kesci数据分类练习赛:提供银行精准营销解决方案(附源码)
(kesci数据分类预测)提供银行精准营销解决方案练习赛
kesci的一个练习赛:https://www.kesci.com/home/competition/5c234c6626ba91002bfdfdd3/content
赛题描述
训练集有20000多条,测试集10000多条,16维特征,最后有两种结果分类:0(不会买银行的产品)和1(会买银行的产品):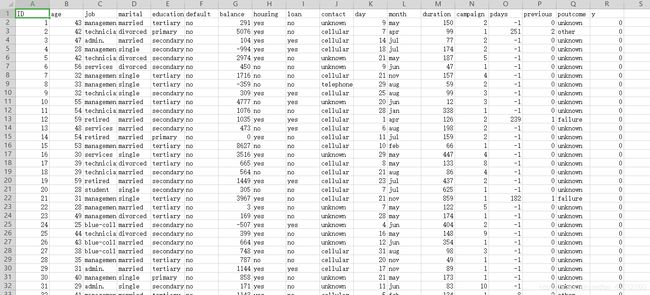
数据预处理
先引入包和读入数据集(包括sklearn中的机器学习算法包和深度学习框架keras),关于分类预测算法可以看我之前的博文:https://blog.csdn.net/qq_43012160/article/details/96303739
import pandas as pd
import numpy as np
import time
import lightgbm as lg
from keras import models
from keras import layers
from keras.utils.np_utils import to_categorical
from keras.preprocessing.text import Tokenizer
from sklearn import metrics
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.neural_network import MLPClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import BernoulliNB
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
#读数据集:
train_data = pd.read_csv('train_set.csv', lineterminator='\n')
test_data=pd.read_csv('test_set.csv', lineterminator='\n')
观察数据集,pdays特征指客户上次与银行联系过去的天数,-1指没联系过。为了保证数据的单调性,即值越大表示用户与银行的联系越久远、越不活跃,用excel的筛选发现这一特征的最大值为854,所以把所有的-1都改成999:
#数据预处理:
print("数值处理:")
#数据中pdays=-1表示从未联络过,替换为999
train_data['pdays'].replace(-1,999,inplace=True)
test_data['pdays'].replace(-1,999,inplace=True)
之后提取一下训练集的分类标签,方便后面给分类器传参:
#提取训练集标签
def getLabel(data):
listLable=[]
for lable in data['y']:
listLable.append(lable)
return listLable
trainLable=np.array(getLabel(train_data))
因为现在有很多特征的值还是字符串,但是最后分类器接收的参数是全数值得二维矩阵,所以我们要给这些特征进行编码。因为编码耗时比较长,而且不管什么分类器都是用这一套编码后的数据,编码完可以保存到文件里,下次用的时候直接从文件里读入就行了。这里比较复杂,我们先大概浏览一下代码:
print("编码:")
#提取要编码的特征目录:
changeColumns=['job','marital','education','default','housing','loan','contact','month','poutcome']
dataColumns=[]
for elem in test_data.columns:
if not(elem=='ID'): dataColumns.append(elem)
#规格化编码特征标签:
print("标准化与规格化:")
def getReview(data):
ResultReview=[]
listReview=data
le = LabelEncoder()
std = StandardScaler()
scl=MinMaxScaler()
for column in changeColumns:
listData=[]
ResultData=[]
for review in data[column]:
listData.append(review)
ResultData=le.fit_transform(listData)
listReview[column]=ResultData
#不同特征编码的归一化:
for column in dataColumns:
listReview[column]=scl.fit_transform(listReview[column].values.reshape(-1,1))
#处理负数:
min = 0
for column in dataColumns:
print('正在寻找最小值:',column,'...')
for elem in listReview[column]:
if elem < min: min = elem
for column in dataColumns:
print('正在处理',column,'...')
for i in range(len(listReview[column])):
listReview.loc[i, column] = listReview.loc[i, column] - min
#向量化:
for i in range(len(data)):
rowVec=[]
for feature in dataColumns:
rowVec.append(listReview.loc[i,feature])
ResultReview.append(rowVec)
return ResultReview
#对处理完毕的训练集进行保存:
trainReview=np.array(getReview(train_data))
testReview=np.array(getReview(test_data))
np.save("trainReview.npy",trainReview)
np.save("testReview.npy",testReview)
LabelEncoder对特征进行编码
for column in changeColumns:
listData=[]
ResultData=[]
for review in data[column]:
listData.append(review)
ResultData=le.fit_transform(listData)
listReview[column]=ResultData
我们看到比如特征poutcome,有四种取值:
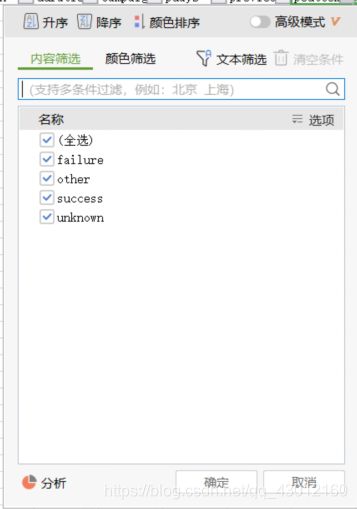
因为最后传给分类器得训练集是全数值得二维矩阵,所以我们就要用LabelEncoder给特征进行编码,比如把failure编码为0,other编码为1,success为2,unknown为3。实际LabelEncoder编码的时候不是按先后顺序来的,但用的就是这样一个编码规则。
不同特征取值的归一化
做好编码之后我们的所有特征值就全都用数字表示了,但我们注意到不同的特征间的数据取值范围是有很大差异的,比如age特征就只有几十,但是balance就可能是几千。这就是分类预测中不同特征的量纲问题,为了解决这个问题就要谈到数据的归一化、标准化和正则化:
1.常用的线性归一化即对某一特征的取值使用函数 y=(x-min)/(max-min)进行变换,把数据变为(0,1)之间的小数。归一化是为了消除不同数据之间的量纲, 把有量纲表达式变换为无量纲表达式,成为纯量。经过归一化处理的数据,处于同一数量级,可以消除指标之间的量纲和量纲单位的影响,提高不同数据指标之间的可比性,方便分类器对不同特征统一处理。
2.常用的零-均值标准化: y=(x-μ)/σ。可以使原本分布不均的数据变为正态分布,方便后续处理。
3.正则化而是利用先验知识,在处理过程中引入正则化因子(regulator),增加引导约束的作用,比如在逻辑回归中使用正则化,可有效降低过拟合的现象。
原博:https://blog.csdn.net/zyf89531/article/details/45922151
这里我们是为了消除不同特征之间的量纲,所以选择归一化处理:
for column in dataColumns:
listReview[column]=scl.fit_transform(listReview[column].values.reshape(-1,1))
新版本sklearn包提供的归一化器MinMaxScaler()要求提供的参数必须是一个二维矩阵,所以这里用了listReview[column].values.reshape(-1,1)将列向量转化为1列的二维矩阵。
处理负数
由于sklearn包有的分类器不接受负数,所以要把数据中的所有数都变成正数(即减去最小的负数):
#处理负数:
min = 0
for column in dataColumns:
print('正在寻找最小值:',column,'...')
for elem in listReview[column]:
if elem < min: min = elem
for column in dataColumns:
print('正在处理',column,'...')
for i in range(len(listReview[column])):
listReview.loc[i, column] = listReview.loc[i, column] - min
向量化
因为经过这些处理后的数组仍然是DataFrame,而分类器需要的参数是一个二维矩阵,矩阵由每条样本构成,而样本又是一个16维的向量,类似这样:
[[1,2,…,3,4],
[5,6,…,7,8],
…
[4,3,…,2,1]]
所以我们对DataFrame一行一行的处理,将每一行的数据(每条样本)处理为行向量,然后添加到目标数组中,再用np.array()方法将其转化为numpy矩阵:
#向量化:
for i in range(len(data)):
rowVec=[]
for feature in dataColumns:
rowVec.append(listReview.loc[i,feature])
ResultReview.append(rowVec)
return ResultReview
函数调用、数组转numpy矩阵与保存:
#对处理完毕的训练集进行保存:
trainReview=np.array(getReview(train_data))
testReview=np.array(getReview(test_data))
np.save("trainReview.npy",trainReview)
np.save("testReview.npy",testReview)
建模与预测
加载处理后的数据:
trainReview = np.load("trainReview.npy")
testReview = np.load("testReview.npy")
传统机器学习模型,这里经过实测发现逻辑回归、MLP、和随机森林效果比较好:
#传统机器学习模型预测:
print('建模:')
model = MLPClassifier()
model.fit(trainReview, trainLable)
print(model)
print('预测:')
pred_model = model.predict_proba(testReview)
深度学习模型(前馈神经网络,效果也不错):
#前馈神经网络模型预测:
print('建模:')
feature_num = trainReview.shape[1]
#求标签的独热编码矩阵
trainCate = to_categorical(trainLable)
#1 创建神经网络
network = models.Sequential()
#2 添加神经连接层
#第一层必须有并且一定是 [输入层], 必选
network.add(layers.Dense( # 添加带有 relu 激活函数的全连接层
units=100,
activation='relu',
input_shape=(feature_num, )
))
#介于第一层和最后一层之间的称为 [隐藏层],可选
network.add(layers.Dense( # 添加带有 relu 激活函数的全连接层
units=100,
activation='relu'
))
#最后一层必须有并且一定是 [输出层], 必选
network.add(layers.Dense( # 添加带有 softmax 激活函数的全连接层
units=2, #输出层感知器个数即标签维度/类数
activation='softmax'
))
#3 编译神经网络
network.compile(loss='categorical_crossentropy', # 分类交叉熵损失函数
optimizer='rmsprop',
metrics=['accuracy'] # 准确率度量,也是选定evaluate的指标值为准确度
)
#4 开始训练神经网络
network.fit(trainReview, # 训练集特征
trainCate, # 训练集标签
epochs=32, # 迭代次数
batch_size=100, # 指定进行梯度下降时每个batch包含的样本数
)
#利用模型进行预测
print('预测:')
pred_model = network.predict_proba(testReview)
为什么不用CNN
作为一个刚入门的初学者我最初也想CNN能不能用在这种分类问题上,后来发现是不行的。CNN主要的特点就是卷积和池化,而卷积和池化本身就建立在“数据的不同特征之间存在内在联系”,比如同一条文本的上下文或者同一张图片的相邻像素之间的。这里的分类特征之间是没有这种很强的不同特征之间的联系的(你要是硬说年龄越大越穷那我也没话说),所以CNN的卷积和池化对于这类分类问题是没有意义的,所以不用CNN来做这一类的分类预测。
结果的写入与展示
这里选取会买产品1(pos)和不会买产品0(neg)的占比打印:
print('写入结果:')
result=[]
for elem in pred_model:
result.append(elem[1])
dataframe = pd.DataFrame({'ID':test_data['ID'],'pred':result})
dataframe.to_csv("preResult.csv",index=False,sep=',')
#结果展示:
pos=0
neg=0
for elem in result:
if elem>0.5:pos=pos+1
else:neg=neg+1
print('pos:',pos/len(test_data))
print('neg:',neg/len(test_data))
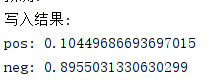
这里经过我多次测试,测试集里1和0大概是11:89左右的关系,我跑出来的最好的结果使用MLP跑出来的,评分是0.90(菜的抠jio):
我看第一名1.0的正确率,神仙吧。
源码:
链接:https://pan.baidu.com/s/1Hs7ZHkNSrVkpBrZlR0HFPg
提取码:9htw