STM32 CAN过滤器详解
1. 前言
bxCAN是STM32系列最稳定的IP核之一,无论有哪个新型号出来,这个IP核基本未变,可见这个IP核的设计是相当成熟的。本文所讲述的内容属于这个IP核的一部分,掌握了本文所讲内容,就可以很方便地适用于所有STM32系列中包含bxCAN外设的型号。有关bxCAN的过滤器部分的内容在参考手册中往往看得“不甚明白“,本文就过滤器的4种工作模式进行详细讲解并使用具体的代码进行演示,这些代码都进行过实测验证通过的,希望能给读者对于bxCAN过滤器有一个清晰的理解。
2. 准备工作
2.1. 为什么要过滤器?
在这里,我们可以将CAN总线看成一个广播消息通道,上面传输着各种类型的消息,好比报纸,有体育新闻,财经新闻,政治新闻,还有军事新闻,每个人都有自己的喜好,不一定对所有新闻都感兴趣,因此,在看报纸的时候,一般人都是只看自己感兴趣的那类新闻,而过滤掉其他不感兴趣的内容。那么我们一般是怎么过滤掉那些不感兴趣的内容的呢?下面有两种方法来实现这个目的:
第一种方法:
每次看报纸时,你都看下每篇文章的标题,如果感兴趣则继续看下去,如果不感兴趣,则忽略掉。
第二种方法:
你告诉邮递员,你只对财经新闻感兴趣,请只将财经类报纸送过来,其他的就不要送过来了,就这样,你看到的内容必定是你感兴趣的财经类新闻。
上面那种方法好呢?很明显,第二种方法是最好的,因为你不用自己每次判断哪些新闻内容是你感兴趣的,可以免受“垃圾”新闻干扰,从而可以节省时间忙其他事。bxCAN的过滤器就是采用上述第二种方法,你只需要设置好你感兴趣的那些CAN报文ID,那么MCU就只能收到这些CAN报文,是从硬件上过滤掉,完全不需要软件参与进来,从而节省了大大节省了MCU的时间,可以更加专注于其他事务,这个就是bxCAN过滤器的意义所在。
2.2. 两种过滤模式(列表模式与掩码模式)
假设我们是bxCAN这个IP的设计者,现在由我们来设计过滤器,那么我们该如何设计呢?
首先我们是不是很快就会想到只要准备好一张表,把我们需要关注的所有CAN报文ID写上去,开始过滤的时候只要对比这张表,如果接收到的报文ID与表上的相符,则通过,如果表上没有,则不通过,这个就是简单的过滤方案。恭喜你!bxCAN过滤器的列表模式采用的就是这种方案。
但是,这种列表方案有点缺陷,即如果我们只关注一个报文ID,则需要往列表中写入这个ID,如果需要关注两个,则需要写入两个报文ID,如果需要关注100个,则需要写入100个,如果需要1万个,那么需要写入1万个,可问题是,有这个大的列表供我们使用吗?大家都知道,MCU上的资源是有限的,不可能提供1万个或更多,甚至100个都嫌多。非常明显,这种列表的方式受到列表容量大小的限制,实际上,bxCAN的一个过滤器若工作在列表模式下,scale为32时,每个过滤器的列表只能写入两个报文ID,若scale为16时,每个过滤器的列表最多可写入4个CAN ID,由此可见,MCU的资源是非常非常有限的,并不能任我们随心所欲。因此,我们需要考虑另外一种替代方案,这种方案应该不受到数量限制。
下面假设我们是古时候一座城镇的守卫,城主要求只有1156年出生的人才可以进城,我们又该如何执行呢?假设古时候的人也有类似今天的身份证(...->_<-…),大家都知道,身份份证号码中有4位是表示出生年月,如下图:
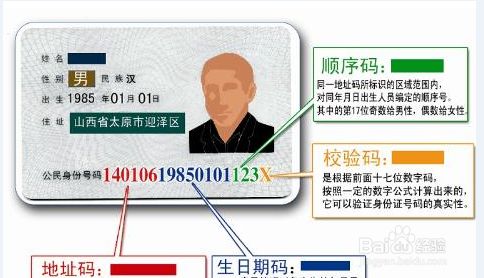
图 1 18位身份证号码的各位定义
如上图,身份证中第7~10这4位数表示的是出生年份,那么,我们可以这么执行:
检查想要进城的所有人的身份证号码的第7~10位数字,如果这个数字依次为1156则可以进入,否则则不可以,至于身份证号码的其他位则完全不关心。假如过几天城主放宽进城条件为只要是1150年~1160前的人都可以进城,那么,我们就可以只关注身份证号码的第7~9这3位数是否为115就可以了,对不对?这样一来,我们就可以非常完美地执行城主的要求了。
再变下,假设现在使用机器来当守卫,不再是人来执行这个“筛选”工作。机器是死的,没有人那么灵活,那么机器又该如何执行呢?
