通用分页【下】(将分页封装成标签)
目录
一、debug调试
1、什么是debug调试?
2、debug调试步骤
3、实践
二、分页的核心
三、优化
分页工具类
编写servlet
jsp代码页面:
分页工具类PageBean完整代码
四、分页标签
jsp代码
编写标签
tld文件
助手类
改写servlet
解析:
编码问题
一、debug调试
1、什么是debug调试?
调试(debugging)是指在软件开发过程中,通过识别、定位和解决程序错误或问题的过程。调试的目的是找出代码中的错误、异常或不正常的行为,并修复它们,以确保程序能够按照预期的方式运行。
调试是一个重要的开发技巧,可以帮助开发人员理解程序的执行过程、找出错误的原因,并从中学习和改进。调试通常包括以下步骤:
- 识别问题:在程序产生错误或不正常行为时,首先需要确认问题的存在,并尽可能准确地描述问题的性质和触发方式。
- 定位问题:确定问题的发生位置,即问题引发的具体代码行或功能模块。可以通过观察错误消息、日志、异常堆栈跟踪等信息来定位问题。
- 分析原因:深入分析问题,找出导致问题的原因。这可能涉及到检查变量值、代码逻辑、输入数据、函数调用等方面的信息。
- 修复问题:根据分析结果,采取适当的措施修复问题。这可能包括修改代码、修正数据输入、重新设计算法等。
- 验证修复:在修改代码之后,重新运行程序以验证修复是否成功。使用测试数据和场景进行测试,并确保程序现在能够正常执行。
调试可以使用不同的工具和技术来辅助,例如打印输出、日志记录、调试器(debugger)等。调试是开发过程中不可或缺的一部分,可以帮助开发人员提高代码质量、加快解决问题的速度,并优化程序的性能和可靠性。
2、debug调试步骤
调试(debugging)是指在软件开发过程中,通过识别、定位和解决程序错误或问题的过程。调试的目的是找出代码中的错误、异常或不正常的行为,并修复它们,以确保程序能够按照预期的方式运行。
调试是一个重要的开发技巧,可以帮助开发人员理解程序的执行过程、找出错误的原因,并从中学习和改进。调试通常包括以下步骤:
- 识别问题:在程序产生错误或不正常行为时,首先需要确认问题的存在,并尽可能准确地描述问题的性质和触发方式。
- 定位问题:确定问题的发生位置,即问题引发的具体代码行或功能模块。可以通过观察错误消息、日志、异常堆栈跟踪等信息来定位问题。
- 分析原因:深入分析问题,找出导致问题的原因。这可能涉及到检查变量值、代码逻辑、输入数据、函数调用等方面的信息。
- 修复问题:根据分析结果,采取适当的措施修复问题。这可能包括修改代码、修正数据输入、重新设计算法等。
- 验证修复:在修改代码之后,重新运行程序以验证修复是否成功。使用测试数据和场景进行测试,并确保程序现在能够正常执行。
调试可以使用不同的工具和技术来辅助,例如打印输出、日志记录、调试器(debugger)等。调试是开发过程中不可或缺的一部分,可以帮助开发人员提高代码质量、加快解决问题的速度,并优化程序的性能和可靠性。
3、实践
1)debug启动项目

2)在调试的地方使用断点
这里会有一个小钥匙
你在你的浏览器重新加载
我们回到运行的界面,可以看到debug的窗口
鼠标放在上面可以看到结果,我们点击键盘里的F6可以查看下一步
禁用debug断点

中间还有些是省略的,大家可以查相关资料
二、分页的核心
- 当我们在第一次搜索的里面搜索你想要的东西的时候,后台分页拿到:bname=XXX、page=1、rows=100、pagintion=true(可传可不传,但是不分页下拉框需求时必须传入false)
- 我们第二次查询(下一页)只是页码进行改变:bname=XXX、page=2、rows=100、pagintion=true(可传可不传,但是不分页下拉框需求时必须传入false)
- 我们第三次查询(尾页)相比第二次只是页码进行改变,其他都不变:bname=XXX、page=2、rows=100、pagintion=true(可传可不传,但是不分页下拉框需求时必须传入false)
【总结】相比上一次的查询,我们只是页码进行了一个改变,其他的查询都不会改变
三、优化
优化pageBean
增加一个属性url,保留上一次发送请求的地址。
增加一个属性pareMap,保留上一次发送请求携带的参数。
req.getParameterMap();增加一个最大页的方法。
增加一个下一页的方法。
增加一个上一页的方法。
初始化pagebean的方法。
分页工具类
在这之前我们先要找到我们的代码应该放在上面位置,以便我们更好的去编写我们的代码
我们需要在PageBean增加以上的属性和方法
// 上一次查询的url
private String url;
// 上一次查询所携带的查询条件
private Map parameterMap = new HashMap();
private boolean pagination = true;// 是否分页
/**
* 对pagebean进行初始化
*
* @param req
*/
public void setRequest(HttpServletRequest req) {
// 初始化jsp页面传递过来的当前页
this.setPage(req.getParameter("page"));
// 初始化jsp页面传递过来的页大小
this.setRows(req.getParameter("rows"));
// 初始化jsp页面传递过来是否分页
this.setPagination(req.getParameter("pagination"));
// 保留上一次的查询请求
this.setUrl(req.getRequestURL().toString());
// 保留上一次的查询条件
this.setParameterMap(req.getParameterMap());
}
private void setPagination(String pagination) {
// 只有填写了false字符串,才代表不分页
if (StringUtils.isNotBlank(pagination))
this.setPagination(!"false".equals(pagination));
}
/**
* 获得起始记录的下标
*
* @return
*/
public int getStartIndex() {
return (this.page - 1) * this.rows;
}
// 上一页
public int getPrevPage() {
return this.page > 1 ? this.page - 1 : this.page;
}
// 下一页
public int getNextPage() {
return this.page < this.getMaxPage() ? this.page + 1 : this.page;
}
// 最大页
public int getMaxPage() {
