linux&shell编程基础
目录
一、安装环境
二、基础篇
2.1 文件系统
2.1.1 bin目录
2.1.2 sbin
2.1.3 lib
2.1.4 lib64
2.1.5 usr
2.1.6 boot
2.1.7 dev
2.1.8 etc
2.1.9 home
2.1.10 root
2.1.11 opt
2.1.12 media
2.1.13 mnt
2.1.14 proc
2.1.15 run
2.1.16 srv
2.1.17 sys
2.1.18 tmp
2.1.19 var
2.2 VIM编辑器
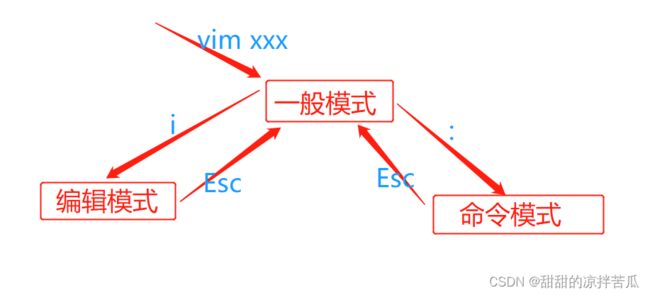
2.2.1 vim的3种模式及相互转换
2.2.2 一般模式
1、对行操作
2、对一个单词的操作
3、对单个字符的操作
4、整页操作
2.2.3 编辑模式
2.2.4 命令模式
2.3 网络配置
2.3.1 网络连接测试
2.3.2 网络连接模式
2.3.3 修改静态IP
2.3.4 配置主机名
2.4 远程登录
2.5 系统管理
2.5.1 Linux服务管理
1、CentOS 7 语法
2.5.2 系统运行级别
1、开机自启动设置
2、查看当前Linux系统的运行级别
3、切换Linux系统运行级别
2.5.3 配置服务开机启动和关闭防火墙
1、 配置服务的自启动设置
CentOS6
CentOS7
2、 防火墙的开机自启动
2.5.4 关机重启
1、shutdown
2、几种关机的命令
3、保险的关机操作
三、实操篇
3.1 shell命令整体介绍
3.1.1 man 命令
3.1.2 type 命令
3.1.3 help 命令
3.1.4 常用快捷键
3.2 文件&目录操作命令
3.2.1 查看和切换工作目录
1、pwd命令
2、cd
3.2.2 ls列出目录内容
3.2.3 创建和删除目录
1、mkdir 创建文件夹
2、rmdir 删除目录
3.2.4 touch创建文件
3.2.5 cp复制文件或文件夹
3.2.6 rm 删除和mv移动文件/目录
1、rm删除文件和目录
2、mv移动文件和目录
3.2.7 查看文件
1、cat
2、more
3、less
3.2.8 控制台显示和输出重定向
1、echo输出到控制台
2、输出重定向 > 和 追加 >>
3.2.9 监控文件变化
1、head显示文件头部内容
2、tail 输出文件尾部内容
3.2.10 软链接ln
1、创建软链接
2、删除软链接
3、硬链接
3.2.11 history查看历史命令
3.3 时间日期操作命令
3.3.1 date 获取当前时间编辑
3.3.2 date 获取非当前时间编辑
3.3.3 date 设置系统时间
3.3.4 cal 查看日历
3.4 用户权限
3.4.1 添加和查看用户
1、useradd 添加用户
2、id 查看用户是否存在
3、查看当前Linux系统有多少用户cat /etc/passwd
4、在会话窗口切换用户 su
3.4.2 获取root权限和删除用户
1、获取root权限
2、userdel删除用户
3.4.3 用户组管理
1、groupadd 新增组
查看Linux系统有哪些组
更改用户的主要组
给用户账号添加辅助组
删除用户账号的某个辅助组
2、groupmod 用户组重命名
3、groupdel 删除组
3.4.4 文件属性和权限
3.4.5 更改文件权限
1、chmod 修改文件权限
2、chown修改文件的属主
3、chgrp 修改文件的属组
3.4.6 案例
3.5 搜索查找
3.5.1 查找定位文件
1、find 查找文件/目录
2、locate 快速文件定位
3、which 查找
4、whereis 查找
3.5.2 内容过滤查找grep和管道过滤|
1、内容过滤查找grep
2、管道过滤 |
3.6 压缩解压
3.6.1 gzip 压缩文件和 gunzip 解压文件
3.6.2 zip压缩和unzip解压缩
3.6.3 tar打包
3.7 磁盘管理
3.7.1 查看目录占用空间大小
1、安装tree
2、查看目录树
3、du 查看文件和目录占用的磁盘空间
3.7.2 df 查看磁盘使用情况
3.7.3 lsblk 查看设备挂载情况
3.7.4 mount挂载和umount卸载
1、mount
2、umount卸载
3、设置开机自动挂载
3.7.5 fdisk 磁盘分区
3.8 进程管理
3.8.1 ps查看进程基本用法
1、列出带有终端的当前用户的进程
2、查看系统内的全部进程
3、查看指定进程
3.8.2 查看远程登录进程
3.8.3 kill 终止进程
3.8.4 pstree 查看进程树
3.8.5 top 实时监控进程
3.8.6 netstat 显示网络状态和端口占用情况
1、 列出所有端口 netstat -a
2、只显示监听端口 netstat -l
3、 显示所有端口的统计信息 netstat -s
4、显示核心路由信息 netstat -r
3.9 crontab 系统定时任务
3.9.1 重启crond服务
3.9.2 crontab 定时任务设置
1、查看当前用户有哪些定时任务 crontab -l
2、新建&编辑定时任务 crontab -e
四、扩展篇
4.1 软件包管理
4.1.1 RPM
1、rpm 查询当前系统安装软件
2、卸载软件rpm -e
3、安装软件rpm -i
4.1.2 YUM
2、卸载指定软件
3、安装指定软件
4、修改网络yum源
4.2 克隆虚拟机
4.2.1 克隆一个虚拟机
4.2.2 修改克隆虚拟机的ip
4.2.3 修改克隆虚拟机的主机名
4.3 shell编程
4.3.1 shell概念
4.3.2 shell脚本入门
1、脚本后缀
2、指定脚本使用的shell类型
3、脚本执行方法
4.3.3 系统预定义变量
4.3.4 用户自定义变量
4.3.5 全局变量、只读变量和撤销变量
1、export 定义全局变量
2、readonly 定义只读变量
3、unset 撤回变量
4.3.6 特殊变量
1、$n
2、$#
3、$* 和$@
4、$?
4.3.7 运算符
4.3.8 条件判断
1、字符串比较
2、数字比较
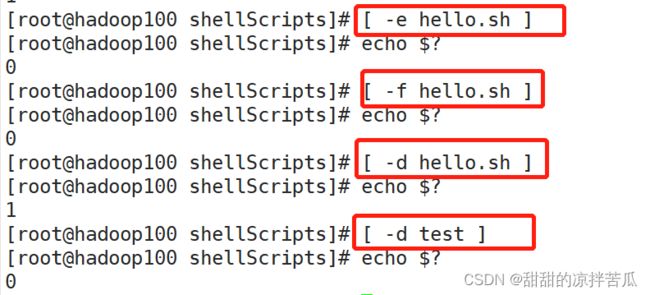
3、文件判断
4、多条件组合判断
4.3.9 if 单分支
4.3.10 if 多分支
4.3.11 case多分支
4.3.12 for循环
4.3.13 while循环
4.3.14 read 读取控制台输入
4.3.15 系统函数
1、basename
2、dirname
4.3.16 自定义函数
4.3.17 案例-归档文件
4.3.18 正则简单用法
1、常规匹配
2、常用特殊字符
4.3.19 正则扩展用法
4.3.20 文本处理工具cut
4.3.21 文本处理工具awk基本功能
4.3.22 文本处理工具awk扩展功能
4.3.23 案例-发送消息
一、安装环境
VMware:下载 VMware Workstation Pro | CN
centOS 7:Index of /CentOS/7.9.2009/isos/x86_64/

二、基础篇
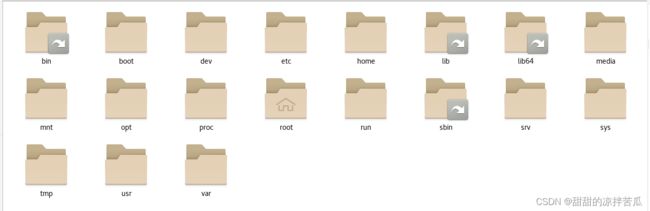
2.1 文件系统

2.1.1 bin目录
存放是可执行的二进制命令文件,普通用户可以执行
bin文件夹的外观和其他不一样,有一个外指的箭头

其实bin目录并不在根目录/下,鼠标右击选择‘属性’:

可以看到根目录下的bin其实是一个链接,它真正的位置是usr/bin, 可以去这个目录看下

可以看到usr下面确实存在一个bin文件夹。
同理其他文件夹有外指箭头的也都是一个链接
2.1.2 sbin
存放的是系统级的二进制命令文件,系统管理员才能够使用的命令
2.1.3 lib
存放的是系统和应用程序需要的一些共享库文件,不能随意删除
2.1.4 lib64
存放的是系统和应用程序一些特殊的64位的共享文件
2.1.5 usr
存储的是用户所需要的所有的应用程序和对应需要的文件数据
2.1.6 boot
存放系统启动所需的文件和核心文件,包括一些链接文件和镜像文件
2.1.7 dev
device 设备目录,存放所有设备的数据,每个设备都会映射对应文件,如cpu 硬盘disk等
2.1.8 etc
存放系统管理所需的配置文件和对应的子目录,如数据库相关的配置文件
2.1.9 home
Linux中每个用户(普通用户不是root管理员)自己的主目录,存放的是用户的个性化的数据和文件
2.1.10 root
存放系统超级用户(即root管理员)的主目录
2.1.11 opt
optional 可选目录,存放第三方软件包,如果需要安装额外的软件可以放在这个目录下
2.1.12 media
存放可移动媒体设备,如U盘 光驱等外接的媒体(其实就是外部存储)就挂载在media下,所以media就是外部可移动媒体设备的挂载点。
2.1.13 mnt
mount 也是外部移动存储设备的挂载点
2.1.14 proc
process 进程目录,是一个虚拟目录,相当于系统内存进程的一个映射文件目录,存放现有的硬件和进程信息。很重要的系统文件目录,不要随意删除内容
2.1.15 run
运行目录,存放的是当前系统运行以来的所有执行信息,是一个临时文件系统,系统重启就会被清空。最好不要动
2.1.16 srv
service 存放和系统服务相关的文件,不要动。
2.1.17 sys
system 存放系统硬件相关信息的文件,不要动
2.1.18 tmp
临时目录,存放临时需要存放的文件,可以删除腾出空间
2.1.19 var
可变目录,存放经常被修改的文件,一般存放日志文件
2.2 VIM编辑器
2.2.1 vim的3种模式及相互转换
命令模式下的命令:
退出vim编辑器 :q 回车
保存修改的内容 :w 回车
修改后:w 回车保存后,如果需要撤回刚才的修改 点击u
保存并退出编辑器 :wq 回车
vim xxx进入文件后,输入:set nu展示行号
输入:set nonu 就不再展示行号
2.2.2 一般模式
一般模式下 可以进行的操作:复制 粘贴 删除

1、对行操作
数字 p :在当前光标下一行粘贴 指定次数 复制内容
数字 yy :复制从当前光标这一行开始 n行 内容
数字 dd:删除从当前光标行开始 n行 内容
y$:复制从光标开始位置直到这一行末尾的全部内容(包括光标位置的字符)
y^:复制从这一行开头到当前光标位置之间的内容(不包括光标位置的字符)
d$:删除从光标开始位置直到这一行末尾的全部内容(包括光标位置的字符)
d^:删除从这一行开头到当前光标位置之间的内容(不包括光标位置的字符)
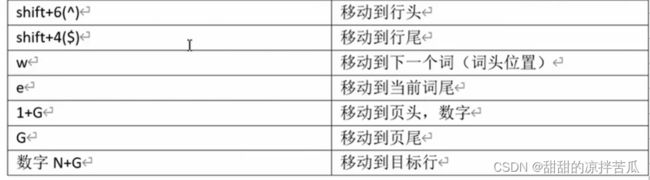
^:移动到当前行行头
$:移动到当前行行尾
2、对一个单词的操作
w:跳转到下一个单词,并且光标停留在单词的第一个字母
e:跳转到当前单词尾部(这里不考虑单词后面的空格),如果已经在一个单词的末尾字母,则会跳转到下一个单词的末尾字母
b:跳到当前单词的词头(这里不考虑单词后面的空格),如果已经在单词词头了,就跳到上一个单词的词头
yw:复制从当前光标开始到这个单词结束(包含光标停留位置的字母)
dw:删除从当前光标开始到这个单词结束(包含光标停留位置的字母),如果光标停留的位置不是单词的第一个字母那就不是完整删除这个单词,每个单词后面都有一个空格,复制yw、删除dw时也会包含最后面那个空格
3、对单个字符的操作
x:剪切光标所在字符
X:剪切当前光标左侧的一个字符
r:按一次r选中当前光标所在字符,表示要替换它,再按一次r会把上一次剪切的那个字符粘贴在这里;或者不按第二次r直接输入一个字符进行替换
R:按一次R表示要替换从当前光标开始到行末尾的字符,之后可以自行输入内容,按Esc退出替换模式
4、整页操作
1+G:移动到整个文件的头部
H:移动到当前可视页第一行的头部
gg:移动到整个文件的头部
G:移动到整个文件的尾部
L:移动到当前可视页最后一行的头部
数字+G:移动到指定行的行头
2.2.3 编辑模式

2.2.4 命令模式

:%s/old/new/g 这个命令很常用
/要查找的内容 :查找指定内容并高亮突出,默认定位在从当前光标行向下查找匹配到的内容,按n向下查找,按N向上查找。
比如在27行输入/net,匹配的有 28、30行,则默认定位在30行的那个匹配内容上。
2.3 网络配置
2.3.1 网络连接测试
测试虚拟机和主机网络是否互通:
1、在Windows中打开cmd输入ipconfig命令,拿到主机IP
2、在虚拟机中打开终端 输入ping 主机IP
3、获取虚拟机IP的方法
1)系统工具——设置——网络——有线(设置)查看虚拟机IP
2)终端输入ifconfig
第一个是虚拟机所处的局域网,名字ens33是Linux创建的
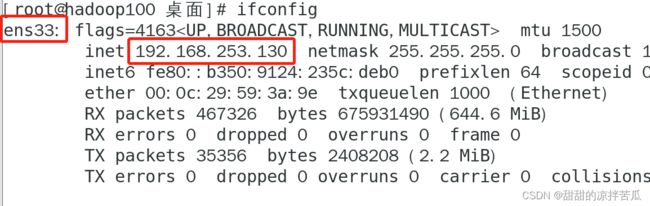
第二个是服务器的IP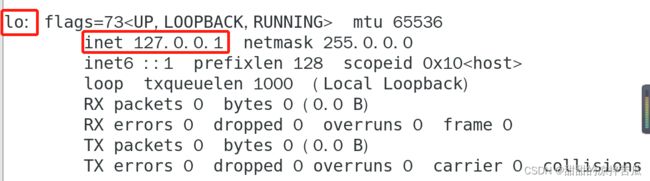
第三个是Linux又创建的一个虚拟网络,可用于接入其他虚拟设备,相当于主机里面套虚拟机,虚拟机里面又可以套虚拟机

4、去主机 打开cmd 输入:ping 虚拟机IP

至此主机和虚拟机的网络是互通的。
2.3.2 网络连接模式
在查看电脑的网络时,看到2个VMware的虚拟网络
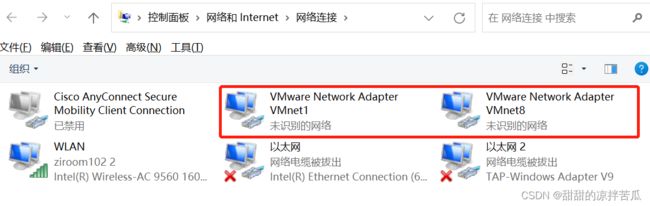
是什么意思 干什么用的呢
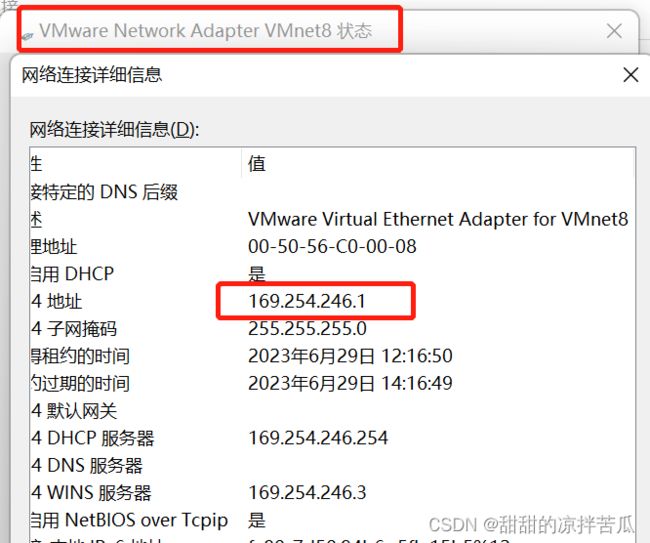
虚拟机的IP是:192.168.253.130 可以看下这2个网络的状态:
,

