【面试专题】Java核心基础篇①
个人主页:个人主页
系列专栏:Java面试专题
目录
1.面向对象的三大特性?分别解释下?
2.介绍一下Java的数据类型
3.说一说重写与重载的区别
4.说一说你对static关键字的理解
5.static修饰的类能不能被继承?
6.static和final有什么区别?
7.this 和 super 在 Java 中的含义是什么
8.使用字符串时,new和""推荐使用哪种方式?
9. String、StringBuilder、StringBuffer 的区别是什么?
10.String类有哪些方法?
11.String可以被继承吗?
12.说一说你对字符串拼接的理解
13.两个字符串相加的底层是如何实现的?
14.String a = "abc"; ,说一下这个过程会创建什么,放在哪里?
15.new String("abc") 是去了哪里,仅仅是在堆里面吗?
1.面向对象的三大特性?分别解释下?
面向对象编程的三大特性是封装、继承和多态。
-
封装:封装是将数据和行为组合在一起,形成一个相对独立的个体,即对象。对象对外部世界隐藏了其内部的实现细节,只暴露出一些公共接口,外部世界只能通过这些接口来访问对象的状态和行为。
-
继承:继承是指一个子类可以继承父类的属性和方法,从而不需要重新定义相同的内容。子类可以在继承的基础上增加新的属性和方法,也可以重写父类的方法,实现个性化的功能。
-
多态:多态是指同一个行为具有多个不同表现形式或形态的能力,Java 中有两种多态的实现形式:继承和接口。比如 List list=new ArrayList()这种写法就是多态的一种实现,从代码上来看,就是父类的对象变量调用了子类或者调用了接口实现类。
总的来说,面向对象编程的三大特性可以提高代码的复用性、可维护性和可扩展性,使得代码更加灵活、易于理解和修改。
扩展阅读
Java 是一款面向对象的语言,Java 语言的最重要三大特征是:封装、继承、多态。这三大特性也是面试官最喜欢问刚毕业程序员的第一个问题,因此这个问题十分重要。
封装
封装指的是把一个对象属性私有化,同时提供一些可以给外界访问该属性的方法。比如写一个类时会用 private 修饰属性,用 public 修饰的 set 和 get 方法提供外界访问和修改属性的方法。
Java语言为我们提供了三种访问修饰符,即private、protected、public,在使用这些修饰符修饰目标时,一共可以形成四种访问权限,即private、default、protected、public,注意在不加任何修饰符时为default访问权限。
-
private:该成员可以被该类内部成员访问;
-
default:该成员可以被该类内部成员访问,也可以被同一包下其他的类访问;
-
protected:该成员可以被该类内部成员访问,也可以被同一包下其他的类访问,还可以被它的子类访问;
-
public:该成员可以被任意包下,任意类的成员进行访问。
继承
继承是指使用已经存在的类作为基础建立新的类。
-
子类拥有父类的所有属性和方法,但是父类中的私有属性和方法子类无法访问。
-
子类可以拥有自己的属性和方法。
多态
多态是指同一个行为具有多个不同表现形式或形态的能力,Java 中有两种多态的实现形式:继承和接口。最常见的一种多态就是 List 集合了
List list=new ArrayList()上面的代码就是多态的一种实现形式。从代码上来看,就是父类的对象变量调用了子类或者调用了接口实现类。
Java 中多态的实现需要具备三个必要条件:继承、重写以及向上转型。
- 继承:多态中需要存在有继承关系的父类和子类,或是类与接口之间的实现关系。
- 重写:子类对父类中的某些方法进行重写,当调用这些方法时就会调用子类中的方法。
- 向上转型:多态中需要将子类的引用赋给父类对象。
以动物为例,首先定义所有动物的公共父类 Animal
public class Animal {
private String message;
public Animal(String message) {
this.message = message;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public void talk(){
System.out.println("动物的叫声");
}
}创建继承了 Animal 类的 Dog 类,该类调用父类构造方法,重写 talk 方法。
public class Dog extends Animal {
