海量数据存储Sharding-JDBC分库分表
文章目录
-
-
- 1.分库分表简介
-
- 1.1.MySQL架构演变
- 1.2.数据库性能优化思路
- 1.3.分库分表带来的优点
- 1.4.分库分表后的六大问题
- 2.常见分库分表介绍
-
- 2.1.垂直分表
- 2.2.垂直分库
- 2.3.水平分表
- 2.4.水平分库
- 2.5.数据库分库分表总结
- 3.水平分库分表常见策略
-
- 3.1.Range(范围)策略
- 3.2.Range策略延伸
- 3.3.Hash取模策略
- 4.分库分表常见中间件介绍
-
- 4.1.业界常见分库分表中间件
- 4.2.ShardingSphere简介
- 4.3.Sharding-Jdbc常见术语
- 4.4.Sharding-Jdbc常见分片算法
- 5.SpringBoot整合Sharding-Jdbc
-
- 5.1.Sharding-Jdbc项目创建
- 5.2.创建数据库表
- 5.3.Sharding-JDBC配置文件
- 5.4.分表代码测试
- 6.Snowflake雪花算法
-
- 6.1.业界常用ID解决方案
- 6.2.Snowflake原理
- 6.3.Snowflake生成ID的问题
- 7.广播表和绑定表配置
-
- 7.1.Sharding-JDBC广播表配置
- 7.2.水平分库分表配置
- 7.3.Sharding-JDBC绑定表配置
- 7.4.水平分库分表后查询和删除操作
- 8.ShardingJDBC多种分片策略
-
- 8.1.Sharding-Jdbc执行流程
- 8.2.精准分片算法《分表》
- 8.3.精准分片算法《分库分表》
- 8.4.范围分片算法
- 8.5.复合分片算法
- 8.6.Hint分片算法
- 8.7.多种分片策略总结
- 9.分库分表常见问题
-
- 9.1.分库分表已解决的三大问题
- 9.2.跨节点数据库复杂查询
- 9.3.分库分表分布式事务问题
- 9.4.分库分表后二次扩容问题
-
1.分库分表简介
1.1.MySQL架构演变
-
单机
- 请求量大查询慢
- 单机故障导致业务不可用
-
主从
- 数据库主从同步,从库可以水平扩展,满足更大读需求
- 但单服务器TPS,内存,IO都是有限的
-
双主
- 用户量级上来后,写请求越来越多
- 一个Master是不能解决问题的,添加多了个主节点进行写入,
- 多个主节点数据要保存一致性,写操作需要2个master之间同步更加复杂
-
分库和分表
1.2.数据库性能优化思路
这边有个数据库单表1千万数据,未来1年还会增长多500万,性能比较慢,说下你的优化思路?
- 不分库分表
- 软优化
- 数据库参数调优
- 分析慢查询SQL语句,分析执行计划,进行sql改写和程序改写
- 优先数据库索引结构
- 优化数据表结构优化
- 引入NOSQL和程序架构调整
- 硬优化
- 提升系统硬件(更快的IO、更多的内存):宽带、CPU、硬盘
- 软优化
- 分库分表
- 根据业务情况而定,选择合适的分库分表策略
- 先看只分表是否能满足业务的需求和未来的增长
- 数据库分表能够解决单表数据量很大时,数据查询的效率问题
- 无法给数据库的并发操作带来效率上的提高,分表的实质还是在一个数据库上进行的操作,受数据库IO性能的限制
- 如果单分表满足不了需求,在分库分表一起使用
- 结论
- 在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。
- 如果数据量极大,且业务持续增长快,在考虑分库分表方案。
1.3.分库分表带来的优点
1、解决数据库本身瓶颈
- 连接数:连接数过多时,就会出现“too many connections”的错误,访问量太大或者数据库设置的最大连接数太小的原因。
- MySQL默认的最大连接数为100,可以修改,而mysql服务允许的最大连接数为16384。
- 数据库分表可以解决单表海量数据的查询性能问题。
- 数据库分库可以解决单台数据库的并发访问压力问题。
2、解决系统本身IO、CPU瓶颈
-
磁盘读写IO瓶颈,热点数据太多,尽管使用了数据库本身缓存,但是依旧有大量IO,导致sql执行速度慢。
-
网络IO瓶颈,请求的数据太多,数据传输大,网络带宽不够,链路响应时间变长
-
CPU瓶颈,尤其在基础数据量大单机复杂SQL计算,SQL语句执行占用CPU使用率高,也有扫描行数大、锁冲突、锁等待等原因
- 可以通过 show processlist; 、show full processlist,发现 CPU 使用率比较高的SQL
- 常见的对于查询时间长,State 列值是 Sending data,Copying to tmp table,Copying to tmp table on disk,Sorting result,Using filesort 等都是可能有性能问题SQL,清楚相关影响问题的情况可以kill掉
- 也存在执行时间短,但是CPU占用率高的SQL,通过上面命令查询不到,这个时候最好通过执行计划分析explain进行分析
1.4.分库分表后的六大问题
- 问题一:跨界点数据库join关联查询
- 数据库切分前,多表关联查询,可以通过sql join进行实现。
- 分库分表后,数据可能分布在不同的节点上,sql join带来的问题就比较麻烦。
- 问题二:分库操作带来的分布式事务问题
- 操作内容同时分布在不同的库中,不可避免会带来跨库事务的问题,即分布式事务。
- 问题三:执行的SQL排序、翻页、函数计算问题
- 分库后,数据分布在不同的节点上,跨节点多库进行查询时,会出现limit分页、order by排序等问题。
- 而且当排序字段非分片字段时,更加复杂了,要在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序(也会带来更多的CPU/IO资源损耗)。
- 问题四:数据库全局主键重复问题
- 常见表的id是使用自增id进行实现的,分库分表后,由于表中数据同时存在不同数据库中,如果用自增id,则会出现冲突问题。
- 问题五:容量规划,分库分表后二次扩容问题
- 业务发展快,初次分库分表后,满足不了数据存储,导致需要多次扩容。
- 问题六:分库分表技术选型问题
- 市场分库分表中间件相对较多,框架各有各的优势与短板,应如何选择。
2.常见分库分表介绍
2.1.垂直分表
- 问题:商品表字段太多,每个字段访问频次不一样,浪费了IO资源,需要进行优化。
1、垂直分表介绍
- 也就是“大表拆小表”,基于列字段进行的。
- 拆分原则一般是表中的字段较多,将不常用的或者数据较大,长度较长的拆分到“扩展表 如text类型字段。
- 访问频次低、字段大的商品描述信息单独存放在一张表中,访问频次较高的商品基本信息单独放在一张表中。
2、垂直拆分原则
- 把不常用的字段单独放在一张表。
- 把text,blob等大字段拆分出来放在附表中。
- 业务经常组合查询的列放在一张表中。