在虚拟机的终端验证下网络是否能连通,发现连通是ok的
在VMware点击虚拟机名称 右击选中【设置】


可以看到我们之前设置的网路连接模式是NAT模式
也可以在VMware总点击【编辑】——【虚拟网络编辑器】查看


最最重要!!!:保证以下红框内ip前3位一致 不然你的虚拟机就可能连不上物理主机和网络了
1)物理主机VMnet8 右击——状态——详细信息
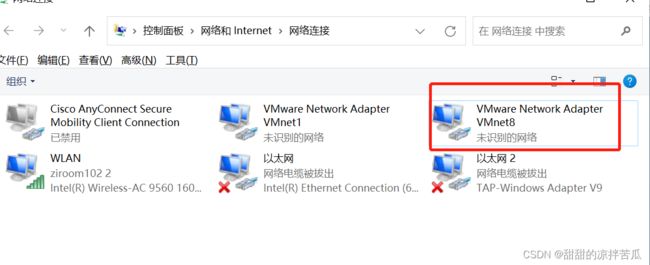

2)虚拟机
编辑——虚拟网络编辑器

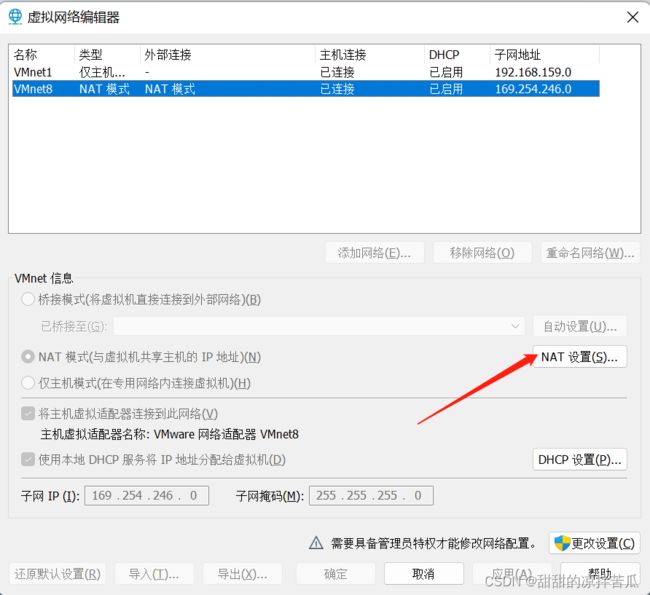

vim /etc/sysconfig/network-scripts/ifcfg-ens33
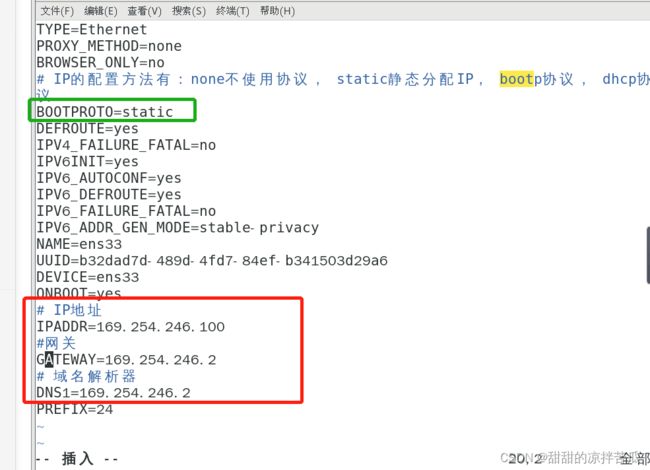
如果都做了 花还是不行,改下网关和DNS的最后一位数字,重启网络服务,试试物理主机 虚拟机 外网是否能连通
2.3.3 修改静态IP
把虚拟机的IP修改为固定的,当前使用的协议是dhcp 也就是动态分配IP

进入以太网配置文件:vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改IP配置协议
![]() 添加IP、网关和域名解析器
添加IP、网关和域名解析器

其他内容不用修改。
修改完成后需要重启网络服务:service network restart
![]()
之后输入ifconfig命令查看下虚拟机IP是否修改成功。

至此虚拟机的IP修改完成。
在主机的cmd中验证网络是否可用:

在虚拟机终端验证是否可以连接主机

验证虚拟机是否可以连接外网

可以看到虚拟机向外连接网络是没有问题的,主机连接虚拟机也是没问题的。
修改完成如果发现有ping不通的问题,可以按照如下步骤进行检查:

2.3.4 配置主机名
查看虚拟机主机名:hostname命令

修改虚拟机主机名:vim /etc/hostname
需改完成后需要重启虚拟机才能生效。
如果感觉重启虚拟机费时间,可以用如下方式:
查看虚拟主机相关信息:hostnamectl

设置新的虚拟主机名:hostnamectl set-hostname newname

再次查看虚拟主机名发现已经修改了 ,只是前面显示的还是之前的名字
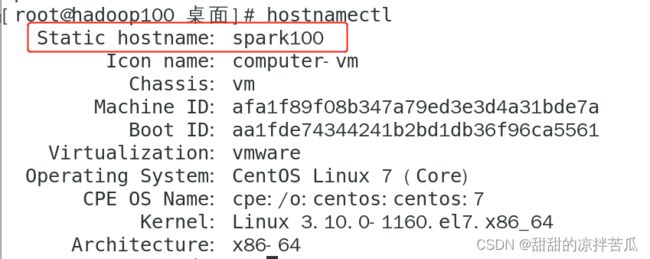
使用hostnamectl查看发现也已经生效了。
此时重新打开一个终端就会发现前面显示的就是最新的虚拟主机名了。

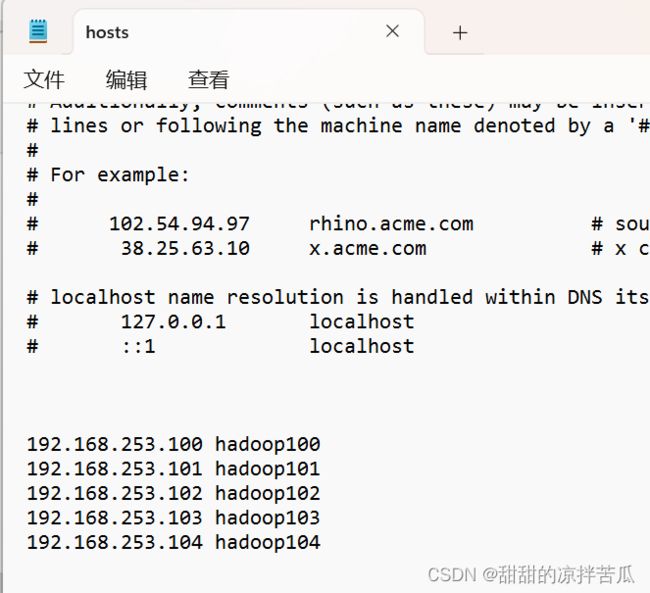
修改虚拟主机名后还需要修改hostname和IP的映射文件。
先在虚拟机中修改映射文件:![]()

复制新增的hadoop100~104 到物理机主机的映射文件

win10修改后不能直接保存,先另存为hosts.txt,之后删除文件后缀并把文件移动到etc目录下替换即可。
之后再物理主机cmd中ping以下hadoop100看是否可以连接
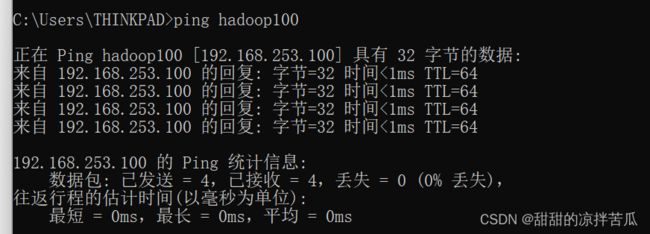
2.4 远程登录
Xshell 用于远程登录Linux服务器
Xftp7 用于远程传输文件
2.5 系统管理
2.5.1 Linux服务管理
前面虚拟机IP静态化中,修改完IP配置后需要执行service network restart命令重启网络服务,
其中service是一个命令,可以在 /usr/sbin/ 中找到这个service文件

先来理解概念:
1、进程:一个正在执行的程序或命令 process,如ls cd等命令
2、服务:启动之后一直存在、常驻内存的进程 service,如网络服务
Linux服务启动的时候需要很多服务支撑,一般在控制台是看不到这些服务的启动的,一般都是后台启动,系统运行期间这些服务会一直常驻内存,直到关闭系统这些服务才会关闭,这些服务统称为系统服务,执行这些服务的
进程就称为 守护进程。
1、CentOS 7 语法
systemctl start | stop | restart | status 服务名
ctl 其实是control的简写
在/usr/lib/systemd/system下面查看系统都有哪些服务
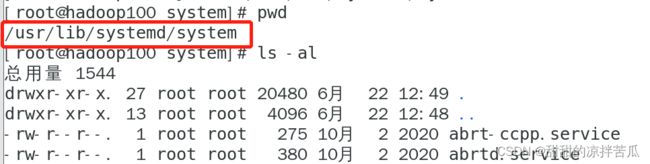
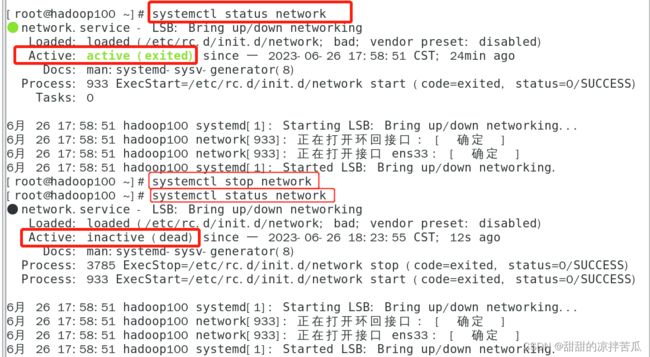
在CentOS7里使用NetworkManager服务替换了CentOS6里的network服务,可以通过命令:systemctl status network看下服务状态

使用systemctl status NetworkManager 看下服务状态

对于network和NetworkManager都是active状态时,肯会出现以下意想不到的问题,所以最好还是把其中一个停掉,因为目前使用的是CentOS7 所以保留NetworkManager,停掉network

之后如果看到虚拟机右上角的 
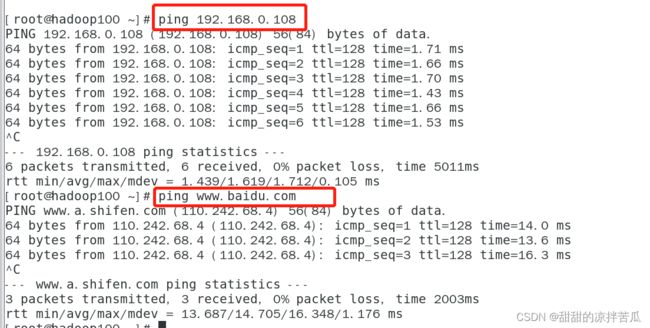
消失了,只需要在终端重启下NetworkManager即可,之后ping www.baidu.com验证下是否可以联网即可


还可以在物理主机cmd中验证是否可以连接虚拟机ping hadoop100

2.5.2 系统运行级别
1、开机自启动设置
在Linux系统终端输入setup 出现选择窗口
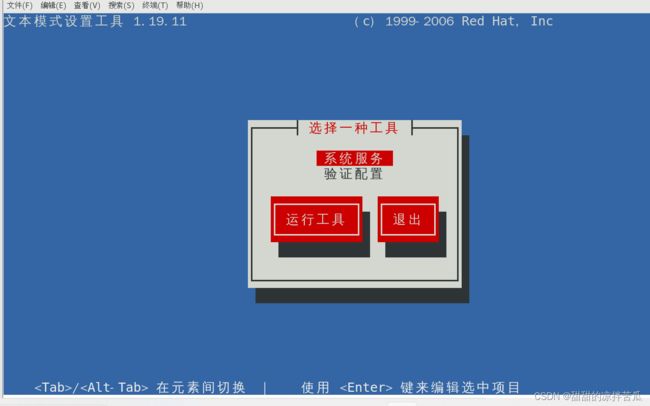
选择 系统服务 回车

每个服务名前面都有一个中括号,里面有的有星号有的没有 
有星号就表示这个服务是开机自启动的


2、查看当前Linux系统的运行级别
查看当前Linux系统的运行级别:systemctl get-default

更改Linux系统的运行级别:systemctl set-default multi-user.target
如果是CentOS6,查看Linux系统的运行级别,vim /etc/inittab 可以查看
3、切换Linux系统运行级别
如果想切换运行级别(当前是5切换为3):init 3
还可以使用快捷键:ctrl alt F2 切换为级别3 ctrl alt F1 切换回级别5
2.5.3 配置服务开机启动和关闭防火墙
1、 配置服务的自启动设置
CentOS6
chkconfig --list

可以看到这里只列出了system V 的服务,只有2个,里面的数字0 ~ 6指的就是在每个Linux系统级别下这个服务的自启动设置。
如果想关闭network服务的开机自启动,执行chkconfig network off
再次开启network 服务的开机自启动,执行chkconfig network on
指定某个Linux运行级别开启/关闭network的自启动,执行chkconfig --level 4 network on/off

CentOS7
查看服务的状态,执行systemctl status NetworkManager

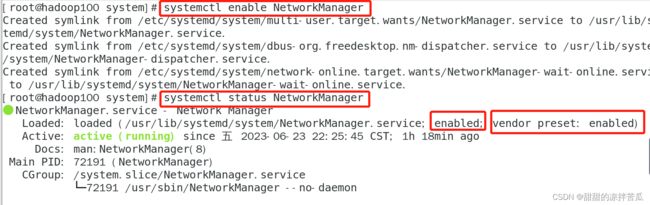
第一个是当前服务的开机自启动设置是什么,第二个是系统默认的这个服务的开机自启动设置时什么,可以看到现在NetworkManager现在的开机自启动是开启(enable),并且NetworkManager服务的开机自启动设置也是开启(enable)。
关闭服务的开机自启动设置,执行 systemctl disable NetworkManager

开启服务的开机自启动设置,执行systemctl enable NetworkManager
查看全部服务的开机自启动设置:systectl list-unit-files
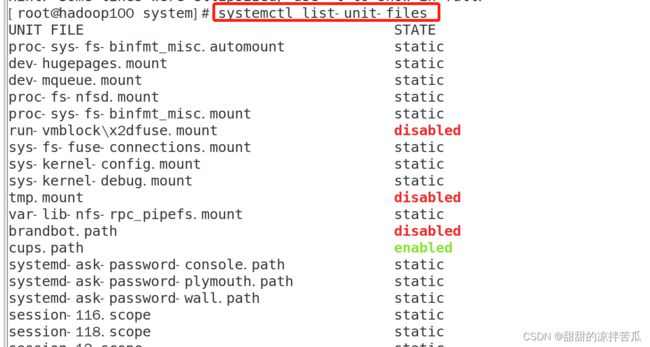
状态是static表示这个服务的启动依赖别的服务,所以部设置,只有当别额服务启动了这个才能启动。
2、 防火墙的开机自启动
先查看下防火墙服务的状态,执行systemctl status firewalld

可以卡到防火墙服务已开启active,并且当前的开机自启动设置是开启,系统默认的开机自启动也是开启,没有修改过。
关闭防火墙服务,执行systemctl stop firewalld

再次开启防火墙服务,systectl restart firewalld

关闭防火墙的开机自启动设置,执行systemctl disable firewalld
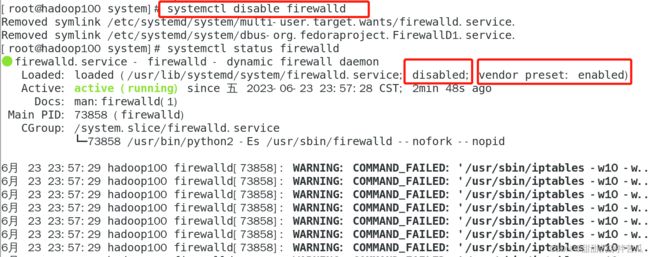
再次打开防火墙的开机自启动,执行systemctl enable firewalld

2.5.4 关机重启
1、shutdown
shutdown 等1分钟再关机
如果再1分钟内执行shutdown -c就可以取消关机操作
shutdown now 立刻关机
shutdown 数字x 在x分钟后关机
shutdown 15:28 制定了一个关机计划,在15:28:00关机
2、几种关机的命令


3、保险的关机操作
先sync保存缓冲区的数据到硬盘
然后执行shutdown或者poweroff
三、实操篇
3.1 shell命令整体介绍
3.1.1 man 命令
Manuel 简写
man 命令 可以查看这个命令的使用信息
如果这个命令是shell内嵌的命令,还需要加上-f 才能查看命令的使用
列出了关于这个命令解释的几个出处,数字1表示第一册,3tcl表示第3侧,1p中的p表示posix标准(基于Unix的可移植的软件开发标准协议)
使用man 1p cd 查看这个里面规定的cd的使用方法

![]()

3.1.2 type 命令
查看命令的类型,了解命令是内置的还是外调的

history命令——c查看使用过的命令历史

3.1.3 help 命令
使用help查看命令的使用文档可以看到比较简洁且重点的内容,方便我们快速学习如何使用命令。
help 命令名 ——只能查看shell内置命令的使用方法,而且解释文案都是英文的
查看外调的命令会提示没有这个命令

