.3296], [0.9450, 0.8152, 0.4318, ..., 0.3698, 0.1965, 0.0140], [0.0147, 0.3103, 0.5506, ..., 0.6233, 0.7996, 0.2039], [0.9472, 0.2460, 0.5017, ..., 0.3560, 0.5117, 0.8877]])
>>> a.view(4*1,28,28).shapetorch.Size([4, 28, 28])
>>> a.view(4*28,28).shape #如果不知道原来的数据结构为batch,channel,pixel*pixel,则无法回复原来数据torch.Size([112, 28])
2)squeez,unsqueez
这种方法,不增加数据,只是增加维度,而且每次只增加1。
>>> a = torch.rand(4,1,28,28)#从1,2,3,4...开始计数,unsqueez只要索引结果是在这个范围内即可
>>> a.shapetorch.Size([4, 1, 28, 28])
>>> a.unsqueeze(0).shapetorch.Size([1, 4, 1, 28, 28])
>>> a.unsqueeze(4).shapetorch.Size([4, 1, 28, 28, 1])
>>> a.unsqueeze(-4).shape #-4+1,即-3位置
torch.Size([4, 1, 1, 28, 28])
>>> a.unsqueeze(-5).shape #-5+1,即-4位置
torch.Size([1, 4, 1, 28, 28])
>>> a = torch.tensor([1.2,2.3])
>>> a.shapetorch.Size([2])
>>> a
tensor([1.2000, 2.3000])
>>> b=a.unsqueeze(-1)
tensor([[1.2000], [2.3000]])
>>> b.shapetorch.Size([2, 1])
>>> b=a.unsqueeze(0)
>>> b.shapetorch.Size([1, 2])
tensor([[1.2000, 2.3000]])
for example
>>> b = torch.rand(32)
>>> b= b.unsqueeze(0).unsqueeze(2).unsqueeze(3)
>>> b.shapetorch.Size([1, 32, 1, 1])
>>> f = torch.rand(4,32,14,14)
这样就可以实现b和f的叠加
>>> b.shapetorch.Size([1, 32, 1, 1])
>>> b.squeeze().shape #squeeze可以挤压掉所有某个维度值为1的,如果不是1,直接返回,不会报错
torch.Size([32])
>> b.squeeze(0).shapetorch.Size([32, 1, 1])
3)expand,repeat
expand不主动复制数据,只有用的时候会复制,推荐使用。而repeat一开始就复制数据。
>>> a = torch.rand(4,32,14,14)
>>> b.shapetorch.Size([1, 32, 1, 1])
>>> b.expand(4,32,14,14).shape #仅限于1变换到N,如果不为1,则无法确定如何变换,所以会报错
torch.Size([4, 32, 14, 14])
>>> c=b.expand(-1,32,14,14) #-1代表不变,如果写成其他负数,虽然可以生成某个维度值为负数,但是没有意义
>>> c.shapetorch.Size([1, 32, 14, 14])#也可以直接使用expand_as(a),使得和a的结构保持一致
>>> c = b.repeat(4,32,1,1).shape #repeat和expand的接口不一致,表示的是重复的次数,而不是最后扩展成的个数
>>> ctorch.Size([4, 1024, 1, 1])
4)t()转置
>>> a = torch.randn(3,4)
>>> a
tensor([[-0.5033, 0.6503, -0.8144, -0.1555], [ 0.8754, -0.3455, 0.0848, -1.3635], [ 0.1745, 1.4552, -0.7793, 0.4431]])
>>> a.t()
tensor([[-0.5033, 0.8754, 0.1745], [ 0.6503, -0.3455, 1.4552], [-0.8144, 0.0848, -0.7793], [-0.1555, -1.3635, 0.4431]])
5)transpose,permute
>>> b = torch.randn(4,3,32,32)
>>> b1=b.transpose(1,3).contiguous().view(4,3*32*32).view(4,3,32,32)#交换维度后需要跟contiguous变成连续的
>>> torch.all(torch.eq(b,b1))
tensor(False)
>>>b2=b.transpose(1,3).contiguous().view(4,3*32*32).view(4,32,32,3).transpose(1,3)#这种方法才可恢复数据
>>> torch.all(torch.eq(b,b2))
