数据库基本概念
数据库基本概念
- 快照和备份
- 元组和元组槽
- 数据库语言
-
-
- 一、DDL(data definition language)数据定义语言(不用commit)
- 二、DML(data Manipulation language)数据操纵语言(需要commit)
- 三、DCL(data control language)数据控制语言
- 四、DQL(data query language)数据查询语言
-
- MVCC多版本并发控制机制
-
-
-
- union类型介绍:
-
- 实现方式
-
- 1、冻结老数据,确保元组间事务号差距<2^31(PG)
- 2、回收脏数据空间
-
- WAL(Write Ahead Log)
-
-
- Undo & Redo
-
-
- Double Write Buffer (相当于脏页写两遍)
-
-
- session
- Toast
- 脏页
- fsync
- 事务快照机制CSN
- HOT(heap only tuple)
-
-
- line pointer(元组指针)和索引元组的区别:
-
- 不同元组的区别
-
- DEAD:
-
- RECENTLY_DEAD:
- index scan & index only scan
-
-
- Index Scan(索引扫描):
- Index Only Scan(仅索引扫描):
-
- 备份
- 两阶段锁
- 分布式数据库存储和处理
-
-
- CN(Coordinator Node)
- DN(Data Node)
- 2PC(两阶段提交)
-
快照和备份
二者共同保证了数据库的安全性,从实现方式上来说,快照是每次记录一次事务的修改内容,并不会对所有数据进行拷贝,占据的空间小且执行速度快。备份则是对所有数据进行拷贝,所以消耗的空间,时间都很大。
元组和元组槽
元组就是一行数据,元组槽相当于n条连续元组,这里有点像跳表的设计,由于数据库中B+树的结构,数据页都在最底层,而如何在一页数据中找到对应元组,就需要元组槽。实际上也是分治思想。首先快速确定一个区域,而后在区域中继续细分寻找对应元组。
元组槽介绍
数据库语言
参考链接
一、DDL(data definition language)数据定义语言(不用commit)
a、创建(create):create index,create tablespace……
b、删除(drop,truncate):truncate删除整个数据,drop删除整个表(数据+表结构)两者都不用commit,也不能回滚
c、修改(alter):alter table,alter database,alter tablespace……
d、查看(show,desc),show parameter(查看参数的值),desc 对象-查看对象的结构
二、DML(data Manipulation language)数据操纵语言(需要commit)
a、插入 b、更新 c、删除某一行
三、DCL(data control language)数据控制语言
a、授权(grant):grant create session to scott
b、回滚(rollback)
c、提交(commit)
d、新建用户(create user)
四、DQL(data query language)数据查询语言
MVCC多版本并发控制机制
PostgreSQL利用多版本并发控制MVCC来维护数据的一致性。从实现上来说,存储的每一个元组都对应有四个隐藏字段,为xmin(表示创建时的事务x_id),xmax(表示删除时的事务x_id),cmin和cmax(二者表示创建该元组时在事务中命令的序列号)。
例子可参考参考链接
例子中可发现cmin和cmax始终是相同的,因为它是union类型,在判断可见性时,cmin和cmax不可能同时起作用,所以为了节省空间就让他们占据同一片空间,使用时当xmin起作用就读取cmin,xmax起作用就读取cmax。