![]()
如果想使用help查看外调的命令,可以执行 命令名 --help
3.1.4 常用快捷键

3.2 文件&目录操作命令
3.2.1 查看和切换工作目录
1、pwd命令
print working directory 显示当前目录的绝对路径

2、cd
change directory
cd 绝对路径
cd 相对路径


使用cd - 在2个路径之间切换,cd - 就是回到上一次所在目录

回到当前用户主目录 使用cd

3.2.2 ls列出目录内容
list 简写
ls -a 显示全部的文件(包括隐藏文件和隐藏文件夹)
ls -l 按照行展示文件信息


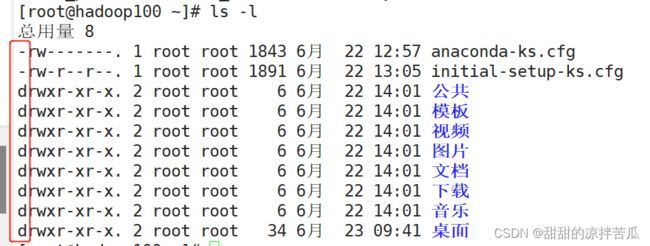
d表示文件夹 -表示文件
ls -l 和ll 实现效果一样

3.2.3 创建和删除目录
1、mkdir 创建文件夹
mkdir 文件夹名

同时创建多个文件夹,如果这几个文件夹是父子关系那么需要加-p参数,否则会报错



在指定目录创建文件夹

2、rmdir 删除目录
如果文件夹内非空 删除需要连带其内部文件,可以先清空里面的内容在删除文件夹,也可以使用rmdir -p 目标文件夹及其子目录

需要先清空文件夹 才能继续删除文件夹

可以使用rmdir -p a/c/ 是因为c是最里层的文件夹且c里面没有任何的文件,如果c里有文件就不能删除成功了
保险起见还是先进入里面一层一层的删除,最后在删除最外层的文件夹。
3.2.4 touch创建文件
touch 文件名 创建一个空文件
如果创建文件时没有指定文件类型,默认创建的是文本文件

打开文件随便输入内容,使用file 文件名可以查看这个文件的类型
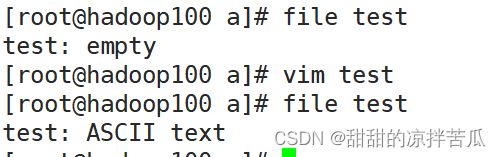
除了touch还可以使用vim 文件名创建文件,这个时候会自动打开vim编辑器,不管是否输入内容,执行保存退出(:wq)这个文件就创建成功了,如果是执行:q 或者:q! 就不会创建文件。
3.2.5 cp复制文件或文件夹
copy的简写

cp target address 把target复制到address里面,address可以是目录也可以是文件


如果不想Linux总是提醒确认可以使用 \cp

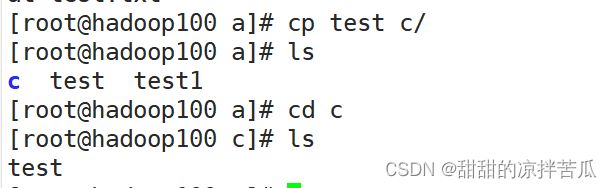
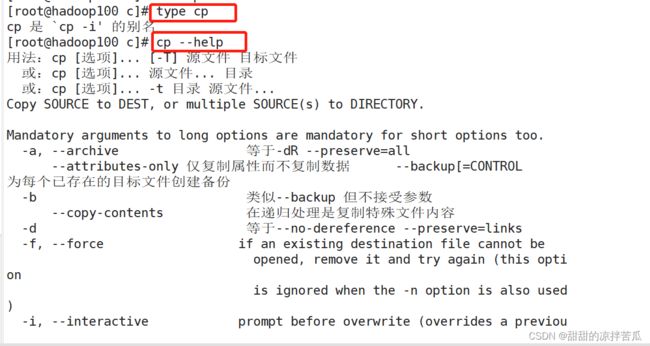
很多命令都是使用的别名,可以使用alias看下Linux系统中有哪些命令有别名

3.2.6 rm 删除和mv移动文件/目录
1、rm删除文件和目录

删除文件夹 如果文件夹里面有内容,Linux会依次询问是否要删除文件夹内部的每个文件,等文件夹内全部删除完 最后再询问是否要删除这个文件夹,比较谨慎 但很麻烦

使用-f可以强制删除,Linux不会再询问,但是要小心使用

2、mv移动文件和目录

移动并且重命名

只是重命名

只是移动

3.2.7 查看文件
1、cat
catch的简写

2、more
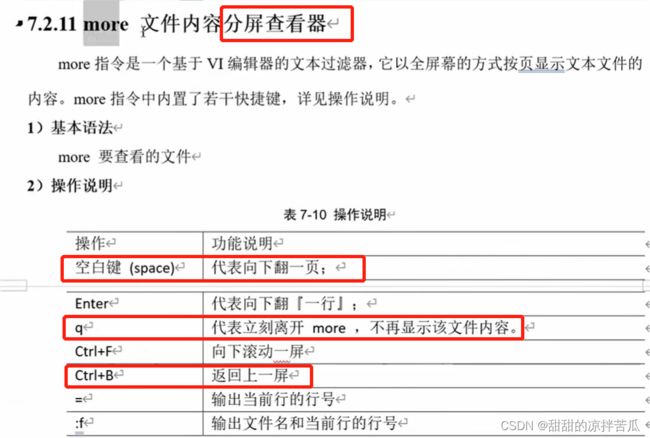
3、less

G:跳到文件末尾
g:跳到文件开头
3.2.8 控制台显示和输出重定向
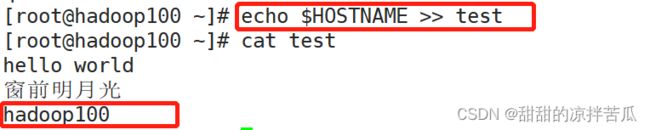
1、echo输出到控制台

使用引号后Linux会按照原样输出到终端

查看Linux系统有哪些环境变量:echo $ 按tab键
查看指定环境变量的值:echo 环境变量

2、输出重定向 > 和 追加 >>


追加内容到文件末尾
 直接覆盖文件内容
直接覆盖文件内容



3.2.9 监控文件变化
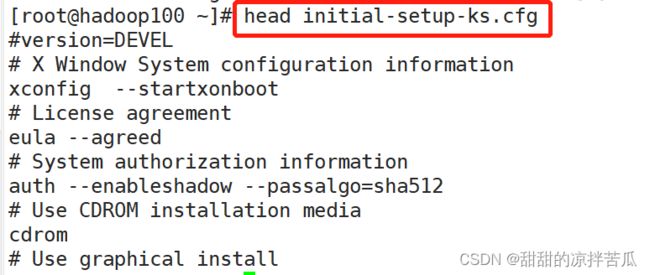
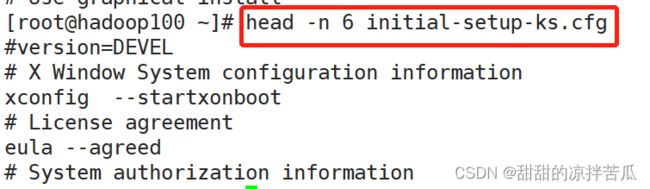
1、head显示文件头部内容

2、tail 输出文件尾部内容

使用tail -f 文件名
之后按ctrl s 可以暂停实时追踪
再按ctrl q 可以恢复追踪
ctrl c 退出
查看文件info的索引号 ls -i info

使用tail -f info进行文件内容实时追踪的时候使用的是文件的inode编号,类似索引
如果使用vim info打开文件进行编辑,之后再查看下info的inode编号可以发现和之前的不一样了,所以如果是通过vim进行文件的修改,tail -f info是追踪不到的,且即使:wq(关闭保存)后再使用echo进行内容追加fail也追踪不到了

3.2.10 软链接ln

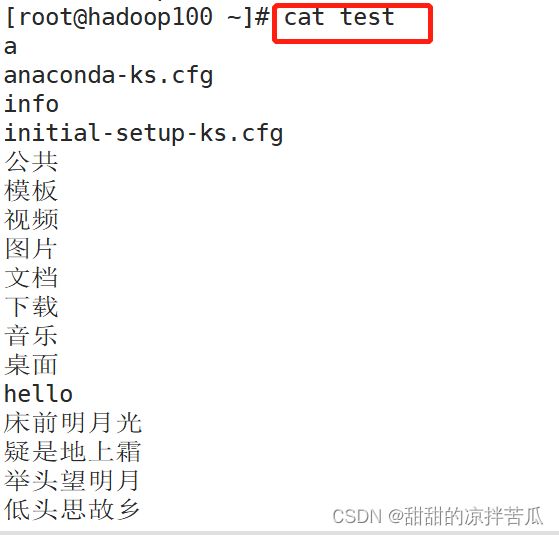
1、创建软链接
给文件创建软连接:ln -s info test
![]()
是l开头,并且会显示连接到哪里

对软连接操作其实就是对原文件操作,包括做任何修改
给目录创建软连接:



如果想要直到当前内容的实际物理位置可以使用pwd -P

如果想进入实际的物理目录不是软连接目录,可以使用cd -P 软连接名

2、删除软链接
rm -rf 软链接名
不管这个软链接对应的是文件还是目录,都使用软链接名,后面不要加/
对于目录软链接如果后面加/删除的不是软链接而是软链接下面的内容,就会导致原来目录下的内容被清空。

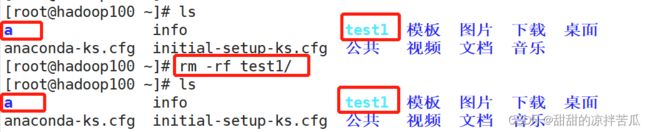


如果把原始文件/目录删除了,软链接显示会和之前不一样

 这里的a会一闪一闪的
这里的a会一闪一闪的
且再进入或者查看软链接时tab补齐功能就不能用了,手动输入软链接名回车,Linux就会提示找不到目标文件

3、硬链接
硬链接创建: ln 文件 链接名
软链接有自己的数据存储块,也就是有自己的inode,里面存储了链接其他文件/目录的路径
硬链接没有自己的数据块,直接指向了原始文件的inode

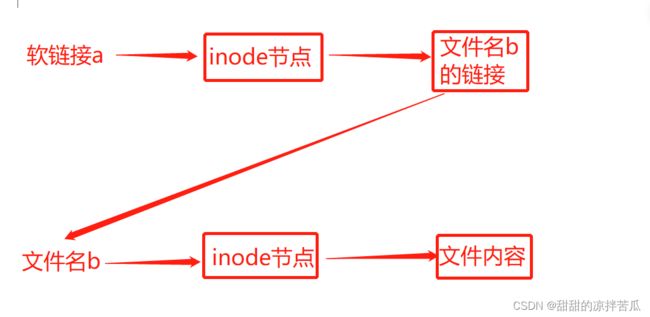
一般查看系统的链接数看的是硬链接的数量。
硬链接指向的文件的inode节点,所以只能针对文件创建硬链接,不能给目录创建硬链接。硬链接很少使用。
3.2.11 history查看历史命令

显示全部使用过的命令

显示最近使用的10条命令

查看第250条命令和它获取的结果内容

删除历史使用过的命令history -c

3.3 时间日期操作命令


3.3.1 date 获取当前时间
注意date后面有空格,加号+和选项之间没空格
获取当前时间的时间戳 date %s 一般会在日志中使用

3.3.2 date 获取非当前时间
数字可以是任意正负整数


根据想要换时间单位即可
3.3.3 date 设置系统时间

3.3.4 cal 查看日历


显示本月日历:cal

显示某一年的日历

显示某年某月的日历:cal 月数字 年数字

显示某年某月某日所在月的日历:cal 日 月 年

显示本月 上月 下月的日历:cal -3

3.4 用户权限
3.4.1 添加和查看用户
1、useradd 添加用户


普通用户添加后都会再/home下面创建自己的主目录,如果不指定主目录名字就创建和用户名同名的主目录

新用户名是dave 但是他的主目录名是test
给指定用户设置密码passwd 用户名

红框那里指的是再次输入一遍你刚才的密码,不是说上次输入的密码不能用,上面只是提示密码不合规
2、id 查看用户是否存在
id 用户名


3、查看当前Linux系统有多少用户cat /etc/passwd
cat /etc/passwd

可以看到有好多我们没见过的用户,这些用户是和系统服务相关的,注意用户来运行系统服务的,这些用户称为系统用户或者伪用户,不能作为真正的用户身份来登录,是用来云系统里面服务的,不要动这些用户。
root用户编号是1,之后是各种系统用户,我们新增的普通用户是从1000开始的


显示用户通过什么方式和系统进行登录交互,显然我们的root和普通用户都是通过bin/bash进行登录和其他操作。
按q退出查看
4、在会话窗口切换用户 su
在当前会话窗口切换用户,使用su 用户名,从root切换其他用户不用输入密码,但是从普通用户切换切他用户需要输入密码

普通用户不能查看别的用户的主目录,只有root可以查看别的普通用户的主目录。

切换用户后,想要回到最开始的用户,可以使用exit 层层退回即可
查看当前使哪个身份在操作Linux,执行 who am i 会显示创建当前会话的那个用户,也就是最开始登录的那个用户
使用whoami 可以查看当前切换的用户


3.4.2 获取root权限和删除用户
1、获取root权限

想要获取root权限需要提前授权,回到root账号
进入 vim /etc/sudoers 文件进行修改
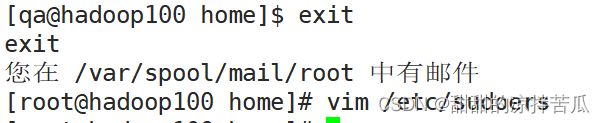

之后再次尝试给qa使用root权限


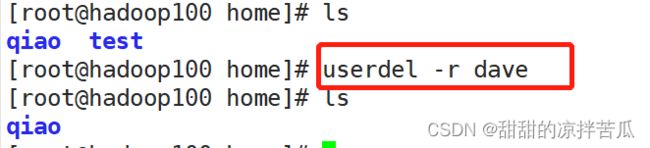
2、userdel删除用户

删除用户后,这个用户的主目录还是存在的
也可以去 cat /etc/passwd 确认下
可以手动删除这个用户的主目录,但是尽量不要删除它的主目录

如果确认要把用户的主目录一起删除,可以使用userdel -r 用户名
3.4.3 用户组管理

1、groupadd 新增组
新建的用户时会默认创建一个同名的用户组,该用户默认属于这个同名的用户组,并且组id和uid相等


root用户的uid是0,组id gid也是0组名是root,root所属的组只有一个,组id是0 组名是root
一个用户可以属于多个组,如组=1001(tony), 10(wheel) 第一个是用户的主要组
查看Linux系统有哪些组
cat /etc/group

添加meifa组:


更改用户的主要组
执行usermod -g 新组名 用户名

可以看到2个用户账号的主要组都已经修改成功。
给用户账号添加辅助组
执行 usermod -a -G 辅助组名 用户名
-a 选项告诉 usermod 将用户添加到组中
-G 选项指定要将用户添加到的辅助组的名称
可以给用户账户添加多个辅助组


删除用户账号的某个辅助组
执行gpasswd -d 用户名 辅助组名

2、groupmod 用户组重命名
groupmod -n 新组名 旧组名
修改meifa组的组名,改成haircut


3、groupdel 删除组


3.4.4 文件属性和权限
不同组的用户账号拥有不同权限





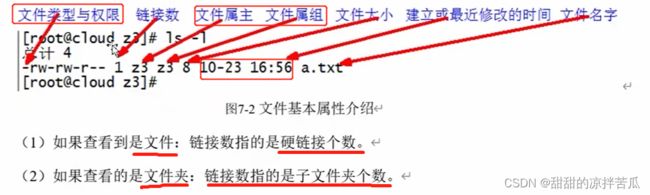
文件类型:
- 文件
d 文件夹
l 链接
c 字符类型的设备文件(鼠标、键盘)
b 块设备文件(硬盘)


![]()
前10位的含义上面已经解释,第二列表示当前文件的硬链接数,第三列表示该文件的属主,第四列表示该文件的属组,第五列是文件大小,第六列文件创建时间/最后一次修改时间(月 年 时:分),最后一列是文件名。
文件的属主和文件的属组不一定存在关系。
3.4.5 更改文件权限
1、chmod 修改文件权限
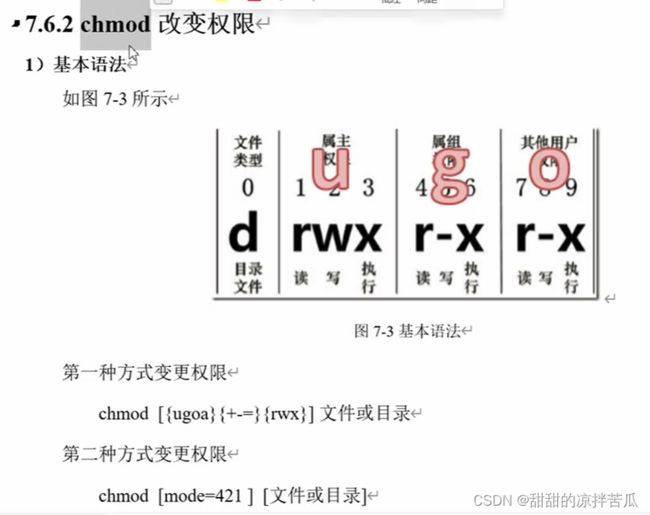
ugoa分别代表 user group other all 可以根据需要选择给哪类用户添加、删除某个权限
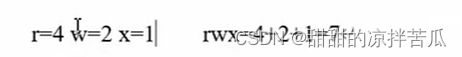




递归修改文件夹及其内部文件的权限:chmod -R 权限 文件名 谨慎使用
2、chown修改文件的属主


3、chgrp 修改文件的属组


3.4.6 案例
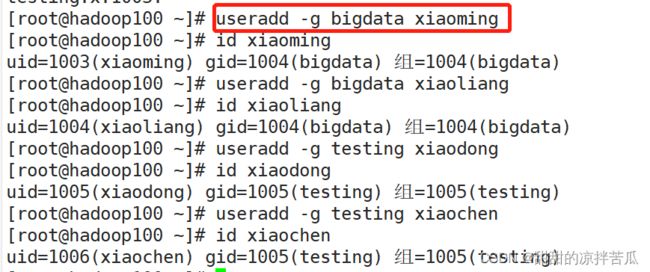
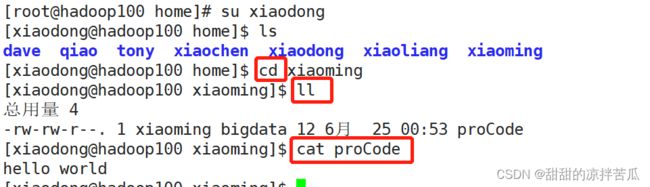
题目:创建组bigdata testing 组内的用户账号可以读写组内文件,其他组的成员只能读取
创建组