tensor(True)#当我们在使用transpose或者permute函数之后,tensor数据将会变的不在连续(内存被打乱),而此时,如果我们采用view函数等需要tensor数据联系的函数时,将会抛出错误,需要使用contiguous进行解决,具体原因可去百度。
>>> b.permute(0,2,3,1).shapetorch.Size([4, 32, 32, 3])#相比较transpose每次只能交换2个维度,permute一步到位。
5.拼接和拆分
1)cat
>>> a = torch.rand(4,32,8)
>>> b = torch.rand(5,32,8)
>>> torch.cat([a,b],dim=0).shape #除了dim的维度,其他必须保持一致torch.Size([9, 32, 8])
2)stack
>>> a = torch.rand(4,3,16,32)
>>> b = torch.rand(4,3,16,32)
>>> torch.cat([a,b],dim=2).shape
torch.Size([4, 3, 32, 32])#这个是cat的效果,stack是在指定的位置添加一个新的维度,根据这个维度去访问后面不同的数据
>>> a = torch.rand(32,8)
>>> b = torch.rand(32,8)
>>> torch.stack([a,b],dim=0).shapetorch.Size([2, 32, 8])#即分两批去访问a,b#stack各维度对应的值必须完全一致,而cat除了指定的dim可以不一致外,其他必须一致
3)split,chunk
都是可以将张量进行拆分,区别:
(1)chunks只能是int型,而split_size_or_section可以是list。
(2)chunks在不满足该维度下的整除关系,会将块按照维度切分成1的结构,而split会报错。
>>> a = torch.rand(32,8)
>>> b = torch.rand(32,8)
>>> c = torch.stack([a,b],dim=0)
>>> aa,bb= c.split(2,dim=0) #在指定的dim上,将张量划分为指定的份数,例如2份
>>> aa,bb= c.split([1,1],dim=0) #如果传入list,表示每份的长度,这个总和要等于对应dim的长度
>>> aa,bb = c.chunk(2,dim=0) #同样的效果
6.数学运算
1)加减乘除
矩阵形式必须相同,对应位置的元素进行相加减,可以使用符号,也可以使用方法,二者等价。
>>> torch.all(torch.eq(a-b,torch.sub(a,b)))
tensor(True)
>>> torch.all(torch.eq(a+b,torch.add(a,b)))
tensor(True)
>>> torch.all(torch.eq(a*b,torch.mul(a,b)))
tensor(True)
>>> torch.all(torch.eq(a/b,torch.div(a,b)))
tensor(True)
2)矩阵乘法matmul
>>> a = torch.randn(2,2)
>>> a
tensor([[-0.3638, -0.3727], [-0.1026, 0.5023]])
>>> b = torch.randn(2,3)
>>> b
tensor([[-1.2305, -1.5390, 0.8672], [-0.8897, -0.8115, 0.3422]])
>>> torch.matmul(a,b)
tensor([[ 0.7793, 0.8625, -0.4431], [-0.3207, -0.2497, 0.0829]])#可以使用a@b,或者torch.mm(a,b),不过推荐用上面的方法#多维乘积,保持前面的不变,后面的进行举证乘法运算
>>> a = torch.rand(4,3,28,64)
>>> b = torch.rand(4,3,64,32)
>>> torch.matmul(a,b).shapetorch.Size([4, 3, 28, 32])#前面如果不一样,会进行broadingcast,要满足不一样的维度其中有一个为1,否则就会报错
3)power,exp,log
>>> a = torch.full([2,2],3)
>>> a.pow(2)tensor([[9, 9], [9, 9]])
>>> a.rsqrt() #平方根后取倒数tensor([[0.5774, 0.5774], [0.5774, 0.5774]])
>>> a**2tensor([[9, 9], [9, 9]])
>>> a= torch.exp(torch.ones(2,2))
>>> a
tensor([[2.7183, 2.7183], [2.7183, 2.7183]])
>>> torch.log(a) #默认以e为底
tensor([[1., 1.], [1., 1.]])
4) floor(),ceil(),round(),trunc(),frac()
>>> a = torch.tensor(3.14)
>>> a.floor(),a.ceil(),a.trunc(),a.frac()
(tensor(3.), tensor(4.), tensor(3.), tensor(0.1400))
>>> a.round() #四舍五入tensor(3.)