return this.total % this.rows == 0 ? this.total / this.rows : (this.total / this.rows) + 1;
} 编写servlet
package com.tgq.servlet;
import java.io.IOException;
import java.util.Map;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.tgq.util.PageBean;
/**
* 分页的Servlet
*/
@WebServlet("/PageServlet")
public class PageServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doPost(request, response);
}
@SuppressWarnings("unused")
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String bname = request.getParameter("bname");
// map包含了浏览器传递到后台的所有参数的键值对
Map map = request.getParameterMap();
// 浏览器请求地址
String url = request.getRequestURI().toString();
request.getRequestDispatcher("index.jsp").forward(request, response);
}
}
因为我们在PageBean增加了方法,所以我们servlet也进行了一定的变化
package com.tgq.servlet;
import java.io.IOException;
import java.util.Map;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.tgq.util.PageBean;
/**
* 分页的Servlet
*/
@WebServlet("/PageServlet")
public class PageServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doPost(request, response);
}
@SuppressWarnings("unused")
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// String bname = request.getParameter("bname");
// // map包含了浏览器传递到后台的所有参数的键值对
// Map map = request.getParameterMap();
// // 浏览器请求地址
// String url = request.getRequestURI().toString();
PageBean pb = new PageBean();
pb.setRequest(request);
request.setAttribute("pb", pb);
request.getRequestDispatcher("index.jsp").forward(request, response);
}
}
我们运行debug可以看到
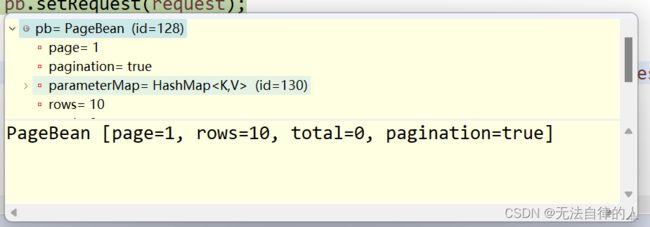
jsp代码页面:
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
书籍列表
${pageBean}
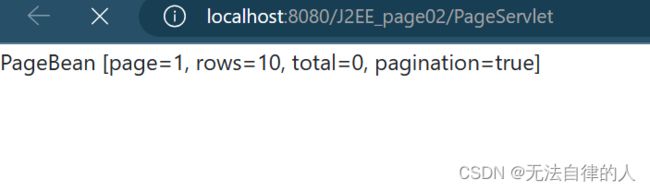
输出结果:
分页工具类PageBean完整代码
package com.tgq.util;
import java.util.HashMap;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
/**
* 分页工具类
*
* @author tgq
*
*/
public class PageBean {
private int page = 1;// 页码
private int rows = 10;// 页大小
private int total = 0;// 总记录数
// 上一次查询的url
private String url;
// 上一次查询所携带的查询条件
private Map parameterMap = new HashMap();
private boolean pagination = true;// 是否分页
/**
* 对pagebean进行初始化
*
* @param req
*/
public void setRequest(HttpServletRequest req) {
// 初始化jsp页面传递过来的当前页
this.setPage(req.getParameter("page"));
// 初始化jsp页面传递过来的页大小
this.setRows(req.getParameter("rows"));
// 初始化jsp页面传递过来是否分页
this.setPagination(req.getParameter("pagination"));
// 保留上一次的url查询请求
this.setUrl(req.getRequestURL().toString());
// 保留上一次的查询条件/参数
this.setParameterMap(req.getParameterMap());
}
private void setPagination(String pagination) {
// 只有填写了false字符串,才代表不分页
if (StringUtils.isNotBlank(pagination))
this.setPagination(!"false".equals(pagination));
}
/**
* 获得起始记录的下标
*
* @return
*/
public int getStartIndex() {
return (this.page - 1) * this.rows;
}
// 上一页
public int getPrevPage() {
return this.page > 1 ? this.page - 1 : this.page;
}
// 下一页
public int getNextPage() {
return this.page < this.getMaxPage() ? this.page + 1 : this.page;
}
// 最大页
public int getMaxPage() {