2.2.垂直分库
- 问题:C端项目里面,单个数据库的CPU、内存长期处于90%+的利用率,数据库连接经常不够,需要进行优化。
1、垂直分库介绍
- 垂直分库针对的是一个系统中的不同业务进行拆分, 数据库的连接资源比较宝贵且单机处理能力也有限。
- 没拆分之前全部都是落到单一的库上的,单库处理能力成为瓶颈,还有磁盘空间,内存,tps等限制。
- 拆分之后,避免不同库竞争同一个物理机的CPU、内存、网络IO、磁盘,所以在高并发场景下,垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈。
- 垂直分库可以更好解决业务层面的耦合,业务清晰,且方便管理和维护。
- 一般从单体项目升级改造为微服务项目,就是垂直分库。

2.3.水平分表
- 问题:当一张表的数据达到几千万时,查询一次所花的时间长,需要进行优化,缩短查询时间。
1、水平分表简介
- 把一个表的数据分到一个数据库的多张表中,每个表只有这个表的部分数据。
- 核心是把一个大表,分割N个小表,每个表的结构是一样的,数据不一样,全部表的数据合起来就是全部数据。
- 针对数据量巨大的单张表(比如订单表),按照某种规则(RANGE,HASH取模等),切分到多张表里面去。
- 但是这些表还是在同一个库中,所以单数据库操作还是有IO瓶颈,主要是解决单表数据量过大的问题。
- 减少锁表时间,没分表前,如果是DDL(create/alter/add等)语句,当需要添加一列的时候mysql会锁表,期间所有的读写操作只能等待。

