python对Excel数据运用的几种库
在python中,我们搭建接口自动化框架里面离不开数据的遍历和调用,这时候我们要用到python强大的库,来获取和调用我们存放在Excel中的数据
首先第一种库:openpyxl 的调用,注意:openpyxl 库只能读取.xlsx文件格式的数据
方法一:
from openpyxl import load_workbook
class Http_Excel_Tow:
def __init__(self, file_name, sheet_name):
self.file_name = file_name
self.sheet_name = sheet_name
self.sheet_obj = load_workbook(self.file_name)[self.sheet_name] # 获取文件对象
self.max_row = self.sheet_obj.max_row # 获取最大行
def do_real(self, i, j):
return self.sheet_obj.cell(i, j).value # 获取文件(行,列)的参数化
if __name__ == '__main__':
res = Http_Excel_Tow('test_api.xlsx', 'python').do_real(1, 4) #打开test_api.xlsx文件,获取其中第一行第四列的数据
print(res)
#方法一的调用 在另外执行我们测试用例的py文件中
from class_demo_login_topup.http_excel_2 import Http_Excel_Tow
res = Http_Excel_Tow('test_api.xlsx', 'python') # 引用实例
suite = unittest.TestSuite()
for i in range(1, res.max_row+1):# 遍历我们最大行+1 遍历 1 2 3 4行的数据
suite.addTest(Login_Http('test_api', res.do_real(i, 1), eval(res.do_real(i, 2)), res.do_real(i, 3),str(res.do_real(i, 4))))
# 执行我们自己写的测试Login_Http类中test_api方法,数据调用do_real方法,实现四行四列数据的遍历,其中:eval()是在EXCEL读取的是字符串,所以要还原之前的字典类型,str()这列在EXCEL读取中是数字,要改成字符串,前面加str()转化一下
方法二:
from openpyxl import load_workbook
class HttpExcel:
def __init__(self, excel_name, sheet_name):
self.excel_name = excel_name
self.sheet_name = sheet_name
def real_excel(self): # real_excel(self, mode='all'):
mode = FileConfig().config('do_config', 'MODE', 'mode') # 遍历 1 3 登录和充值两条用例
wb = load_workbook(self.excel_name)
sheet = wb[self.sheet_name]
test_data = []
for i in range(1, sheet.max_row + 1): # 遍历 1 2 3 4 sheet.max_row EXCEL中的最大行
sub_test = {}
sub_test['mode'] = sheet.cell(i, 1).value
sub_test['url'] = sheet.cell(i, 2).value
sub_test['data'] = sheet.cell(i, 3).value
sub_test['method'] = sheet.cell(i, 4).value
sub_test['expected'] = sheet.cell(i, 5).value
test_data.append(sub_test)
if mode == 'all':
final_data = test_data
else:
final_data = []
for item in test_data:
if item['mode'] in eval(mode):
final_data.append(item)
return final_data
def write_back(self, i, value): # 把测试结果写入到EXCEL文件中 I 行数 V 结果值保存
wb = openpyxl.load_workbook(self.file_name)
sheet = wb[self.sheet_name]
sheet.cell(i, 7).value = value
wb.save(self.file_name)
if __name__ == '__main__':
res = HttpExcel('test_api.xlsx', 'python').real_excel()
print(res)
#方法二的调用 在另外执行我们测试用例的py文件中
test_data = HttpExcel('test_api.xlsx', 'python').real_excel()
for item in test_data:
suite.addTest(Login_Http('test_api', item['url'], eval(item['data']), item['method'], str(item['expected'])))
其实我们最后实现的 test_data 数据就是这样的:
[{'url':'xx','data':{'xx'},'method':'xx','expected':'xx'},
{'url':'xx','data':{'xx'},'method':'xx','expected':'xx'},
{'url':'xx','data':{'xx'},'method':'xx','expected':'xx'},
{'url':'xx','data':{'xx'},'method':'xx','expected':'xx'}]
openpyxl 库提取的位置(1,1),对应的是蓝色框的一列:openpyxl没有定位(0,0)
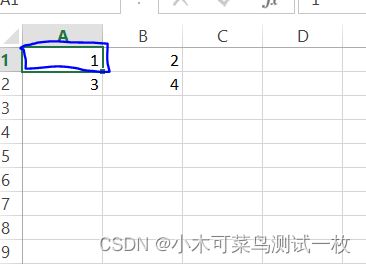
openpyxl 库提取的位置(1,2),对应的是蓝色框的一列:
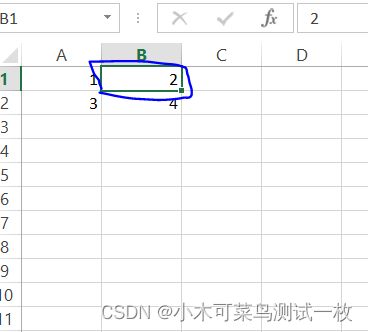
openpyxl 库提取的位置(2,1),对应的是蓝色框的一列:

openpyxl 库提取的位置(2,2),对应的是蓝色框的一列:
第二种库:xlrd 这种库 就只支持.xls文件,写成类 参考第一种情况
import xlrd
table = xlrd.open_workbook('test.xls')
Sheet = table.sheet_by_name('python')
print(Sheet.cell(1, 1).value)
print(Sheet.row_values(1)) # 获取第一行的全部数据
一、
下面是示例:excel内容在文章中register内容一致: 但是配置文件读取的mode很有区别:
ReadExcel类的配置文件config的内容是:
[MODE]
test_1=[1,3]
import xlrd
from config.class_config import ReadFile
class ReadExcel():
def __init__(self, excel_name, sheet_name):
self.excel_name = excel_name
self.sheet_name = sheet_name
def read_excel_value(self, i, j):
table = xlrd.open_workbook(self.excel_name) # 获取文件对象
# nrows = table.sheet_by_name(self.sheet_name).nrows # 获取最大行数
sheet = table.sheet_by_name(self.sheet_name) # 定位表单
return sheet.cell(i, j).value # 获取文件(行,列)的参数化
def read_excel(self):
mode = ReadFile().read('../data/data.config', 'MODE', 'test_1') # 遍历充值 1 3 两条用例
table = xlrd.open_workbook(self.excel_name)
sheet = table.sheet_by_name(self.sheet_name)
test_data = []
for i in range(1, sheet.nrows): # 最大行数:nrows 最大列数:ncols
sub_test = {}
sub_test['mode'] = sheet.cell(i, 0).value
sub_test['url'] = sheet.cell(i, 1).value
sub_test['data'] = sheet.cell(i, 2).value
sub_test['method'] = sheet.cell(i, 3).value
sub_test['expected'] = sheet.cell(i, 4).value
sub_test['meg'] = sheet.cell(i, 5).value
sub_test['result'] = sheet.cell(i, 6).value
test_data.append(sub_test)
if mode == 'all':
final_data = test_data
else:
final_data = []
for item in test_data:
if item['mode'] in mode:
final_data.append(item)
return final_data
def write_back(self, i, value): # 把测试结果写入到 EXCEL 文件中 I 行数 V 结果值保存
table = xlrd.open_workbook(self.excel_name)
sheet = table.sheet_by_name(self.sheet_name)
sheet.cell(i, 7).value = value
table.save(self.sheet_name)
if __name__ == '__main__':
# 用法一
url = r'../data/test_data.xlsx'
# res = ReadExcel(url, 'register').read_excel_value(1, 1)
final_data = ReadExcel(url, 'register').read_excel()
print(final_data)
二、可配置化excel
ConfigExcel类的配置文件config的内容是:
[MODE]
test={‘login’:[],‘register’:[1,3],‘recharge’:[]}
import xlrd
from config.class_config import ReadFile
class ConfigExcel(object):
@staticmethod
def config_excel(file_name):
mode = eval(ReadFile().read('../data/data.config', 'MODE', 'test')) # 获取config文件里面的数据 eval 还原的字典类型
table = xlrd.open_workbook(file_name)
test_data = []
for key in mode: # 遍历存在配置文件的字典 register 注册
sheet = table.sheet_by_name(key)
if mode[key] == 'all':
for i in range(1, sheet.nrows):
sub_test = {}
sub_test['mode'] = sheet.cell(i, 0).value
sub_test['url'] = sheet.cell(i, 1).value
sub_test['data'] = sheet.cell(i, 2).value
sub_test['method'] = sheet.cell(i, 3).value
sub_test['expected'] = sheet.cell(i, 4).value
sub_test['meg'] = sheet.cell(i, 5).value
sub_test['result'] = sheet.cell(i, 6).value
sub_test['sheet_name'] = key # 方便执行不同的文件
test_data.append(sub_test)
else:
for case_id in mode[key]:
sub_test = {}
sub_test['mode'] = sheet.cell(case_id+1, 0).value
sub_test['url'] = sheet.cell(case_id+1, 1).value
sub_test['data'] = sheet.cell(case_id+1, 2).value
sub_test['method'] = sheet.cell(case_id+1, 3).value
sub_test['expected'] = sheet.cell(case_id+1, 4).value
sub_test['meg'] = sheet.cell(case_id+1, 5).value
sub_test['result'] = sheet.cell(case_id+1, 6).value
sub_test['sheet_name'] = key # 方便执行不同的文件
test_data.append(sub_test)
return test_data
if __name__ == '__main__':
url = r'../data/test_data.xlsx'
data = ConfigExcel.config_excel(url)
print(data)
xlrd库提取的位置(0,0),对应的是蓝色框的一列:
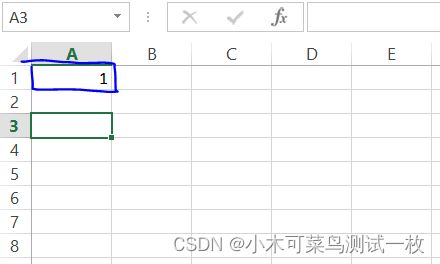
xlrd库提取的位置(0,1),对应的是蓝色框的一列:
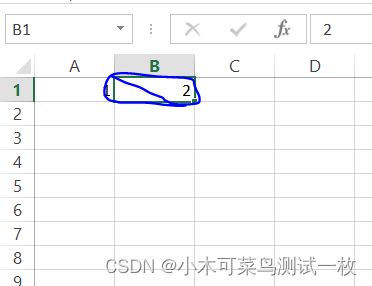
xlrd库提取的位置(1,0),对应的是蓝色框的一列:
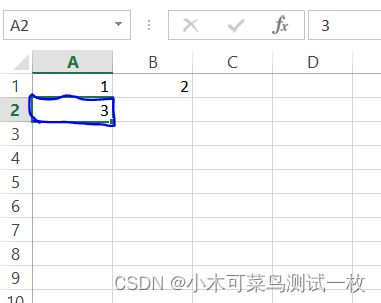
xlrd库提取的位置(1,1),对应的是蓝色框的一列:
遍历 EXCEL 脚本 方式一:
a.编写EXCEL处理的方法
import xlrd
from common.config_reader import get_value
class DoExcel():
def __init__(self):
self.case_file_path = get_value("file","case_file_path")
self.workbook = xlrd.open_workbook(self.case_file_path)
self.sheets = self.workbook.sheet_names()
def getname(self,name):
sheetname=self.workbook.sheet_by_name(name)
return sheetname
def get_value(self, sheet, row, col):
table = self.workbook.sheet_by_name(sheet)
cell_value = table.cell_value(row, col)
return cell_value
def sheetnames(self):
sheetname = []
for sheet in self.sheets:
if sheet == "ElementMap":
pass
else:
sheetname.append(sheet)
return sheetname
def enablesheet_list(self):
name_status = {}
workbook = openpyxl.load_workbook(self.case_file_path)
sheet = workbook["EnableSheet"]
sheetnames = self.sheetnames()
nrow = 0
for sheetname in sheetnames:
nrow += 1
if sheetname == "EnableSheet":
pass
else:
sheet.cell(nrow + 1, 1).value = sheetname
name_status[sheetname] = sheet.cell(nrow + 1,2).value
return name_status
def get_all_value(self):
values = []
status_lists = self.enablesheet_list()
for st in self.sheets:
if st in ("ElementMap","EnableSheet"):
pass
else:
if status_lists[st] == 1:
rows_obj = self.workbook.sheet_by_name(st).get_rows()
i = 0
for row_tuple in rows_obj:
self.value_list = []
n = 0
for val in row_tuple:
if val.value == None:
val.value = ''
n = n + 1
self.value_list.append(val.value)
if n >= 9:
pass
else:
if i == 0:
pass
else:
values.append(self.value_list)
i += 1
else:
pass
return values
def get_excel_title(self):
rows_obj = self.workbook.sheet_by_name(self.sheets[0]).get_rows()
rows_objs = tuple(rows_obj)[0]
title = []
for r in rows_objs:
title.append(r.value)
return title
def get_listdict_all_value(self):
sheet_title = self.get_excel_title()
all_values = self.get_all_value()
value_list = []
for value in all_values:
value_list.append(dict(zip(sheet_title, value)))
return value_list
def get_all_value_map(self):
rows_obj = self.getname("ElementMap").get_rows()
values = []
for row_tuple in rows_obj:
value_list = []
n = 0
for val in row_tuple:
if val.value == None:
value = ""
n = n + 1
value_list.append(val.value)
if n >= 5:
pass
else:
values.append(value_list)
del (values[0])
return values
def get_excel_title_map(self):
rows_obj = self.getname("ElementMap").get_rows()
rows_objs = tuple(rows_obj)[0]
title = []
for r in rows_objs:
title.append(r.value)
return title
def get_listdict_all_value_map(self):
sheet_title = self.get_excel_title_map()
all_values = self.get_all_value_map()
value_list = []
for value in all_values:
value_list.append(dict(zip(sheet_title, value)))
return value_list
b.对于上面的方法进行集成处理
from interfaces.icase_reader import *
from common.doexcel import DoExcel
from models.case import *
class ExcelCaseReader(ICaseReader):
def __init__(self):
self.case_file_path = ''
def read_case(self):
"read case file and return case"
case = Case()
excel = DoExcel()
all_value_case = excel.get_listdict_all_value()
for value in all_value_case:
case_step = CaseStep()
case_step.Step = value['Step']
case_step.Behavior = value['Behavior']