对于机器来说,每一步都得细化到机器可以理解的程度,于是我们可以作如下细化:
第一步:获取想进城的人的身份证号码
第二步:只看获取到身份证的第7~9位,其他位忽略
第三步:将忽略后的结果与1156进行比较
第四步:比较结果相同则通过,不同则不能通过
这种方式,我们称之为掩码模式。
2.3. 验证码与屏蔽码
仔细查看上面4个步骤,这不就是C代码中的if语句吗?如下:
- if( x & y ==z) //x表示待检查身份证号码,y表示只关注第7~9位的屏蔽码,Z则为1156,这里叫做验证码
- {
- //可以通过
- }
- else
- {
- //不可以通过
- }
对于机器来说,我们要为它准备好两张纸片,一片写上屏蔽码,另一片纸片写上验证码,屏蔽码上相应位为1时,表示此位需要与验证码对应位进行比较,反之,则表示不需要。机器在执行任务的时候先将获取的身份证号码与屏蔽码进行“与”操作,再将结果与验证码的进行比较,根据判断是否相同来决定是否通过。整个判别流程如下所示:
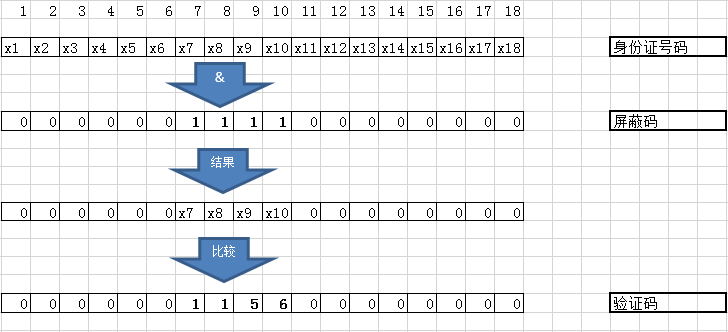
图 2 掩码模式的计算过程
从上图可以很容易地理解屏蔽码与验证码的含义,这样一来,能通过的结果数量就完全取决于屏蔽码,设得宽,则可以通过的多(所有位为0,则不过任何过滤操作,则谁都可以通过),设得窄,则通过的少(所有位设为1,则只有一个能通过)。那么知道这个有什么用呢?因为bxCAN的过滤器的掩码模式就是采用这种方式,在bxCAN中,分别采用了两个寄存器(CAN_FiR1,CAN_FiR2)来存储屏蔽码与验证码,从而实现掩码模式的工作流程的。这样,我们就知道了bxCAN过滤器的掩码模式的大概工作原理。
但是,我们得注意到,采用掩码模式的方式并不能精确的对每一个ID进行过滤,打个比方,还是采用之前的守卫的例子,假如城主要求只有1150~1158年出生的人能通过,那么,若我们还是使用刚才的掩码模式,那么掩码就设为第7~9位为”1”,对应的,验证码的7~9位分别为”115”,这样就可以了。但是,仔细一想,出生于1159的人还是可以通过,是不是?但总体来说,虽然没有做到精确过滤,但我们还是能做到大体过滤的,而这个就是掩码模式的缺点了。在实际应用时,取决于需求,有时我们会同时使用到列表模式和掩码模式,这都是可能的。
2.4. 列表模式与掩码模式的对比
综合之前所述,下面我们来对比一下列表模式与掩码模式这两种模式的优缺点。
| 模式 | 优点 | 缺点 |
| 列表模式 | 能精确地过滤每个指定的CAN ID | 有数量限制 |
| 掩码模式 | 取决于屏蔽码,有时无法完全精确到每一个CAN ID,部分不期望的CAN ID有时也会收到 | 数量取决于屏蔽码,最多无上限 |
2.5. 标准CAN ID与扩展CAN ID
1986 年德国电气商BOSCH公司开发出面向汽车的CAN 通信协议,刚开始的时候,CAN ID定义为11位,我们称之为标准格式,ISO11898-1标准中CAN的基本格式如下图所示:
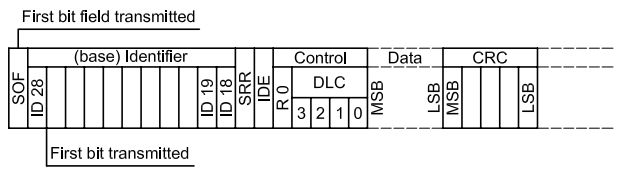
图 3 标准CAN报文格式定义
如上图所示,标准CAN ID存放在上图ID18~ID28中,共11位。随着工业发展,后来发现11位的CAN ID已经不够用,于是就增加了18位,扩展CAN ID到29位,如下图所示:

图 4 扩展CAN报文格式定义
从上图对比扩展CAN报文与标准CAN报文,发现在仲裁域部分,扩展CAN报文的CAN ID包含了base Identifier与extension Identifier,即基本ID与扩展ID,而标准CAN报文的CAN ID部分只包含基本ID,扩展ID(ID0~ID17)被放在基本ID的右方,也就是说,属于低位。知道这些有什么用呢?至少我们可以得到这两条信息:
- 标准ID一般小于或等于<=0x7FF(11位),只包含基本ID。
- 对于扩展CAN的低18位为扩展ID,高11位为基本ID。