cmin和cmax的combo类型
union类型介绍:
union(联合)与struct(结构)有一些相似之处。但两者有本质上的不同。在struct中各成员有各自的内存空间, 一个struct变量的总长度是各成员长度之和。而在union中,各成员共享一段内存空间, 一个union变量的长度等于各成员中最长的长度。应该说明的是, 这里所谓的共享不是指把多个成员同时装入一个union变量内, 而是指该union变量可被赋予任一成员值,但每次只能赋一种值, 赋入新值则冲去旧值。如前面介绍的“单位”变量, 如定义为一个可装入“班级”或“教研室”的union后,就允许赋予整型值(班级)或字符串(教研室)。要么赋予整型值,要么赋予字符串,不能把两者同时赋予它。union类型的定义和变量的说明一个union类型必须经过定义之后, 才能把变量说明为该union类型。
实现方式
参考链接 实现MVCC
astore 形式中并不对旧版本元组直接删除,而是会继续保留,然后通过VACUUM机制来清理脏数据(所有事务都不可能访问到的版本)。VACCUM机制有两个作用:
1、冻结老数据,确保元组间事务号差距<2^31(PG)
将过老的脏数据元组的xmin、xmax直接修改为2、0, 这样所有的事务都比这个元组新,使其都为可见。PG中只用了32位,而OpenGauss中使用了64位,故不存在事务号回卷的情况。32位事务号很快会耗尽,那么就需要从0开始。64位要耗尽可能要几十年上百年,故不考虑回卷问题。
具体的,OpenGauss中实现64位事务号,方式如下:
事务号是uint64单调递增序列,为了节省空间以及兼容老的版本。元组头部的xmIn/xmax存储为:
xid_base(uint64)+xmin/ ×max(uint32)。属于同一个页面的元组会共用同一个页面基本的xid_base以节省空间。
2、回收脏数据空间
极力推荐的学习视频
AutoVacuum只是回收了空间给数据库,但没有给操作系统。VacuumFull才是彻底的释放空间给操作系统。
WAL(Write Ahead Log)
参考链接
通过日志(Undo和Redo)保证数据操作的原子性和持久性。
其中Undo保证事务在未提交时可以撤销所有操作,实现原子性
Redo保证事务提交后,即使修改数据未写入磁盘,可以按照Redo日志重新写入。
原因:日志是连续数据,采用缓存和多线程并发写入,相比数据更快写入磁盘。
Undo & Redo
数据库通常借助日志来实现事务,常见的有undo log、redo log,undo/redo log都能保证事务特性,这里主要是原子性和持久性,即事务相关的操作,要么全做,要么不做,并且修改的数据能得到持久化。
- undo log是把所有没有COMMIT的事务回滚到事务开始前的状态,系统崩溃时,可能有些事务还没有COMMIT,在系统恢复时,这些没有COMMIT的事务就需要借助undo log来进行回滚。也就是说:针对所有未COMMIT的日志,根据undo log来进行回滚。
- redo log是指在回放日志的时候把已经COMMIT的事务重做一遍,对于没有commit的事务按照abort处理,不进行任何操作。也就是说:针对所有已COMMIT的日志,根据redo log来进行重做。
undo/redo log 更灵活
Double Write Buffer (相当于脏页写两遍)
InNo DB中,redolog配合Double Write Buffer 实现高可用性。极端情况下,当写入磁盘脏页时发生断电,只写入了4KB,未全部写入,磁盘页已经被破坏,是难以仅通过ReDoLog恢复的。所以设计了Double Write Buffer ,在写入脏页之前,首先要复制到Double Write Buffer中,
