顺序结构
-
- 基本概念
- 顺序表实现
- Arraylist类使用:
- 小小练习
基本概念
数据结构:描述和组织数据的方式。
数据结构的两种分类方式逻辑结构和物理结构:
逻辑结构:数据元素之间的相互关系;逻辑结构分以下四种。
1:集合;没有任何关系
2:线性结构:元素之间是一对一关系
数据结构的元素之间存在一对一线性关系,所有结点都最多只有一个直接前趋结点和一个直接后继结点。
3:树形结构;一对多
4:图形结构;多对多
物理结构(储存结构):是指数据在计算机内存或磁盘中的存储方式,包括顺序存储、链式存储、索引存储、散列储存等。
顺序储存结构:逻辑和物理地址上都连续;比如排队做核酸;我的位置在前一个人后面;我确确实实在这个位置上。
链式储存结构:逻辑上连续;物理上不一定连续;比如老师点名确定人数情况;2号同学在一号后面;但是他两并不需要按照顺序坐
顺序表实现
1:创建一个顺序表;用数组的方式实现;我们new一个对象就自动创建
2:功能1;打印顺序表
3:功能2;末尾增加元素(细节:如果满了则无法增加;需要扩容;那首先需要一个判断满的方法;还可以增加一个求顺序表长度的功能。)
4:功能3;任意位置插入元素;(细节:还得看是否满;还要判断这个位置是否合法,有没有是负数、有没有是超出范围。插入在前面你还得把后面数据往后移)
5:功能4;判断是否包含某个元素;查询某个元素下标(细节:空的时候就无法查找到;但是这里得注意;如果是引用类型不能直接用==比较;得用equls或者比较器等等)
6:获取pos下标元素(细节:pos的合法性;顺序表空的时候无法获取)
6:功能5;替换元素(细节:空的时候没法替换)
7:功能6;删除第一次出现元素;删除全部的key元素;删除某位置元素(细节:空的时候没法删除;可以利用刚才查找元素的方法知道位置;删除后面往前移就好了)(删除全部;找一个删一个;直到找完为止)
8:功能7;清空顺序表(useSize=0;标记删除;就跟我们计算机硬盘;你删除一个东西不经过回收站;只是标记删除;我们也还是能恢复的;反正你也不用这一块空间;当你要用的时候自然就覆盖掉删除的东西。我们数组反正空间已经创建了;你最多把这个数组全部元素置0)
import java.util.Arrays;
public class test1 {//顺序表的实现
public static void main(String[] args) {
//通过new对象创建这个数组;通过这个对象的方法对这些数组进行操作
arrays a1=new arrays();
a1.add(1);
a1.add(1);
a1.add(1);
a1.add(1);
a1.add(1);
a1.add(1);
a1.display();
}
}
class arrays{
public int useSize;
// 记录顺序表有效数据的长度;初始值0
public int []arr;
// 创建全局变量是为了下面方法能使用这个;如果在构造方法里创建;出了方法别的方法就无法使用
public arrays() {
this.arr=new int[10];
// 默认初始容量是10;
}
public int size(){//获取顺序表长度
return useSize;
}
public void display(){//打印顺序表
for (int i = 0; i <useSize ; i++) {
// 这里不能是arr.length;因为不是全部都是有效元素。
System.out.println(arr[i]);
}
}
public boolean isFull(){//判满
if(useSize>=arr.length){
return true;
}
else return false;
// 可以更直接返回return size()>=arr.length
}
public void add(int key){//末尾增加元素
if(isFull()){
System.out.println("顺序表已满;马上扩容");
arr= Arrays.copyOf(arr,2*arr.length);
}
arr[useSize]=key;
useSize++;
}
public void addevery(int pos,int key){//任意位置插入元素;还得判满和是否扩容;可以把这里写成方法;方便代码复用
if(isFull()){
System.out.println("顺序表已满;马上扩容");
arr= Arrays.copyOf(arr,2*arr.length);
}
if(pos<0||pos>=useSize){
//这里可以使用抛异常的方式处理
System.out.println("输入的位置不合法;插入失败");
return;
}
else {//把pos后面数据往后移;这里使用后面先移;就能避免前面先移然后覆盖掉后面的数据
for (int i = useSize; i >pos ; i--) {
arr[i+1]=arr[i];
}
arr[pos]=key;
useSize++;
}
}
public boolean isnull(){
if(useSize==0){
return true;
}
return false;
}
public boolean select(int key){//判断是否包含元素
if(isnull()){
return false;
}
for (int i = 0; i <useSize ; i++) {
if(arr[i]==key){
System.out.println("嘿嘿;找到啦");
return true;
}
}
return false;
}
public int selectindexof(int key){//查找包含的元素
if(isnull()){
return -1;
}
for (int i = 0; i <useSize ; i++) {
if(arr[i]==key){
System.out.println("嘿嘿;找到啦");
return i;
}
}
return -1;
}
public int get(int pos){//获取pos下标元素
if(isnull()){
return -1;
}
if(pos<0||pos>=useSize){
//这里可以使用抛异常的方式处理
System.out.println("输入的位置不合法;获取失败");
return -1;
}
return arr[pos];
}
public void set(int pos,int key){//替换pos下标元素
if(isnull()){
return ;
}
else {
arr[pos]=key;
}
}
public void delete(int key){//删除第一次出现的key元素;
if(isnull()){
System.out.println("嘿嘿嘿;空的;无法删除");
return ;
}
int pos= selectindexof(key);
for (int i =pos ; i <useSize ; i++) {
arr[i]=arr[i+1];
}
useSize--;
}
public void delete_every(int key){//删除所有出现的key元素;
if(isnull()){
System.out.println("嘿嘿嘿;空的;无法删除");
return ;
}
for (int i = 0; i <useSize ; i++) {//知道这些元素的位置
if (arr[i] == key) {
for (int j=i ; j <useSize ; j++) {
arr[j]=arr[j+1];
}
useSize--;
}
}
}
public void delete1(int pos){//删除pos下标元素
for (int i =pos ; i <useSize ; i++) {
arr[i]=arr[i+1];
}
}
public void clean(){
useSize=0;
}
}
Arraylist类使用:
点开源码;看到源码是这样子创建的顺序表;这样子定义是属于类的,只有一份,不可修改。