例如标准CAN ID 0x7E1,二进制展开为0b 0[111 1110 0001] ,只有中括号内的11位才有效,其全部是基本ID。
再例如扩展CAN ID 0x1835f107,二进制展开为0b 000[1 1000 0011 10][01 11110001 0000 0111],只有红色中括号和绿色中括号内的位才有效,总共29位,左边红色中括号中的11位为基本ID,右边绿色中括号内的18位为扩展ID,请记住这个信息!知道这个之后,我们可以很方便地将一个CANID拆分成基本ID和扩展ID,这个也将在后续的内容中多次用到,再次留意一下,扩展ID是位于基本ID的右方,在扩展CAN ID的构成中,扩展ID位于低18位,而基本ID位于高11位,于是要获取一个扩展CANID的基本ID,就只需要将这个CANID右移18位(这种算法后续将多次用到,请务必记住!)。
3. bxCAN的过滤器的解决方案
终于进入到正题了!前面已经介绍了过滤器的列表模式与掩码模式,以及掩码模式下的屏蔽码与验证码的含义,还介绍了标准CAN ID与扩展CAN ID的组成部分。现在我们终于要站在bxCAN的角度来分析其过滤方案。
首先过滤模式分列表模式和掩码模式,因此,对于没有过滤器,我们需要这么一个位来标记,用户可以通过设置这个位来标记他到底是想要这个过滤器工作在列表模式下还是掩码模式,于是,这个表示过滤模式的位就定义在CAN_FM1R寄存器中的FBMx位上,如下图:
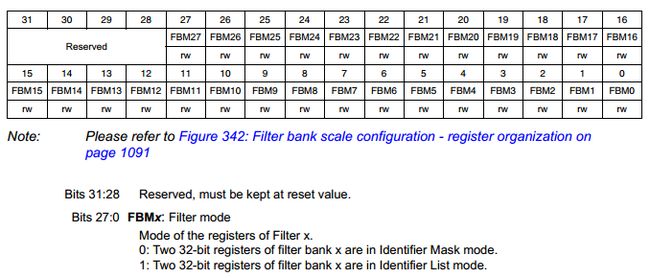
图5 CAN过滤器模式寄存器CAN_FM1R定义
这里以STM32F407为例,bxCAN共有28个过滤器,于是上图的每一个位对应地表示这28个过滤器的工作模式,供用户设置。”0”表示掩码模式,”1”表示列表模式。
另外,我们知道了标准CAN ID位11位,而扩展CAN ID有29位,对于标准的CAN ID来说,我们有一个16位的寄存器来处理他足够了,相应地,扩展CAN ID,我们就必须使用32位的寄存器来处理它,而在实际应用中,根据需求,我们可能自始至终都只需要处理11位的CAN ID。对于资源严重紧张的MCU环境来说,本着不浪费的原则,这里最好能有另外一个标志用告诉过滤器是否需要处理32位的CAN ID。于是,bxCAN处于这种考虑,也设置了这么一个寄存器CAN_FS1R来表示CAN ID的位宽,如下图所示:

图6 CAN过滤器位宽寄存器CAN_FS1R定义
如上图,每一个位对应着bxCAN中28个过滤器的位宽,这个需要用户来设置。
于是根据模式与位宽的设置,我们共可以得出4中不同的组合:32位宽的列表模式,16位宽的列表模式,32位宽掩码模式,16位宽的掩码模式。如下图所示:
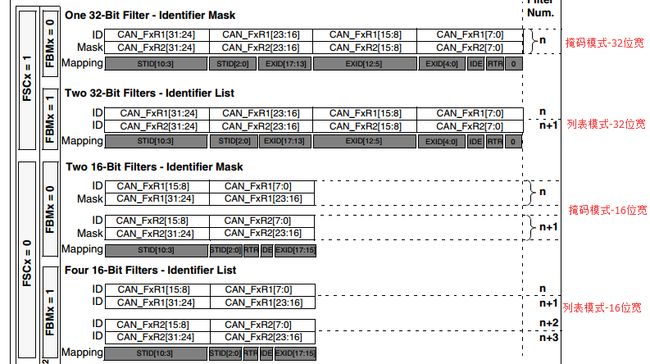
图 7 CAN过滤器的4中工作模式
在bxCAN中,每个过滤器都存在这么两个寄存器CAN_FxR1和CAN_FxR2,这两个寄存器都是32位的,他的定义并不是固定的,针对不同的工作模式组合他的定义是不一样的,如列表模式-32位宽模式下,这两个寄存器的各位定义都是一样的,都用来存储某个具体的期望通过的CAN ID,这样就可以存入2个期望通过的CAN ID(标准CAN ID和扩展CAN ID均可);若在掩码模式-32位宽模式下时,则CAN_FxR1用做32位宽的验证码,而CAN_FxR2则用作32位宽的屏蔽码。在16位宽时,CAN_FxR1和CAN_FxR2都要各自拆分成两个16位宽的寄存器来使用,在列表模式-16位宽模式下,CAN_FxR1和CAN_FxR2定义一样,且各自拆成两个,则总共可以写入4个标准CAN ID,若在16位宽的掩码模式下,则可以当做2对验证码+屏蔽码组合来用,但它只能对标准CAN ID进行过滤。这个就是bxCAN过滤器的解决方案,它采用了这4种工作模式。
本着从易到难得目的,下面我们将依次介绍如何使用bxCAN的这4种工作模式并给出对应的代码示例.