case_step.OperationPage = value['OperationPage']
case_step.Description = value['Description']
case_step.ObjectName = value['ObjectName']
case_step.PositioningExpression = value['PositioningExpression']
case_step.InputValue = value['InputValue']
case_step.OutputValue = value['OutputValue']
case_step.ExpectedResult = value['ExpectedResult']
case_step.WaitTime = value['WaitTime']
case_step.Enabled = value['Enabled']
case_step.IgnoreErr = value['IgnoreErr']
case_step.LoopCnt = value['LoopCnt']
case.caseSteps.append(case_step)
all_map = excel.get_listdict_all_value_map()
for value in all_map:
element_map = ElementMap()
element_map.Page = value["Page"]
element_map.Type = value["Type"]
element_map.Name = value["Name"]
element_map.TmpText = value["TmpText"]
element_map.SourceName = value["SourceName"]
case.elementMaps.append(element_map)
return case
from models.case import * 这对应就是初始化方法
对应的就是我们EXCEL对应的标题栏位。
class CaseStep:
def __init__(self):
self.Step = 0
self.Behavior = ''
self.OperationPage = ''
self.Description = ''
self.ObjectName = ''
self.PositioningExpression = ''
self.InputValue = ''
self.OutputValue = ''
self.ExpectedResult = ''
self.WaitTime = 1
self.Enabled = 1
self.IgnoreErr = 1
self.LoopCnt = 1
class ElementMap:
def __init__(self):
self.Page = ''
self.Type = ''
self.Name = ''
self.TmpText = ''
self.SourceName = ''
class Case:
def __init__(self):
self.caseSteps = list()
self.elementMaps = list()
interfaces.icase_reader
就是定位的一个
from interfaces.icase_reader import *
class ICaseReader:
supportFile = ''
case_file_path = ''
def read_case(self, file_path: str):
"""
Read case file
:return caseSteps list:
"""
c.对于b进一步单独处理提取EXCEL后缀.xls&.xlsx进行判断
from common.config_reader import *
from web_ui_auto_lib.case_readers.ecel_case_reader import *
import os
def get_case_reader():
file_path = get_value("file", "Case_file_path") # case_file_path=.\data\modlue_v0.1.xlsx
(filepath, tempfilename) = os.path.split(file_path)
(filename, extension) = os.path.splitext(tempfilename)
if extension in [".xls",".xlsx"]:
case_reader = ExcelCaseReader()
case_reader.case_file_path = file_path
return case_reader
遍历 EXCEL 脚本 方式二:
实现的功能就是不用指定特定的路径就能够读取多个EXCEL文件的处理。
lambda 函数的运用参考这里
a.处理excel的方法
import xlrd
from common.config_reader import ConfigReader
import openpyxl
from common.log import Log
import os
class DoExcel():
def __init__(self):
self.log =Log()
def get_excellist(self):# 获取EXCEL中所在的路径下所有的xls或者包含xls,以xls开头的文件
file_list=[]
root_dir=os.getcwd()
dir_or_files = os.listdir(root_dir)
for dir_file in dir_or_files:
dir_file_path = os.path.join(root_dir,dir_file)
if os.path.isdir(dir_file_path):
pass
else:
filepath,filename = os.path.split(dir_file_path)
file_list.append(filename)
# lambda函数用于指定过滤列表元素的条件。
# 例如filter(lambda x: x % 3 == 0, [1, 2, 3])指定将列表[1,2,3]中能够被3整除的元素过滤出来,其结果是[3]。
case_list = list(filter(lambda case:".xls" in case, file_list))
if not case_list:
raise Exception(self.log.logMsg(3,("case not exist")))
return case_list
def openworkbook(self,xlsx): # 获取 EXCEL 的对象
try:
workbook = xlrd.open_workbook(xlsx)
self.sheets=workbook.sheet_names()
return workbook
except Exception as e:
self.log.logMsg(3,f'case not exist')
return None
def getname(self,name): # 获取EXCEL 的 sheet 名字
sheetname=self.workbook.sheet_by_name(name)