public Dog(String talk) {
super(talk);
}
@Override
public void talk() {
System.out.println("狗的叫声:"+super.getMessage());
}
}创建继承了 Animal 类的 Cat 类,该类调用父类构造方法,重写 talk 方法。
public class Cat extends Animal {
public Cat(String message) {
super(message);
}
@Override
public void talk() {
System.out.println("猫的叫声:"+super.getMessage());
}
}在 Main 方法中分别使用多态的调用方式生成 Dog 和 Cat 对象
public static void main(String[] args) {
Animal dog=new Dog("汪");
Animal cat=new Cat("喵");
dog.talk();
cat.talk();
}执行上述代码,输出结果如下:
狗的叫声:汪
猫的叫声:喵多态的作用是消除类型间的耦合关系,以上面的代码为例,多态不仅简化了代码,当要增加新的功能时,只需要新建一个类继承父类即可,不用修改其他类的代码,增强代码的扩展能力。
2.介绍一下Java的数据类型
Java数据类型包括基本数据类型和引用数据类型两大类。
基本数据类型有8个,可以分为4个小类,分别是整数类型(byte/short/int/long)、浮点类型(float/double)、字符类型(char)、布尔类型(boolean)。其中,4个整数类型中,int类型最为常用。2个浮点类型中,double最为常用。另外,在这8个基本类型当中,除了布尔类型之外的其他7个类型,都可以看做是数字类型,它们相互之间可以进行类型转换。
引用类型就是对一个对象的引用,根据引用对象类型的不同,可以将引用类型分为3类,即数组、类、接口类型。引用类型本质上就是通过指针,指向堆中对象所持有的内存空间,只是Java语言不再沿用指针这个说法而已。
扩展阅读
对于基本数据类型,你需要了解每种类型所占据的内存空间,面试官可能会追问这类问题:
-
byte:1字节(8位),数据范围是 -2^7 ~ 2^7-1。
-
short:2字节(16位),数据范围是 -2^15 ~ 2^15-1。
-
int:4字节(32位),数据范围是 -2^31 ~ 2^31-1。
-
long:8字节(64位),数据范围是 -2^63 ~ 2^63-1。
-
float:4字节(32位),数据范围大约是 -3.4*10^38 ~ 3.4*10^38。
-
double:8字节(64位),数据范围大约是 -1.8*10^308 ~ 1.8*10^308。
-
char:2字节(16位),数据范围是 \u0000 ~ \uffff。
-
boolean:Java规范没有明确的规定,不同的JVM有不同的实现机制。
对于引用数据类型,你需要了解JVM的内存分布情况,知道引用以及引用对象存放的位置,详见JVM部分的题目。

3.说一说重写与重载的区别
重载发生在同一个类中,若多个方法之间方法名相同、参数列表不同,则它们构成重载的关系。重载与方法的返回值以及访问修饰符无关,即重载的方法不能根据返回类型进行区分。
重写发生在父类子类中,若子类方法想要和父类方法构成重写关系,则它的方法名、参数列表必须与父类方法相同。另外,返回值要小于等于父类方法,抛出的异常要小于等于父类方法,访问修饰符则要大于等于父类方法。还有,若父类方法的访问修饰符为private,则子类不能对其重写。
扩展阅读
重载指的是同样的方法名可以接受不同的参数类型和参数数量,以及给出不同的结果。比如下面的这段代码就是重载的实现:
public class Basic {
public int getBasicInfo(int a){
return a;
}
public String getBasicInfo(String a){
return a;
}
}重写指的是子类继承父类后,对同样的方法名有自己的处理逻辑,就可以重写父类的方法,重写方法时需要注意:
-
方法名和参数名必须相同;
-
子类方法返回值类型应比父类方法返回值类型更小或相等,子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等;
-
子类方法的访问权限应比父类方法的访问权限更大或相等。