4. 应用实例
4.1. 工程建立及主体代码
本文硬件采用STM3240G-EVAL评估板和ZLG的USBCAN-2E-U及其配套的软件工具CANTest来实现对MCU进行CAN报文的发送。工程使用STM32CubeMx自动生成:
引脚如下:
PD0: CAN1_Rx
PD1: CAN1_Tx
PG6: LED1
PG8: LED2
PI9: LED3
PC7: LED4

图 8 引脚定义
时钟树如下设置:
图 9时钟树设置
在配置中的NVIC中,打开CAN1 RX0接收中断,如下图所示:
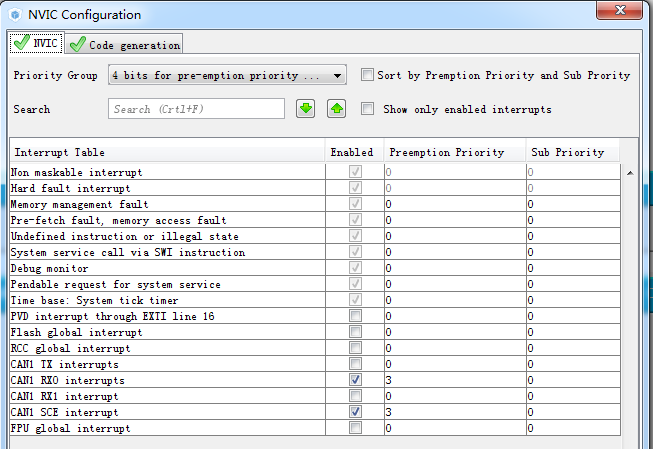
图 10 打开CAN1的RX0接收中断
其他的没有什么特殊设置,生成工程后的main函数如下:
- int main(void)
- {
- /* USER CODE BEGIN 1 */
- static CanTxMsgTypeDef TxMessage;
- static CanRxMsgTypeDef RxMessage;
- /* USER CODE END 1 */
- /* MCU Configuration----------------------------------------------------------*/
- /* Reset of all peripherals, Initializes the Flash interface and the Systick. */
- HAL_Init();
- /* Configure the system clock */
- SystemClock_Config();
- /* Initialize all configured peripherals */
- MX_GPIO_Init();
- MX_CAN1_Init();
- /* USER CODE BEGIN 2 */
- hcan1.pTxMsg =&TxMessage;
- hcan1.pRxMsg =&RxMessage;
- CANFilterConfig_Scale32_IdList(); //列表模式-32位宽
- //CANFilterConfig_Scale16_IdList(); //列表模式-16位宽
- //CANFilterConfig_Scale32_IdMask_StandardIdOnly(); //掩码模式-32位宽(只有标准CAN ID)
- //CANFilterConfig_Scale32_IdMask_ExtendIdOnly(); //掩码模式-32位宽(只用扩展CAN ID)
- //CANFilterConfig_Scale32_IdMask_StandardId_ExtendId_Mix(); //掩码模式-32位宽(标准CANID与扩展CAN ID混合)
- //CANFilterConfig_Scale16_IdMask(); //掩码模式-16位宽
- HAL_CAN_Receive_IT(&hcan1,CAN_FIFO0);
- /* USER CODE END 2 */
- /* Infinite loop */
- /* USER CODE BEGIN WHILE */
- while (1)
- {
- /* USER CODE END WHILE */
- /* USER CODE BEGIN 3 */
- }
- /* USER CODE END 3 */
- }
如上代码所示,示例中将采用各种过滤器配置来演示,在测试时我们可以只保留一种配置,也可以全部打开,为了确保每种配置的准确性,这里建议只保留其中一种配置进行测试。
另外,接收中断回调函数如下所示:
- void HAL_CAN_RxCpltCallback(CAN_HandleTypeDef* hcan)
- {
- if(hcan->pRxMsg->StdId ==0x321)
- {
- //handle the CAN message
- HandleCANMessage(hcan->pRxMsg); //处理接收到的CAN报文
- }
- if(hcan->pRxMsg->ExtId ==0x1800f001)
- {
- HandleCANMessage(hcan->pRxMsg); //处理接收到的CAN报文
- }
- HAL_GPIO_WritePin(LED4_GPIO_Port,LED4_Pin,GPIO_PIN_SET); //若收到消息则闪烁下LED4
- HAL_Delay(200);
- HAL_GPIO_WritePin(LED4_GPIO_Port,LED4_Pin,GPIO_PIN_RESET);
- HAL_CAN_Receive_IT(&hcan1,CAN_FIFO0);
- }
接下来将分别介绍过滤器的4中工作模式以及所对应的代码示例。
4.2. 32位宽的列表模式

图11 32位宽下的CAN_FxR1与CAN_FxR2各位定义
如上图所示,在32位宽的列表模式下,CAN_FxR1与CAN_FxR2都用来存储希望通过的CAN ID,由于是32位宽的,因此既可以存储标准CAN ID,也可以存储扩展CAN ID。注意看上图最底下的各位定义,可以看出,从右到左,首先,最低位是没有用的,然后是RTR,表示是否为远程帧,接着IDE,扩展帧标志,然后才是EXID[0:17]这18位扩展ID,最后才是STID[0:10]这11位标准ID,也就是前面所说的基本ID。在进行配置的时候,即将希望通过的CAN ID写入的时候,要注意各个位对号入座,即基本ID放到对应的STD[0:10],扩展ID对应放到EXID[0:17],若是扩展帧,则需要将IDE设为“1”,标准帧则为“0”,数据帧设RTR为“0”,远程帧设RTR为“1”。示例代码如下:
- static void CANFilterConfig_Scale32_IdList(void)
- {
- CAN_FilterConfTypeDef sFilterConfig;
- uint32_t StdId =0x321; //这里写入两个CAN ID,一个位标准CAN ID
- uint32_t ExtId =0x1800f001; //一个位扩展CAN ID
- sFilterConfig.FilterNumber = 0; //使用过滤器0
- sFilterConfig.FilterMode = CAN_FILTERMODE_IDLIST; //设为列表模式
- sFilterConfig.FilterScale = CAN_FILTERSCALE_32BIT; //配置为32位宽
- sFilterConfig.FilterIdHigh = StdId<<5; //基本ID放入到STID中
- sFilterConfig.FilterIdLow = 0|CAN_ID_STD; //设置IDE位为0
- sFilterConfig.FilterMaskIdHigh = ((ExtId<<3)>>16)&0xffff;
- sFilterConfig.FilterMaskIdLow = (ExtId<<3)&0xffff|CAN_ID_EXT; //设置IDE位为1
- sFilterConfig.FilterFIFOAssignment = 0; //接收到的报文放入到FIFO0中
- sFilterConfig.FilterActivation = ENABLE;
- sFilterConfig.BankNumber = 14;
- if(HAL_CAN_ConfigFilter(&hcan1, &sFilterConfig) != HAL_OK)
- {
- Error_Handler();
- }
- }
这里需要说明一下,由于我们使用的是cube库,在cube库中,CAN_FxR1与CAN_FxR2寄存器分别被拆成两段,CAN_FxR1寄存器的高16位对应着上面代码中的FilterIdHigh,低16位对应着FilterIdLow,而CAN_FxR2寄存器的高16位对应着FilterMaskIdHigh,低16位对应着FilterMaskIdLow,这个CAN_FilterConfTypeDef的的4个成员FilterIdHigh,FilterIdLow,FilterMaskIdHigh,FilterMaskIdLow,不应该单纯看其名字,被其名字误导,而应该就单纯地将这4个成员看成4个uint_16类型的变量x,y,m,n而已,后续其他示例也是同样理解,不再重复解释。这4个16位的变量其具体含义取决于当前过滤器工作与何种模式,比如当前32位宽的列表模式下,FilterIdHigh与FilterIdLow一起用来存放一个CAN ID,FilterMaskIdHigh与FilterMaskIdLow用来存放另一个CAN ID,不再表示其字面所示的mask含义,这点我们需要特别注意。
在上述代码示例中,我们分别将标准CAN ID和扩展CAN ID放入到CAN_FxR1与CAN_FxR2寄存器中。对于标准CAN ID,对比 图11,由于标准CAN ID只拥有标准ID,所以,只需要将标准ID放入到高16位的STID[0:10]中,高16位最右边被EXID[13:17]占着,因此,需要将StdId左移5位才能刚好放入到CAN_FxR1的高16位中,于是有了:
- sFilterConfig.FilterIdHigh = StdId<<5;
另一个扩展CAN ID ExtId类型,将其基本ID放入到STID中,扩展ID放入到EXID中,最后设置IDE位为1。就这样配置好了。
4.3. 16位宽的列表模式

图12 16位宽的列表模式
如上图所示,在16位宽的列表模式下,FilterIdHigh,FilterIdLow,FilterMaskIdHigh,FilterMaskIdLow这4个16位变量都是用来存储一个标准CAN ID,这样,就可以存放4个标准CAN ID了,需要注意地是,此种模式下,是不能处理扩展CANID,凡是需要过滤扩展CAN ID的,都是需要用到32位宽的模式。于是有以下代码示例:
- static void CANFilterConfig_Scale16_IdList(void)
- {
- CAN_FilterConfTypeDef sFilterConfig;
- uint32_t StdId1 =0x123; //这里采用4个标准CAN ID作为例子
- uint32_t StdId2 =0x124;
- uint32_t StdId3 =0x125;
- uint32_t StdId4 =0x126;
- sFilterConfig.FilterNumber = 1; //使用过滤器1
- sFilterConfig.FilterMode = CAN_FILTERMODE_IDLIST; //设为列表模式