return sheetname
def getsheetnames(self): # 获取 EXCEL 除了ElementMap之外的 sheet 名字
sheetname=[]
for sheet in self.sheets:
if sheet == "ElementMap":
pass
else:
sheetname.append(sheet)
return sheetname
def get_value(self, sheet, row, col): # 获取 EXCEL 空格中单个的值
table = self.workbook.sheet_by_name(sheet)
cell_value = table.cell_value(row, col)
return cell_value
def enablesheet_list(self,xlsx):
# 读取除了EnableSheet之外的的sheet名写入到EnableSheet栏位,其实保存不了,导致有些问题。其实这个方法没有用到。
name_status = {}
workbook = openpyxl.load_workbook(xlsx)
sheet = workbook["EnableSheet"]
sheetnames = self.getsheetnames()
nrow = 0
for sheetname in sheetnames:
nrow += 1
if sheetname == "EnableSheet":
pass
else:
sheet.cell(nrow + 1, 1).value = sheetname
name_status[sheetname] = sheet.cell(nrow + 1, 2).value
# workbook.save(xlsx)
return name_status
def get_excel_title(self,xlsx):
rows_obj = self.openworkbook(xlsx).sheet_by_name(self.sheet_name_title).get_rows()
# self.sheet_name_title --> 取工作区域的 title ,在运行get_listdict_all_value方法时,
# 先运行get_all_value方法中定义好的self.sheet_name_title=st的值
rows_objs = tuple(rows_obj)[0] # get_rows() 取首列的值
title = []
for r in rows_objs:
title.append(r.value)
return title
def get_all_value(self,xlsx): # 获取除了title以外所有的EXCEL里面的数据
self.workbook = xlrd.open_workbook(xlsx)
self.sheets = self.workbook.sheet_names()
values = []
status_lists = self.enablesheet_list(xlsx)
for st in self.sheets:
if st in("ElementMap","EnableSheet"):
pass
else:
if status_lists[st] == 1: # sheet控制工作区域
self.sheet_name_title = st # 取工作sheet里面的 title
rows_obj = self.workbook.sheet_by_name(st).get_rows() # get_rows()——读取表单中的所有数据
i = 0
for row_tuple in rows_obj:
self.value_list = []
n = 0
for val in row_tuple:
if val.value == None:
val.value = ""
n = n + 1
self.value_list.append(val.value)
if n >= 10:
pass
else:
if i == 0: # 首列的值除外 不存储到values列表中
pass
else:
values.append(self.value_list)
i += 1
else:
pass
return values
def get_listdict_all_value(self,xlsx): # 把上面的title和对应的数据,全部整合在一起
self.xlsx=xlsx
all_values = self.get_all_value(xlsx)
sheet_title = self.get_excel_title(xlsx)
value_list = []
for value in all_values:
value_list.append(dict(zip(sheet_title, value)))#zip方法把title和value整合在一起
return value_list
def get_all_value_map(self): #把ElementMap表单里面的value读取出来
rows_obj = self.getname("ElementMap").get_rows()
values = []
for row_tuple in rows_obj:
value_list = []
n = 0
for val in row_tuple:
if val.value == None:
val.value = "" # 解决excel问题
n = n + 1
value_list.append(val.value)
if n >= 5:
pass
else:
values.append(value_list)
del (values[0])
return values
def get_excel_title_map(self): #把ElementMap表单里面的title提取出来
rows_obj = self.getname("ElementMap").get_rows()
rows_objs = tuple(rows_obj)[0]
title = []
for r in rows_objs:
title.append(r.value)
return title
def get_listdict_all_value_map(self):# 把ElementMap的title和对应的数据,全部整合在一起
sheet_title = self.get_excel_title_map()
all_values = self.get_all_value_map()
value_list = []
for value in all_values:
value_list.append(dict(zip(sheet_title, value)))
return value_list
EXCEL处理的这个页签名:EnableSheet 是配置运行的sheet,ElementMap是配置元素定位表达式,其他的都是工作区域。
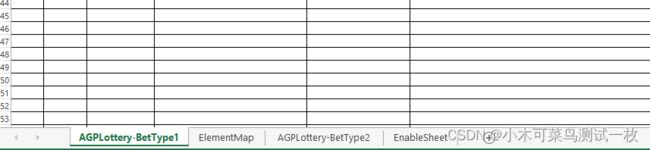
EnableSheet 栏位 enablesheet_list 方法会把除了EnableSheet的sheet名写入到EnableSheet栏位写到这里,好去处理应该工作的sheet工作簿。

b.遍历EXCEL文件,依次执行文件的case.