往组里加人

xiaoming在自己的主目录新建文件

切换xiaoliang ,xiaoliang进入xiaoming主目录访问proCode文件

xiaoliang没有xiaoming主目录的访问权限,回到root账号把xiaoming的主目录的属组的可执行权限打开

xiaoliang没有xiaoming主目录的读权限,切回root,xiaoming主目录的属组权限增加读权限
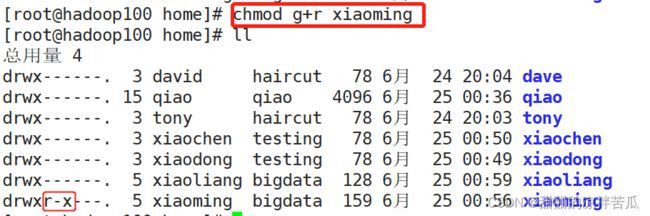
xiaoliang有了读取权限
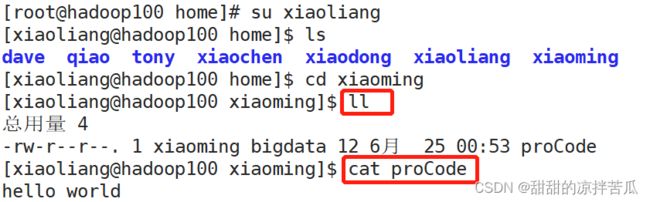
但是xiaoliang不能修改小明主目录里面的proCode文件,需要开放这个文件的写权限给属组


这个时候xiaoliag可以修改代码文件了
需要给测试组testing内的用户增加xiaoming主目录的访问权限 读权限,还要开放proCode文件的读权限给testing组内用户

3.5 搜索查找
3.5.1 查找定位文件
1、find 查找文件/目录
find 从指定目录向下递归遍历各个子目录,把满足条件的文件显示在终端。
find [搜索范围] [选项] 匹配条件
不指定搜索范围就默认从当前目录开始查找

如果使用-size 查找大于100M的文件,find -size +100M 小于就用- ,要注意单位的大小写
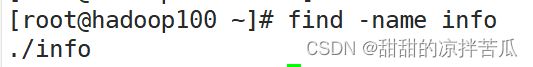



2、locate 快速文件定位

在locate查找前先执行 updatedb
locate是模糊匹配,只要是文件 文件夹名称内包含搜索内容就都会展示在终端。

3、which 查找
用来查找系统PATH目录下的可执行文件。
本质就是查找本地已经安装好的可直接执行的命令。
注意:
- 不需要关注在哪个目录下执行,which总会查找全局PATH下的可执行文件。
- 若可执行文件不在PATH下,也是无法被which查询到。

alias展示的是这个命令是哪个命令的别名
在终端显示这个命令所在目录
4、whereis 查找
whereis用于查找二进制(命令)、源文件、man文件。
通过文件索引数据库而非PATH来查找。(与which不同之处)
同样不需要关注哪个路径下执行

3.5.2 内容过滤查找grep和管道过滤|
1、内容过滤查找grep
grep是在确定的文件内查找需要匹配的内容
语法:grep -n 查找内容 文件名

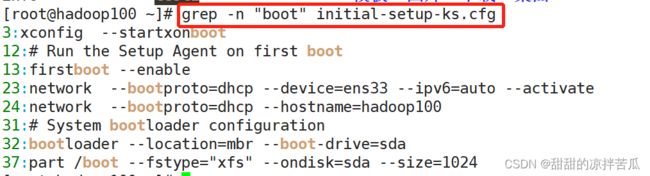
用文件的绝对路径和相对路径都可以

2、管道过滤 |
管道符 | 表示把前一个命令的处理结果输出传递给后面的命令处理。

3、统计匹配到的结果的数量wc
word count 的简写
终端输出匹配的行数、这些行总的单词个数(依据是空格分隔)、字节大小、文件名(如果指定的是文件就显示文件名)


3.6 压缩解压
3.6.1 gzip 压缩文件和 gunzip 解压文件
gzip 文件名 把文件压缩为.gz文件


gunzip 文件.gz 解压 .gz 文件
![]()

3.6.2 zip压缩和unzip解压缩
zip [-r] 压缩文件名.zip 被压缩文件名 把文件/目录压缩为名字是xxx.zip的压缩包
-r 在压缩文件夹时使用
压缩文件名.zip可以是相对路径也可以是绝对路径
unzip [-d] 解压到xxx路径 压缩文件名.zip 把压缩文件解压到指定目录



如果test文件夹不存在,自动新建文件夹test存放解压文件


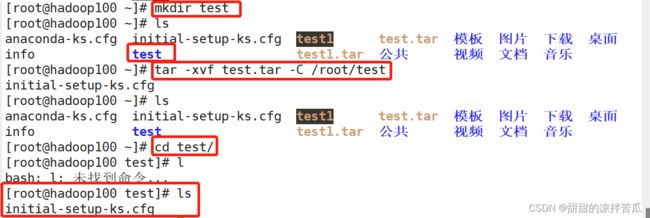
3.6.3 tar打包

打包一个文件到指定名字的tar包:

打包多个文件到一个指定名字的tar包

解包时如果要解包到指定目录,需要保证目录是已存在的:

打包并且压缩,并指定.tar.gz的文件名

解压缩解包 到指定目录,也要保证那个目录是存在的:


3.7 磁盘管理
3.7.1 查看目录占用空间大小
1、安装tree

2、查看目录树
查看当前所在目录的目录树

3、du 查看文件和目录占用的磁盘空间
disk usage 简写

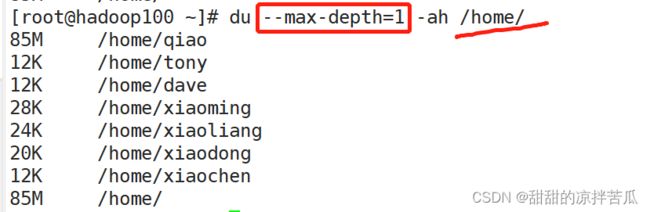
只看当前目录占用空间总和,不关心子目录和文件

3.7.2 df 查看磁盘使用情况
disk free 磁盘空余


这个只能看到 / 目录 下磁盘的占用情况,在最开始划分磁盘时我们分给虚拟机40G,第一个时系统启动服务分区boot(1G),第二个是 swap(4G)交换分区也叫虚拟内存(内存不够用时可以把暂时不执行的任务放在swap,把需要执行的任务放进内存),第三个分区是根目录/ (35G)。
后续话可以挂载其他磁盘,要查看这些磁盘的使用情况,需要使用df -h
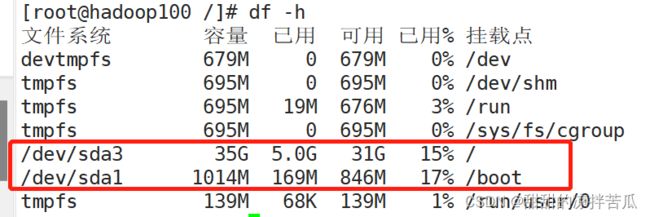
可以看到之前划分的磁盘分区boot 和 / 对应的文件系统以及使用情况
可以看到其他的文件系统并不是磁盘分区的使用情况
其他的文件系统名称都有tmpfs 表示的是临时文件系统,是基于内存的文件系统(这里的内存不仅包括真实的内存还有划分的swap分区)。
上面的挂载点 /dev/shm指的是共享内存(shared memory),默认大小是Linux系统内存的一半(之前设置的系统内存是1.4G)
挂载点 /run 指的是系统运行时。
devtmpfs 是Linux内核启动时创建的,用于管理全部设备。
所以df -h显示的不仅仅是磁盘的占用情况,还展示了内存的占用情况
free -h 查看系统内存使用情况

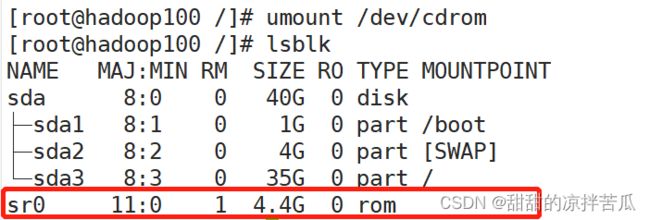
3.7.3 lsblk 查看设备挂载情况
list blok 的简写


文件系统 sr0是之前在VMware安装centOS7时使用的光盘,虽然不再使用但光盘还在。
可以看到dev下面有一个软链接 指向sr0

使用lsblk -f 可以显示文件系统类型和uuid
补充知识:
可以看到我们的硬盘名称是sda,对于不同的硬盘类型这里的名称可能是hda sda vda,最常见的是sda
硬盘类型 及其特点:
IDE:读写性能和数据传输很差,现在基本不用了
SATA:
- 基于行业标准的串行硬件驱动器接口,是由Intel、IBM、Dell、APT、Maxtor和Seagate公司共同提出的硬盘接口规范;
- 需要硬件芯片的支持;
- 数据传输快,节省空间,价格也比SCSI设备便宜
- 不需要设置主从盘跳线。BIOS会为它按照1、2、3顺序编号
SCSI:
- 一种用于计算机和智能设备之间(硬盘、软驱、光驱、打印机、扫描仪等)系统级接口的独立处理器标准
- 通过独立的高速的SCSI卡来控制数据的读写操作
- 价格高些,性能更稳定、耐用,可靠性也更好
- 需要在SCSI母线上可以连接主机适配器和八个SCSI外设控制器,外设可以包括磁盘、磁带、CD-ROM、可擦写光盘驱动器、打印机、扫描仪和通讯设备等
SATA一般用于个人电脑,SCSI一般用于服务器
IDE ———— hda hdb ...
SATA和SCSI ———— sda sdb .....
还有一种用的是虚拟硬盘,所以它的系统硬盘就是vda vdb .....
下面的sda1 sda2 sda3表示的是第一块硬盘sda的多个分区。
可以看下我们虚拟机选择的是什么类的硬盘

3.7.4 mount挂载和umount卸载


可以看到这个光盘没有挂载点,如果想给它挂载一个硬件设备,需要先有一个真实的光盘或者已经连接镜像文件
回到虚拟机桌面,可以看到已经识别了一个光盘
看下这个光盘被默认挂载到了哪里
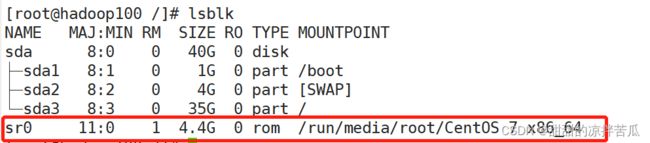 可以把光盘弹出,自己尝试在终端进行挂载
可以把光盘弹出,自己尝试在终端进行挂载
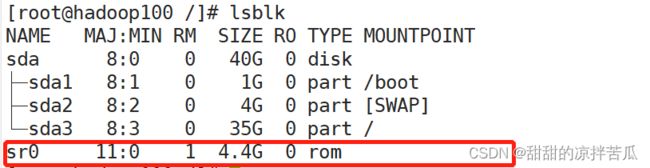
1、mount

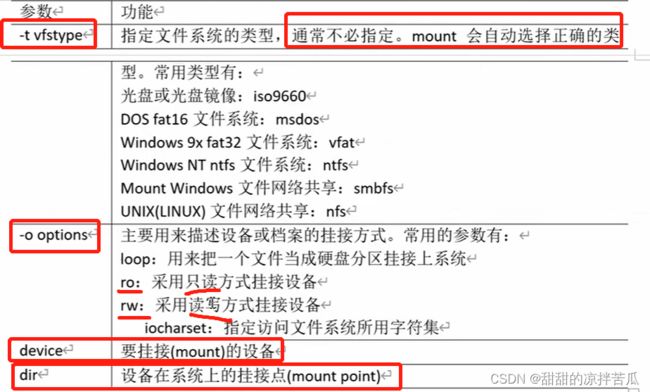
要给sr0添加挂载点,这个 /dev/sr0 就是device,dir 挂载点可以新建 /mnt/cdrom

原因是我们上面弹出了光盘,但是如果设置为已连接就自动给挂载到别的挂载点了,解决方式是关闭Linux系统的图形化界面,回到登录界面

再次点击连接光盘

再次执行挂载命令mount -o ro /dev/sr0 /mnt/cdrom
或者执行mount /dev/cdrom /mnt/cdrom
因为/dev/cdrom 是 /dev/sr0的软链接
之后查看系统挂载信息lsblk


可以正常读取光盘信息
2、umount卸载
umount 设备文件名或者挂载点 都可以实现卸载


3、设置开机自动挂载
vim /etc/fstab

可以看到每行后面都有2个0,代表的是什么意思??
第一个0 —— dump定期备份,如果值是1 则表示每天定时dump,0则不做备份
第二个0 ——文件系统检查的优先级(命令fsck用于文件系统检查,每次开机时会执行fsck,它会根据文件系统设置的优先级进行检查),优先级有1 2 3..等,1为最高级别,设置成0就表示开机时不检查当前文件系统。
添加 内容保存退出即可

3.7.5 fdisk 磁盘分区
如果挂载的不是光盘是硬盘,那就不仅是挂载就可以了,需要先对硬盘进行分区 和格式化,之后才是挂载操作。
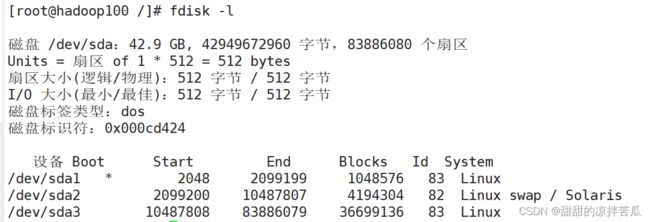
fdisk -l 查看磁盘分区详情

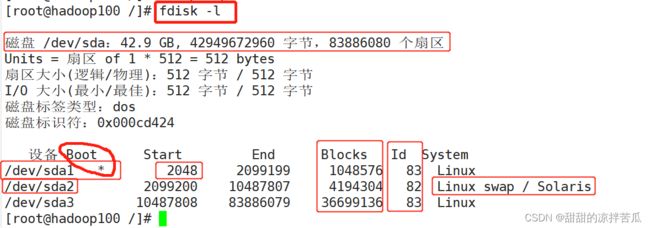
最上面是磁盘的基本信息
设备信息也就是这个磁盘sda有几个分区 sda1 sda2 sda3
Boot 指的是这个分区是不是Linux系统启动分区,*代表是系统的启动分区
分区划分不是从0开始的,是从2048开始的,所以并没有占满磁盘
Blocks指的就是磁盘分区的容量
Id指的是系统分区类型的id
system指的是系统分区的类型,sda2的系统分区类型是交换分区
如果要接入一块硬盘,第一步在Linux系统中添加硬盘

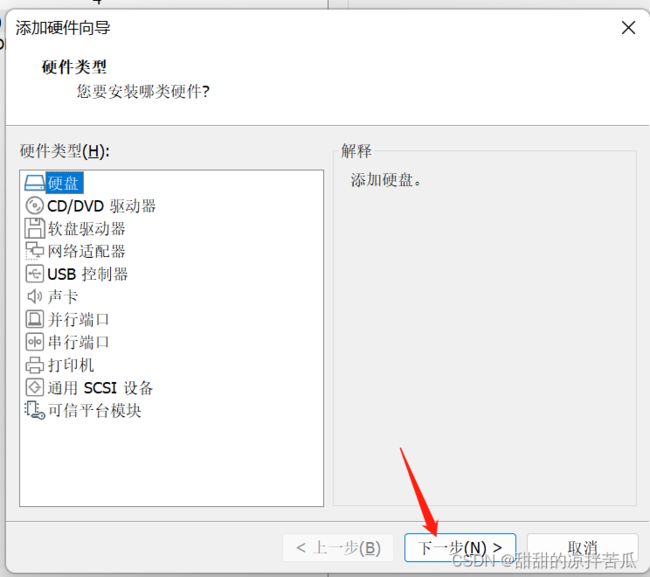

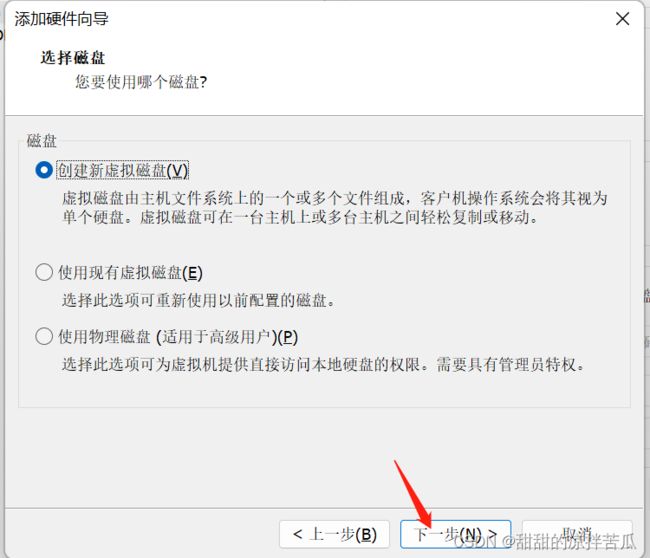


添加完硬盘使用fdisk -l 看下,发现没有刚才的那个硬盘信息
添加完硬盘需要重启Linux系统,执行 reboot 一次不行就多重启几次,等系统启动完在重新连接

