Python基础 P8 永久存储
文章目录
- Python基础 P8 永久存储
-
- 文件
-
- 打开文件
- 文件的关闭close
- 文件的读取read/readline
- 文件的定位tell/seek
- 文件的写入write/writeline
- 文件系统
-
- 简介
- OS模块
-
- getcwd()
- chdir(path)
- listdir(path='.')
- mkdir/makedirs
- remove/rmdir/removedirs
- rename
- sytem
- walk
- OS.path模块
-
- basename/dirname
- join
- split/splitext
- getsize
- getatime/getctime/getmtime
- pickle模块
-
- dump
- load
Python基础 P8 永久存储

文件
大多数的程序都遵循着输入->处理->输出的模型,首先接收输入数据,然后按照要求进行处理,最后输出数据
但你迫切想要关注到系统的方方面面,需要自己的代码可以自动分析系统的日志,需要分析的结果可以保存为一个新的日志,甚至需要与外面的世界进行交流。
在编写代码的时候,操作系统为了更快地做出响应,把所有当前的数据都放在内存中,因为内存和CPU数据传输的速度要比在硬盘和CPU之间传输的速度快很多倍,但内存有一个天生的不足,就是一旦断电就没了;所以将一些必要且重要的文件存储在文件中就显得很重要了
打开文件
open
在Python中,使用open()这个内置函数来打开文件并返回文件对象
open(file, mode='r', buffering=-1, encoding=None, errors=None, closefd=True, opener=None)
file:传入的文件名,如果只有文件名,不带路径的话,那么python会在当前文件夹中去找到文件并打开
mode:指定文件打开的模式,具体如下
| 打开模式 | 执行操作 |
|---|---|
| r | 以只读方式打开文件(默认) |
| w | 以写入的方式打开文件,会覆盖已存在的文件 |
| x | 如果文件已经存在,使用此模式打开将引发异常 |
| a | 以写入模式打开文件,如果文件存在,则在末尾追加写入 |
| b | 以二进制模式打开文件 |
| t | 以文本模式打开(默认) |
| + | 可读写模式(可添加到其他模式中使用) |
| U | 通用换行符支持 |
举个栗子
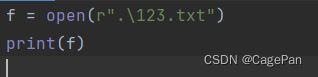
f = open(r".\123.txt")
print(f)
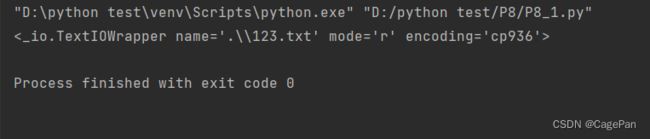
这样就说明以只读方式读取成功123.txt这个文件了
其他的参数都可以选填,使用open()成功打开一个文件之后,它会返回一个文件对象,获取这个文件对象之后,就可以对这个文件进行操作了
buffering:缓冲的意思,指在读取或写入文件时,数据被存储在内存中的一段缓冲区中,而不是直接访问磁盘;缓冲可以提高程序的性能,减少I/O操作的次数;在打开文件时,可以使用buffering参数来指定缓冲的大小或缓冲策略
该参数可选,如果不写,则默认值为-1,在默认情况下,python会根据文件的类型和操作系统的不同自动选择缓冲策略;如果写0表示不缓冲,每次进行I/O操作,数据会立即被写入或读取磁盘;写入1时表示使用行缓冲,每次读取或写入行结束符时,数据才会被写入或读取磁盘;大于1时的整数表示缓冲区的大小,当缓冲区被填满时数据会写入或读取磁盘,适用于需要大量读写文件的情况,可以提高程序的性能。
encoding:这个参数用于指定打开文件时所采用的编码格式,在读取和写入文件时,如果文件的编码格式与指定的编码格式不同,就会导致数据的乱码或其他异常
默认值为None,表示使用系统默认的编码格式;如果需要指定其他的编码格式,可以传递一个字符串作为参数,比如’utf-8’
errors:这个参数用于指定在文件读取或写入时遇到编码错误时的处理方式,当文件的编码与指定的编码格式不匹配的时候,可能会出现无法解码或编码的情况。
默认值为None,表示在遇到编码错误时抛出一个UnicodeError异常
ingore:忽略无法解码或编码的字符,直接跳过;适用于需要处理大量数据,但对数据完整性要求不高的情况
replace:用指定的字符(默认为?)代替无法解码或编码的字符;适用于需要保留完整数据,但对数据质量要求不高的情况
strict:在遇到无法解码或编码的字符时,抛出UniceodeError异常;适用于需要保留完整数据,并对数据质量有较高要求的情况
closefd:这个参数用于指定在关闭文件时是否同时关闭文件描述符;
当参数为True时,在文件被关闭时会同时关闭文件描述符;如果参数为False,文件被关闭时不会关闭文件描述符,这意味着在程序退出时,文件描述符会一直保持打开状态
opener:这个参数用于指定一个自定义的文件打开器,用于在打开文件时对文件进行预处理或后处理,如果未指定opener参数,则使用默认的文件打开器
文件对象的方法
在取得文件之后,我们可以对文件对象进行读取、修改等操作
| 文件对象的方法 | 执行操作 |
|---|---|
| close() | 关闭文件 |
| read(size=-1) | 从文件读取size个字符,当未给定负值得时候,读取剩余的所有字符,然后作为字符串返回 |
| readline() | 从文件读取一整行字符串 |
| write(str) | 将字符串str写入文件 |
| writelines(seq) | 向文件写入字符串序列seq,seq应该是一个返回字符串的可迭代对象 |
| seek(offset,from) | 在文件中移动文件指针,从from(0代表文件起始位置,1代表当前位置,2代表文件末尾)偏移offset个字符 |
| tell() | 返回当前文件中的位置 |
文件的关闭close
close方法用于关闭文件,关闭文件是非常重要的,但是python拥有垃圾收集机制,会在文件对象的引用计数降至零的时候自动关闭文件,所以在python编程,如果忘记关闭文件并不会造成内存泄漏那么危险的结果。但是养成不使用该文件的时候关闭文件这个习惯是必要的。
举个栗子
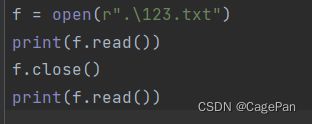
f = open(r".\123.txt")
print(f.read())
f.close()
print(f.read())
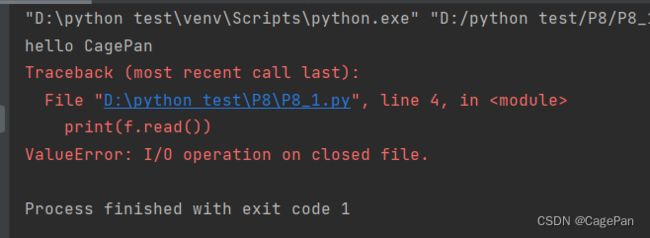
在关闭文件之后再去读文件报错,说明已经成功关闭了这个文件
文件的读取read/readline
文件读取的方法有很多,可以使用文件队形的read()和readline()方法,也可以直接使用list(f)来读取
read
read是以字节为单位读取,如果不设置参数,那么会全部进行读取,文件指针指向文件末尾
readline
readline()方法用于在文件中读取一整行,就是从文件指针的位置向后读取,直到遇到换行符(\n)结束,文件指针指向结束位置
list
文件还可以使用list直接来获取文件内容并转换为列表
举个栗子