return this.total % this.rows == 0 ? this.total / this.rows : (this.total / this.rows) + 1;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public Map getParameterMap() {
return parameterMap;
}
public void setParameterMap(Map parameterMap) {
this.parameterMap = parameterMap;
}
private void setRows(String rows) {
if (StringUtils.isNotBlank(rows))
this.setRows(Integer.valueOf(rows));
}
private void setPage(String page) {
if (StringUtils.isNotBlank(page))
this.setPage(Integer.valueOf(page));
}
public PageBean() {
super();
}
public int getPage() {
return page;
}
public void setPage(int page) {
this.page = page;
}
public int getRows() {
return rows;
}
public void setRows(int rows) {
this.rows = rows;
}
public int getTotal() {
return total;
}
public void setTotal(int total) {
this.total = total;
}
public void setTotal(String total) {
this.total = Integer.parseInt(total);
}
public boolean isPagination() {
return pagination;
}
public void setPagination(boolean pagination) {
this.pagination = pagination;
}
@Override
public String toString() {
return "PageBean [page=" + page + ", rows=" + rows + ", total=" + total + ", pagination=" + pagination + "]";
}
} 四、分页标签
分页代码:我们需要
HTML 分页条
JS
form
我们需要利用标签
tld
助手类
jsp代码
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
书籍列表
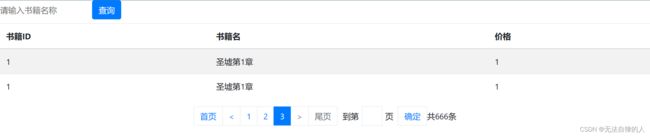
书籍ID
书籍名
价格
1
圣墟第1章
1
1
圣墟第1章
1
zzz
编写标签
tld文件
JSTL 1.1 core library
JSTL core
1.1
t
http://jsp.tgq.cn
page
com.tgq.tag.PageTag
JSP
pageBean
true
true
助手类
package com.tgq.tag;
import java.io.IOException;
import java.util.Map;
import java.util.Set;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.JspWriter;
import javax.servlet.jsp.tagext.BodyTagSupport;
import com.tgq.util.PageBean;
/**
*
* @author tgq
*
*/
public class PageTag extends BodyTagSupport {
private PageBean pageBean;
public PageBean getPageBean() {
return pageBean;
}
public void setPageBean(PageBean pageBean) {
this.pageBean = pageBean;
}
@Override
public int doStartTag() throws JspException {
return SKIP_BODY;
}
}
我们要做的是把
替换成标签
所以我们要在助手类进行一个拼接,拼接我们就要编写一个方法
@Override public int doStartTag() throws JspException { JspWriter out = pageContext.getOut(); try { out.print(toHTML()); } catch (IOException e) { e.printStackTrace(); } return SKIP_BODY; } private String toHTML() { StringBuilder sb = new StringBuilder(); // 这里拼接的是一个上一次发送的请求以及携带的参数,唯一改变的就是页码 sb.append(""); int page = pageBean.getPage();// 当前页 int max = pageBean.getMaxPage();// 最大页 int before = page > 4 ? 4 : page - 1;// 前面有几页,当前页显示前面显示几页,默认显示4页 // 一共显示10页 int after = 10 - 1 - before;// 后面的页数 // 后面还有几页,必须后面还有5页才显示 after = page + after > max ? max - page : after; // disabled boolean startFlag = page == 1; boolean endFlag = max == page; // 拼接分页条 sb.append(""); sb.append("
"); // 拼接分页的js代码 sb.append(""); return sb.toString(); }- 首页
"); sb.append("- <
"); // 代表了当前页的前4页 for (int i = before; i > 0; i--) { sb.append("- " + (page - i) + "
"); } sb.append("- " + pageBean.getPage() + "
"); // 代表了当前页的后5页 for (int i = 1; i <= after; i++) { sb.append("- " + (page + i) + "
"); } sb.append("- >
"); sb.append("- 尾页
"); sb.append( "- 到第页