源码的图形简化版;底层还是没那么简单的;最重要List接口。java集合类一般在until包里。实现Cloneable接口;可以被克隆的。实现RandomAccess接口;是可以随机访问。实现Serializable是支持序列化(序列化是啥意思;在redis揭秘)。可以动态扩容;线程不安全。

三个构造方法:
无参构造:ArrayList() 默认10容量大小;(这里的泛型;先实例化对象才能使用;我们增加的类型要对应)
有参构造:
ArrayList(int initialCapacity) : int initialCapacity 构造根据你指定的初始容量的空顺序表
ArrayList(Collection c):该构造方法创建一个包含指定集合中的元素的ArrayList对象。它将集合c中的元素复制到新的ArrayList中,元素的顺序将按照集合的迭代器返回顺序进行存储。

ArrayList(int initialCapacity)内部实现:

当直接打印这个对象的时候会发现;打印的确不是地址的哈希值。只能说明它重写to string方法
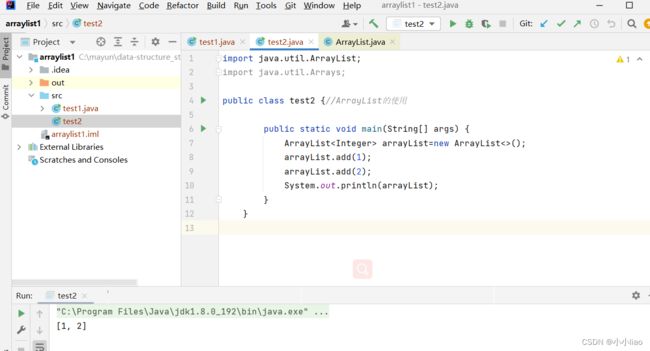
在他父亲的父亲继承的这个方法

找到这个方法

有参构造:Collectionc;根据你这里的集合构建列表;利用这里的迭代器确定的顺序返回。实现collectio接口就能传进去。这里是通配符的上界;传过去的类型一定是E或者E的子类。String不是Integer的子类类型,所以接收不了。
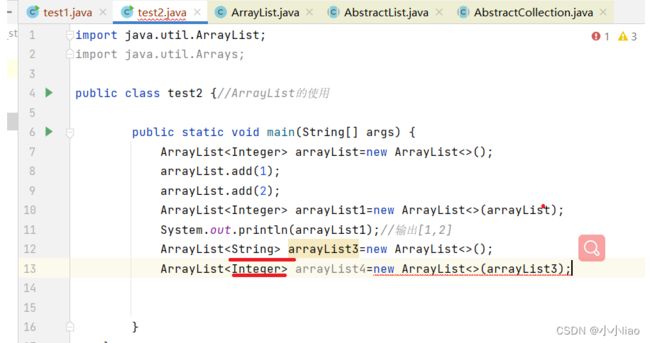
我们创建对象时并没有真真正正的去创建10容量大小的数组;而是当你第一次进行add才分配大小为10的内存。这里面套娃套的很深。当放的超过10个就会进行1.5倍扩容。(类似操作系统概念讲到懒汉模式)
常见操作:
增加
1:boolean add(E e);尾插元素e;类型得要和创建时指定的要一样;返回的结果是否插入成功。
2:void add(int index, E e)指定位置插入
3:boolean addAll(Coection e)尾插c的元素
4:E remove(int index)删除index位置的元素;返回的结果是这个被删除的元素
5:Boolean remave(Object o)删除第一个遇到的o。删除这里得注意;你得把要删除的类型转成E;因为你单纯的填int 类型7;都会被当成下标处理。