2.4.水平分库
- 问题:高并发的项目中,水平分表后依旧在单个库上面,1个数据库资源瓶颈 CPU/内存/带宽等限制导致响应慢,需要进行优化。
1、水平分库简介
- 把同个表的数据按照一定规则分到不同的数据库中,数据库在不同的服务器上。
- 水平分库是把不同表拆到不同数据库中,它是对数据行的拆分,不影响表结构。
- 每个库的结构都一样,但每个库的数据都不一样,没有交集,所有库的并集就是全量数据。
- 水平分库的粒度,比水平分表更大。
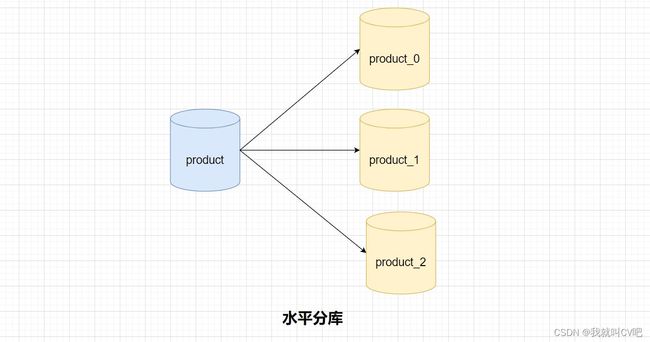
2.5.数据库分库分表总结
1、垂直角度(表结构不一样)
- 垂直分表: 将一个表字段拆分多个表,每个表存储部分字段。
- 好处: 避免IO时锁表的次数,分离热点字段和非热点字段,避免大字段IO导致性能下降。
- 原则:业务经常组合查询的字段一个表;不常用字段一个表;text、blob类型字段作为附属表。
- 垂直分库:根据业务将表分类,放到不同的数据库服务器上
- 好处:避免表之间竞争同个物理机的资源,比如CPU/内存/硬盘/网络IO
- 原则:根据业务相关性进行划分,领域模型,微服务划分一般就是垂直分库
2、水平角度(表结构一样)
- 水平分库:把同个表的数据按照一定规则分到不同的数据库中,数据库在不同的服务器上
- 好处: 多个数据库,降低了系统的IO和CPU压力
- 原则
- 选择合适的分片键和分片策略,和业务场景配合
- 避免数据热点和访问不均衡、避免二次扩容难度大
- 水平分表:同个数据库内,把一个表的数据按照一定规则拆分到多个表中,对数据进行拆分,不影响表结构
- 单个表的数据量少了,业务SQL执行效率高,降低了系统的IO和CPU压力
- 原则
- 选择合适的分片键和分片策略,和业务场景配合
- 避免数据热点和访问不均衡、避免二次扩容难度大
3.水平分库分表常见策略
3.1.Range(范围)策略
方案一:自增id,根据ID范围进行分表(左闭右开)
- 规则案例
- 1~1,000,000 是 table_1
- 1,000,000 ~2,000,000 是 table_2
- 2,000,000~3,000,000 是 table_3
- …更多
- 优点
- id是自增长,可以无限增长
- 扩容不用迁移数据,容易理解和维护
- 缺点
- 大部分读和写都访会问新的数据,有IO瓶颈,整体资源利用率低
- 数据倾斜严重,热点数据过于集中,部分节点有瓶颈
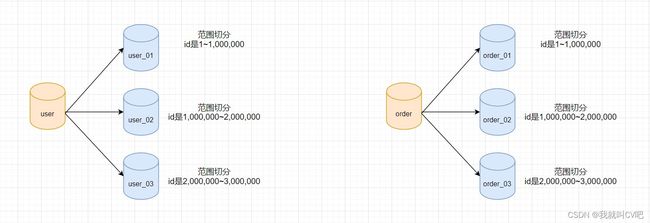
3.2.Range策略延伸
1、范围角度思考问题 (范围的话更多是水平分表)
- 数字
- 自增id范围
- 时间
- 年、月、日范围
- 比如按照月份生成 库或表 pay_log_2022_01、pay_log_2022_02
- 空间
- 地理位置:省份、区域(华东、华北、华南)
- 比如按照 省份 生成 库或表
2、基于Range范围分库分表业务场景
- 微博发送记录、微信消息记录、日志记录,id增长/时间分区都行
- 水平分表为主,水平分库则容易造成资源的浪费
- 网站签到等活动流水数据时间分区最好
- 水平分表为主,水平分库则容易造成资源的浪费
- 大区划分(一二线城市和五六线城市活跃度不一样,如果能避免热点问题,即可选择)
- saas业务水平分库(华东、华南、华北等)
3.3.Hash取模策略
方案二:hash取模(Hash分库分表是最普遍的方案)
案例规则
- 用户ID是整数型的,要分2库,每个库表数量4表,一共8张表
- 用户ID取模后,值是0到7的要平均分配到每张表
A库ID = userId % 库数量 2
表ID = userId / 库数量 2 % 表数量4
| userId | id % 2 (库-取余) | id /2 % 4 (表) |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 0 | 1 |
| 3 | 1 | 1 |
| 4 | 0 | 2 |
| 5 | 1 | 2 |
| 6 | 0 | 3 |
| 7 | 1 | 3 |
| 8 | 0 | 0 |
| 9 | 1 | 0 |
- 优点
- 保证数据较均匀的分散落在不同的库、表中,可以有效的避免热点数据集中问题。
- 缺点
- 扩容不是很方便,需要数据迁移。
4.分库分表常见中间件介绍
4.1.业界常见分库分表中间件
-
Cobar(已经被淘汰没使用了)
-
TDDL
- 淘宝根据自己的业务特点开发了TDDL(Taobao Distributed Data Layer)。
- 基于JDBC规范,没有server,以client-jar的形式存在,引入项目即可使用。
- 开源功能比较少,阿里内部使用为主。
-
Mycat
- Java语言编写的MySQL数据库网络协议的开源中间件,前身 Cobar。
- 遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理。
- 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成一个 MySQL 数据库。
- 和ShardingShere下的Sharding-Proxy作用类似,需要单独部署。

- ShardingSphere下的Sharding-JDBC
- Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈
- 它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar 3个独立产品组合
- Sharding-JDBC
- 基于jdbc驱动,不用额外的proxy,支持任意实现 JDBC 规范的数据库
- 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖
- 可理解为加强版的 JDBC 驱动,兼容 JDBC 和各类 ORM 框架
- Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈

- Mycat和ShardingJdbc区别
- 两者设计理念相同,主流程都是SQL解析->SQL路由->SQL改写->结果归并
- sharding-JDBC
- 基于jdbc驱动,不用额外的proxy,在本地应用层重写jdbc原生的方法,实现数据库分片形式
- 是基于JDBC接口的扩展,是以jar包的形式提供轻量级服务的,性能高。
- 代码有侵入性
- Mycat
- 是基于Proxy,它复写了MySQL协议,将Mycat Server伪装成一个MySQL数据库
- 客户端所有的jdbc请求都必须要先交给Mycat,再有Mycat转发到具体的真实服务器
- 缺点是效率偏低,中间包装了一层
- 代码无侵入性
4.2.ShardingSphere简介
1、什么是ShardingSphere
- 已于2020年4月16日成为Apache软件基金会的顶级项目。
- 是一套开源的分布式数据库解决方案组成的生态圈,定位为Database Plus。
- 它由JDBC、Proxy、和Sidecar这三款既能独立部署,又支持混合部署配合使用的产品组成。
2、三大构成
- ShardingSphere-Sidecar
- 定位为Kubernetes的云原生数据库代理,以Sidecar的形式代理所有对数据库的访问。
- 通过无中心、零侵入的方案提供与数据库的交互,即Database Mesh,又可称为数据库网格。
- ShardingSphere-JDBC
- 它使用客户端直连数据库,以jar包形式提供服务
- 无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架
- 适用于任何基于JDBC的ORM框架,如:JPA、Hibernate、Mybatis或直接使用JDBC
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库
- 采用无中心化架构,与应用程序共享资源,适用于 Java 开发的高性能的轻量级 OLTP 应用

- ShardingSphere-Proxy
- 数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL
- 它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据