5)clamp
>>> grad = torch.rand(2,3)*15
>>> grad.max()
tensor(8.9718)
>>> grad.min()
tensor(0.4775)
>>> grad.median()
>tensor(5.0097)
>>> grad.clamp(10) #所有小于10的都会变成10
tensor([[10., 10., 10.], [10., 10., 10.]])
>>> gradtensor([[8.9718, 5.7908, 2.3024], [0.4775, 5.0097, 6.5894]])
>>> grad.clamp(0,10) #不在0-10之间的,小于0变成0,大于10的变成10
tensor([[8.9718, 5.7908, 2.3024], [0.4775, 5.0097, 6.5894]])
7.统计属性
1)norm 范数
>>> a = torch.full([8],1.)
>>> atensor([1., 1., 1., 1., 1., 1., 1., 1.])
>>> b = a.view(2,4)
>>> c = a.view(2,2,2)
>>> a.norm(1),b.norm(1),c.norm(1)
(tensor(8.), tensor(8.), tensor(8.))
>>> a.norm(2),b.norm(2),c.norm(2)
(tensor(2.8284), tensor(2.8284), tensor(2.8284)) #x**2,加起来后,接着开根号
>>> btensor([[1., 1., 1., 1.], [1., 1., 1., 1.]])
>>> ctensor([[[1., 1.], [1., 1.]], [[1., 1.], [1., 1.]]])
>>> b.norm(1,dim=1) #在维度1取范数1
tensor([4., 4.])
>>> b.norm(2,dim=1) #在维度1取范数2
tensor([2., 2.])
>>> c.norm(1,dim=0) #在维度0取范数1
tensor([[2., 2.], [2., 2.]])
>>> c.norm(2,dim=0) #在维度0取范数2
tensor([[1.4142, 1.4142], [1.4142, 1.4142]])
2)mean,sum,min,max,prod
>>> a= torch.arange(8).view(2,4).float()
>>> atensor([[0., 1., 2., 3.], [4., 5., 6., 7.]])
>>> a.min(),a.max(),a.mean(),a.prod()
(tensor(0.), tensor(7.), tensor(3.5000), tensor(0.))
>>> a.sum()
tensor(28.)
>>> a.argmax(),a.argmin() #打平,然后得到索引,而不是二维的值
(tensor(7), tensor(0))
>>> a= torch.randn(4,10)
>>> a.argmax(dim=1) # tensor([3, 7, 1, 4])
>>> a= torch.randn(2,3,4)
>>> a
tensor([[[ 0.0456, 0.0638, -1.7585, -0.5761], [-2.0696, 0.8162, 0.8706, 0.1251], [-0.2504, -1.0267, 0.4605, 0.7746]], [[ 1.0210, 1.5221, 1.6295, -0.9321], [ 0.5695, -0.6758, 0.3616, -0.0788], [ 0.1279, 1.1306, 0.5182, 0.3628]]])
>>> a.argmax(dim=0) # 除去指定的dim,剩下的即为答案的维度
tensor([[1, 1, 1, 0], [1, 0, 0, 0], [1, 1, 1, 0]])
>>> a.argmax(dim=1)
>tensor([[0, 1, 1, 2], [0, 0, 0, 2]])
3)dim,keepdim
>>> a.max(dim=1)
torch.return_types.max(values=tensor([[0.0456, 0.8162, 0.8706, 0.7746], [1.0210, 1.5221, 1.6295, 0.3628]]),indices=tensor([[0, 1, 1, 2], [0, 0, 0, 2]]))
>>> a.max(dim=1,keepdim=True) # 保持原来的维度
torch.return_types.max(values=tensor([[[0.0456, 0.8162, 0.8706, 0.7746]], [[1.0210, 1.5221, 1.6295, 0.3628]]]),indices=tensor([[[0, 1, 1, 2]], [[0, 0, 0, 2]]]))
4)topK
>>> a = torch.randn(4,10)
>>> a.topk(3,dim=1)#默认返回最大的几个
torch.return_types.topk(values=tensor([[1.6636, 0.4823, 0.2113], [2.2586, 1.3601, 1.3257], [1.9844, 0.9145, 0.5822], [1.7426, 1.0411, 0.3964]]),indices=tensor([[2, 7, 4], [9, 5, 2], [6, 9, 2], [2, 4, 7]]))
>>> a.topk(3,dim=1,largest=False)#返回最小的几
torch.return_types.topk(values=tensor([[-1.3783, -1.2496, -1.2438], [-1.5512, -0.8749, -0.5103], [-1.4080, -0.4035, -0.1197], [-0.7173, -0.6119, -0.4954]]),indices=tensor([[8, 3, 9], [7, 8, 3], [3, 0, 5], [0, 9, 5]]))
>>> a.kthvalue(8,dim=1)
torch.return_types.kthvalue(values=tensor([0.2113, 1.3257, 0.5822, 0.3964]),indices=tensor([4, 2, 2, 7]))
>>> a.kthvalue(3)
torch.return_types.kthvalue(values=tensor([-1.2438, -0.5103, -0.1197, -0.4954]),indices=tensor([9, 3, 5, 5]))
5)compare
>>> a>0
tensor([[False, False, True, False, True, False, False, True, False, False], [False, True, True, False, True, True, True, False, False, True], [False, True, True, False, True, False, True, True, True, True], [False, False, True, False, True, False, True, True, False, False]])
>>> torch.gt(a,0)
tensor([[False, False, True, False, True, False, False, True, False, False], [False, True, True, False, True, True, True, False, False, True], [False, True, True, False, True, False, True, True, True, True], [False, False, True, False, True, False, True, True, False, False]])
>>>> a!=0
tensor([[True, True, True, True, True, True, True, True, True, True], [True, True, True, True, True, True, True, True, True, True], [True, True, True, True, True, True, True, True, True, True], [True, True, True, True, True, True, True, True, True, True]])
8.高阶
1)where

2)gather

9.数据可视化
1)dataset
在项目中,创建个dataset文件,将图片和图片的标签文件夹放进去
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir
self.lable_dir = label_dir
self.path = os.path.join(self.root_dir,self.lable_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.lable_dir,img_name)
img = Image.open(img_item_path)
label = self.lable_dir
return img,label
if __name__ == '__main__':
root_dir = "dataset/train"
lable_dir = "ants_image"
ants_dataset = MyData(root_dir,lable_dir)
img,label = ants_dataset[0]
img.show()
print(label)
2)tensorboard
pip install tensorboard
如果正确安装tensorboard之后,重新运行代码,还是报错找不到在torch.utils.tensorboard中找不到SummaryWriter该怎么办。别着急,因为SummaryWriter是存在于tensorboardX(其作为tensorboard的子模块)因此同样通过pip进行安装:
pip install tensorboardX
如果正确安装tensorboardX依旧找不到SummaryWriter
请将报错的:from torch.utils.tensorboard import SummaryWriter
改为: from tensorboardX import SummaryWriter
from tensorboardX import SummaryWriter
writer = SummaryWriter("logs")
for i in range(100):
writer.add_scalar("y=2x\*x",i\*i,i)
writer.close()
更改端口
tensorboard --logdir=logs --port=6007
3)transform
将图片转换成tensor
from PIL import Image
from torchvision import transforms
from tensorboardX import SummaryWriter
img_path = "dataset/train/ants_image/0013035.jpg"
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()
tensorImg = tensor_trans(img)#normalization
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])#均值和标准差
img_norm = trans_norm(tensorImg)
writer = SummaryWriter("logs")
writer.add_image("Normalize",img_norm,2)#resize
print(img.size)
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img)
img_resize=tensor_trans(img_resize)
print(img.size)
writer.add_image("resize",img_resize,2)#compose
trans_resize2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize2,tensor_trans])
img_resize2 = trans_compose(img)
writer.add_image("resize2",img_resize2,1)
print(tensorImg.shape)
writer.close()
4)下载数据集
import torchvision
from tensorboardX import SummaryWriter
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])#下载数据集
cifar10train_set = torchvision.datasets.CIFAR10(root="./dataset/cifar10",transform=dataset_transform,train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset/cifar10",transform=dataset_transform,train=False,download=True)
writer = SummaryWriter("p10")
for i in range(10):
img,target = test_set[i] writer.add_image("test_set",img,i)
writer.close()