【PostgreSQL的CLOG解析】

同样还是这张图,之前发过shared_buffer和os cache、wal buffer和work mem的文章,今天的主题是图中的clog,即 commit log,PostgreSQL10之前放在数据库目录的pg_clog下面。PostgreSQL10之后修更名为xact,数据目录变更为pg_xact下面,表现形式是一些物理文件。

PostgreSQL为什么要使用clog呢,众所周知,PostgreSQL有着独特的MVCC机制,由于其多版本的特性,
在进行可见性判断时,需要获取事务的状态,即元组中 t_xmin 和 t_xmax 的状态,需要clog来记录事务的状态,从而判断其可见性,内存里的访问远远快于磁盘读写,因此PostgreSQL的很多机制都是运行时候在内存,然后定期持久化到磁盘。因此clog也有一块内存区域便于高效访问,即clog buffers,它也属于共享内存的这部分,平时更新clog是内存中进行的,然后满足条件后会调用pg_fsync刷数据到磁盘上的clog文件,或者等待checkpoint刷数据。数据库启动时会从磁盘的pg_xact目录下读取事务状态加载到clog buffers,并且运行过程中,vacuum会定时将不再使用的clog文件清理。
关于clog buffers 的大小,可以在 src/backend/access/transam/clog.c里看到相关定义。
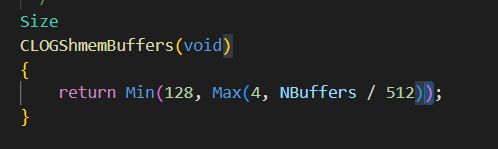
所以clog buffers 占用的页的个数是NBuffers / 512,最大为128个页,最小为4个页,这里的NBuffers 在之前wal buffer这篇文章已经说过,它和shared_buffers的关系,两者计算的字节数是一致的,感兴趣可以去看下 (PostgreSQL的wal_buffers - 墨天轮)。
因此,这里clog buffers的大小可以理解为 shared_buffers的1/512。
PostgreSQL中通过clog来存储事务的状态。所以,当在Postgresql中如果想要取消一个执行了很长时间的事务,基本上是瞬间完成的,而不是像Oracle中一样需要等到undo表空间中内容回滚完,因为PostgreSQL里只需要将事务的状态由IN_PROGRESS修改为ABORTED即可。
PG中,事务号最多占用32位,有三个是比较特殊的,在access/xlogdefs.h下可以看到,这里的BootstrapTransactionId是用于“bootstrap”操作的XID,FrozenTransactionId用于非常老的元组。FirstNormalTransactionId是第一个“正常”的事务id。

一、事务状态
在clog.h里定义了需要提交日志clog来记录事务的状态,从而判断其可见性,在PostgreSQL里总共有四种事务状态。分别是:IN_PROGRESS、COMMITED、ABORTED和SUB_COMMITED。例如事务正在运行中,那么它的状态就是IN_PROGRESS。全部是0是初始状态,SUB_COMMITTED状态表示已提交的子事务,其父事务尚未提交或中止。每个状态只需要两位(2 bit)就可以表示。

二、clog文件里事务id和状态信息的空间占用
对于上述提到的四种状态,可以用2 bit来表示。因此四个事务的状态就占用了8 bit 即一个字节。
在src/backend/access/transam/clog.c里一样可以找到关于这块空间占用的定义。

CLOG_BITS_PER_XACT:每个事务占用几个 bit(默认为2,因为4种状态用2bit就可以完全表示)
CLOG_XACTS_PER_BYTE :每个字节可以存几个事务的状态(默认为4,因为1bytes=8bit,1个事务状态需要占用2bit)
CLOG_XACTS_PER_PAGE:每个页可以存几个事务的状态(8KB*4=32K=2^15)
CLOG_XACT_BITMASK:位掩码
三、如何根据事务ID查看在clog日志里的事务的状态
在PostgreSQL中,事务id并不是在事务开始时就会被真正分配,它会先分配一个虚拟事务号,当有数据要发生变化时才会真正分配xid,而当事务提交或回滚时,其事务状态便会被写入clog中。比如你显式开启事务,什么都不做或者只做查询操作,commit之后,是不会消耗xid的。而当你有对数据的变更操作,则会消耗xid。
举个例子如下,当我们执行 select txid_current();的时候,他每次也要使用一个事务号,而当我们显式开启事务,然后什么都不做或者只执行select操作后,commit以后,事务号是不会增加的。我测试中增加了1是因为执行了select txid_current();的原因。而当显示事务里有对数据的变更操作,则下次执行select txid_current();的时候,事务号直接跳了两个,减去一个select txid_current();的,剩下那个增加的事务号则是我这个insert的事务占用的。
postgres=# select txid_current();
txid_current
--------------
2119
(1 row)
postgres=# select txid_current();
txid_current
--------------
2120
(1 row)
postgres=# begin;
BEGIN
postgres=*# select 1;
?column?
----------
1
(1 row)
postgres=*# commit;
COMMIT
postgres=# select txid_current();
txid_current
--------------
2121
(1 row)
postgres=# begin;
BEGIN
postgres=*# insert into t1 values(5);
INSERT 0 1
postgres=*# commit;
COMMIT
postgres=# select txid_current();
txid_current
--------------
2123
(1 row)
在src/backend/access/transam/clog.c里同同样也存在着事务ID存放位置的定义和计算方法,如下所示