这里的seek是定位函数,这里是将位置重新定位到开头
f = open(r".\123.txt")
print(f.read(2), end='\n\n')
print(f.readline(), end='\n\n')
print(f.read(), end='\n\n')
f.seek(0, 0)
print(list(f))

文件的定位tell/seek
tell
tell能够获取当前的位置值
seek
而seek则是将位置定位进行修改到指定位置
举个栗子
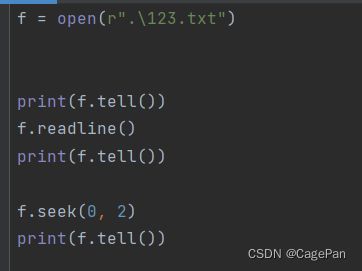
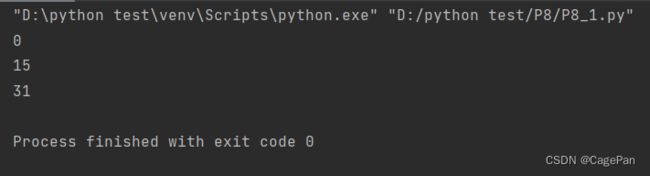
f = open(r".\123.txt")
print(f.tell())
f.readline()
print(f.tell())
f.seek(0, 2)
print(f.tell())
文件的写入write/writeline
如果需要写入文件,需要在打开文件的模式为‘w’或‘a’,否则会出错
举个栗子
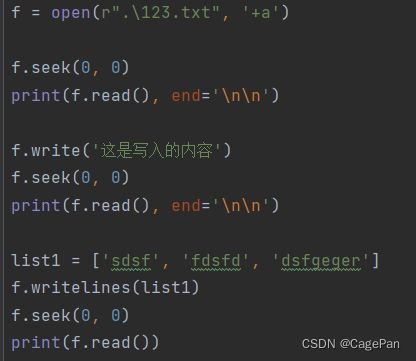
f = open(r".\123.txt", '+a')
f.seek(0, 0)
print(f.read(), end='\n\n')
f.write('这是写入的内容')
f.seek(0, 0)
print(f.read(), end='\n\n')
list1 = ['sdsf', 'fdsfd', 'dsfgeger']
f.writelines(list1)
f.seek(0, 0)
print(f.read())