- sFilterConfig.FilterScale = CAN_FILTERSCALE_16BIT; //位宽设置为16位
- sFilterConfig.FilterIdHigh = StdId1<<5; //4个标准CAN ID分别放入到4个存储中
- sFilterConfig.FilterIdLow = StdId2<<5;
- sFilterConfig.FilterMaskIdHigh = StdId3<<5;
- sFilterConfig.FilterMaskIdLow = StdId4<<5;
- sFilterConfig.FilterFIFOAssignment = 0; //接收到的报文放入到FIFO0中
- sFilterConfig.FilterActivation = ENABLE;
- sFilterConfig.BankNumber = 14;
- if(HAL_CAN_ConfigFilter(&hcan1, &sFilterConfig) != HAL_OK)
- {
- Error_Handler();
- }
- }
可见,列表模式还是非常好理解的。
4.4. 32位宽掩码模式

图13 32位宽掩码模式
如上图所示,32位宽模式下,FilterIdHigh与FilterIdLow合在一起表示CAN_FxR1寄存器,用来存放验证码,而FilterMaskIdHigh与FilterMaskIdLow合在一起表示CAN_FxR2寄存器,用来存放屏蔽码,关于验证码与屏蔽码的概念在之前的2.3节已经明确说明了,不清楚的可以回过去看看2.3节的内容。在32位宽的掩码模式下,既可以过滤标准CAN ID,也可以过滤扩展CAN ID,甚至两者混合这来也是可以的,下面我们就这3中情况分别给出示例。
4.4.1. 只针对标准CAN ID
如下代码示例:
- static void CANFilterConfig_Scale32_IdMask_StandardIdOnly(void)
- {
- CAN_FilterConfTypeDef sFilterConfig;
- uint16_t StdIdArray[10] ={0x7e0,0x7e1,0x7e2,0x7e3,0x7e4,
- 0x7e5,0x7e6,0x7e7,0x7e8,0x7e9}; //定义一组标准CAN ID
- uint16_t mask,num,tmp,i;
- sFilterConfig.FilterNumber = 2; //使用过滤器2
- sFilterConfig.FilterMode = CAN_FILTERMODE_IDMASK; //配置为掩码模式
- sFilterConfig.FilterScale = CAN_FILTERSCALE_32BIT; //设置为32位宽
- sFilterConfig.FilterIdHigh =(StdIdArray[0]<<5); //验证码可以设置为StdIdArray[]数组中任意一个,这里使用StdIdArray[0]作为验证码
- sFilterConfig.FilterIdLow =0;
- mask =0x7ff; //下面开始计算屏蔽码
- num =sizeof(StdIdArray)/sizeof(StdIdArray[0]);
- for(i =0; i
- {
- tmp =StdIdArray[i] ^ (~StdIdArray[0]); //所有数组成员与第0个成员进行同或操作
- mask &=tmp;
- }
- sFilterConfig.FilterMaskIdHigh =(mask<<5);
- sFilterConfig.FilterMaskIdLow =0|0x02; //只接收数据帧
- sFilterConfig.FilterFIFOAssignment = 0; //设置通过的数据帧进入到FIFO0中
- sFilterConfig.FilterActivation = ENABLE;
- sFilterConfig.BankNumber = 14;
- if(HAL_CAN_ConfigFilter(&hcan1, &sFilterConfig) != HAL_OK)
- {
- Error_Handler();
- }
- }
如上代码所示,对于验证码,任意一个期望通过的CAN ID都是可以设为验证码的,但屏蔽码,却是所有期望通过的CAN ID相互同或后的最终结果,这个即是屏蔽码。
4.4.2. 只针对扩展CAN ID
如下代码示例:
- static void CANFilterConfig_Scale32_IdMask_ExtendIdOnly(void)
- {
- CAN_FilterConfTypeDef sFilterConfig;
- //定义一组扩展CAN ID用来测试
- uint32_t ExtIdArray[10] ={0x1839f101,0x1835f102,0x1835f113,0x1835f124,0x1835f105,
- 0x1835f106,0x1835f107,0x1835f108,0x1835f109,0x1835f10A};
- uint32_t mask,num,tmp,i;
- sFilterConfig.FilterNumber = 3; //使用过滤器3
- sFilterConfig.FilterMode = CAN_FILTERMODE_IDMASK; //配置为掩码模式