| ShardingSphere-JDBC | ShardingSphere-Proxy | ShardingSphere-Sidecar | |
|---|---|---|---|
| 数据库 | 任意 | Mysql/PostgreSQL | Mysql/PostgreSQL |
| 连接消耗数 | 高 | 低 | 高 |
| 异构语言 | 仅Java | 任意 | 任意 |
| 性能 | 损耗低 | 损耗略高 | 损耗低 |
| 无中心化 | 是 | 否 | 是 |
| 静态入口 | 无 | 有 | 无 |
4.3.Sharding-Jdbc常见术语
- 数据节点Node
- 数据分片的最小单元,由数据源名称和数据表组成
- 比如:ds_0.product_order_0
- 真实表
- 在分片的数据库中真实存在的物理表
- 比如订单表 product_order_0、product_order_1、product_order_2
- 逻辑表
- 水平拆分的数据库(表)的相同逻辑和数据结构表的总称
- 比如订单表 product_order_0、product_order_1、product_order_2,逻辑表就是product_order
- 绑定表
- 指分片规则一致的主表和子表
- 比如product_order表和product_order_item表,均按照order_id分片,则此两张表互为绑定表关系
- 绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升
- 广播表
- 指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致
- 适用于数据量不大且需要与海量数据的表进行关联查询的场景
- 例如:字典表、配置表
4.4.Sharding-Jdbc常见分片算法
-
数据库表分片(水平库、表)
- 包含分片键和分片策略
-
分片键 (PartitionKey)
- 用于分片的数据库字段,是将数据库(表)水平拆分的关键字段
- 比如prouduct_order订单表,根据订单号 out_trade_no做哈希取模,则out_trade_no是分片键
- 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片
-
分片策略(先了解,后面有案例实战)
-
行表达式分片策略 InlineShardingStrategy(必备)
-
只支持【单分片键】使用Groovy的表达式,提供对SQL语句中的 =和IN 的分片操作支持
-
可以通过简单的配置使用,无需自定义分片算法,从而避免繁琐的Java代码开发
-
prouduct_order_$->{user_id % 8}` 表示订单表根据user_id模8,而分成8张表,表名称为`prouduct_order_0`到`prouduct_order_7
-
-
标准分片策略StandardShardingStrategy(需了解)
- 只支持【单分片键】,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法
- PreciseShardingAlgorithm 精准分片 是必选的,用于处理=和IN的分片
- RangeShardingAlgorithm 范围分配 是可选的,用于处理BETWEEN AND分片
- 如果不配置RangeShardingAlgorithm,如果SQL中用了BETWEEN AND语法,则将按照全库路由处理,性能下降
-
复合分片策略ComplexShardingStrategy(需了解)
- 支持【多分片键】,多分片键之间的关系复杂,由开发者自己实现,提供最大的灵活度
- 提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持
-
Hint分片策略HintShardingStrategy(需了解)
-
这种分片策略无需配置分片健,分片健值也不再从 SQL中解析,外部手动指定分片健或分片库,让 SQL在指定的分库、分表中执行
-
用于处理使用Hint行分片的场景,通过Hint而非SQL解析的方式分片的策略
-
Hint策略会绕过SQL解析的,对于这些比较复杂的需要分片的查询,Hint分片策略性能可能会更好
-
-
不分片策略 NoneShardingStrategy(需了解)
- 不分片的策略。
-
5.SpringBoot整合Sharding-Jdbc
5.1.Sharding-Jdbc项目创建
1、创建maven项目,pom.xml引入依赖
<properties>
<java.version>1.8java.version>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<spring.boot.version>2.5.5spring.boot.version>
<mybatisplus.boot.starter.version>3.4.0mybatisplus.boot.starter.version>
<lombok.version>1.18.16lombok.version>
<sharding-jdbc.version>4.1.1sharding-jdbc.version>
<junit.version>4.12junit.version>
<druid.version>1.1.16druid.version>
<skipTests>trueskipTests>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
<version>${spring.boot.version}version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<version>${spring.boot.version}version>
<scope>testscope>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>${mybatisplus.boot.starter.version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.27version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>${lombok.version}version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>${sharding-jdbc.version}version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>${junit.version}version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
<version>${spring.boot.version}version>
<configuration>
<fork>truefork>
<addResources>trueaddResources>
configuration>
plugin>
plugins>
build>
2、创建application.properties
spring.application.name=sharding-jdbc
server.port=8080
3、创建主启动类
@MapperScan("com.lixiang.mapper")
@EnableTransactionManagement
@SpringBootApplication
public class ShardingApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingApplication.class);
}
}
5.2.创建数据库表
- 分库分表需求
- 2库2表
- 数据库
- shop_order_0
- product_order_0
- product_order_1
- shop_order_1
- product_order_0
- product_order_1
- shop_order_0
- 脚本
CREATE TABLE `product_order_0` (
`id` bigint NOT NULL AUTO_INCREMENT,
`out_trade_no` varchar(64) DEFAULT NULL COMMENT '订单唯一标识',
`state` varchar(11) DEFAULT NULL COMMENT 'NEW 未支付订单,PAY已经支付订单,CANCEL超时取消订单',
`create_time` datetime DEFAULT NULL COMMENT '订单生成时间',
`pay_amount` decimal(16,2) DEFAULT NULL COMMENT '订单实际支付价格',
`nickname` varchar(64) DEFAULT NULL COMMENT '昵称',
`user_id` bigint DEFAULT NULL COMMENT '用户id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
- 实体bean
@Data
@EqualsAndHashCode(callSuper = false)
@TableName("product_order")
public class ProductOrderDO {
@TableId(value = "id", type = IdType.AUTO)
private Long id;
private String outTradeNo;
private String state;
private Date createTime;
private Double payAmount;
private String nickname;
private Long userId;
}
//Mapper类
public interface ProductOrderMapper extends BaseMapper<ProductOrderDO> {
}
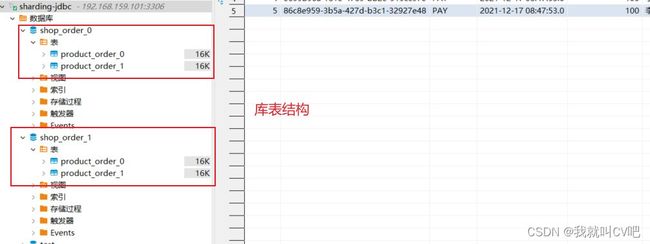
5.3.Sharding-JDBC配置文件
spring.application.name=sharding-jdbc
server.port=8080
spring.shardingsphere.props.sql.show=true
# 配置数据源
spring.shardingsphere.datasource.names=ds0,ds1
# 配置ds0库
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://192.168.159.101:3306/shop_order_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
# 配置ds1库
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://192.168.159.101:3306/shop_order_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
# 指定product_order表的数据分布情况,配置数据节点,行表达式标识符使用${...}或$->{...}
# 但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $->{...}
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds0.product_order_$->{0..1}
# 指定product_order表的分片策略,分片策略包括【分片键和分片算法】
# 使用user_id作为分片健
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.sharding-column=user_id
# 分片策略为user_id和2取余,进入到某一张product_order_?表
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.algorithm-expression=product_order_$->{user_id % 2}
5.4.分表代码测试
@RunWith(SpringRunner.class)
@SpringBootTest(classes = ShardingApplication.class)
@Slf4j
public class DBTest {
@Resource
private ProductOrderMapper productOrderMapper;
@Test
public void testSaveProductOrder(){
for(int i=0;i<10;i++){
ProductOrderDO productOrder = new ProductOrderDO();
productOrder.setCreateTime(new Date());
productOrder.setNickname("李祥:i="+i);
productOrder.setOutTradeNo(UUID.randomUUID().toString().substring(0,32));
productOrder.setPayAmount(100.00);
productOrder.setState("PAY");
productOrder.setUserId(Long.valueOf(i+""));
productOrderMapper.insert(productOrder);
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2YiIijUe-1668057977987)(images/4.2(3).jpg)]
- 控制台SQL
- Logic SQL : 逻辑SQL,没具体到哪个数据节点
- Actual SQL:真实SQL, 具体到每个数据节点的SQL
- 问题:主键重复问题,分库分表后,主键自增会造成不同分片上的数据表主键会重复。