文件系统
简介
接下来会介绍与python文件相关的一些十分有用的模块,其实我们写的每一个源文件.py都是一个模块。python自带有非常多实用的模块,在日常编程中如果能够熟练地掌握他们,必将事半功倍。
OS模块
首先要介绍的是高大上的OS模块,OS模块就是Operating System:及操作系统。对于文件系统的访问,python一般是通过OS模块来实现的。
我们知道的常用的操作系统有很多,如windows、MacOS、Linux等,但是这些操作系统底层对文件系统访问的工作原理是不一样的,这样调用文件系统就会很麻烦;但是python是跨平台的语言,也就是说,同样的源代码在不同的操作系统中不需要修改就可以同样实现
有了OS模块,不需要关心什么操作系统下使用什么模块,OS模块会帮你选择正确的模块并调用。
OS常用函数
| 函数名 | 使用方法 |
|---|---|
| getcwd() | 返回当前工作目录 |
| chdir(path) | 改变工作目录 |
| listdir(path=‘’) | 列举指定目录中的文件名(‘.’表示当前目录’…'表示上一级目录) |
| mkdir(path) | 创建单层目录,如果该目录已存在抛出异常 |
| makedirs(path) | 递归创建多层目录,如该目录已存在抛出异常 |
| remove(path) | 删除文件 |
| rmdir(path) | 删除单层目录,如该目录非空则抛出异常 |
| remove(path) | 递归删除目录,从子目录逐层尝试删除,遇到目录非空则抛出异常 |
| rename(old,new) | 将文件old重命名为new |
| system(command) | 运行系统的shell命令 |
支持路径操作中常用到的一些定义,支持所有平台
| 函数名 | 使用方法 |
|---|---|
| os.curdir | 指代当前目录’.’ |
| os.pardir | 指代上一级目录’…’ |
| os.sep | 输出操作系统特定的路径分隔符’\’ |
| os.linesep | 当前平台使用的行终止符’\r\n’ |
| os.name | 指代当前使用的操作系统 |
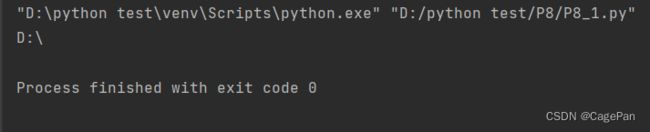
getcwd()
在有些情况下需要获得应用程序当前的工作目录,那么可以使用gwtcwd() 函数获得
举个栗子
import os
print(os.getcwd())

chdir(path)
用chdir() 函数可以改变当前工作目录
举个栗子
import os
os.chdir("D:\\")
print(os.getcwd())
listdir(path=‘.’)
有时候可能需要知道当前目录下有哪些文件和子目录,那么listdir() 函数可以帮助列举出来
import os
print(os.listdir())