1、如果此时断电,未完全写入,那么磁盘中的页面是好的,完全可以借助ReDoLog恢复;
2、如果磁盘写入脏页的过程中断电,虽然这时候不能用ReDoLog恢复,但是Double Write Buffer中还有好的脏页,可以继续执行脏页写入。
session
也叫回话,表示一个客户端与服务端建立的连接,这个连接中有可能发生多个事务。
Toast
写入比特流数据或大数据时,行中放一个类似指针的东西,完整放在另一个单独的TOAST表或外部磁盘介质中。在TOAST表中数据被切割成若干个chunk,每个chunck以一个数据行的形式存放。
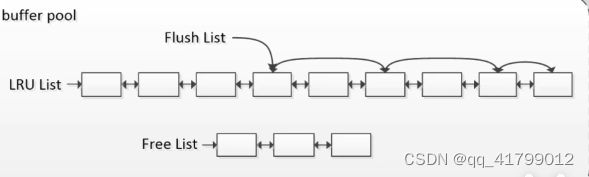
脏页
指内存中已经被修改的页,表示与物理介质上信息不一样的页。一般来说,数据修改后的脏页并不会立刻刷入硬盘,只有日志才会写入。脏页之间会形成一条链表,在恰当的时机写入硬盘。
fsync
功能介绍
实现方式详细介绍
调用fsync函数会将修改的数据和文件描述符的属性持久化到存储设备中
事务快照机制CSN
对于事务的隔离等级 未提交读,提交读,可重复读和串行化。
默认的隔离等级就是提交读,要实现这个需要在事务查询时获取一个快照CSN号,然后去遍历所有元组时,主要通过一个Map(key:事务号 x_id,value: CSN号->随时间不断推进)来判断可见性。当然也有一个算法流程,见判断可见性参考链接。
在PG中,实现可重复读时是在事务开始前获得一个快照CSN号,而后事务中所有的查询、修改等都使用这个CSN来判断可见性。从逻辑上来说,这样其实已经实现了串行化,但是并不是真正意义上的串行执行事务,事务还是可以并发的,只是从事务的执行结果上表现出串行化的效果。
HOT(heap only tuple)
视频链接
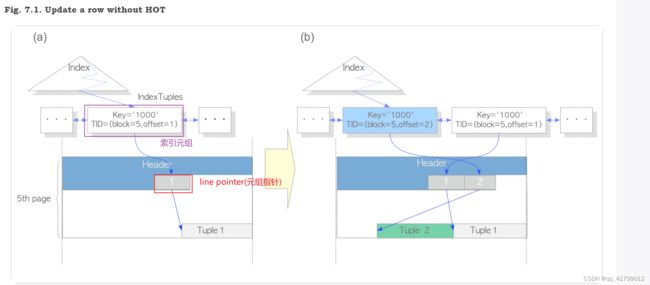
line pointer(元组指针)和索引元组的区别:
“索引元组”(index tuple)是指在索引结构中的一个条目,用于表示索引的键值和指向对应数据行的指针。索引元组是在创建索引时生成的,它包含了索引键的值以及对应数据行的物理位置信息。
line pointer 实际上是一个指向堆表的物理位置的指针。它包含了一些元数据,如该行所在的页号和偏移量等信息,以便能够准确定位到该行的位置。
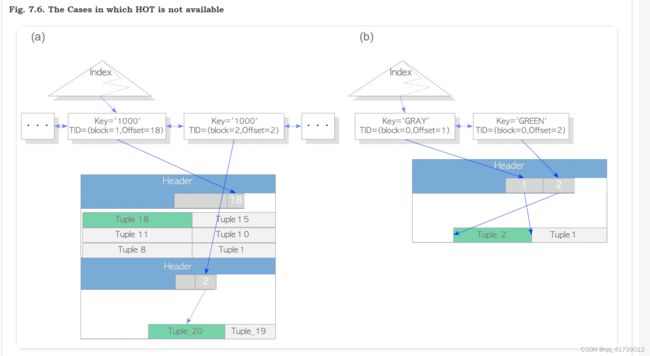
优点:
当非索引列更新时,索引页可以不用增加,直接修改堆表中元组的xmin和xmax,然后修改其后继指针指向新的元组。如果不适用HOT,那么每次非索引列更新时还需要增加索引元组,消耗索引页的空间,为VACCUM带来更大的开销。
不足之处:
(a)索引列更新时不可避免还是会增加索引元组;
(b)当存放的新旧元组在两个不同的页面,那么还是会增加索引元组。
不同元组的区别
在PostgreSQL中,DEAD和RECENTLY_DEAD是用于描述MVCC(多版本并发控制)中行版本状态的术语。它们表示在表中的不同状态的行版本。以下是它们之间的区别:
DEAD:
DEAD行版本表示已经被标记为删除的行。
当执行DELETE或UPDATE操作时,PostgreSQL并不会立即从磁盘中删除或修改相应的行,而是将其标记为DEAD状态。
DEAD行版本占据着空间,但不再被查询或事务使用。
在后续的VACUUM操作中,DEAD行版本将被回收并释放所占用的空间。
RECENTLY_DEAD:
RECENTLY_DEAD行版本表示最近被标记为删除的行。
在某些情况下,例如执行UPDATE操作并设置逻辑重写标志(logical rewrite),会将行版本标记为RECENTLY_DEAD而不是立即标记为DEAD。
RECENTLY_DEAD行版本和DEAD行版本的区别在于,RECENTLY_DEAD行版本可能在一段时间内仍然可见,直到相应的VACUUM操作运行并回收该行版本。