6.Snowflake雪花算法
6.1.业界常用ID解决方案
(1)数据库自增ID
- 利用自增id,设置不同的自增步长,auto_increment_offset、auto_increment_increment
DB1:单数
//从1开始、每次加2
DB2:偶数
//从2开始,每次加2
- 缺点
- 依靠数据库系统的功能实现,但是未来扩容麻烦
- 主从切换时的不一致可能导致重复发号
- 性能瓶颈存在单台sql上
(2)UUID
- 性能非常高,没有网络消耗
- 缺点
- 无序的字符串,不具备趋势自增特性
- UUID太长,不易于存储,浪费存储空间,很多场景不适用
(3)Redis发号器
- 利用Redis的INCR和INCRBY来实现,原子操作,线程安全,性能比Mysql强劲
- 缺点
- 需要占用网络资源,增加系统复杂度
(4)Snowflake雪花算法
- twitter 开源的分布式 ID 生成算法,代码实现简单、不占用宽带、数据迁移不受影响
- 生成的 id 中包含有时间戳,所以生成的 id 按照时间递增,算法性能高
- 部署了多台服务器,需要保证系统时间一样,机器编号不一样
- 缺点
- 依赖系统时钟(多台服务器时间一定要一样)
6.2.Snowflake原理
雪花算法生成的数字,long类,所以就是8个byte,64bit
- 表示的值 -9223372036854775808(-2的63次方) ~ 9223372036854775807(2的63次方-1)
- 生成的唯一值用于数据库主键,不能是负数,所以值为0~9223372036854775807(2的63次方-1)

6.3.Snowflake生成ID的问题
- 全局唯一不能重复
(1)分布式部署就需要分配不同的workId, 如果workId相同,可能会导致生成的id相同
- 配置文件配置实操,在application.properties种,yml文件注意层级即可
spring.shardingsphere.sharding.tables.product_order.key-generator.props.worker.id=1
- 使用sharding-jdbc中的使用IP后几位来做workId, 但在某些情况下会出现生成重复ID的情况
- 解决办法时:在启动时给每个服务分配不同的workId, 引入redis/zk都行,缺点就是多了依赖
(2)分布式情况下,需要保证各个系统时间一致,如果服务器的时钟回拨,就会导致生成的 id 重复
- 配置雪花算法生成id
- 订单id使用MybatisPlus的配置,ProductOrder类配置
@TableId(value = "id", type = IdType.ASSIGN_ID)
默认实现类为DefaultIdentifierGenerator雪花算法
- 使用Sharding-Jdbc配置文件,注释DO类里面的id分配策略
#id生成策略
spring.shardingsphere.sharding.tables.product_order.key-generator.column=id
spring.shardingsphere.sharding.tables.product_order.key-generator.type=SNOWFLAKE
7.广播表和绑定表配置
7.1.Sharding-JDBC广播表配置
1、什么是广播表
- 指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致
- 适用于数据量不大且需要与海量数据的表进行关联查询的场景
- 例如:字典表、配置表
2、配置实战
(1)增加ad_config表
CREATE TABLE `ad_config` (
`id` bigint unsigned NOT NULL COMMENT '主键id',
`config_key` varchar(1024) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '配置key',
`config_value` varchar(1024) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '配置value',
`type` varchar(128) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '类型',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
(2)POJO类、Mapper
@Data
@EqualsAndHashCode(callSuper = false)
@TableName("ad_config")
public class AdConfigDO {
private Long id;
private String configKey;
private String configValue;
private String type;
}
public interface AdConfigMapper extends BaseMapper<AdConfigDO> {
}
(3)配置文件
# 配置广播表
spring.shardingsphere.sharding.broadcast-tables=ad_config
spring.shardingsphere.sharding.tables.ad_config.key-generator.column=id
spring.shardingsphere.sharding.tables.ad_config.key-generator.type=SNOWFLAKE
(4)测试代码
@Test
public void testSaveAdConfig(){
AdConfigDO adConfigDO = new AdConfigDO();
adConfigDO.setConfigKey("key");
adConfigDO.setConfigValue("value");
adConfigDO.setType("type");
adConfigMapper.insert(adConfigDO);
}

7.2.水平分库分表配置
1、分库分表配置
- 分库规则 根据 user_id 进行分库
- 分表规则 根据 product_order_id 订单号进行分表
spring.application.name=sharding-jdbc
server.port=8080
spring.shardingsphere.props.sql.show=true
# 配置数据源
spring.shardingsphere.datasource.names=ds0,ds1
# 配置ds0库
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://192.168.159.101:3306/shop_order_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
# 配置ds1库
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://192.168.159.101:3306/shop_order_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
# id生成策略(雪花算法)
spring.shardingsphere.sharding.tables.product_order.key-generator.column=id
spring.shardingsphere.sharding.tables.product_order.key-generator.type=SNOWFLAKE
# 指定product_order表的数据分布情况,配置数据节点,行表达式标识符使用${...}或$->{...}
# 但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $->{...}
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds$->{0..1}.product_order_$->{0..1}
spring.shardingsphere.sharding.tables.product_order.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
# 指定product_order表的分片策略,分片策略包括【分片键和分片算法】
# 使用id作为分片健
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.sharding-column=id
# 分片策略为id和2取余,进入到某一张product_order_?表
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.algorithm-expression=product_order_$->{id % 2}
# 配置广播表
spring.shardingsphere.sharding.broadcast-tables=ad_config
spring.shardingsphere.sharding.tables.ad_config.key-generator.column=id
spring.shardingsphere.sharding.tables.ad_config.key-generator.type=SNOWFLAKE
2、测试代码
@Test
public void testSaveProductOrder(){
Random random = new Random();
for(int i=0;i<10;i++){
ProductOrderDO productOrder = new ProductOrderDO();
productOrder.setCreateTime(new Date());
productOrder.setNickname("李祥:i="+i);
productOrder.setOutTradeNo(UUID.randomUUID().toString().substring(0,32));
productOrder.setPayAmount(100.00);
productOrder.setState("PAY");
productOrder.setUserId(Long.valueOf(random.nextInt(50)));
productOrderMapper.insert(productOrder);
}
}