同样通过一个代码例子展示重写:
public class Father {
public String talk(String something){
return something;
}
}
public class Son extends Father {
@Override
public String talk(String something) {
return "son:"+something;
}
}Son 类继承了 Father 类,重写了 talk 方法。
重载和重写的异同点如下:
| 重写 | 重载 | |
|---|---|---|
| 应用场景 | 必定是父类与子类之间 | 通常在本类中 |
| 方法名 | 必须相同 | 必须相同 |
| 参数类表 | 必须相同 | 必须不相同 |
| 返回类型 | 子类方法返回类型应比父类更小或相等 | 没有特殊要求 |
| 抛出的异常 | 子类方法声明抛出的异常类应比父类更小或相等 | 没有特殊要求 |
4.说一说你对static关键字的理解
在Java类里只能包含成员变量、方法、构造器、初始化块、内部类(包括接口、枚举)5种成员,而static可以修饰成员变量、方法、初始化块、内部类(包括接口、枚举),以static修饰的成员就是类成员。类成员属于整个类,而不属于单个对象。
对static关键字而言,有一条非常重要的规则:类成员(包括成员变量、方法、初始化块、内部类和内部枚举)不能访问实例成员(包括成员变量、方法、初始化块、内部类和内部枚举)。因为类成员是属于类的,类成员的作用域比实例成员的作用域更大,完全可能出现类成员已经初始化完成,但实例成员还不曾初始化的情况,如果允许类成员访问实例成员将会引起大量错误。
扩展阅读
static
通常来说,通过 new 创建一个对象时,这个对象的存储空间才会被分配,这个时候对象里的方法才能被调用。但是有的时候会有这样一种需求,希望在没有创建对象的时候,也能访问这个类里的方法或者变量,这种情况下就可以使用 static 关键字。
static 关键字修饰的方法一般会被称为类方法或者静态方法,static 关键字修饰的变量一般会被称为类变量或者静态变量。被 static 修饰的类和方法属于这个类,而不属于由这个类生成的某个对象,可以通过类名.静态变量和类名.静态方法名访问这些成员。
比如在写工具类的时候,我们一般会把工具类中的方法声明成 static,这样可以直接通过类名调用,而不需要每次调用时都去创建一个工具类对象:
public class StringUtil {
public static final char[] HEX_DIGITS = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F' };
public static String toHexString(byte[] b) {
StringBuilder sb = new StringBuilder(b.length * 2);
for (int i = 0; i < b.length; i++) {
sb.append(HEX_DIGITS[(b[i] & 0xf0) >>> 4]);
sb.append(HEX_DIGITS[b[i] & 0x0f]);
}
return sb.toString();
}
}
被 static 修饰的代码块称为静态代码块,静态代码块只会执行一次。
5.static修饰的类能不能被继承?
static修饰的类可以被继承。
扩展阅读
如果使用static来修饰一个内部类,则这个内部类就属于外部类本身,而不属于外部类的某个对象。因此使用static修饰的内部类被称为类内部类,有的地方也称为静态内部类。
static关键字的作用是把类的成员变成类相关,而不是实例相关,即static修饰的成员属于整个类,而不属于单个对象。外部类的上一级程序单元是包,所以不可使用static修饰;而内部类的上一级程序单元是外部类,使用static修饰可以将内部类变成外部类相关,而不是外部类实例相关。因此static关键字不可修饰外部类,但可修饰内部类。
静态内部类需满足如下规则:
-
静态内部类可以包含静态成员,也可以包含非静态成员;
-
静态内部类不能访问外部类的实例成员,只能访问它的静态成员;
-
外部类的所有方法、初始化块都能访问其内部定义的静态内部类;
-
在外部类的外部,也可以实例化静态内部类,语法如下:
外部类.内部类 变量名 = new 外部类.内部类构造方法();
6.static和final有什么区别?