这时再执行fdisk -l 或者 lsblk 发现多了一个sdb磁盘


第二步:对磁盘进行分区
fdisk 磁盘绝对路径


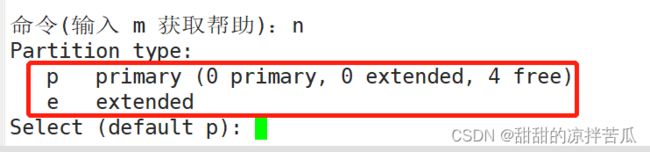
p指的是主分区,一个磁盘最多划分为4个主分区,如果还想多划分几个则会拿出一个主分区变为扩展分区,在扩展分区里面扩展出多个逻辑分区
前面4个主分区的编号是1 2 3 4,如果要扩展出逻辑分区,逻辑分区的编号为5~16,也就是最多有12个逻辑分区。



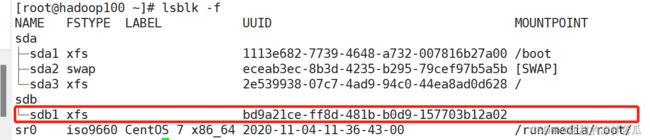
使用lsblk -f 查看 文件系统类型和uuid,发现sdb1 没有文件系统类型、uuid和挂载点

需要对sdb1指定文件系统和格式化
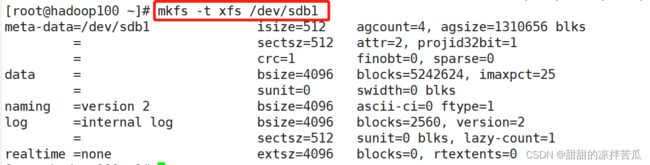
创建文件系统:mkfs -t xfs 设备名称
-t 用于指定文件系统类型
之后进行挂载,把/home/tony/ 的数据单独存储在/dev/sdb1
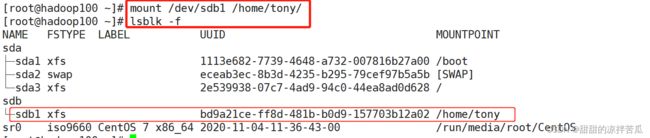
看下磁盘使用情况 df -h

卸载磁盘挂载umount
df -h 查看磁盘使用情况,发现刚才的/dev/sdb1已经没有了

3.8 进程管理
3.8.1 ps查看进程基本用法
进程是正在执行的一个程序或者命令,每一个进程都是一个运行的实体,都有自己的地址空间并占用一定的系统资源。

系统服务一般都是后台进程,统称为 守护进程。
系统服务的命名有一定特殊性,一般都在服务名称后加一个d,系统服务进程存储在/usr/lib/systemd/system文件夹
查看系统服务有哪些 ls /usr/lib/systemd/system | grep d.service

ps是process status 的简写

1、列出带有终端的当前用户的进程
带有终端的进程表示不会站展示后台运行的进程
直接执行 ps 即可

2、查看系统内的全部进程
有2种实现方法:ps aux 和 ps -ef
aux 这种选项前面没- 是BSD风格写法
ps aux | less
使用管道和less分屏显示系统的全部进行,按PgDn切到下一页 PgUp切到上一页,q 退出
a —— 全部用户
x —— 全部进程(有终端输出和无终端输出)
u —— 友好展示


STAT还有几个状态:
< 表示这个进程优先级很高
N 表示当前进程的优先级比较低
CentOS7的 1号进程(pid=1)是/usr/lib/systemd 这个进程
CentOS6 的1号进程是init这个进程
2号进程kthreadd 是负责所有内核线程的调度和管理,很重要
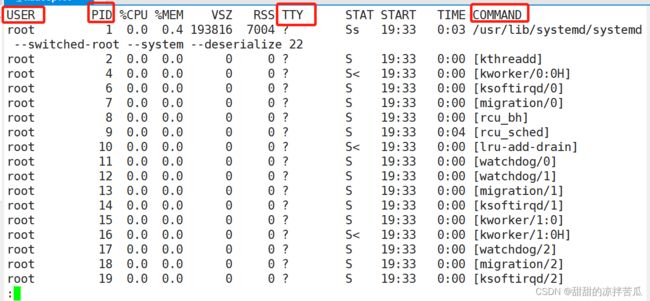
-euf 这种选项前面有- 是Unix风格的写法
ps -ef | less
使用管道和less分屏显示系统的全部进行,按PgDn切到下一页 PgUp切到上一页 q退出查看
-e —— 显示全部进程
-f —— 展示完整格式的进程列表
会比ps aux 多一个PPID列指的是父进程的PID


0号进程是系统级别的 idle进程 运行在系统内核
可以看到1号进程和2号进程的父进程都是0号进程,可见1 2号进程的重要性
其他的系统进程的父进程基本都是2号进程
用户启动的进程的父进程都是1号进程
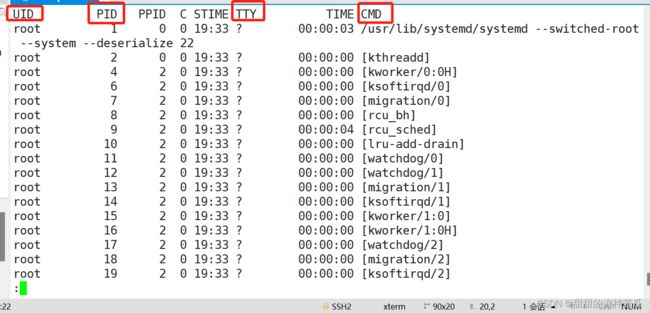

3、查看指定进程
ps aux | grep 进程名
ps -ef | grep 进程名

第二条就是远程终端使用sshd登录Linux
第三条就是我们上面执行的ps -ef | grep sshd的这个命令的进程
什么时候用ps aux 什么时候用ps -ef

3.8.2 查看远程登录进程
命令:ps -ef | grep sshd
pts0 ~ 255指的是虚拟终端
root@pts/0 root@pts/1 root@pts/2就表示有3个远程虚拟终端使用root账号登录了Linux服务器
所有的虚拟终端的sshd服务的父进程都是pid=1079 sshd进程启动
1079号进程sshd 是由1号进程systemd启动的

使用其他用户开启会话窗口后,再次查看远程登录进程信息

可以看到多了2条进程信息
第一条是用于权限隔离的进程,当qiao要使用sudo临时获取root权限进行其他操作时,使用的进程
第二条是qiao用户进行普通用户权限的操作时使用的进程
3.8.3 kill 终止进程
kill -9 进程号
killall 进程名 进程名支持模糊匹配,可以杀死多个进程
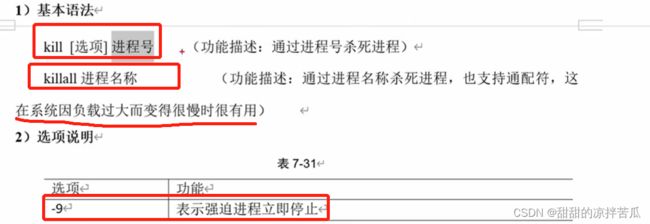

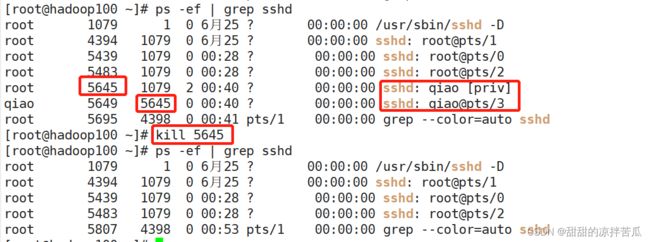
因为5645是5649的父进程,所以kill掉5645,5649也就一块没了
去qiao这个用户的会话窗口可以看到已经被迫断开,还有提示原因

如果kill掉的是守护进程,远程虚拟终端进程还是可以继续连接进行操作的,但是如果还想增加新的远程连接就连不上了,因为守护进程都没了
而且可以看到杀死守护进程后,远程虚拟终端的进程的父进程变成了1号进程systemd

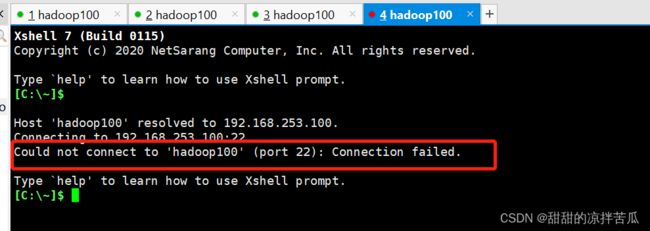
如果我们不在现有的远程虚拟终端把sshd服务启动,一旦关闭了远程这几个虚拟终端,就再也连不上Linux服务器了
使用systemctl status sshd看下sshd服务的状态
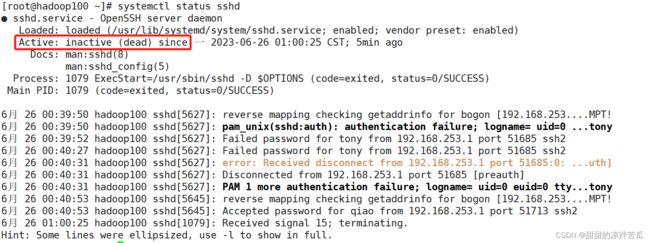
是挂的,使用systemctl start sshd 开启sshd服务

重新把守护进程启动后,就可以新增远程连接了,可以发现重启的守护进程 pid变成了5958,而且后面新增的远程连接的父进程也都是5958,但是之前的那几个进程的父进程还是1号进程
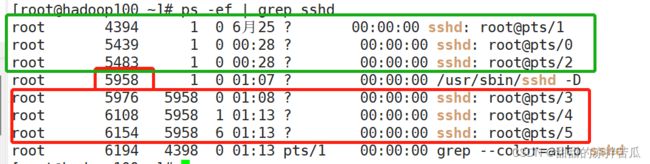
最后一个进程的父进程id是4398,这个是什么进程??
执行ps -ef | grep 4398 可以看到4398是bash,所有在终端输入的命令的父进程都是当前会话窗口的bash进程


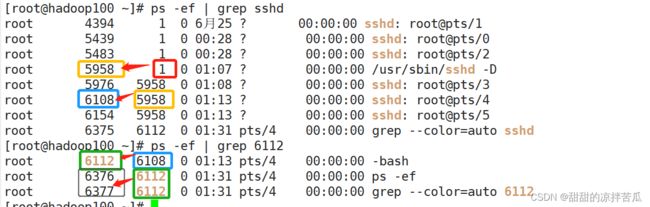

如果执行killall sshd就把全部sshd相关的进程都杀死了
所以如果你是通过远程终端登录Linux服务器,在kill进程时一定要注意不要把远程登录的守护进程sshd给杀了,因为如果你没有及时启动守护进程sshd,这样一旦你关闭了现有的远程连接,就再也连不上Linux服务器了,只能去机房启动sshd守护进程。
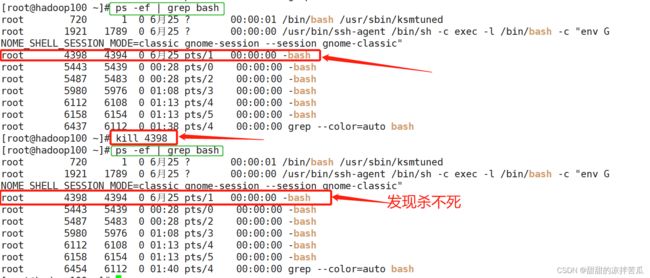
去看下pid=4398这个bash会话窗口,发现确实还正常连接着Linux服务器

使用kill -9 4398

去4398对应的会话窗口看下,确实断开Linux连接了

3.8.4 pstree 查看进程树

pstree -pu 默认的所属用户是root,如果子进程的所属用户和父进程一样,那子进程就不用显示所属用户名了,只有当子进程的所属用户和父进程的所属用户不一样时,才显示。



3.8.5 top 实时监控进程
top是实时监控并刷新终端的显示信息


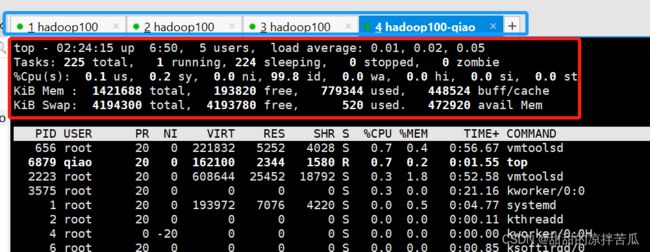
上面显示系统信息:

上半部分系统数据含义解释:
top ——现在的时间
up —— 系统启动运行到现在的时间 几天几小时几分钟
users —— 当前移动登录正在使用机器的用户数量,等于开的会话窗口数+图形化桌面数,VMware中Linux的图形化桌面也是一个用户
load average —— 平均负载显示的是3个数,分别是过去的1分钟 5 分钟 15分钟之内系统的平均负载,如果数值小于0.7 认为是比较小的,大于1就超出系统负荷了
tasks —— 当前正在运行的程序,总数,正在运行的数量,休眠数量,停止的数量,僵尸状态的进程数量
%cpu(s) —— us用户空间占用CPU百分比,sy内核空间占用CPU百分比,ni表示执行完nice调整用户进程优先级后进程占用的百分比,id表示idle空闲CPU百分比,wa等待输入输出的CPU时间百分比,hi CPU服务于硬件中断所耗费的时间总额,si CPU服务软中断所耗费的时间总额,st Steal time 虚拟机被hypervisor偷去的CPU时间(如果当前处于一个hypervisor下的vm,实际上 hypervisor也是要消耗一部分CPU处理时间的)。
KiB Mem —— total 物理内存总量,used使用的物理内存总量,free 空闲内存总量,buff/cache 用作内核缓存的内存量
KiB Swap ——total 交换区总量,used 使用交换区总量,free 空闲交换区总量,avail Mem 缓冲的交换区总量
下半部分数据解含义释

PID: Process Id(进程ID)
USER:User Name(进程所有者的用户名)
PR:Priority(优先级)
NI:Nice value(nice值,负值表示高优先级,正值表示低优先级)
VIRT:Virtual Image (kb)(进程使用的虚拟内存总量,单位kb,VIRT=SWAP+RES)
RES:Resident size (kb)(进程使用的,未被换出的物理内存大小,单位kb,RES=CODE+DATA)
SHR:Shared Mem size (kb)(共享内存大小,单位kb)
S:Process Status(进程状态,D=不可终端的进程状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程)
%CPU:CPU usage(上次更新到现在的CPU时间占用百分比)
%MEM:Memory usage (RES)(进程使用的物理内存占用百分比)
TIME+ CPU Time, hundredths(进程使用的CPU时间占比,精确到0.01秒,单位1/100秒)
COMMAND:Command name/line(命令名/命令行)
top -i
-i 指的是不显示从上次刷新到本次刷新,期间从来没有占用过cpu进程
如果在此期间进程占用过cpu,那么及时此时此刻它是睡眠或者僵死状态也会显示出来
top -d 5
-d 表示间隔多少秒刷新终端进程进程数据
top -p 7265
-p 只监测指定进程的数据
在监控页面,按u 可以指定只监控某个用户的进程
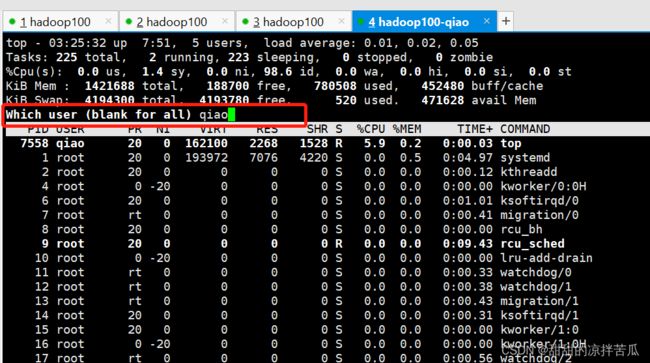
之后展示的就只是这个用户的进程信息

在监控页面,按k 可以指定要终止的进程id
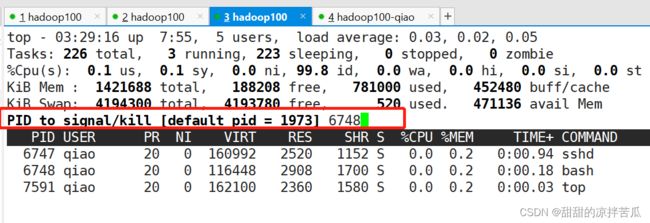
kill命令有多个信号,9表示立即强制杀死进程


3.8.6 netstat 显示网络状态和端口占用情况
netstat [选项]
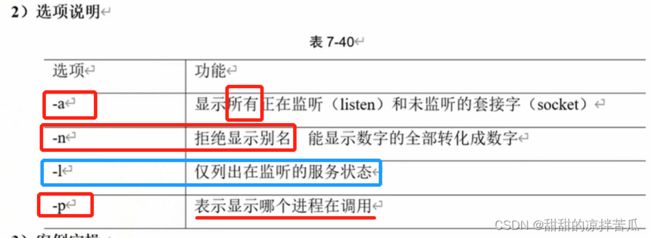
-n 指的是尽量展示机器的IP
1、 列出所有端口 netstat -a
列出所有 tcp 端口 netstat -at
列出所有 udp 端口 netstat -au


