高效数据传输:轻松上手将Kafka实时数据接入CnosDB

本篇我们将主要介绍如何在 Ubuntu 22.04.2 LTS 环境下,实现一个Kafka+Telegraf+CnosDB 同步实时获取流数据并存储的方案。在本次操作中,CnosDB 版本是2.3.0,Kafka 版本是2.5.1,Telegraf 版本是1.27.1
随着越来越多的应用程序架构转向微服务或无服务器结构,应用程序和服务的数量每天都在增加。用户既可以通过实时聚合,也可以通过输出为测量或指标的计算,来处理数量不断增加的时间序列数据。面对产生的海量数据,用户可以通过多种方式来捕获和观察系统中数据的变化,在云原生环境中,最流行的一种是使用事件。
Apache Kafka是一个耐用、高性能的消息系统,也被认为是分布式流处理平台。它可应用于许多用例,包括消息传递、数据集成、日志聚合和指标。而就指标而言,仅有消息主干或代理是不够的。虽然 Apache Kafka 很耐用,但它并不是为运行指标和监控查询而设计的。这恰恰正是 CnosDB 的长处。
架构方案
通过将这Kafka、Telegraf和CnosDB 三者结合起来,可以实现数据的完整流程:
- 数据生成:使用传感器、设备或其他数据源产生数据,并将其发送到Kafka主题。
- Kafka 消息队列:Kafka 接收并存储数据流,确保数据安全和可靠性。
- Telegraf 消费者:Telegraf 作为 Kafka 的消费者,订阅 Kafka 主题并获取数据流。
- CnosDB 数据存储:经过预处理的数据由 Telegraf 发送到 CnosDB 中进行时序数据的存储。
整体的应用程序架构如图所示:


Kafka
Apache Kafka 是一个开源分布式流处理平台,它被设计用于处理实时数据流,具有高可靠性、高吞吐量和低延迟的特点,目前已经被大多数公司使用。它的使用方式非常多样化,包括:
- 流处理:它通过存储实时事件以进行聚合、丰富和处理来提供事件主干。
- 指标:Apache Kafka 成为许多分布式组件或应用程序(例如微服务)的集中聚合点。这些应用程序可以发送实时指标以供其他平台使用,包括 CnosDB。
- 数据集成:可以捕获数据和事件更改并将其发送到 Apache Kafka,任何需要对这些更改采取行动的应用程序都可以使用它们。
- 日志聚合:Apache Kafka 可以充当日志流平台的消息主干,将日志块转换为数据流。
几个核心概念
- 实例(Broker):Kafka的Broker是Kafka集群中的服务器节点,负责存储和转发消息,提供高可用性、容错性和可靠性。
- 主题(Topic):Apache Kafka 中的 topic ,是逻辑存储单元,就像关系数据库的表一样。主题通过分区通过代理进行分发,提供可扩展性和弹性。
- 生产者(Producer):生产者将消息发布到Kafka的指定主题。生产者可以选择将消息发送到特定的分区,也可以让Kafka自动决定分配策略。
- 消费者(Consumer):消费者从指定主题的一个或多个分区中读取消息。消费者可以以不同的方式进行组织,如单播、多播、消费者组等。
- 发布-订阅模式:是指生产者将消息发布到一个或多个主题,而消费者可以订阅一个或多个主题,从中接收并处理消息。
简单来说就是,当客户端将数据发送到 Apache Kafka 集群实例时,它必须将其发送到某个主题。
此外,当客户端从 Apache Kafka 集群读取数据时,它必须从主题中读取。向 Apache Kafka 发送数据的客户端成为生产者,而从 Kafka 集群读取数据的客户端则成为消费者。数据流向示意图如下:
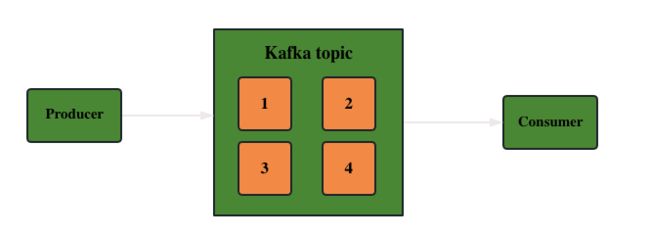
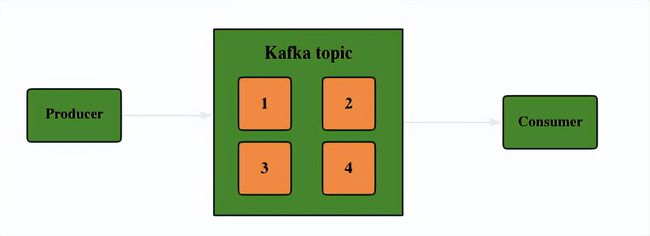
注:这里没有引入更复杂的概念,如topic分区、偏移量、消费者组等,用户可自行参考官方指导文档学习:
Kafka:【https://kafka.apache.org/documentation/#gettingStarted】
部署 Kafka
下载并安装Kafka【https://kafka.apache.org/】
1.前提:需确保有 JDK 环境和 Zookeeper 环境,如果没有可以使用下面的命令进行安装:
sudo apt install openjdk-8-jdk
sudo apt install zookeeper2.下载 Kafka 安装包并解压
wget https://archive.apache.org/dist/kafka/2.5.1/kafka_2.12-2.5.1.tgz
tar -zxvf kafka_2.12-2.5.1.tgz3.进入解压后的 Kafka 目录
cd kafka_2.12-2.5.14.修改$KAFKA_HOME/config/server.properties的配置文件(可按需修改端口、日志路径等配置信息)
5.保存并关闭编辑器。运行下面的命令来启动Kafka:
bin/kafka-server-start.sh config/server.propertiesKafka 将在后台运行,并通过默认的 9092 端口监听连接。
Telegraf
Telegraf 是一个开源的服务器代理程序,用于收集、处理和传输系统和应用程序的指标数据。Telegraf 支持多种输入插件和输出插件,并且能够与各种不同类型的系统和服务进行集成。它可以从系统统计、日志文件、API 接口、消息队列等多个来源采集指标数据,并将其发送到各种目标,如 CnosDB 、Elasticsearch、Kafka、Prometheus 等。这使得 Telegraf 非常灵活,可适应不同的监控和数据处理场景。
- 轻量级:Telegraf被设计为一个轻量级的代理程序,对系统资源的占用相对较小,可以高效运行在各种环境中。
- 插件驱动:Telegraf使用插件来支持各种输入和输出功能。它提供了丰富的插件生态系统,涵盖了众多的系统和服务。用户可以根据自己的需求选择合适的插件来进行指标数据的采集和传输。
- 数据处理和转换:Telegraf具有灵活的数据处理和转换功能,可以通过插件链(Plugin Chain)来对采集到的指标数据进行过滤、处理、转换和聚合,从而提供更加精确和高级的数据分析。
部署 Telegraf
1.安装 Telegraf
sudo apt-get update && sudo apt-get install telegraf2.切换到 Telegraf 的默认配置文件所处目录 /etc/telegraf 下
3.在配置文件 telegraf.config 中添加目标 OUTPUT PLUGIN
[[outputs.http]]
url = "http://127.0.0.1:8902/api/v1/write?db=telegraf"
timeout = "5s"
method = "POST"
username = "root"
password = ""
data_format = "influx"
use_batch_format = true
content_encoding = "identity"
idle_conn_timeout = 10按需修改的参数:
url:CnosDB 地址和端口
username:连接 CnosDB 的用户名
password:连接 CnosDB 的用户名对应的密码注:其余参数可与上述配置示例中保持一致
4.在配置文件中将下面的配置注释放开,可按需修改
[[inputs.kafka_consumer]]
brokers = ["127.0.0.1:9092"]
topics = ["oceanic"]
data_format = "json"参数:
brokers:Kafka 的 broker list
topics:指定写入 Kafka 目标的 topic
data_format:写入数据的格式注:其余参数可与上述配置示例中保持一致
5.启动 Telegraf
telegraf -config /etc/telegraf/telegraf.confCnosDB
部署 CnosDB
详细操作请参考: CnosDB 安装
【https://docs.cnosdb.com/zh/latest/start/install.html】
整合
Kafka创建topic
1.进入 kafka 的 bin 文件夹下
2.执行命令,创建 topic
./kafka-topics.sh --create --topic oceanic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1Python 模拟写入数据到Kakfa
1.编写代码:
import time
import json
import random
from kafka import KafkaProducer
def random_pressure():
return round(random.uniform(0, 10), 1)
def random_tempreture():
return round(random.uniform(0, 100), 1)
def random_visibility():
return round(random.uniform(0, 100), 1)
def get_json_data():
data = {}
data["pressure"] = random_pressure()
data["temperature"] = random_temp_cels()
data["visibility"] = random_visibility()
return json.dumps(data)
def main():
producer = KafkaProducer(bootstrap_servers=['ip:9092'])
for _ in rang(2000):
json_data = get_json_data()
producer.send('oceanic', bytes(f'{json_data}','UTF-8'))
print(f"Sensor data is sent: {json_data}")
time.sleep(5)
if __name__ == "__main__":
main()2.运行Python脚本
python3 test.py查看 kafka topic 中的数据
1.执行下面查看指定 topic 数据的命令
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic oceanic --from-beginning
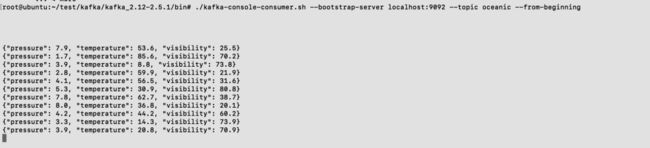
查看同步到 CnosDB 中的数据
1.使用工具连接到CnosDB
cnosdb-cli2.切换到指定库
\c public3.查看数据
select * from kafka_consumer;

补充阅读
1.使用 Telegraf 采集数据并写入 CnosDB:
https://docs.cnosdb.com/zh/latest/versatility/collect/telegraf.html
2.Python 连接器:
https://docs.cnosdb.com/zh/latest/reference/connector/python.html
3.CnosDB 快速开始:
https://docs.cnosdb.com/zh/latest/start/quick_start.html