static关键字可以修饰成员变量、成员方法、初始化块、内部类,被static修饰的成员是类的成员,它属于类、不属于单个对象。以下是static修饰这4种成员时表现出的特征:
-
类变量:被static修饰的成员变量叫类变量(静态变量)。类变量属于类,它随类的信息存储在方法区,并不随对象存储在堆中,类变量可以通过类名来访问,也可以通过对象名来访问,但建议通过类名访问它。
-
类方法:被static修饰的成员方法叫类方法(静态方法)。类方法属于类,可以通过类名访问,也可以通过对象名访问,建议通过类名访问它。
-
静态块:被static修饰的初始化块叫静态初始化块。静态块属于类,它在类加载的时候被隐式调用一次,之后便不会被调用了。
-
静态内部类:被static修饰的内部类叫静态内部类。静态内部类可以包含静态成员,也可以包含非静态成员。静态内部类不能访问外部类的实例成员,只能访问外部类的静态成员。外部类的所有方法、初始化块都能访问其内部定义的静态内部类。
final关键字可以修饰类、方法、变量,以下是final修饰这3种目标时表现出的特征:
-
final类:final关键字修饰的类不可以被继承。
-
final方法:final关键字修饰的方法不可以被重写。
-
final变量:final关键字修饰的变量,一旦获得了初始值,就不可以被修改。
扩展阅读
final
final 作为 Java 中的关键字可以用于三个地方。用于修饰类、类属性和类方法。
特征:凡是引用 final 关键字的地方皆不可修改!
-
修饰类:表示该类不能被继承;
-
修饰方法:表示方法不能被重写;
-
修饰变量:表示变量不能被修改。
修饰变量:
final 修饰变量后这个变量不能被修改,这个不能被修改的说法对于不同的数据类型有不同的含义。
首先对于 8 个基本数据类型,当使用 final 修饰时,初始化后这个值是不会变的。
如果使用 final 修饰引用类型数据时,表示该引用初始化后永远指向一个地址,而这个地址里的对象属性是可以修改的。
final User user=new User("javayz",23);
user.setAge(18);
在上面一段代码中,用 final 修饰了自定义的 user 对象,但 user 对象中的值依旧可以被修改。
修饰方法:
final 修饰方法的作用是让方法无法被重写,这里没有太多额外的内容
修饰类:
当使用 final 修饰类的时候表明这个类不能被继承,被修饰的类所有成员方法都会被隐式地修饰为 final 方法。
7.this 和 super 在 Java 中的含义是什么
this 关键字表示当前对象,在一个对象内部,可以通过 this.xxx 去访问该对象的属性或者方法。super 关键字可以理解为指向自己父类对象的指针,可以从子类访问父类的属性和方法。
扩展阅读
this
this 关键字表示当前对象,在一个对象内部,可以通过 this.xxx 去访问该对象的属性或者方法。很多人刚开始学 Java 的时候,写的第一个类的 set 方法就会用到 this 关键字:
public class User {
private String name;
private String address;
public void setName(String name) {
this.name = name;
}
public void setAddress(String address) {
this.address = address;
}
}
表示当前这个对象的 name 变量等于 setName 方法传入的 name 参数。
super
super 关键字可以理解为指向自己父类对象的指针,可以从子类访问父类的属性和方法,比如:
public class User {
private String name;
private String address;
public void doSomething(){
System.out.println("User do something");
}
}
public class UserDetail extends User {
void superInfo(){
super.doSomething();
}
}
由于 this 和 super 都是调用对象实例中的属性和方法,因此this 和 super 都不能用在 static 方法中。
8.使用字符串时,new和""推荐使用哪种方式?