字段含义介绍:
- Proto:协议名
- Recv-Q:网络接收队列,表示收到的数据已在本地接收缓冲,但是还有多少没有被进程取走recv()。
如果接收队列Recv-Q一直处于阻塞状态,可能是遭受了拒绝服务 denial-of-service 攻击。- Send-Q:对方没有收到的数据或者说没有Ack的,还是本地缓冲区.
如果发送队列Send-Q不能很快的清零,可能是有应用向外发送数据包过快,或者是对方接收数据包不够快。
recv-Q、send-Q这两个值通常应该为0,如果不为0可能是有问题的。packets在两个队列里都不应该有堆积状态。可接受短暂的非0情况。- Local Address:本地地址,
127.0.0.1:port 表示只能本机访问的端口,外网无法访问。0.0.0.0:port 表示对外开放的IPv4端口,外网可访问。
:::port 表示对外开放的IPv6端口,外网可访问。
::1:port对应IPv6,如::1:9000:表示监听IPv6的回环地址的9000端口
- Foreign Address:外部地址,与本机端口通信的外部socket,显示规则与 Local Address 相同,一般都是
0.0.0.0:*(IPv4)和:::*(IPv6)。
- State:链路状态,共有11种。state列共有12种可能的状态,前面11种是按照TCP连接建立的三次握手和TCP连接断开的四次挥手过程来描述的。
1) LISTEN:首先服务端需要打开一个socket进行监听,状态为LISTEN。来自远方TCP端口的连接请求
2) SYN_SENT:客户端通过应用程序调用connect进行active open。于是客户端tcp发送一个SYN以请求建立一个连接,状态置为SYN_SENT。在发送连接请求后等待匹配的连接请求
3) SYN_RECV:服务端应发出ACK确认客户端的 SYN,同时自己向客户端发送一个SYN,状态置为SYN_RECV。在收到和发送一个连接请求后等待对连接请求的确认
4) ESTABLISHED:代表一个打开的连接,双方可以进行或已经在数据交互了。代表一个打开的连接,数据可以传送给用户
5) FIN-WAIT-1:主动关闭(active close)端应用程序调用close,于是其TCP发出FIN请求主动关闭连接,之后进入FIN_WAIT1状态。等待远程TCP连接中断请求,或先前的连接中断请求的确认
6) CLOSE-WAIT:被动关闭(passive close)端TCP接到FIN后,就发出ACK以回应FIN请求(它的接收也作为文件结束符传递给上层应用程序),并进入CLOSE_WAIT。等待从本地用户发来的连接中断请求
7) FIN-WAIT-2:主动关闭端接到ACK后,就进入了 FIN-WAIT-2。从远程TCP等待连接中断请求
8) LAST-ACK:被动关闭端一段时间后,接收到文件结束符的应用程序将调用CLOSE关闭连接。这导致它的TCP也发送一个 FIN,等待对方的ACK,这就进入了LAST-ACK。等待原来发向远程TCP的连接中断请求的确认
9) TIME-WAIT:在主动关闭端接收到FIN后,TCP 就发送ACK包,并进入TIME-WAIT状态。等待足够的时间以确保远程TCP接收到连接中断请求的确认
10) CLOSING:比较少见。等待远程TCP对连接中断的确认
11) CLOSED:被动关闭端在接受到ACK包后,就进入了closed的状态。链接结束,没有任何连接状态
12) UNKNOWN:未知的Socket状态
SYN:同步序列编号(Synchronize Sequence Numbers),该标志只在三次握手建立TCP连接时有效,表示一个新的TCP连接请求
ACK:确认编号(Acknowledgement Number),是对TCP请求的确认标志,同时提示对端系统已成功接收所有数据
FIN:结束标志(Finish),用来结束一个TCP对话,但对应端口仍处于开放状态,等待接收后续数据- PID/Programe name:PID即进程id,Program即使用该socket的应用程序
2、只显示监听端口 netstat -l
只列出所有监听 tcp 端口 netstat -lt
只列出所有监听 udp 端口 netstat -lu
只列出所有监听 UNIX 端口 netstat -lx

3、 显示所有端口的统计信息 netstat -s
显示 TCP 端口的统计信息 netstat -st
显示 UDP端口的统计信息 netstat -su

4、显示核心路由信息 netstat -r
使用 netstat -rn 显示数字格式,不查询主机名称

3.9 crontab 系统定时任务
3.9.1 重启crond服务
systemctl restart crond

3.9.2 crontab 定时任务设置
crontab [选项]

1、查看当前用户有哪些定时任务 crontab -l

2、新建&编辑定时任务 crontab -e
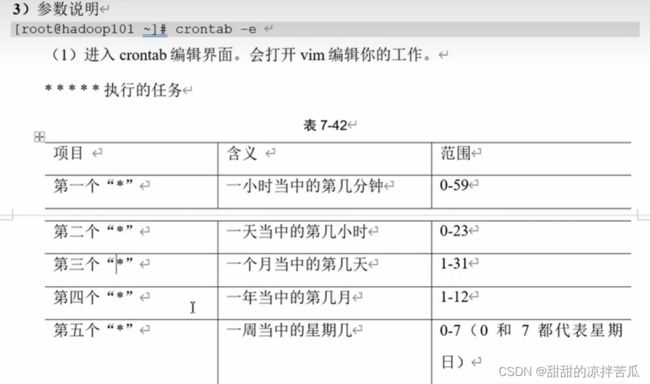

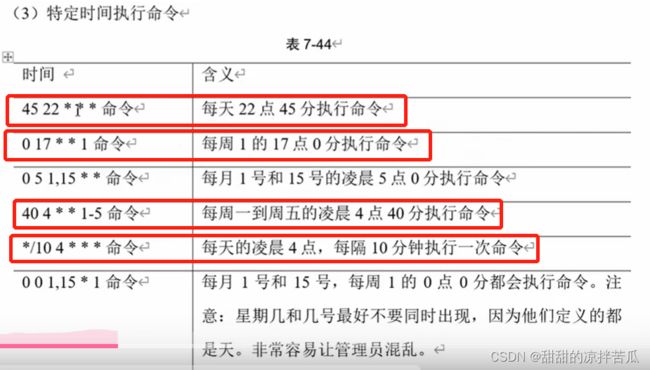
需要注意的是每个*之间要有一个空格,不然会报错


增加了crontab任务后,在/var/spool/cron目录下会有一个当前登录账号命名的文件。比如我的登录账号是root。则会存在一个root文件。该文件的内容就是刚添加的crontab任务。
crontab -l
cat /var/spool/cron/root
crontab -e

删除crontab内容里的happy的任务
其实该处是使用sed命令来处理/var/spool/cron/root 文件,将含happy的行的内容删除掉。
sed -i '/happy/d' /var/spool/cron/root
crontab -l
cat /var/spool/cron/root

sed 主要是用来将数据进行选取、替换、删除、新増的命令。我们看看命令的语法:
[root@localhost ~] # sed [选项] '[动作]' 文件名
选项:
- -n:一般 sed 命令会把所有数据都输出到屏幕上。如果加入此选项,则只会把经过 sed 命令处理的行输出到屏幕上;sed -n ' 动作' 文件名
- -i:用 sed 的修改结果直接修改读取数据的文件,而不是由屏幕输出动作;sed -i '动作' 文件名
- -e: 允许对输入数据应用多条 sed 命令编辑;sed -e 's/Liming//g; s/Gao//g' student.txt
- -f :脚本文件名:从 sed 脚本中读入 sed 操作。和 awk 命令的 -f 选项非常类似;
- -r:在 sed 中支持扩展正则表达式;
动作:
- p:打印,输出指定的行;sed -n '2p' text.txt
- a \:在后面追加行,在当前行后添加一行或多行。当添加多行时,除最后一行外,每行末尾需要用“\”代表数据未完结;sed -i '2a 你好' text.txt
- i \:在前面插入行,在当前行前插入一行或多行。当插入多行时,除最后一行外,每行末尾需要用“\”代表数据未完结;sed -i '2i 蛋糕' text.txt
- c \:行替换,用c后面的字符串替换原数据行。当替换多行时,除最后一行外,每行末尾需用“\”代表数据未完结;sed -i '2c No such person' student.txt
- s:字符串替换,用一个字符串替换另一个字符串。格式为“行范围s/旧字串/新字串/g”(和Vim中的替换格式类似);sed '3s/74/99/g' student.txt sed '4s/^/#/g' student.txt
- d:删除,删除指定的行;sed '2,4d' text.txt
1、查看文件指定内容
想查看一下 student.txt 文件的第二行,就可以利用"p"动作了。
[root@localhost ~]# sed '2p' student.txt
ID Name PHP Linux MySQL Average
1 Liming 82 95 86 87.66
1 Liming 82 95 86 87.66
2 Sc 74 96 87 85.66
3 Gao 99 83 93 91.66
"p"动作确实输出了第二行数据,但是 sed 命令还会把所有数据都输出一次,这时就会看到这个比较奇怪的结果。那如果我想指定输出某行数据,就需要"-n"选项的帮助了。
[root@localhost ~]# sed -n '2p' student.txt
1 Liming 82 95 86 87.66这样才可以输出指定的行。当我们需要输出指定的行时,需要把"-n"选项和"p"动作一起使用。
2、删除文件中的数据
[root@localhost ~]#sed '2,4d' student.txt
#删除从第二行到第四行的数据
ID Name PHP Linux MySQL Average
[root@localhost ~]# cat student.txt
#文件本身并没有被修改
ID Name PHP Linux MySQL Average
1 Liming 82 95 86 87.66
2 Sc 74 96 87 85.66
3 Gao 99 83 93 91.66
看到这条命令首先需要注意,所有的动作必须使用"单引号"包含;其次,在动作中可以使用数字代表行号,逗号代表连续的行范围。还可以使用"$"代表最后一行,如果动作是"2,$d",则代表从第二行删除到最后一行。
3、追加a 和插入i 行数据
[root@localhost ~]# sed '2a hello' student.txt
#在第二行后加入hello
ID Name PHP Linux MySQL Average
1 Liming 82 95 86 87.66
hello
2 Sc 74 96 87 85.66
3 Gao 99 83 93 91.66"a"动作会在指定行后追加数据。如果想要在指定行前插入数据,则需要使用"i"动作。
[root@localhost ~]# sed '2i hello > world' student.txt
#在第二行前插入两行数据
ID Name PHP Linux MySQL Average
hello
world
1 Liming 82 95 86 87.66
2 Sc 74 96 87 85.66
3 Gao 99 83 93 91.66如果想追加或插入多行数据,则除最后一行外,每行的末尾都要加入"\"代表数据未完结。
再来看看"-n"选项的作用,命令如下:
[root@localhost ~]# sed -n'2i hello \
#只查看sed命令操作的结果
world' student.txt
hello
world"-n"只用于查看 sed 命令操作的数据,而并非查看所有的数据。
4、如何实现行数据替换
行替换c
[root@localhost ~]# cat student.txt | sed '2c No such person'
ID Name PHP Linux MySQL Average
No such person
2 Sc 74 96 87 85.66
3 Gao 99 83 93 91.66第二行数据变成了 "No such person",sed 可以接收和处理管道符传输的数据。
sed 命令在默认情况是不会修改文件内容的。如果确定需要让 sed 命令直接处理文件的内容,则可以使用"-i"选项。不过要小心,这样非常容易误操作。
[root@localhost ~]# sed -i'2c No such person' student.txt"c"动作是进行整行替换的,如果仅仅想替换行中的部分数据,就要使用"s"动作了。"s"动作的格式如下:
[root@localhost ~]# sed's/旧字符串/新字符串/g' 文件名
替换的格式和 Vim 非常类似:
[root@localhost ~]# sed '3s/74/99/g' student.txt
#在第三行中,把74换成99
ID Name PHP Linux MySQL Average
1 Liming 82 95 86 87.66
2 Sc 99 96 87 85.66
3 Gao 99 83 93 91.66
如果想把某行的成绩注释掉,让它不再生效,则可以这样做:
[root@localhost ~]#sed '4s/^/#/g' student.txt
#在这里使用正则表达式,"^"代表行首
ID Name PHP Linux MySQL Average
1 Liming 82 95 86 87.66
2 Sc 74 96 87 85.66
#3 Gao 99 83 93 91.66
不仅如此还可以这样做:
[root@localhost ~]# sed -e 's/Liming//g; s/Gao//g' student.txt
#同时把"Liming"和"Gao"替换为空
ID Name PHP Linux MySQL Average
1 82 95 86 87.66
2 Sc 74 96 87 85.66
3 99 83 93 91.66
"-e"选项可以同时执行多个 sed 动作,当然,如果只执行一个动作,则也可以使用"-e"选项,但是这时没有什么意义。还要注意,多个动作之间要用";"或回车分隔。
例如,#同时把"Liming"和"Gao"替换为空
[root@localhost ~]# sed -e 's/Liming//g > s/Gao//g' student.txt
ID Name PHP Linux MySQL Average
1 82 95 86 87.66
2 Sc 74 96 87 85.66
3 99 83 93 91.66四、扩展篇
4.1 软件包管理
4.1.1 RPM
RedHat Packge Manager 的简写
是Linux操作系统的打包安装工具。
RPM 软件安装包的命名规则:

1、rpm 查询当前系统安装软件
语法:rpm [选项]
-q query 查询
-a all 全部的软件
-i 展示软件的安装详细信息
rpm -qa 查询系统安装的全部软件
软件包比较多,可以使用管道| 和 grep进行过滤查询
rpm -qa | grep 软件名
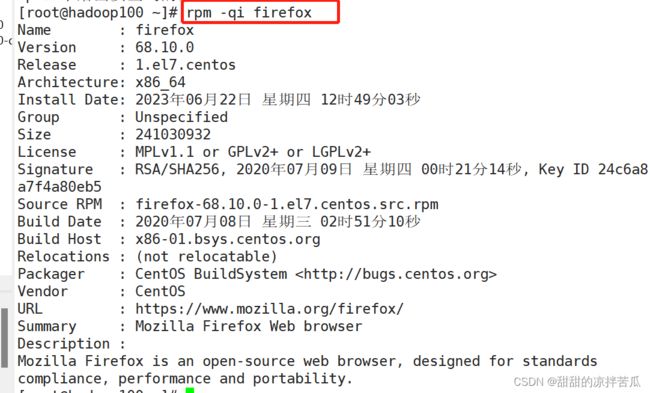
rpm -qi 软件名 查询指定软件的安装详细信息

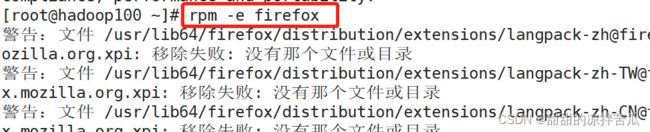
2、卸载软件rpm -e
rpm -e 软件名
-e 卸载软件包
-nodeps no dependence的简写,卸载软件时不检查依赖关系,可能会导致其他软件不可用,所以这个选项要谨慎使用
rpm -e -nodeps 软件名
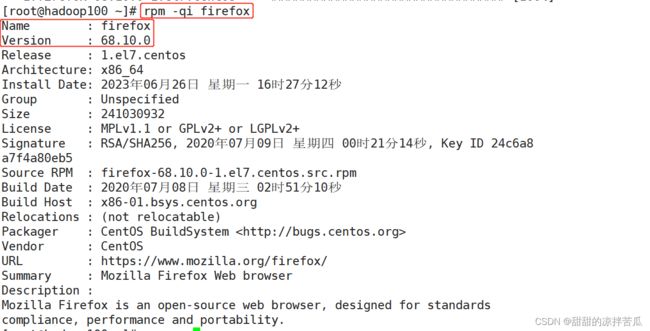
3、安装软件rpm -i
语法:rpm 【选项】 软件安装包的绝对路径
-i install简写
-v verbose简写,显示详细信息
-h hash 简写 显示进度条
-nodeps 安装前不检查依赖,谨慎使用
rpm -ivh 软件安装包的绝对路径
首先找到软件安装包的位置,Firefox是CentOS7 安装的时候自带的浏览器,所以会在光盘里



使用rpm进行软件安装和管理的缺点:
1、需要自己下载好rpm包
2、安装a软件过程中如果它有其他依赖,安装过程会报错,提示你需要先下载指定依赖才能继续安装
4.1.2 YUM
Yellow dog Updater Midfied 的简写
是Fedora、RedHat和CentOS中的shell前端软件包管理器。
可以从指定服务器自动下载rpm软件包并且安装,自动处理依赖性关系,并且一次安装所有依赖的软件包。
语法:yum [-y] [参数]
-y 表示对所有提问都回答ye
1、查看当前系统全部软件的安装包信息
yum list
yum list | grep 软件名 查看指定软件的安装包

后面的update表示当前检测到可更新的版本,可以先把老版本的firefox卸载
2、卸载指定软件
yum -y remove firefox
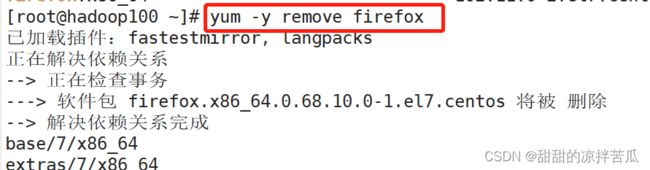

之后查看下firefox的安装包信息,检查是否卸载成功
yum list | grep 软件名
rpm -q 软件名

之后 安装最新版本的firefox
3、安装指定软件
yum -y install 软件名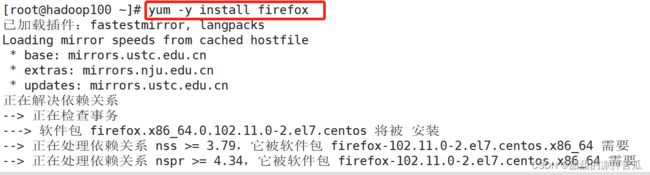


验证下是否安装成功
yum list | grep 软件名
rpm -q 软件名

安装成功 并且安装的版本是最新的版本。
4、修改网络yum源
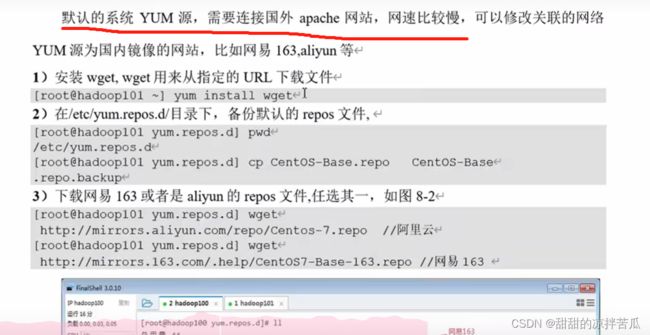
下载安装wget
yum -y install wget

备份系统默认的repos 文件 (CentOS-Base.repo)

可以看下之前安装firefox时使用的镜像源是哪个??