- sFilterConfig.FilterScale = CAN_FILTERSCALE_32BIT; //设为32位宽
- sFilterConfig.FilterIdHigh =((ExtIdArray[0]<<3) >>16) &0xffff;//数组任意一个成员都可以作为验证码
- sFilterConfig.FilterIdLow =((ExtIdArray[0]<<3)&0xffff) | CAN_ID_EXT;
- mask =0x1fffffff;
- num =sizeof(ExtIdArray)/sizeof(ExtIdArray[0]);
- for(i =0; i
- {
- tmp =ExtIdArray[i] ^ (~ExtIdArray[0]); //都与第一个数据成员进行同或操作
- mask &=tmp;
- }
- mask <<=3; //对齐寄存器
- sFilterConfig.FilterMaskIdHigh = (mask>>16)&0xffff;
- sFilterConfig.FilterMaskIdLow = (mask&0xffff)|0x02; //只接收数据帧
- sFilterConfig.FilterFIFOAssignment = 0;
- sFilterConfig.FilterActivation = ENABLE;
- sFilterConfig.BankNumber = 14;
- if(HAL_CAN_ConfigFilter(&hcan1, &sFilterConfig) != HAL_OK)
- {
- Error_Handler();
- }
- }
如上代码所示,与之前的标准CAN ID相比,扩展CAN ID的验证码与屏蔽码放入到相对应的寄存器时所移动的位数与标准CAN ID时有所差别,其他的都一样。
接下来是标准CAN ID与扩展CAN ID混合着来。
4.4.3. 标准CAN ID与扩展CAN ID混合过滤
如下代码所示:
- static void CANFilterConfig_Scale32_IdMask_StandardId_ExtendId_Mix(void)
- {
- CAN_FilterConfTypeDef sFilterConfig;
- //定义一组标准CAN ID
- uint32_t StdIdArray[10] ={0x711,0x712,0x713,0x714,0x715,
- 0x716,0x717,0x718,0x719,0x71a};
- //定义另外一组扩展CAN ID
- uint32_t ExtIdArray[10] ={0x1900fAB1,0x1900fAB2,0x1900fAB3,0x1900fAB4,0x1900fAB5,
- 0x1900fAB6,0x1900fAB7,0x1900fAB8,0x1900fAB9,0x1900fABA};
- uint32_t mask,num,tmp,i,standard_mask,extend_mask,mix_mask;
- sFilterConfig.FilterNumber = 4; //使用过滤器4
- sFilterConfig.FilterMode = CAN_FILTERMODE_IDMASK; //配置为掩码模式
- sFilterConfig.FilterScale = CAN_FILTERSCALE_32BIT; //设为32位宽
- sFilterConfig.FilterIdHigh =((ExtIdArray[0]<<3) >>16) &0xffff; //使用第一个扩展CAN ID作为验证码
- sFilterConfig.FilterIdLow =((ExtIdArray[0]<<3)&0xffff);
- standard_mask =0x7ff; //下面是计算屏蔽码
- num =sizeof(StdIdArray)/sizeof(StdIdArray[0]);
- for(i =0; i
- {
- tmp =StdIdArray[i] ^ (~StdIdArray[0]);
- standard_mask &=tmp;
- }
- extend_mask =0x1fffffff;
- num =sizeof(ExtIdArray)/sizeof(ExtIdArray[0]);
- for(i =0; i
- {
- tmp =ExtIdArray[i] ^ (~ExtIdArray[0]);
- extend_mask &=tmp;
- }
- mix_mask =(StdIdArray[0]<<18)^ (~ExtIdArray[0]); //再计算标准CAN ID与扩展CAN ID混合的屏蔽码
- mask =(standard_mask<<18)& extend_mask &mix_mask; //最后计算最终的屏蔽码
- mask <<=3; //对齐寄存器
- sFilterConfig.FilterMaskIdHigh = (mask>>16)&0xffff;
- sFilterConfig.FilterMaskIdLow = (mask&0xffff);
- sFilterConfig.FilterFIFOAssignment = 0;
- sFilterConfig.FilterActivation = ENABLE;
- sFilterConfig.BankNumber = 14;