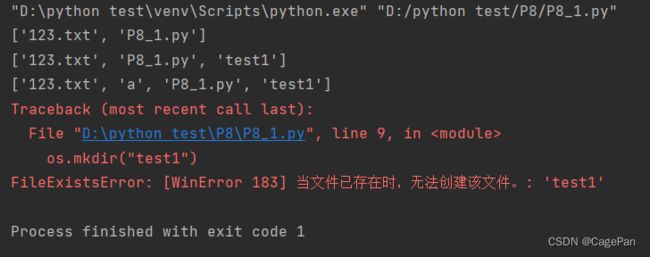
mkdir/makedirs
mkdir()函数用于创建文件夹,如果该文件夹存在,则抛出FileExistsError异常
import os
print(os.listdir())
os.mkdir("test1")
print(os.listdir())
os.makedirs(r".\a\b\c")
print(os.listdir())
os.mkdir("test1")
print(os.listdir())
os.makedirs(r".\a\b\c")
print(os.listdir())

remove/rmdir/removedirs
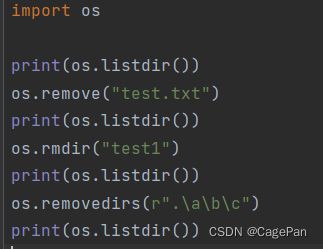
remove函数用于删除指定的文件,注意是删除文件,不是删除目录。
rmdir函数用来删除指定目录,注意是删除目录,不是删除多层目录
removedirs函数用于删除多层目录
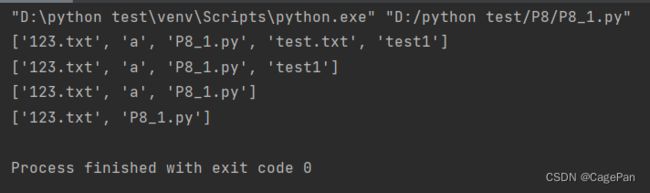
import os
print(os.listdir())
os.remove("test.txt")
print(os.listdir())
os.rmdir("test1")
print(os.listdir())
os.removedirs(r".\a\b\c")
print(os.listdir())
rename
rename函数用于重命名文件或文件夹
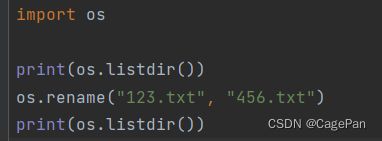
import os
print(os.listdir())
os.rename("123.txt", "456.txt")
print(os.listdir())
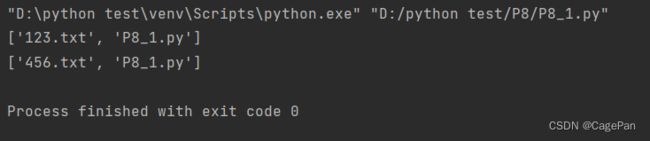
sytem
几乎每个操作系统都会提供一些小工具,system函数用于使用这些小工具
比如想要弹出计算机,可以填入calc
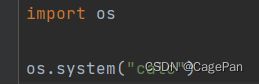
import os
os.system("calc")
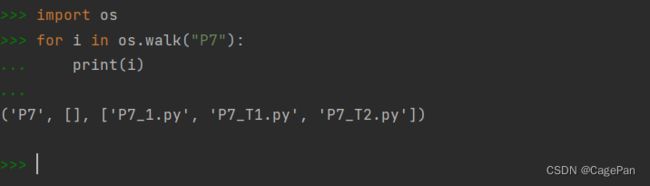
walk
walk函数,这个函数在有些时候确实非常有用,可以省去很多麻烦,该函数的作用是遍历top参数指定路径下的所有子目录,并将结果返回一个三元组(路径,包含目录,包含文件)
OS.path模块
常用os.path模块
| 函数名 | 使用方法 |
|---|---|
| basename(path) | 去掉目录路径,单独返回文件名 |
| dirname(path) | 去掉文件名,单独返回目录路径 |
| join(path1[,path2[,…]]) | 将path1、path2各部分组合成一个路径名 |
| split(path) | 分割文件名与路径,返回(f_path,f_name)元组。如果完全使用目录,它也会将最后一个目录作为文件名分离,且不会判断文件或者目录是否存在 |
| splitext(path) | 分离文件名与扩展名,返回(f_name,f_extension)元组 |
| getsize(file) | 返回指定文件的尺寸,单位是字节 |
| getatime(file) | 返回指定文件最近的访问时间(浮点型秒速,可用time模块的gmtime()或localtime()函数换算) |
| getctime(file) | 返回指定文件的创建时间(浮点型秒速,可用time模块的gmtime()或localtime()函数换算) |
| getmtine(file) | 返回指定文件的最新修改时间(浮点型秒速,可用time模块的gmtime()或localtime()函数换算) |
| exists(path) | 判断指定路径(目录或文件)是否存在 |
| isabs(path) | 判断指定路径是否为绝对路径 |
| isdir(path) | 判断指定路径是否存在且是一个目录 |
| isfile(path) | 判断指定路径是否存在且是一个文件 |
| islink(path) | 判断指定路径是否存在且是一个符号链接 |
| ismount(path) | 判断指定路径是否存在且是一个挂载点 |
| samefile(path1,path2) | 判断path1和path2两个路径是否指向同一个文件 |
basename/dirname
basename获取文件的文件名,dirname获取文件的路径名