先看看 "hello" 和 new String("hello") 的区别:
-
当Java程序直接使用 "hello" 的字符串直接量时,JVM将会使用常量池来管理这个字符串;
-
当使用 new String("hello") 时,JVM会先使用常量池来管理 "hello" 直接量,再调用String类的构造器来创建一个新的String对象,新创建的String对象被保存在堆内存中。
显然,采用new的方式会多创建一个对象出来,会占用更多的内存,所以一般建议使用直接量的方式创建字符串。
扩展阅读
关于字符串常量池
字符串常量池是虚拟机中的内容,但是接下来的几个问题需要用到,就简单了解下。为了让 String 字符串可以复用,Java 虚拟机中设置了一种叫做字符串常量池的东西。
Java 为了避免产生大量的 String 对象,设计了一个字符串常量池。工作原理是这样的,创建一个字符串时,JVM 首先为检查字符串常量池中是否有值相等的字符串,如果有,则不再创建,直接返回该字符串的引用地址,若没有,则创建,然后放到字符串常量池中,并返回新创建的字符串的引用地址。因此看下面这段代码:
String s1="abc";
String s2="abc";
System.out.println(s1==s2); //返回true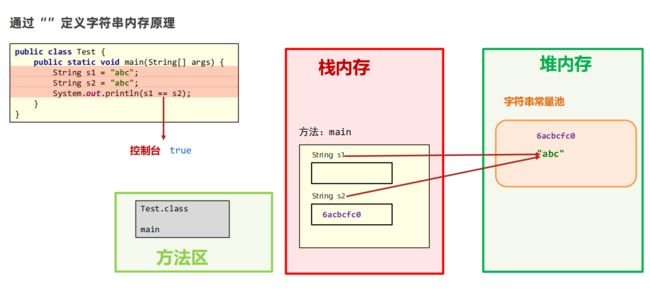
返回的结果就是 true,因为指向了同一个对象。
关于字符串常量池的位置,在不同版本的 JDK 中有所不同:
JDK1.7 之前字符串常量池属于运行时常量池的一部分,存放在方法区。
JDK1.7 之后字符串常量池被从方法区拿到了堆中。
String str 和 new String()有什么区别
String str 和 new String()有什么区别?区别在于,String str 创建的字符串保存在字符串常量池中,并且可复用。new String()创建的字符串按照最标准的对象创建方式,生成在堆中,并且一个 new String 会在堆中创建一个对象。
通过“”定义字符串内存原理
通过new构造器得到字符串对象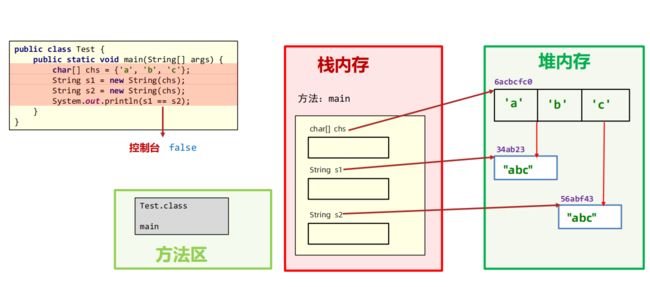
9. String、StringBuilder、StringBuffer 的区别是什么?
String 类中使用 final 关键字修饰字符数组来保存字符串(Java9 以前),因为使用了 final 修饰符,因此 String 是不可变的。每次改变 String 类型的值时,会生成一个新的 String 对象,然后将指针指向新的 String 对象。
StringBuilder 和 StringBuffer 都是继承 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串,但是没有用 final 关键字修饰,所以这两种对象都是可变的。StringBuffer 对字符串的一些操作方法加上了同步锁,因此是线程安全的.