在MVCC的环境中,当一个事务读取数据时,它只能看到其启动时间之前提交的事务所做的更改,因此,DEAD和RECENTLY_DEAD行版本对于事务的可见性是不同的。在一般情况下,RECENTLY_DEAD行版本可能会在VACUUM运行之前在某些查询中可见,但DEAD行版本则不可见。一旦VACUUM运行并回收了这些行版本,它们将不再对任何事务可见。
index scan & index only scan
在 PostgreSQL 中,“index scan” 和 “index only scan” 是两种不同的索引访问方法,用于加速查询操作。它们的区别主要在于是否需要回表操作。
Index Scan(索引扫描):
在使用 Index Scan 时,查询需要根据索引的键值来检索符合条件的行。PostgreSQL 将使用索引中的键值进行查找,并获取对应的行指针(line pointer)。然后,通过回表操作(retrieval),访问表的物理存储来获取满足查询条件的行数据。
Index Only Scan(仅索引扫描):
Index Only Scan 是一种更高效的索引访问方法,它避免了回表操作。当查询的列都包含在索引中时,PostgreSQL 可以直接从索引中获取所需的列值,而无需进一步访问表的物理存储。这种方式可以提高查询性能,减少额外的磁盘 I/O。
需要注意的是,Index Only Scan 仅在满足以下条件时才能使用:
查询只涉及到索引包含的列。
索引类型支持 Index Only Scan(例如 B-tree)。
表没有未定义长度类型(如 text)或长字段(如 varchar(max))。
备份
数据库备份通常分为冷备份(Cold Backup)和热备份(Hot Backup),它们在备份数据时的操作状态和要求方面有所不同。
冷备份(Cold Backup):
冷备份是在数据库处于关闭状态下进行的备份。在进行冷备份时,数据库系统会被完全停止,所有的数据库进程都被终止,然后备份数据库文件。由于数据库没有在运行,所以数据的一致性得到了保证,备份过程中不会有其他活动干扰。冷备份适用于小型数据库或可以在停机期间进行备份的环境。优点是备份过程稳定,没有并发问题,但缺点是需要停机时间,不适合高可用性要求。
热备份(Hot Backup):
热备份是在数据库正常运行时进行的备份。这种备份方式不需要停止数据库,可以在数据库运行时复制数据。为了确保备份数据的一致性,热备份通常需要数据库管理系统提供支持,以确保在备份过程中没有数据修改。热备份适用于需要实时性和高可用性的场景,但备份过程需要确保数据一致性,可能会对数据库性能产生轻微影响。
总之,冷备份在数据库停止状态下进行,确保数据一致性,但需要停机时间。热备份在数据库运行状态下进行,适用于需要实时性和高可用性的环境,但需要确保备份过程不影响数据一致性和系统性能。选择哪种备份方式取决于数据库的特定需求、业务优先级和可用性要求。
两阶段锁
PG中使用严格的两阶段锁,在数据处理阶段只申请锁,不释放锁。
在事务提交阶段,只释放锁,不申请锁。
分布式数据库存储和处理
CN(Coordinator Node)
Coordinator Node(协调节点)是负责协调和管理整个数据库集群的节点
DN(Data Node)
在分布式数据库系统中,Data Node(数据节点)是存储和处理实际数据的节点。它是分布式数据库架构中的一部分,负责存储和管理数据库中的数据。
每个Data Node都包含一部分数据库的数据和相应的处理能力。这些节点可以分布在不同的物理服务器或计算节点上,构成一个分布式数据库集群。
2PC(两阶段提交)
参考链接
一个协调者,多个参与者。将事务提交过程分为两个阶段,准备阶段和提交阶段。
在InNoDB 中,binLog担任协调者,redoLog担任参与者,准备阶段写入redoLog,提交阶段写入BinLog。
宕机时的处理:
