Mybatis-plus---的批量插入

批量插入
一、继承IService(伪批量)
二、insertBatchSomeColumn
Mybatis-plus很强,为我们诞生了极简CURD操作,但对于数据批量操作,显然默认提供的insert方法是不够看的了,于是它和它来了!!! Mybatis-plus提供的两种插入方式
继承IService(伪批量)
insertBatchSomeColumn
一、继承IService(伪批量)
在Mapper继承BaseMapper
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.demo.entity.UserStudy;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface UserStudyMapper extends BaseMapper {
}
在Service中继承IService
import com.baomidou.mybatisplus.extension.service.IService;
import com.example.demo.entity.UserStudy;
/********************************************************************************
** @author : ZYJ
** @date :2023/04/20
** @description :厂长老婆催的睡觉了-批量插入Service
*********************************************************************************/
public interface UserStudyService extends IService {
} 在Service实现类继承ServiceImpl
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.example.demo.entity.UserStudy;
import com.example.demo.mapper.UserStudyMapper;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
/********************************************************************************
** @author : ZYJ
** @date :2023/04/04
** @description :厂长加班写代码-批量插入
*********************************************************************************/
@Service
public class UserStudyServiceImpl extends ServiceImpl implements UserStudyService {
@Resource
private UserStudyMapper userStudyMapper;
} 测试代码,调用IService的saveBatch方法
/*
*批量插入
*/
@Override
public void greatMany() {
List userStudyList = new ArrayList<>();
UserStudy userStudy1 = new UserStudy();
userStudy1.setName("张三");
UserStudy userStudy2 = new UserStudy();
userStudy2.setName("李四");
userStudyList.add(userStudy1);
userStudyList.add(userStudy2);
//调用IService的saveBatch方法
this.saveBatch(userStudyList);
} Mybatis-plus的SQL日志打印在配置文件application.yml配置
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #开启sql日志
# log-impl: org.apache.ibatis.logging.nologging.NoLoggingImpl #关闭sql日志测试结果,代码执行打印了两条SQL,所以可以看得出saveBatch底层也是遍历循环完成
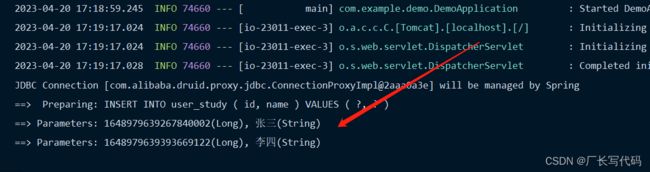
saveBatch方法分析
底层也是通过for来完成,默认是一个事务一次提交1000条数据,点击进入saveBatch可以看到, 也可以自定义每次提交多少条,自定义如下
//调用IService的saveBatch方法
this.saveBatch(userStudyList,2000);二、insertBatchSomeColumn
自定义SQL注入器
import com.baomidou.mybatisplus.core.injector.AbstractMethod;
import com.baomidou.mybatisplus.core.injector.DefaultSqlInjector;
import com.baomidou.mybatisplus.extension.injector.methods.InsertBatchSomeColumn;
import java.util.List;
/********************************************************************************
** @author : ZYJ
** @date :2023/03/09
** @description :厂长加班写代码-批量插入SQL注入器
*********************************************************************************/
public class InsertBatchSqlInjector extends DefaultSqlInjector {
@Override
public List getMethodList(Class mapperClass) {
List methodList = super.getMethodList(mapperClass);
methodList.add(new InsertBatchSomeColumn()); //添加InsertBatchSomeColumn方法
return methodList;
}
} 把SQL注入器交给Spring
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
@Component
public class MybatisPlusConfig {
/********************************************************************************
** @author : ZYJ
** @date :2023/04/14
** @description :注入配置
*********************************************************************************/
@Bean
public InsertBatchSqlInjector easySqlInjector () {
return new InsertBatchSqlInjector();
}
}
到此定义完毕,在Mapper中生成insertBatchSomeColumn(必须是这个方法名)方法,你就可以撒手不管了,直接调用就行,或者直接在ServiceImpl通过Mapper调用insertBatchSomeColumn,然后ALT+回车生成此方法。
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.demo.entity.UserStudy;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import java.util.List;
@Mapper
public interface UserStudyMapper extends BaseMapper {
void insertBatchSomeColumn(@Param("list") List userStudyList);
} 测试代码,调用insertBatchSomeColumn方法
@Resource
private UserStudyMapper userStudyMapper;
/*
*批量插入
*/
@Override
public void greatMany() {
List userStudyList = new ArrayList<>();
UserStudy userStudy1 = new UserStudy();
userStudy1.setName("张三");
UserStudy userStudy2 = new UserStudy();
userStudy2.setName("李四");
userStudyList.add(userStudy1);
userStudyList.add(userStudy2);
//调用insertBatchSomeColumn方法
userStudyMapper.insertBatchSomeColumn(userStudyList);
//调用IService的saveBatch方法
//this.saveBatch(userStudyList,2000);
} 测试结果,代码执行打印一条SQL,所以可以看出是一条SQL便新增完成

注意:SQL有语句长度限制,在MySQL中被参数max_allowed_packet限制,默认为1M,如果拼接长度超过此限制就会报错,两种解决方式,一个是调整MySQL的max_allowed_packet 限制,另一个则是通过代码控制每次的提交数量。
通过代码控制每次提交数量,模拟造五条数据,每次提交两条数据
/*
*批量插入
*/
@Override
public void greatMany() {
List userStudyList = new ArrayList<>();
UserStudy userStudy1 = new UserStudy();
userStudy1.setName("张三");
UserStudy userStudy2 = new UserStudy();
userStudy2.setName("李四");
UserStudy userStudy3 = new UserStudy();
userStudy3.setName("王五");
UserStudy userStudy4 = new UserStudy();
userStudy4.setName("赵六");
UserStudy userStudy5 = new UserStudy();
userStudy5.setName("小红");
userStudyList.add(userStudy1);
userStudyList.add(userStudy2);
userStudyList.add(userStudy3);
userStudyList.add(userStudy4);
userStudyList.add(userStudy5);
//创建入库的list
List userStudyCount = new ArrayList<>();
for (int i = 0; i < userStudyList.size(); i++) {
//调用insertBatchSomeColumn方法
userStudyCount.add(userStudyList.get(i));
//控制每次提交数量
if(userStudyCount.size()==2){
userStudyMapper.insertBatchSomeColumn(userStudyCount);
//将入库的list清空重新新增
userStudyCount.clear();
}
}
//将list中size不够2的数据在此处新增
userStudyMapper.insertBatchSomeColumn(userStudyCount);
//调用IService的saveBatch方法
//this.saveBatch(userStudyList,2000);
} 结果分析,五条数据应该请求三次新增,打印三条SQL,完美结束
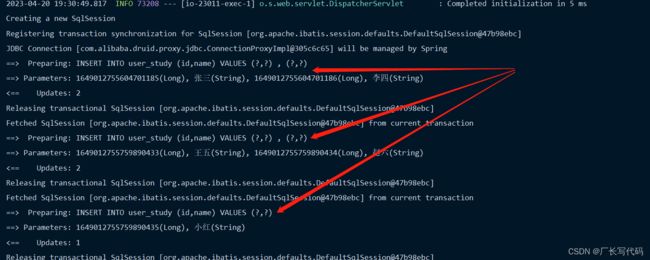
总结:默认的insert的方法对寻常业务来说是非常之高效,但对于批量数据的产生确实灾难性的,就是慢,很慢,巨慢,IService的saveBatch方法优于默认的insert方法,但是我选通过SQL注入器的方法insertBatchSomeColumn。