from interfaces.icase_reader import *
from common.doexcel import DoExcel
from models.case import *
class ExcelCaseReader(ICaseReader):
def __init__(self):
self.excel=DoExcel()
def read_case(self):
"read case file and return case"
case = Case()
xlsx_list=self.excel.get_excellist()
for xlsx in xlsx_list:
all_value_case = self.excel.get_listdict_all_value(xlsx)
for value in all_value_case:
case_step = CaseStep()
case_step.Step = value['Step']
case_step.Behavior = value['Behavior']
case_step.OperationPage = value['OperationPage']
case_step.Description = value['Description']
case_step.ObjectName = value['ObjectName']
case_step.PositioningExpression = value['PositioningExpression']
case_step.InputValue = value['InputValue']
case_step.OutputValue = value['OutputValue']
case_step.ExpectedResult = value['ExpectedResult']
case_step.WaitTime = value['WaitTime']
case_step.Enabled = value['Enabled']
case_step.IgnoreErr = value['IgnoreErr']
case_step.LoopCnt = value['LoopCnt']
case.caseSteps.append(case_step)
all_map = self.excel.get_listdict_all_value_map()
for value in all_map:
element_map = ElementMap()
element_map.Page = value["Page"]
element_map.Type = value["Type"]
element_map.Name = value["Name"]
element_map.TmpText = value["TmpText"]
element_map.SourceName = value["SourceName"]
case.elementMaps.append(element_map)
return case
解释:all_value_case 返回的是什么,就是下面的数据:
[['Step', 'Behavior', 'OperationPage', 'Description', 'ObjectName', 'PositioningExpression', 'InputValue', 'OutputValue', 'ExpectedResult', 'WaitTime', 'Enabled', 'IgnoreErr', 'LoopCnt'],
[1.0, 'click', '点击开始', 'la', 'sd', 'lasd', 123456.0, '', '', 2.0, 0.0, 0.0, 1.0],
[2.0, 'click', '点击开始', 'la', 'sd', 'lasd', 123457.0, '', '', 2.0, 1.0, 1.0, 1.0],
[3.0, 'click', '点击开始', 'la', 'sd', 'lasd', 123458.0, '', '', 2.0, 1.0, 1.0, 1.0],
[4.0, 'click', '点击开始', 'la', 'sd', 'lasd', 123459.0, '', '', 2.0, 1.0, 1.0, 1.0],
[5.0, 'click', '点击开始', 'la', 'sd', 'lasd', 123460.0, '', '', 2.0, 1.0, 1.0, 1.0],
[6.0, 'click', '点击开始', 'la', 'sd', 'lasd', 123461.0, '', '', 2.0, 0.0, 0.0, 1.0],
[7.0, 'click', '点击开始', 'la', 'sd', 'lasd', 123462.0, '', '', 2.0, 0.0, 0.0, 1.0],
[8.0, 'click', '点击开始', 'la', 'sd', 'lasd', 123463.0, '', '', 2.0, 0.0, 0.0, 1.0],
[9.0, 'click', '点击开始', 'la', 'sd', 'lasd', 123464.0, '', '', 2.0, 0.0, 0.0, 1.0]]