这四个分别为
TransactionIdToPage (事务id对应在哪个CLOG页)
计算方法为:(xid) / (TransactionId) CLOG_XACTS_PER_PAGE,这个CLOG_XACTS_PER_PAGE是第二部分看到的每个页可以存几个事务的状态,它默认是2^15。因此。事务id/ (2^15)得到的就是事务id对应在哪个CLOG页,当然,是要取整的。从0号页开始。
TransactionIdToPgIndex(事务id对应在上面页中的偏移量)
计算方法为:(xid) % (TransactionId) CLOG_XACTS_PER_PAGE,即事务id%(2^15)得到的是在页里的偏移量。
TransactionIdToByte(事务id对应在上面页中第几个的字节)
计算方法为:TransactionIdToPgIndex(xid) / CLOG_XACTS_PER_BYTE,这里的TransactionIdToPgIndex(xid)是刚才计算的偏移量。而CLOG_XACTS_PER_BYTE是第二部分定义的每个字节可以存几个事务的状态,默认是4,所以事务在页里的偏移量/4得到的是事务id对应在页中第几个的字节。
TransactionIdToBIndex(事务id对应在上面字节中的哪个bit)
计算方法为:(xid) % (TransactionId) CLOG_XACTS_PER_BYTE。这里 CLOG_XACTS_PER_BYTE依旧是每个字节可以存几个事务的状态,默认为4,此处不用偏移量。直接用事务id%4来得到在一个byte里的哪个bit。(1byte=8bit)
这里做一个验证,
开启一个session

另开一个session,查看clog

计算四个值,我们该条记录是一个新的bytes里的
事务id对应在哪个CLOG页=2108/(2^15)=0
事务id对应在上面页中的偏移量=2108%(2^15)=2108
事务id对应在上面页中第几个的字节=2108/4=527
事务id对应在上面字节中的哪个bit=2108%4=0(表示这个事务在一bytes的第一组bits)


在commit后,原本的值应该变为01,但我们查看对应的clog文件部分是00,但是这可能并不代表事务在进程中,因为所有的状态初始值都是00,clog的数据还没有从内存写到磁盘。而且clog分配于共享内存的clog_buffer中,当申请新的CLOG PAGE时所有的clog_buffer都没有刷出脏页,才需要主动选择一个page并调用pg_fsync刷出对应的pg_clog到磁盘中,除此之外,checkpoint会将clog buffer刷到磁盘。因此我这里为了观察选择使用checkpoint。

此时clog buffer刷到了磁盘,可以看到此事务的状态是01,对照开头的状态,是已经提交的状态。

上边的例子是一个TransactionIdToByte计算为整数的,当TransactionIdToByte计算带有小数的时候,我们只看整数取整就可以了,例如如下的例子。


15从16进制转换成2进制为 0001 0101 ,而上边这个2110的事务,其计算的TransactionIdToBIndex(事务id对应在上面字节中的哪个bit)=2110%4=2,所以他在第3组bit上(取值是0为第一组),为01。因此在这个bytes里,我们的三个事务都是提交的状态。

等到一个byte的四组事务全部都是commited的时候,hexdump -C 0000 -s 527 -n 1查看到的值应该是55,例如下面这种大量的55,如果不是55则表示这一bytes里的四组事务,不是全部提交的,存在IN PROCESS、ABORTED或者SUB_COMMITTED的事务。