StringBuilder 没有对方法加锁,因此是线程不安全的。
扩展阅读
String 应该是 Java 中最常用的一个对象,他不是八种基本数据类型的其中之一,但是随便翻了一下项目代码,用 String 定义的变量超过百分之八十。

关于 String 的几个基本知识点在 String 类的源码定义中就能看到:
-
在 JDK8 中,String 实例的值是通过 char 数组存储的。(JDK9 时,String 实例的存储由 char 变成了 byte 数组,原因是使用 byte 数组可以减少一半的内存)
-
String 类被 final 修饰,因此 String 不能被继承,value 变量被 final 修饰,因此 String 实例不能被修改
-
String 类实现了 Serializable, Comparable, CharSequence 接口。
String、StringBuilder、StringBuffer 的区别
String 类中使用 final 关键字修饰字符数组来保存字符串(JDK 9 以前)
private final char value[]
JDK 9 之后使用 byte 数组保存字符串
private final byte[] value
因为使用了 final 修饰符,因此 String 是不可变的。每次改变 String 类型的值时,会生成一个新的 String 对象,然后将指针指向新的 String 对象。
StringBuilder 和 StringBuffer 都是继承 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串,但是没有用 final 关键字修饰,所以这两种对象都是可变的。
StringBuffer 对字符串的一些操作方法加上了同步锁,因此是线程安全的。
StringBuilder 没有对方法加锁,因此是线程不安全的。
StringBuilder 相比 StringBuffer 提升约 10%-15% 的速度。
10.String类有哪些方法?
String类是Java最常用的API,它包含了大量处理字符串的方法,比较常用的有:
-
char charAt(int index):返回指定索引处的字符;
-
String substring(int beginIndex, int endIndex):从此字符串中截取出一部分子字符串;
-
String[] split(String regex):以指定的规则将此字符串分割成数组;
-
String trim():删除字符串前导和后置的空格;
-
int indexOf(String str):返回子串在此字符串首次出现的索引;
-
int lastIndexOf(String str):返回子串在此字符串最后出现的索引;
-
boolean startsWith(String prefix):判断此字符串是否以指定的前缀开头;
-
boolean endsWith(String suffix):判断此字符串是否以指定的后缀结尾;
-
String toUpperCase():将此字符串中所有的字符大写;
-
String toLowerCase():将此字符串中所有的字符小写;
-
String replaceFirst(String regex, String replacement):用指定字符串替换第一个匹配的子串;
-
String replaceAll(String regex, String replacement):用指定字符串替换所有的匹配的子串。
注意事项
String类的方法太多了,你没必要都记下来,更不需要一一列举。面试时能说出一些常用的方法,表现出对这个类足够的熟悉就可以了。另外,建议你挑几个方法仔细看看源码实现,面试时可以重点说这几个方法。
11.String可以被继承吗?
String类由final修饰,所以不能被继承。
扩展阅读
在Java中,String类被设计为不可变类,主要表现在它保存字符串的成员变量是final的。
-
Java 9之前字符串采用char[]数组来保存字符,即 private final char[] value;
-
Java 9做了改进,采用byte[]数组来保存字符,即 private final byte[] value;
之所以要把String类设计为不可变类,主要是出于安全和性能的考虑,可归纳为如下4点。
-
由于字符串无论在任何 Java 系统中都广泛使用,会用来存储敏感信息,如账号,密码,网络路径,文件处理等场景里,保证字符串 String 类的安全性就尤为重要了,如果字符串是可变的,容易被篡改,那我们就无法保证使用字符串进行操作时,它是安全的,很有可能出现 SQL 注入,访问危险文件等操作。
-