7.3.Sharding-JDBC绑定表配置
1、什么是绑定表
- 指分片规则一致的主表和子表
- 比如product_order表和product_order_item表,均按照order_id分片,则此两张表互为绑定表关系
- 绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升

2、创建product_order_item表,一个库创建两个
CREATE TABLE `product_order_item_0` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`product_order_id` bigint DEFAULT NULL COMMENT '订单号',
`product_id` bigint DEFAULT NULL COMMENT '产品id',
`product_name` varchar(128) DEFAULT NULL COMMENT '商品名称',
`buy_num` int DEFAULT NULL COMMENT '购买数量',
`user_id` bigint DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;

3、编写实体ProductOrderItemDO,Mapper
@Data
@EqualsAndHashCode(callSuper = false)
@TableName("product_order_item")
public class ProductOrderItemDO {
private Long id;
private Long productOrderId;
private Long productId;
private String productName;
private Integer buyNum;
private Long userId;
}
public interface ProductOrderItemMapper extends BaseMapper<ProductOrderItemDO> {
@Select("select o.id from product_order o left join product_order_item i on o.id = i.product_order_id")
List<Map<String,Object>> listProductOrderDetail();
}
4、编写配置文件
spring.application.name=sharding-jdbc
server.port=8080
spring.shardingsphere.props.sql.show=true
# 配置数据源
spring.shardingsphere.datasource.names=ds0,ds1
# 配置ds0库
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://192.168.159.101:3306/shop_order_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
# 配置ds1库
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://192.168.159.101:3306/shop_order_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
# 配置默认分库规则
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression = ds$->{user_id % 2}
# 配置product_order表 id生成策略(雪花算法)
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds$->{0..1}.product_order_$->{0..1}
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.algorithm-expression=product_order_$->{id % 2}
spring.shardingsphere.sharding.tables.product_order.key-generator.column=id
spring.shardingsphere.sharding.tables.product_order.key-generator.type=SNOWFLAKE
# 配置广播表 id生成策略(雪花算法)
spring.shardingsphere.sharding.broadcast-tables=ad_config
spring.shardingsphere.sharding.tables.ad_config.key-generator.column=id
spring.shardingsphere.sharding.tables.ad_config.key-generator.type=SNOWFLAKE
# 配置product_order_item表 id生成策略(雪花算法)
spring.shardingsphere.sharding.tables.product_order_item.actual-data-nodes=ds$->{0..1}.product_order_item_$->{0..1}
spring.shardingsphere.sharding.tables.product_order_item.table-strategy.inline.sharding-column=product_order_id
spring.shardingsphere.sharding.tables.product_order_item.table-strategy.inline.algorithm-expression=product_order_item_$->{product_order_id % 2}
spring.shardingsphere.sharding.tables.product_order_item.key-generator.column=id
spring.shardingsphere.sharding.tables.product_order_item.key-generator.type=SNOWFLAKE
# 配置绑定表 让对应的主表为1的找副表为1的关联,注意不加这个,会产生笛卡尔积
spring.shardingsphere.sharding.binding-tables[0]=product_order,product_order_item
5、测试代码
@Test
public void testFindOrderItem(){
List<Map<String, Object>> list = productOrderItemMapper.listProductOrderDetail();
list.forEach(map -> System.out.println(map));
}
- 不加配置绑定表的结果(spring.shardingsphere.sharding.binding-tables[0]=product_order,product_order_item)

- 加配置绑定表的结果(spring.shardingsphere.sharding.binding-tables[0]=product_order,product_order_item)

7.4.水平分库分表后查询和删除操作
1、查询操作
- 有分片键(标准路由)
@Test
public void testSelectHavePartitionKey(){
//id为分片键
ProductOrderDO orderDO = productOrderMapper.selectOne(new QueryWrapper<ProductOrderDO>().eq("id", 678627813053431809L));
System.out.println(orderDO);
}

- 无分片键(全库表路由)
@Test
public void testSelectNoHavePartitionKey(){
//id为分片键
ProductOrderDO orderDO = productOrderMapper.selectOne(new QueryWrapper<ProductOrderDO>().eq("out_trade_no", "59c66f86-55f7-4b80-b803-13a76048"));
System.out.println(orderDO);
}

2、删除操作
- 有分片键(标准路由)
@Test
public void testDeleteHavePartitionKey(){
//id为分片键
productOrderMapper.delete(new QueryWrapper<ProductOrderDO>().eq("id", 678627813053431809L));
}

- 无分片键(全库表路由)
@Test
public void testDeleteNoHavePartitionKey(){
//id为分片键
productOrderMapper.delete(new QueryWrapper<ProductOrderDO>().eq("out_trade_no", "59c66f86-55f7-4b80-b803-13a76048"));
}