- if(HAL_CAN_ConfigFilter(&hcan1, &sFilterConfig) != HAL_OK)
- {
- Error_Handler();
- }
- }
如上代码所示,在混合的情况下,只需稍微修改下屏蔽码的计算方式就可以了,其他的基本没有什么变化。
4.5. 16位宽掩码模式
如下图所示:

图14 16位宽的掩码模式
如上图所示,在16位宽的掩码模式下,CAN_FxR1的低16位是作为验证码,对应的16位屏蔽码为CAN_FxR1的高16位,同样的,CAN_FxR2的低16位是作为验证码,对应与CAN_FxR2的高16位为屏蔽码。于是,其示例代码如下:
- static void CANFilterConfig_Scale16_IdMask(void)
- {
- CAN_FilterConfTypeDef sFilterConfig;
- uint16_t StdIdArray1[10] ={0x7D1,0x7D2,0x7D3,0x7D4,0x7D5, //定义第一组标准CAN ID
- 0x7D6,0x7D7,0x7D8,0x7D9,0x7DA};
- uint16_t StdIdArray2[10] ={0x751,0x752,0x753,0x754,0x755, //定义第二组标准CAN ID
- 0x756,0x757,0x758,0x759,0x75A};
- uint16_t mask,tmp,i,num;
- sFilterConfig.FilterNumber = 5; //使用过滤器5
- sFilterConfig.FilterMode = CAN_FILTERMODE_IDMASK; //配置为掩码模式
- sFilterConfig.FilterScale = CAN_FILTERSCALE_16BIT; //设为16位宽
- //配置第一个过滤对
- sFilterConfig.FilterIdLow =StdIdArray1[0]<<5; //设置第一个验证码
- mask =0x7ff;
- num =sizeof(StdIdArray1)/sizeof(StdIdArray1[0]);
- for(i =0; i
- {
- tmp =StdIdArray1[i] ^ (~StdIdArray1[0]);
- mask &=tmp;
- }
- sFilterConfig.FilterMaskIdLow =(mask<<5)|0x10; //只接收数据帧
- //配置第二个过滤对
- sFilterConfig.FilterIdHigh = StdIdArray2[0]<<5; //设置第二个验证码
- mask =0x7ff;
- num =sizeof(StdIdArray2)/sizeof(StdIdArray2[0]);
- for(i =0; i
- {
- tmp =StdIdArray2[i] ^ (~StdIdArray2[0]);
- mask &=tmp;
- }
- sFilterConfig.FilterMaskIdHigh = (mask<<5)|0x10; //只接收数据帧
- sFilterConfig.FilterFIFOAssignment = 0; //通过的CAN 消息放入到FIFO0中
- sFilterConfig.FilterActivation = ENABLE;
- sFilterConfig.BankNumber = 14;
- if(HAL_CAN_ConfigFilter(&hcan1, &sFilterConfig) != HAL_OK)
- {
- Error_Handler();
- }
- }
如上代码所示,在这种模式下,其特殊之处就是可以配置两套验证码,屏蔽码组合,可以分别相对独立地对标准CAN ID进行过滤。
4.6. 测试验证
上述代码运行的STM3240G-EVAL评估板上,使用ZLG的USBCAN-2E-U盒子配合PC上的软件CANTest进行验证,整个系统连接后的效果如下图所示:
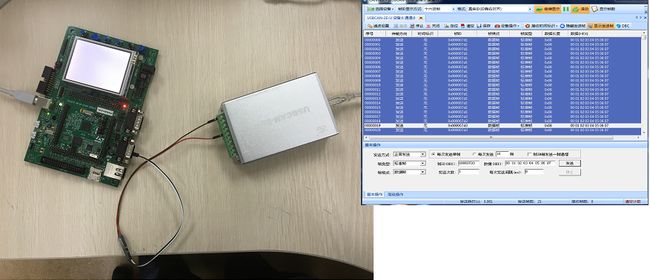
图 15 测试环境
测试时,逐个测试各个配置,并使用PC端软件CANTest发送各个测试的CAN ID均能通过,而使用其他的CAN ID则不能通过,测试结果正常.
5. 总结
在实际的应用中,我们需要根据需求的实际情况来决定使用何种过滤配置,STM32F4的bxCAN提供了28个过滤器,在配置之前,我们需要先将那些需要通过的CANID进行整理,若数量少,则使用列表模式,精准,若只有标准CAN ID,则可以考虑使用16位宽模式,若需求中的CAN ID过多,则可以考虑使用多个过滤器,部分使用列表模式,部分使用掩码模式,CAN ID值相近的可以归纳成一组,使用掩码模式进行过滤。但使用掩码模式的同时,我们也需要意识到,也有可能部分不期望的CAN ID也会通过过滤器,掩码放得越宽,带进其他CAN ID的几率就越大,这点我们需要格外注意,视情况进行应用判断和处理。另外,对于相近的CAN ID,我们可以提前计算好屏蔽码,直接在代码中填入,而不是在代码中临时计算,这样可以提高软件效率,大家视情况而定。
几年前我有写过一篇关于CAN ID过滤器的另外一篇文章,是基于标准库的,感兴趣的朋友可以参考下: http://blog.csdn.net/flydream0/article/details/8148791