可以看下之前默认设置的yum源的下载地址和逻辑:

4.2 克隆虚拟机
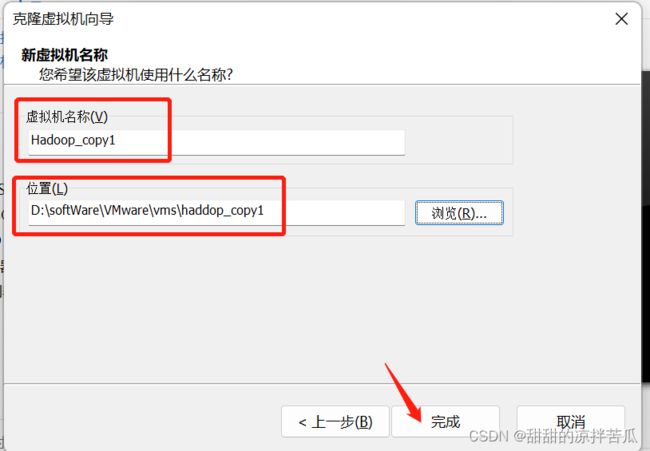
4.2.1 克隆一个虚拟机
目录内选中虚拟机,右击——【管理】——【克隆】
如果当前虚拟机时开机态 那就无法克隆
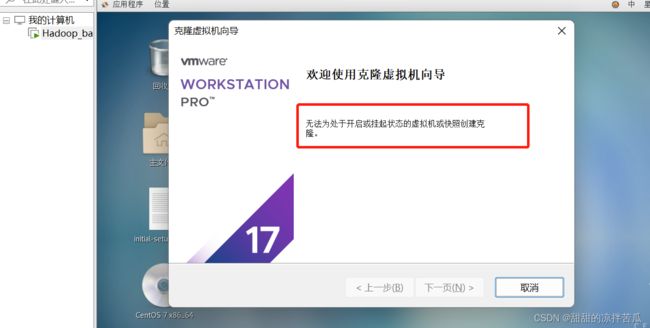


4.2.2 修改克隆虚拟机的ip
克隆的虚拟机和原始虚拟机的账号 密码都是一样的,但要创建集群,每个虚拟机的ip肯定不能一样
ifconfig 查看克隆虚拟机的ip,可以发现copy的虚拟机和原始虚拟机的IP是一样的

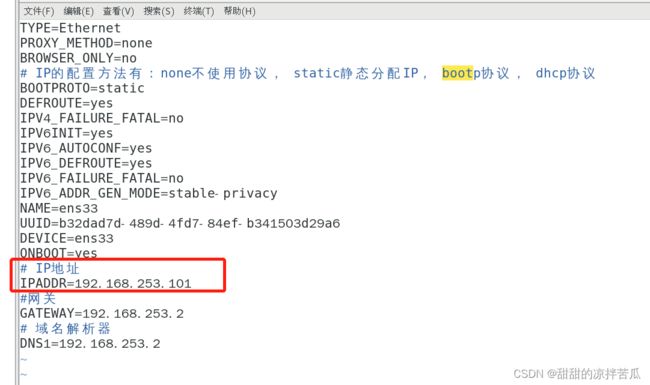
修改 vim /etc/sysconfig/network-scripts/ifcfg-ens33


改下ip
之后需要重启当前虚拟机的网络服务,要先保证centos系统内只有一个网络服务时活跃的,否则可能重启后虚拟机ip也不会更新
因为centos6的网络服务时network 而centos7的网络服务时networkmanager,而且centos7里面还兼容保留了centos6的网络服务,所以需要先把network服务停掉。
之后再重启NetworkManager 服务

之后ping以下物理主机和外网,看copy的虚拟机能不能连接成功
可以确认虚拟机网络连接是正常的。
4.2.3 修改克隆虚拟机的主机名
查看当前克隆虚拟机的主机名 cat /etc/hostname

可以看到copy得到的虚拟机的主机名也是hadoop100,这显然不合适
修改克隆虚拟机的主机名,vim /etc/hostname 进行修改
或者使用 hostnamectl set-hostname 新名字

之后要执行reboot重启虚拟机再次进入才是新的虚拟主机名。
需要保证物理主机能够通过主机名连接到虚拟机,
修改物理机的 c\windows\system32\drivers\etc\hosts
这个文件在最开始建立远程虚拟连接时就添加了。

check下虚拟机hadoop01的配置文件 /etc/hosts 中是否保存了其他虚拟机的ip和主机名,这样才能保证hadoop101可以和这些虚拟机通过主机名通信。
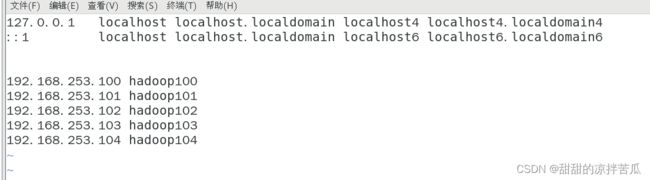
4.3 shell编程
4.3.1 shell概念
shell是一个命令行解释器,接收应用程序/用户指令,之后调用操作系统内核。

可以看下当前centos7里面提供了几种shell


可以看到根目录/下的bin和sbin都是软链接,指向的是usr下面的bin和sbin
再看下系统中默认使用的shell是哪个


本身bin下面的sh就是一个bash的软链接
4.3.2 shell脚本入门
1、脚本后缀
脚本文件的后缀一般都是.sh
2、指定脚本使用的shell类型
脚本第一行会先指定当前脚本使用命令行解释器是哪个
#!/bin/bash
3、脚本执行方法
1)sh 脚本的相对路径/绝对路径
bash 脚本的相对路径/绝对路径

2)直接输入文件的相对路径/绝对路径执行
但是前提这个文件的可执行权限必须是打开的

可以看到打开可执行权限后脚本文件名的颜色 变成了绿色
如果要执行当前目录下的脚本 直接输入脚本名不行,需要用 ./文件名
其他情况直接使用脚本的先对/绝对路径就可以执行了


3)使用 . 文件相对路径/绝对路径 注意点. 后面有空格
或者 source 文件相对路径/绝对路径

比较下3种方式的区别:
前面2种方式是在当前shell 中又打开了一个shell来执行指定的脚本,有父子shell的关系。
第三种方式是直接在当前shell中执行指定的脚本。
嵌套的父子shell会存在环境变量获取不到的情况。
建议使用第三种方式
以上是老式的说法,但是目前可能是shell优化了,以上3种方式方式都是直接在当前shell中执行指定的脚本,没有区别。

使用第二种方式按照老式的说法应该是 打开一个子shell 但是查看进程信息发现并没有
ps -f 只会查看当前用户有终端的进程的全部信息,无终端的比如后台守护进程就不会展示
使用 ps -ef 就能展示全部用户的全部进程的完整信息
![]()
4.3.3 系统预定义变量
变量可以划分为系统变量和用户变量
也可以划分为全局变量和局部变量
常用系统变量:
$HOME 当前用户的主文件夹
$PWD 当前所在位置
$SHELL 当前用户使用的shell解释器是哪个
$USER 当前用户是谁
PATH 决定了shell将到哪些目录中寻找命令或程序
HISTSIZE 历史记录数
LOGNAME 当前用户的登录名
HOSTNAME 指主机的名称
LANGUGE 语言相关的环境变量,多语言可以修改此环境变量
MAIL 当前用户的邮件存放目录
PS1 基本提示符,对于root用户是#,对于普通用户是$
查看下这些环境变量的值:
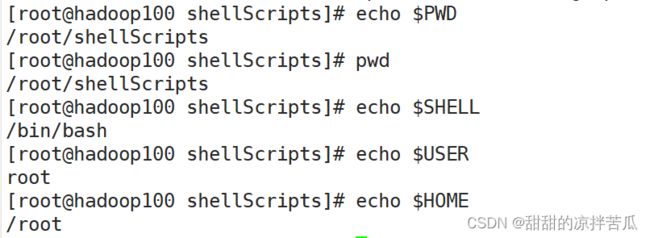

查看系统的全局环境变量:env
查看所有变量和函数(包括全局 局部,系统定义的和用户定义的):set
4.3.4 用户自定义变量



可以直接定义变量并赋值,也可以只定义,但是等号左右不能有空格
变量名前加$表示的是变量的值
变量赋值后可以重新赋值
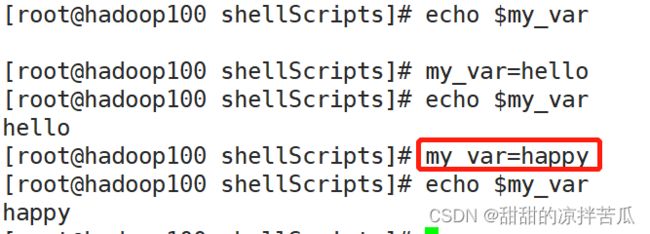

看下这个变量是用户定义的局部变量还是全局变量呢??
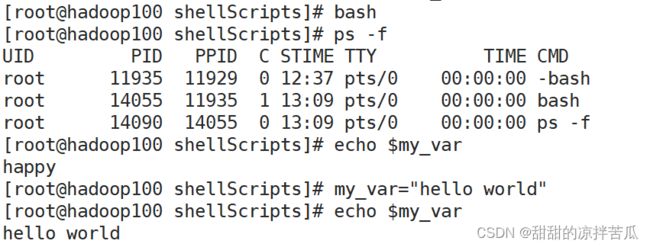
bash 打开一个子shell
ps -f 看下当前有终端的进程信息,发现多了一个bash,并且它的父进程是11935
在这个子进程里查看下之前定义的变量是否可以访问到
能访问到说明这变量是全局变量,访问不到说明是局部变量
退出子shell 查看下当前有终端的进程发现子shell的进程已被kill了
再次访问之前的变量就可以访问到了

如果想把定义的局部变量 变成全局:export 变量名
如果在子shell种修改了全局变量,那么这个修改结果不会在父shell中生效,只会在子shell以及该子shel再次嵌套的zishell中生效


4.3.5 全局变量、只读变量和撤销变量
1、export 定义全局变量
使用 export 变量名 定义全局变量,可以在定义时赋值,也可以单独赋值
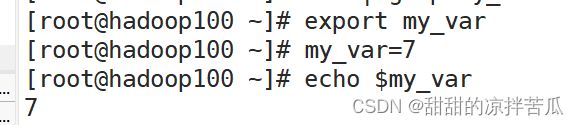

2、readonly 定义只读变量
使用 readonly 变量名 定义只读变量,可以在定义时赋值,也可以单独赋值
只读变量只能赋值一次,后面不能修改
只读变量不能撤回

3、unset 撤回变量
使用 unset 变量名 撤回已定义的变量,注意只读变量不能撤回
4.3.6 特殊变量
写好的.sh脚本怎么才能像shell命令那样直接就能运行呢??
在shell中 cd ls 这种命令是存储在/bin/ /sbin/ 目录下的.sh文件
但是这些目录是系统定义并分配好的,有具体含义的目录,我们尽量不要去污染它
可以看下系统环境变量$PATH


如果你想像执行cd ls 那样执行你的脚本文件,可以把脚本文件所在目录放在 PATH环境变量中,这样你的脚本就可以作为命令来执行
cd find 等命令后面可以传一些变量参数,那如何给我们自己写的shell脚本传递参数呢??这就涉及到特殊参数
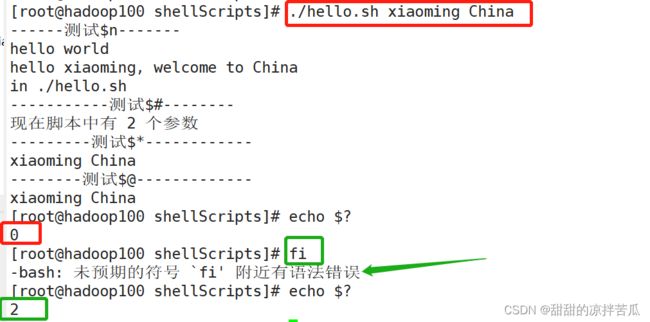
1、$n

vim hello.sh

$0 会自动获取当前脚本的名称,并且展示的是绝地/相对路径(取决于执行命令时使用的是什么)执行脚本时不用传参


双引号内 如果有$hello 那shell会把它当作一个变量的调用,如果你之前定义了一个hello变量,那么就会输出这个变量值,但是如果使用单引号就就不会把$后面的作为变量名
但是如果字符串中需要用到变量的值就必须使用双引号

2、$#


不会把$0 算进去

3、$* 和$@



4、$?

最后一次执行的命令的状态 不是指这个脚本文件最后一次执行的返回状态,是这个shell进程上一次执行的命令返回的状态,上一次可能是脚本的执行也可能是其他命令的执行
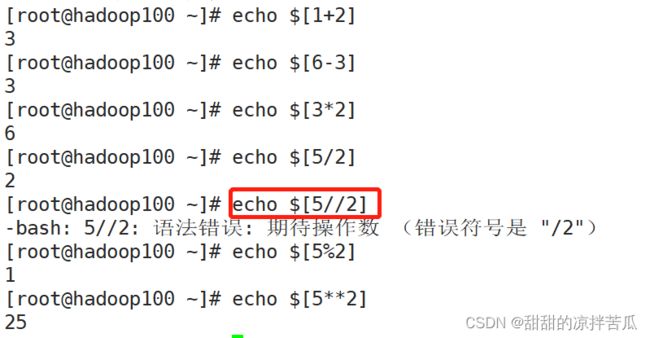
4.3.7 运算符
语法:$((算数运算式)) 或 $[运算式]
4.3.8 条件判断
语法:test 条件表达式 或者 [ 条件表达式 ] 表达式左右要有空格,
1、字符串比较
使用 = != 需要注意的是 = 和 != 左右也要有空格


中括号里面只有2个空格 ,则会认为是false

2、数字比较
2个数字是否相等也可以使用= 和 != 但是Linux实际是把他们2个当作字符串进行比较的
使用-eq等只能比较整数,比较运算左右也必须空格都可以,而且必须是2个数字的比较


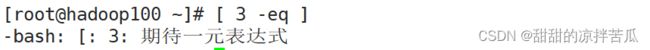
3、文件判断

对于文件权限的判断,当前用户有这个权限的,那就是True, echo $? 就返回0

4、多条件组合判断
&& —— 前一个条件判断命令执行成功(Ture)后,才执行下一个条件判断命令,这里的执行成功指的是echo $? 返回的是0
|| —— 前一个条件判断命令执行失败(False)后,才执行下一个条件判断命令,这里的执行失败指的是echo $? 返回的是1

[ -w test.sh ] && echo "追加内容" >> test.sh || sudo chmod o+w test.sh
4.3.9 if 单分支
语法:
if [ 条件判断 ];then 程序;fi
if [ 条件判断 ];then
程序
fi
if [ 条件判断 ]
then
程序
fi
if后面必须要有空格,中括号里面条件判断左右也都必须有一个空格

如果需要比较字符串是否相等,最好把字符串用双引号包含并在后面加一个x,避免因为一个不存在导致脚本报错 if [ "$1"x = "China"x ]
如果if里面需要有多个判断条件,可以使用-a 或者 -o连接,-a表示and,-o表示or

4.3.10 if 多分支
语法:if 后面的条件判断一般都是使用[ ]
if [ 条件判断式 ]
then
程序
elif [ 条件判断式 ]
then
程序
elif [ 条件判断式 ]
then
程序
else
程序
fi
#!/bin/bash
echo '如果if后面使用中括号,数值的比较不能使用数学的常规比较运算符,可以使用-eq -ne -gt -ge -lt
-le , 并且有多个判断条件,需要使用-a 或者 -o连接,-a表示and,-o表示or'
if [ $2 -ge 0 -a $2 -le 750 ]
then
if [ $2 -lt 450 ]
then
echo "可以复习一年"
elif [ $2 -ge 450 -a $2 -lt 550 ]
then
echo "报考二本"
elif [ $2 -ge 550 -a $2 -lt 650 ]
then
echo "报考一本"
else
echo "报考重点大学"
fi
else
echo "分数不合规"
fi
想在shell中的使用双小括号(()),括号里面是可以使用数学上的运算式,所以数学常规的比较运算符(> < >= <= == !=)和算数运算符(+ - * / % **)都是可以用的,如果要拿到运算结果,在双小括号前面加一个$就可以了 $(())
条件判断中常使用比较运算,当有多个条件判断时可以使用& 或者 | 表示逻辑关系
比较运算的结果就是true false 算术运算的结果就是计算结果
在shell中使用$[] 进行数学算数运算也可以使用常规的算数运算符(+ - * / % **),如sum=$[ $sum+$i ] 但是建议还是使用$(())
在shell中使用$[]进行数学的比较运算不能使用常规的比较运算符(> < >= <= == !=),可以
使用-eq等于 -ne不等于 -gt大于 -ge大于等于 -lt 小于 -le小于等于
并且在条件判断语句里面,如果有多个条件需要设置逻辑关系,需要用-a -o 表示and or 不能使用& |