"); sb.append("- 确定
"); sb.append("- 共" + pageBean.getTotal() + "条
"); sb.append("
改写servlet
我们把之前的servlet进行一个修改;完整版的servlet
package com.tgq.servlet;
import java.io.IOException;
import java.util.List;
import java.util.Map;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.tgq.dao.BookDao;
import com.tgq.entity.Book;
import com.tgq.util.PageBean;
/**
* 分页的Servlet
*/
@WebServlet("/book.action")
public class PageServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doPost(request, response);
}
@SuppressWarnings("unused")
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
//修改前
// String bname = request.getParameter("bname");
// // map包含了浏览器传递到后台的所有参数的键值对
// Map map = request.getParameterMap();
// // 浏览器请求地址
// String url = request.getRequestURI().toString();
//修改后
PageBean pageBean = new PageBean();
pageBean.setRequest(request);
// 查找我们的书籍
BookDao bookDao = new BookDao();
Book book = new Book();
//获取到书籍的名称
book.setBname(request.getParameter("bname"));
try {
//调用查询的方法
List list = bookDao.list2(book, pageBean);
//利用setAttribute保存
request.setAttribute("list", list);
} catch (Exception e) {
e.printStackTrace();
}
//利用setAttribute保存
request.setAttribute("pageBean", pageBean);
//跳转到页面
request.getRequestDispatcher("index.jsp").forward(request, response);
}
}
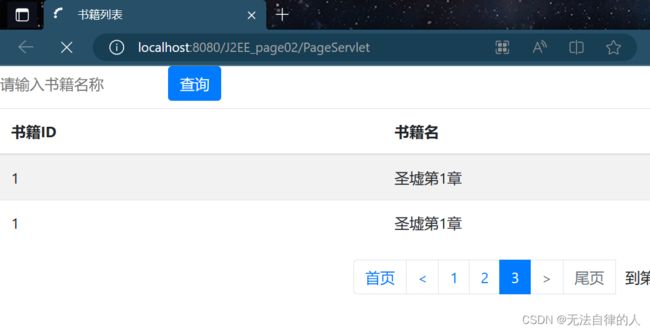
运行结果:
解析:
在助手类的这行代码,是我们需要理解的
int page = pageBean.getPage();// 当前页
int max = pageBean.getMaxPage();// 最大页
int before = page > 4 ? 4 : page - 1;// 前面有几页,当前页显示前面显示几页,默认显示4页
// 一共显示10页
int after = 10 - 1 - before;// 后面的页数
// 后面还有几页,必须后面还有5页才显示
after = page + after > max ? max - page : after;
编码问题
如果我们出搜索我们想要的就会出现一个乱码,这时候就需要用到过滤器来设置一个编码的问题

注意@WebFilter("*.action")这里的后缀必须要和我们的servlet@WebServlet("/book.action")后缀一样
package com.tgq.util;
import java.io.IOException;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.xml.ws.WebFault;
/**
* 中文乱码处理
*
*/
@WebFilter("*.action")
public class EncodingFiter implements Filter {
private String encoding = "UTF-8";// 默认字符集
public EncodingFiter() {
super();
}
public void destroy() {
}
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) request;
HttpServletResponse res = (HttpServletResponse) response;
// 中文处理必须放到 chain.doFilter(request, response)方法前面
res.setContentType("text/html;charset=" + this.encoding);
if (req.getMethod().equalsIgnoreCase("post")) {
req.setCharacterEncoding(this.encoding);
} else {
Map map = req.getParameterMap();// 保存所有参数名=参数值(数组)的Map集合
Set set = map.keySet();// 取出所有参数名
Iterator it = set.iterator();
while (it.hasNext()) {
String name = (String) it.next();
String[] values = (String[]) map.get(name);// 取出参数值[注:参数值为一个数组]
for (int i = 0; i < values.length; i++) {
values[i] = new String(values[i].getBytes("ISO-8859-1"),
this.encoding);
}
}
}
chain.doFilter(request, response);
}
public void init(FilterConfig filterConfig) throws ServletException {
String s = filterConfig.getInitParameter("encoding");// 读取web.xml文件中配置的字符集
if (null != s && !s.trim().equals("")) {
this.encoding = s.trim();
}
}
}
更改编码后我们去搜索我们想要的结果就不会出现乱码了

希望对你们有用!!!