import os
print(os.path.dirname(r"..\P7\P7_T1.py"))
print(os.path.basename(r"..\P7\P7_T1.py"))

join
join函数与BIF的那个join函数不同,用于将路径名和文件名组合成一个完整的路径

import os
print(os.path.join(r"D:\\python test\P8", "P8_1.py"))

split/splitext
split函数分割路径和文件名
splitext函数则用于分割文件名和扩展名
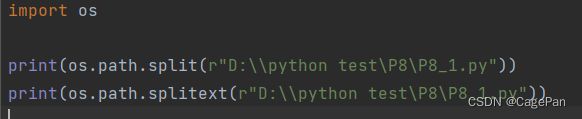
import os
print(os.path.split(r"D:\\python test\P8\P8_1.py"))
print(os.path.splitext(r"D:\\python test\P8\P8_1.py"))

getsize
getsize函数用于获取文件的尺寸,返回值以字节为单位
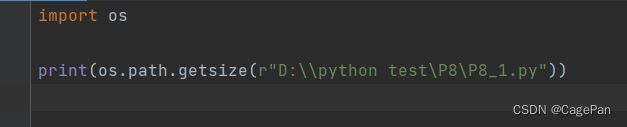
import os
print(os.path.getsize(r"D:\\python test\P8\P8_1.py"))
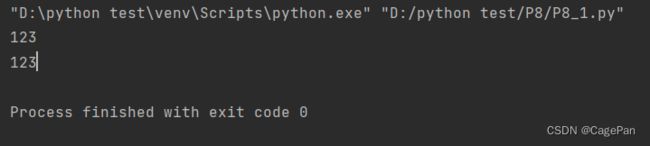
getatime/getctime/getmtime
这三个函数分别用于获取文件的最近访问时间、创建时间和修改时间,不过返回值是浮点型秒速,可用time模块gmtime进行转换
getatime:最近访问时间
getctime:创建时间
getmtime:修改时间

import os
import time
t1 = time.localtime(os.path.getatime("456.txt"))
t2 = time.localtime(os.path.getctime("456.txt"))
t3 = time.localtime(os.path.getmtime("456.txt"))
print(time.strftime("%Y-%m-%d %H:%M:%S", t1))
print(time.strftime("%Y-%m-%d %H:%M:%S", t2))
print(time.strftime("%Y-%m-%d %H:%M:%S", t3))

pickle模块
此前一直在讲保存文件,然而当要保存的数据像列表、字典甚至是类的实例这些更复杂的数据类型时,普通的文件操作就会变得不知所措。也许你会把这些都转换为字符串,再写入到一个文本文件中保存起来,但是很快就会发现要把这个过程反过来,从文本文件恢复数据对象,就变得异常麻烦了。不过python提供了pickle模块,使用这个模块就可以非常容易地将列表、字典这类复杂数据类型存储为文件。
dump
使用dump可以将数据保存进文件
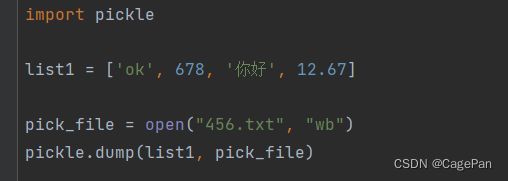
import pickle
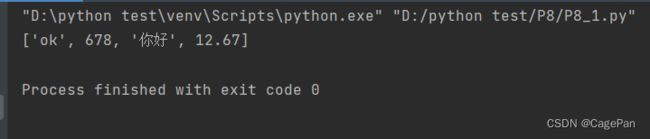
list1 = ['ok', 678, '你好', 12.67]
pick_file = open("456.pkl", "wb")
pickle.dump(list1, pick_file)
load
使用load可以从文件中提取数据
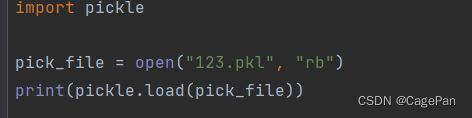
import pickle
pick_file = open("123.pkl", "rb")
print(pickle.load(pick_file))