6:E get(int index) 获取index位置的元素
7:E set(int index,E e) 把index位置的元素设置为e;返回的结果是被替换原来的值
8:void clear() ;清空
9:boolean contains(Object o); 判断o是否在线性表中
10:int indexOf(Object o)返回第一个o的下标
11:int lastindexOf(Object o)返回最后一个o的下标
12:list.size();求顺序表长度
13:List subList(int fromIndex,int tolndex); 截取这个部分的list。注意这个截取并没有重新创建新的;而是在原来的找。所以比如:
1,2,3, 4,5现在截取1到3;左开右闭;[1,2)。取到的是下标1和下标2。现在将这个截取的部分0下标改成99;发现原来的顺序表的这个元素对应位置也被改了;因为它两是同一块地方。


这里Object和E的区别;Object是什么类型的都可以;E你就得是我们创建时指定类型或者是它的子类。
遍历打印顺序表:
1:Integer重写to string方法;直接打印会出现结果
2:foreach
3:for i循环
4:迭代器;前提得实现iterable接口。就是我们源码简化图最上面的那个
迭代器是啥呢?Iterator接口;可以用来遍历没有索引的集合。
常用方法:
boolean hasNext();判断有没有下一个元素;如果有就返回true;没有返回false
E next()返回/取出下一个元素。
remove()把迭代器返回的元素删除
这个接口的获取方式比较特殊;我们通过Collection接口中的一个方法(list实现这个接口;直接用后面这个方法获取就行了),叫做iterotor(),这个方法返回的就是迭代器的实现对象。

import java.util.ArrayList;
import java.util.Iterator;
public class test4 {
public static void main(String[] args) {
ArrayList<Integer> list=new ArrayList<>();
list.add(0);
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
list.add(6);
list.add(7);
System.out.println(list);
System.out.print("[");
for (int i:list //遍历时把每个元素放在i里;然后操作;取出时会进行拆包
) {
System.out.print(i+", ");
}
System.out.println("]");
for (int i = 0; i <list.size() ; i++) {
System.out.print(list.get(i)+" ");
}
System.out.println();
Iterator<Integer> it=list.iterator();//先创建一个迭代器变量;(使用list.ListIterator也行;返回值类型是ListIterator;ListIterator是Iterator的子类;用Iterator接收,发送向上转型)
while (it.hasNext()){//判断有没有下一个
System.out.print(it.next()+" ");//获取这个next元素时;it会往后走一步
}
}
}
迭代器的remove方法;我们在使用顺序表时删除元素。可能会使用for循环删除某个元素。
比如我们想删除list所有的2;但是如果元素相邻重复的情况删除就会出现删除失败。数组删除某个元素时,后面所有元素的索引都会往前移,for循环的指针是却是往后移动。(就像你我双向奔赴;但是擦肩而过;双方都没坦白)
import java.util.ArrayList;
public class test5 {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < 5; i++) {
list.add(i);
list.add(i);
}
System.out.println("删除前:" + list);
for (int i = 0; i < list.size(); i++) {
if(list.get(i).equals(2)){
list.remove(i);
}
}
System.out.println("删除后:" + list);
}
}
发现重复的只能删除一个然后跳一个。

使用迭代器删除所有的2:
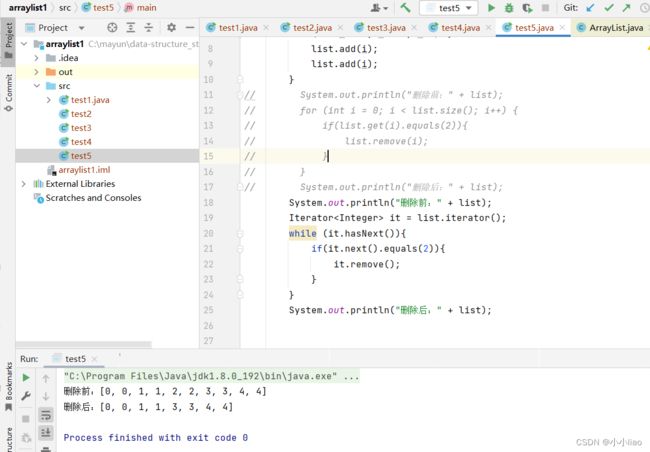
迭代器这里迭代的时候是不允许使用集合对象去删除,添加,清空集合存储的对象时,那么就程序就会报出异常。
public class IteratorTest {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>(Arrays.asList("a","b","c","d"));
Iterator<String> iter = list.iterator();
while(iter.hasNext()){
String s = iter.next();
if(s.equals("a")){
list.remove(0);
// iter.remove();
}
}
}
}