对于字符串变量只能用比较运算符(!= = ==)来判断:一般都是在条件判断中使用

如果if后面使用双小括号,并且里面有多个判断条件,可以使用& 或者|连接
#!/bin/bash
echo '如果if后面使用双小括号,并且里面有多个判断条件,可以使用& 或者|连接'
if ((0 <= $1 & $1 <= 750))
then
if (($1 < 450))
then
echo "可以复习一年"
elif ((450 <= $1 & $1 < 550))
then
echo "报考二本"
elif ((550 <= $1 & $1 < 650))
then
echo "报考一本"
else
echo "报考重点大学"
fi
else
echo "分数不合规"
fi
~ 4.3.11 case多分支
case $变量名 in
"值1")
程序1
;;
"值2")
程序2
;;
"值3")
程序3
;;
*)
以上情况都不满足时,执行兜底程序
;;
esac

#!/bin/bash
echo "-------测试case分支-----"
case $1 in
"985")
echo "分数要求650以上"
;;
"211")
echo "分数要求600以上"
;;
"一本")
echo "分数要求550以上"
;;
"二本")
echo "分数要求450以上"
;;
*)
echo "建议再复习一年"
;;
esac
4.3.12 for循环
语法:for后面的条件判断一般都使用双小括号 (())
for ((初始值;循环控制条件;变量变化))
do
程序
done
for 变量名 in 值1 值2 值3...
do
程序
done
如果值很多的话:
for 变量名 in {1..100}
do
程序
done
这里的{}是Linux shell的内部运算符,表示一个序列,不同的是{}里面不能用变量,必须直接指定数值
for 后面的初始值和( 之间可以有空格也可以没有空格,同样的变量变化和)之间可以有空格也可以没有
#~/bin/bash
for (( i=1; i <= $1; i++ ))
do
# 2个数字相加,不能直接使用+号,因为这是字符串的拼接逻辑,需要在外面加上中括号$[]
# sum=$[ $sum + $i ]
# sum=$(($sum+$i))
# 使用let 更简单易懂
let sum+=i
done
echo $sum
for i in {1..100}
do
# newSum=$(($newSum+$i))
# 使用let 更简单易懂
let newSum+=i
done
echo $newSum

外侧使用双小括号(()),里面就可以使用数学比较运算符和算数运算符了
$*和$@都代表执行脚本时命令行传入的全部参数
上面的$*和$@的区别:
#!/bin/bash
echo '==============$*================'
for param in $*
do
echo $param
done
echo '===============$@================'
for param in $@
do
echo $param
done

#!/bin/bash
echo '==============$*================'
for param in "$*"
do
echo $param
done
echo '===============$@================'
for param in "$@"
do
echo $param
done

加上引号后,$*会把所有参数合并为一个整体
而$@加上引号后依旧会保持每个参数的独立
4.3.13 while循环
语法:while 后面的条件判断一般使用 [ ]
while [ 条件判断 ]
do
程序
done
条件判断内如果使用到除了命令行传入的参数以外的的其他参数,需要在while外层进行定义和赋值
echo '===========while循环================'
i=1
while [ $i -le $1 ]
do
# 使用let这关键字 后面就可以写正常的算数表达式了
let sum2+=i
let i++
done
echo $sum2
4.3.14 read 读取控制台输入



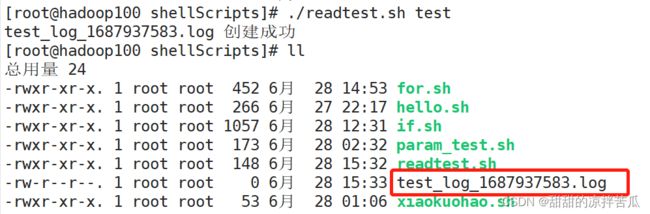
4.3.15 系统函数
在脚本内需要获取命令执行后返回的数据时,需要把命令放在$(命令) 表示获取命令执行后返回的数据

1、basename
语法:basename 文件名路径字符串 文件扩展名

取路径里面的文件名
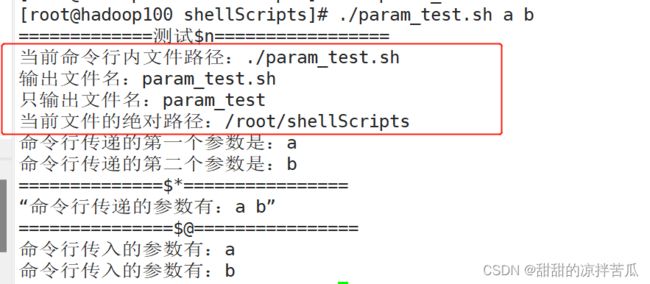
#!/bin/bash
echo '=============测试$n================='
echo "当前命令行内文件路径:$0"
echo "输出文件名:$(basename $0)"
echo "只输出文件名:$(basename $0 .sh)"
# cd $(dirname $0)
# echo "当前文件的绝对路径:$(pwd)"
echo "当前文件的绝对路径:$(cd $(dirname $0);pwd)"
echo "命令行传递的第一个参数是:$1"
echo "命令行传递的第二个参数是:$2"
echo '==============$*================'
for param in "$*"
do
echo “命令行传递的参数有:$param”
done
echo '===============$@================'
for param in "$@"
do
echo "命令行传入的参数有:$param"
done
虽然这个命令名字叫basename 但是这个其实就只是一个字符串截取的逻辑,如果传入随意字符串也会按照逻辑返回截取部分
2、dirname
dirname 文件路径字符串
获取文件的绝对路径 $(cd $(dirname $0);pwd)
和前面的basename互补,这个dirname截取的是字符串最后一个/及其前面的内容

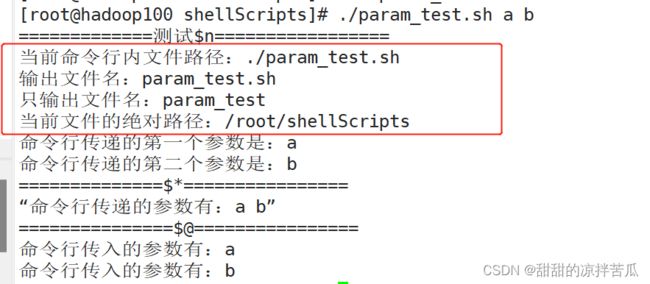
#!/bin/bash
echo '=============测试$n================='
echo "当前命令行内文件路径:$0"
echo "输出文件名:$(basename $0)"
echo "只输出文件名:$(basename $0 .sh)"
# cd $(dirname $0)
# echo "当前文件的绝对路径:$(pwd)"
echo "当前文件的绝对路径:$(cd $(dirname $0);pwd)"
echo "命令行传递的第一个参数是:$1"
echo "命令行传递的第二个参数是:$2"
4.3.16 自定义函数

前面的 [function] 可以不写
函数的形参也不用定义,直接在里面用$1 $2 ..... $9 ${10} ${11} 直接用就行。
#!/bin/bash
function add(){
let s=$1+$2
echo $s
}
read -t 10 -p "请输入求和计算的第一个数字:" a
read -t 10 -p "请输入求和计算的第二个数字:" b
# 函数想要返回什么内容,就在函数内用echo输出
# 调用函数后把函数打印的结果再赋值给sum
sum=$(add $a $b)
echo "求和结果是:"$sum

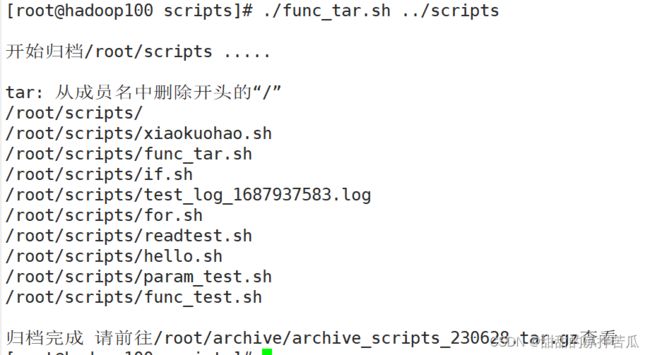
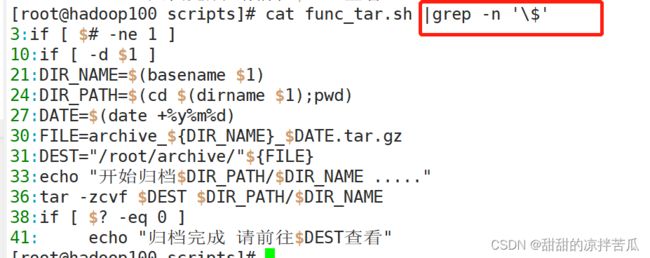
4.3.17 案例-归档文件
tar -zcvf
#!/bin/bash
if [ $# -ne 1 ]
then
echo "参数个数不对"
exit
fi
if [ -d $1 ]
then
echo
else
echo
echo "目录不存在"
echo
exit
fi
# 获取原始目录名
DIR_NAME=$(basename $1)
# 获取原始目录所在文件夹的绝对路径
DIR_PATH=$(cd $(dirname $1);pwd)
# 获取当前日期
DATE=$(date +%y%m%d)
# 拼接出要把原始目录 打包归档的目的地路径和归档文件名
# 为了不把变量名和文件名设置的下划线搞混了,把DIR_NAME用花括号括起来 ${DIR_NAME}
FILE=archive_${DIR_NAME}_$DATE.tar.gz
DEST="/root/archive/"${FILE}
echo "开始归档$DIR_PATH/$DIR_NAME ....."
echo
tar -zcvf $DEST $DIR_PATH/$DIR_NAME
if [ $? -eq 0 ]
then
echo
echo "归档完成 请前往$DEST查看"
else
echo "归档失败"
echo
fi
exit
删除不用的定时任务

创建定时任务执行脚本,每天2点整执行脚本

4.3.18 正则简单用法
Linux中grep sed awk 等文本处理工具都支持通过正则表达式进行模式匹配。
1、常规匹配
不使用任何匹配符 直接对指定内容进行匹配筛选

2、常用特殊字符
^ 匹配一行的开头
![]()
$ 匹配一行的结束
^$ 表示匹配空字符串,显示空行:

. 匹配一个任意字符
* 不单独使用,和上一个字符连用,表示匹配上一个字符0次或多次

.* 可以匹配任意长度的字符串(包括空字符串)
+ 不单独使用,和上一个字符连用,表示匹配上一个字符1次或多次
?不单独使用,和上一个字符连用,表示匹配上一个字符0次或1次
{n,m} 不单独使用,和上一个字符连用,表示匹配上一个字符n次
- a{1, 4} 匹配 a 字符 1 到 4次 如 a aa aaa aaaa
- [0-9]{3} 匹配连续 3 个数字
- [a-z]{1,} 匹配小写字母字符 1次到无数次
- [a-z]{,5} 匹配小写字母字符 最多5次
4.3.19 正则扩展用法
字符区间[] —— 表示匹配某个范围内的一个字符
[6,8] 匹配6或者8
[a-c,x-z] 匹配a-c 或者 s-z之间任意一个字符
[0-9] 匹配一个 0-9 范围内的数字
[s-z] 匹配一个 s-z 范围内的字符
[a-z]* 匹配任意长度的 字符串
[0-9]* 匹配任意长度的数字字符串
\ 表示转义,不会单独使用,后面跟要转义的字符
使用正则匹配手机号:一共11位
第一位:必须是1
第二位:3或 4或 5或 7或 8
第3位~11位:0-9
^1[3-4,7-8][0-9]{9}$
grep当前默认是不支持{}这种匹配模式,需要在grep后面加 -E

4.3.20 文本处理工具cut

cut可以放在管道|后面,获取管道之前命令执行得到的结果作为cut处理的文本
-f 指定要选取第几列
-d 指定分隔符,按照给定的分隔符对文件内容进行cut
-c 按字符进行切割

-d " " 先按照一个空格作为分隔符
第一行可以切分为3列
第二行可以切分为3列
第三行可以被切分为2列(huahua 和20之间是制表符)
第四行 lei和lei之间是2个制表符,没有空格,所以只有1列
-f 1 按照上面切割好的选取第一列

如果要选取多列使用: -f 1,2 或者 -f 2,1 没有区别, 都是从小列到大列展示
还可以看出虽然是按照空格切割的,但是空格还在并不是把空格切没了
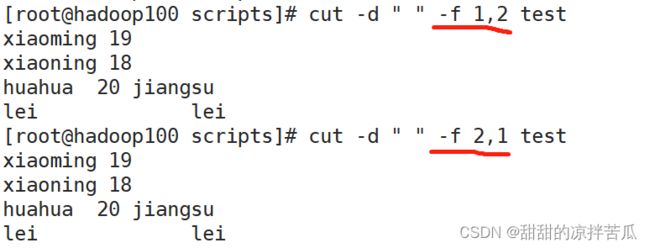
想要cut得到1 6 7列并输出
同样 虽然是按照冒号 : 切割,但是冒号还在。
如果是连续选取多个列,可以使用n-m,表示从第n列到第m列 n小于m
如果是从第n列直到最后,可以写为n-
如果时从第1列到第n列,可以写为-n

也可以把cut得到的结果输出到指定文件内:
>> 在指定文件末尾追加内容
> 覆盖指定文件内的内容
文件不存在时会自动创建

获取虚拟机局域网IP
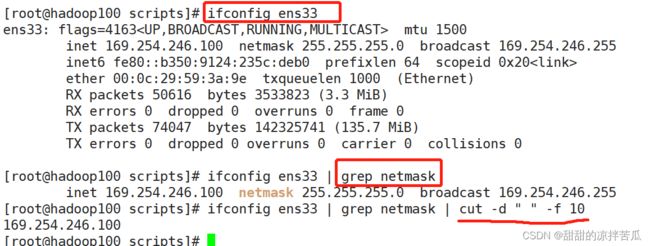
获取虚拟机全部网络IP

4.3.21 文本处理工具awk基本功能



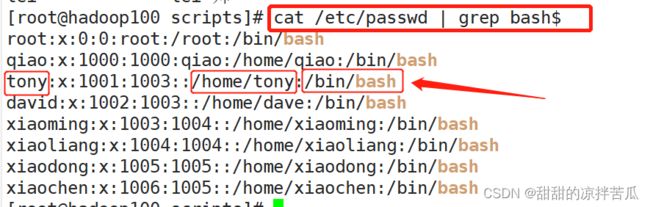
cat /etc/passwd | awk -F ":" '/^root/ {print $7}'
先获取以root开头的那一行 ^root
再按照冒号:切割,切割后得到了7个列 -F ":"
把这7列以参数形式传递给print,print要打印输出的是第7列 print $7

获取以root开头的行,打印输出第1和第7列,中间以逗号,分隔
$1 和$7都是字符串,所以可以再中间加一个逗号字符串进行拼接即可

关键字:BEGIN 和 END
BEGIN 在所有数据读取之前执行,END在所有数据执行完操作后再执行


4.3.22 文本处理工具awk扩展功能
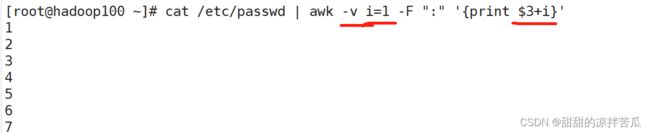
把获取到的数据进行算数运算
获取/etc/passwd里面的用户id 之后加1输出,在print里面可以直接使用算数运算符


在awk里面定义变量并进行数据运算,使用变量值时直接用变量名即可,不用在变量名前加$%,
awk的内置变量:



输出ifconfig获取的网络信息中所有空行的行号

获取ifconfig获取的网络信息中的IP

awk默认就是按照空格分割的,所以用不用 -F " "都可以
inet前面有8个空格,awk有一个特性,如果行开头有多个空格,那么以空格分割时前面那些空格不会考虑,直接从有内容的开始,所以第二个参数就是我们要的IP地址

4.3.23 案例-发送消息

使用who am i 可以查看当前登录用户的信息,包括用户名、终端、日期时间和局域网IP
![]() 这里展示的IP就是物理主机网络连接里面的虚拟网络8
这里展示的IP就是物理主机网络连接里面的虚拟网络8
使用who可以查看当前登录这个虚拟机的全部用户信息

使用mesg命令可以查看当前登录用户自己的消息功能是否打开
可以使用mesg n关闭消息通知功能
使用mesg y打开消息通知功能

使用write 命令给登录Linux系统的其他用户发消息
语法:write 用户名 登录的终端 回车后就可以输入消息内容,按回车即可发送

 按ctrl c 退出发送消息
按ctrl c 退出发送消息
#!/bin/bash
# 查看用户是否登录
# 从who命令获取的登录当前Linux系统的用户列表中查找匹配指定用户名的数据who | grep $1
# -i 不区分 输入的用户名的大小写 who | grep -i $1
# 如果这个用户登录了多个终端,只选择1个 -m 1
# -m :是maxcount 最大数
# 取到1条用户登录信息后需要选取这行数据的第一列,第一列才是用户名
login_user=$(who | grep -i -m 1 $1 | awk -F " " '{print $1}')
# 使用-z 判断当前获取的用户名是不是空的
if [ -z $login_user ]
then
echo "用户$1未登录"
echo "脚本退出"
exit
fi
# 查看用户是否打开了消息通知
mesg_open=$(who -T | grep -i -m 1 $1 | awk -F " " '{print $2}')
if [ $mesg_open != "+" ]
then
echo "用户$1没有开启消息通知"
echo "脚本退出"
exit
fi
# 验证输入的消息是否为空
if [ -z $2 ]
then
echo "消息内容为空"
echo "脚本退出"
exit
fi
# 获取要发送的消息
# $* 会把命令行输入的参数作为一个整体
whole_msg=$(echo $* | cut -d " " -f 2-)
# 获取用户登录的终端
user_terminal=$(who | grep -i -m 1 $1 | awk -F " " '{print $2}')
# 可以发送消息
echo $whole_msg | write $login_user $user_terminal
if [ $? != 0 ]
then
echo "发送失败"
else
echo "发送成功"
fi
exit
~ 