在多线程中,只有不变的对象和值是线程安全的,可以在多个线程中共享数据。由于 String 天然的不可变,当一个线程”修改“了字符串的值,只会产生一个新的字符串对象,不会对其他线程的访问产生副作用,访问的都是同样的字符串数据,不需要任何同步操作。
-
字符串作为基础的数据结构,大量地应用在一些集合容器之中,尤其是一些散列集合,在散列集合中,存放元素都要根据对象的 hashCode() 方法来确定元素的位置。由于字符串 hashcode 属性不会变更,保证了唯一性,使得类似 HashMap,HashSet 等容器才能实现相应的缓存功能。由于 String 的不可变,避免重复计算 hashcode,只要使用缓存的 hashcode 即可,这样一来大大提高了在散列集合中使用 String 对象的性能。
-
当字符串不可变时,字符串常量池才有意义。字符串常量池的出现,可以减少创建相同字面量的字符串,让不同的引用指向池中同一个字符串,为运行时节约很多的堆内存。若字符串可变,字符串常量池失去意义,基于常量池的 String.intern() 方法也失效,每次创建新的字符串将在堆内开辟出新的空间,占据更多的内存。
因为要保证String类的不可变,那么将这个类定义为final的就很容易理解了。如果没有final修饰,那么就会存在String的子类,这些子类可以重写String类的方法,强行改变字符串的值,这便违背了String类设计的初衷。
12.说一说你对字符串拼接的理解
拼接字符串有很多种方式,其中最常用的有4种,下面列举了这4种方式各自适合的场景。
-
+ 运算符:如果拼接的都是字符串直接量,则适合使用 + 运算符实现拼接;
-
StringBuilder:如果拼接的字符串中包含变量,并不要求线程安全,则适合使用StringBuilder;
-
StringBuffer:如果拼接的字符串中包含变量,并且要求线程安全,则适合使用StringBuffer;
-
String类的concat方法:如果只是对两个字符串进行拼接,并且包含变量,则适合使用concat方法;
扩展阅读
采用 + 运算符拼接字符串时:
-
如果拼接的都是字符串直接量,则在编译时编译器会将其直接优化为一个完整的字符串,和你直接写一个完整的字符串是一样的,所以效率非常的高。
-
如果拼接的字符串中包含变量,则在编译时编译器采用StringBuilder对其进行优化,即自动创建StringBuilder实例并调用其append()方法,将这些字符串拼接在一起,效率也很高。但如果这个拼接操作是在循环中进行的,那么每次循环编译器都会创建一个StringBuilder实例,再去拼接字符串,相当于执行了 new StringBuilder().append(str),所以此时效率很低。
采用StringBuilder/StringBuffer拼接字符串时:
-
StringBuilder/StringBuffer都有字符串缓冲区,缓冲区的容量在创建对象时确定,并且默认为16。当拼接的字符串超过缓冲区的容量时,会触发缓冲区的扩容机制,即缓冲区加倍。
-
缓冲区频繁的扩容会降低拼接的性能,所以如果能提前预估最终字符串的长度,则建议在创建可变字符串对象时,放弃使用默认的容量,可以指定缓冲区的容量为预估的字符串的长度。
采用String类的concat方法拼接字符串时:
-
concat方法的拼接逻辑是,先创建一个足以容纳待拼接的两个字符串的字节数组,然后先后将两个字符串拼到这个数组里,最后将此数组转换为字符串。
-
在拼接大量字符串的时候,concat方法的效率低于StringBuilder。但是只拼接2个字符串时,concat方法的效率要优于StringBuilder。并且这种拼接方式代码简洁,所以只拼2个字符串时建议优先选择concat方法。
13.两个字符串相加的底层是如何实现的?
如果拼接的都是字符串直接量,则在编译时编译器会将其直接优化为一个完整的字符串,和你直接写一个完整的字符串是一样的。
如果拼接的字符串中包含变量,则在编译时编译器采用StringBuilder对其进行优化,即自动创建StringBuilder实例并调用其append()方法,将这些字符串拼接在一起。
14.String a = "abc"; ,说一下这个过程会创建什么,放在哪里?
JVM会使用常量池来管理字符串直接量。在执行这句话时,JVM会先检查常量池中是否已经存有"abc",若没有则将"abc"存入常量池,否则就复用常量池中已有的"abc",将其引用赋值给变量a。
15.new String("abc") 是去了哪里,仅仅是在堆里面吗?
在执行这句话时,JVM会先使用常量池来管理字符串直接量,即将"abc"存入常量池。然后再创建一个新的String对象,这个对象会被保存在堆内存中。并且,堆中对象的数据会指向常量池中的直接量。