扩容机制:
会检测是否真正需要扩容,如果是调用grow准备扩容。最大21亿4千多,不能超过,超过就调用这个函数进行其它操作,给你纠正;不需要你手动去扩;扩容之前它都会检测一下;防止太大而扩容失败。初步预估按照1.5倍大小扩容;如果用户所需大小超过预估1.5倍大小,则按照用户所需大小扩容。底层还是很多套娃的。
小小练习
1:泛型不仅仅局限于基本类型和包装类类型;还能是自定义类型。比如:要储存学生的数学成绩信息;有姓名;年龄;分数
import java.util.ArrayList;
public class test6 {
public static void main(String[] args) {
Student s1=new Student(18,"张三",98);
Student s2=new Student(19,"李四",96.5);
Student s3=new Student(19,"王五",90.5);
ArrayList<Student> list=new ArrayList<>();
list.add(s1);
list.add(s2);
list.add(s3);
System.out.println(list);
}
}
class Student{
int age;
@Override
public String toString() {//自定义类型可不像Integer源码重写to string 方法;所以我们得自己重写
return age+" "+name+" "+score+" ";
}
String name;
double score;
public Student(int age,String name,double score ) {
this.age=age;
this.name=name;
this.score=score;
}
}
2:对上述的信息;进行成绩由高到低排序。这里不能使用Arrays.sort;这个是数组使用的;我们的ArrayList是集合类。但是ArrayList也有专门的Collections.sort来排序。使用的前提是要有实现compare接口,重写compare to方法;不然你用什么比较呢;是用年龄还是分数、姓名字母排序。
import java.util.ArrayList;
import java.util.Collections;
public class test6 {
public static void main(String[] args) {
Student s1=new Student(18,"张三",98);
Student s2=new Student(19,"李四",99.5);
Student s3=new Student(19,"王五",95.5);
ArrayList<Student> list=new ArrayList<>();
list.add(s1);
list.add(s2);
list.add(s3);
System.out.println("排序前");
System.out.println(list);
Collections.sort(list);
System.out.println("排序后");
System.out.println(list);
}
}
class Student implements Comparable<Student>{
int age;
@Override
public String toString() {//自定义类型可不像Integer源码重写to string 方法;所以我们得自己重写
return age+" "+name+" "+score+" ";
}
String name;
double score;
public Student(int age,String name,double score ) {
this.age=age;
this.name=name;
this.score=score;
}
@Override
public int compareTo(Student o) {
return (int)(o.score-this.score);//这里具体谁是谁;一测试就知道结果;谁调用 谁就是this
}
}
3:字符串 str1:“liao yu wang” str2:" ctrl"。删除第一个字符串中出现的第二个字符串的字符。输出结果:iao yu wang。使用集合。
思路:第一想法把str1存入顺序表;每取一个和str2的全部对比查看。那为什么还要存进去然后再取出来对比呢;直接对比发现没有内鬼就一个一个放进去不香吗。创建字符类型。把空格也得当字符放进去。
import java.util.ArrayList;
public class test7 {//铲除字符串1中存在的字符串2的字符
public static void main(String[] args) {
funs("liao yu wang", "ctrl");
}
public static ArrayList<Character> funs(String str1,String str2){
ArrayList<Character> list1=new ArrayList<>();
int x=0;
for (int i = 0; i <str1.length() ; i++) {
for (int j = 0; j <str2.length() ; j++) {
if(str1.charAt(i)==str2.charAt(j)){//有内鬼;终止交易
x=1;
break;
}
}
if(x==1){
x=0;
continue;
}
list1.add(str1.charAt(i));
//走到这里都能没内鬼;把它加入到组织;空格也要加入组织。
}
//打印结果
for (int i = 0; i <list1.size() ; i++) {
System.out.print(list1.get(i));
}
return list1;
}
}
我这里的写法就有点捞了;把得到的字符再去遍历字符串2一个一个找有没有相同的;而这个方法直接就能查找这个字符串是否包含一个子字符串;虽然我们这里是字符;但是加个" "就能转成字符串。

简洁的写法:如果发现没内鬼就立马给拉入组织。

向上转型:虽然内容变窄;但是向上转型有其优点;比如能把类型统一;然后放一块。