8.ShardingJDBC多种分片策略
8.1.Sharding-Jdbc执行流程
- 长:SQL解析 -> SQL优化 -> SQL路由 -> SQL改写 -> SQL执行 -> 结果归并 ->返回结果
- 短:解析->路由->改写->执行->结果归并

8.2.精准分片算法《分表》
StandardShardingStrategy(标准分片策略)
- 只支持【单分片键】,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法
- PreciseShardingAlgorithm 精准分片 是必选的,用于处理=和IN的分片
- RangeShardingAlgorithm 范围分片 是可选的,用于处理BETWEEN AND分片
- 如果不配置RangeShardingAlgorithm,如果SQL中用了BETWEEN AND语法,则将按照全库路由处理,性能下降
代码案例
@Component
public class CustomTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* @param dataSourceNames 数据源集合
* 在分库时值为所有分片库的集合 dataSourceNames
* 分表时为对应分片库种所有分片表的集合 tableNames
* @param preciseShardingValue 分片属性
* logicTableName:逻辑表名
* columnName:分片健(字段)
* value:从SQL中解析出的分片健的值
* @return
*/
@Override
public String doSharding(Collection<String> dataSourceNames, PreciseShardingValue<Long> preciseShardingValue) {
for (String dataSourceName : dataSourceNames) {
//从preciseShardingValue中拿出分片健,和表的个数取模,确定落在哪个表中
String value = preciseShardingValue.getValue() % dataSourceNames.size() + "";
if (dataSourceName.endsWith(value)){
return dataSourceName;
}
}
throw new IllegalArgumentException();
}
}
配置文件
spring.application.name=sharding-jdbc
server.port=8080
spring.shardingsphere.props.sql.show=true
# 配置数据源
spring.shardingsphere.datasource.names=ds0,ds1
# 配置ds0库
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://192.168.159.101:3306/shop_order_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
spring.shardingsphere.sharding.tables.product_order.key-generator.column=id
spring.shardingsphere.sharding.tables.product_order.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds0.product_order_$->{0..1}
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.sharding-column=id
#配置分片策略类的全路径包名
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.precise-algorithm-class-name=com.lixiang.strategy.CustomTablePreciseShardingAlgorithm
测试代码
@Test
public void testSaveProductOrder(){
Random random = new Random();
for(int i=0;i<10;i++){
ProductOrderDO productOrder = new ProductOrderDO();
productOrder.setCreateTime(new Date());
productOrder.setNickname("李祥:i="+i);
productOrder.setOutTradeNo(UUID.randomUUID().toString().substring(0,32));
productOrder.setPayAmount(100.00);
productOrder.setState("PAY");
productOrder.setUserId(Long.valueOf(random.nextInt(50)));
productOrderMapper.insert(productOrder);
}
}

8.3.精准分片算法《分库分表》
新增分库策略类
public class CustomDBPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* @param dataSourceNames 数据源集合
* 在分库时值为所有分片库的集合 dataSourceNames
* 分表时为对应分片库种所有分片表的集合 tableNames
* @param preciseShardingValue 分片属性
* logicTableName:逻辑表名
* columnName:分片健(字段)
* value:从SQL中解析出的分片健的值
* @return
*/
@Override
public String doSharding(Collection<String> dataSourceNames, PreciseShardingValue<Long> preciseShardingValue) {
for (String dataSourceName : dataSourceNames) {
//从preciseShardingValue中拿出分片健,和表的个数取模,确定落在哪个表中
String value = preciseShardingValue.getValue() % dataSourceNames.size() + "";
if (dataSourceName.endsWith(value)){
return dataSourceName;
}
}
throw new IllegalArgumentException();
}
}
配置文件
spring.application.name=sharding-jdbc
server.port=8080
spring.shardingsphere.props.sql.show=true
# 配置数据源
spring.shardingsphere.datasource.names=ds0,ds1
# 配置ds0库
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://192.168.159.101:3306/shop_order_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
# 配置ds1库
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://192.168.159.101:3306/shop_order_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
spring.shardingsphere.sharding.tables.product_order.key-generator.column=id
spring.shardingsphere.sharding.tables.product_order.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds$->{0..1}.product_order_$->{0..1}
#根据用户id分库
spring.shardingsphere.sharding.tables.product_order.database-strategy.standard.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.database-strategy.standard.precise-algorithm-class-name=com.lixiang.strategy.CustomDBPreciseShardingAlgorithm
#根据订单id分表
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.sharding-column=id
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.precise-algorithm-class-name=com.lixiang.strategy.CustomTablePreciseShardingAlgorithm
测试代码
@Test
public void testSaveProductOrder(){
Random random = new Random();
for(int i=0;i<10;i++){
ProductOrderDO productOrder = new ProductOrderDO();
productOrder.setCreateTime(new Date());
productOrder.setNickname("李祥:i="+i);
productOrder.setOutTradeNo(UUID.randomUUID().toString().substring(0,32));
productOrder.setPayAmount(100.00);
productOrder.setState("PAY");
productOrder.setUserId(Long.valueOf(random.nextInt(50)));
productOrderMapper.insert(productOrder);
}
}
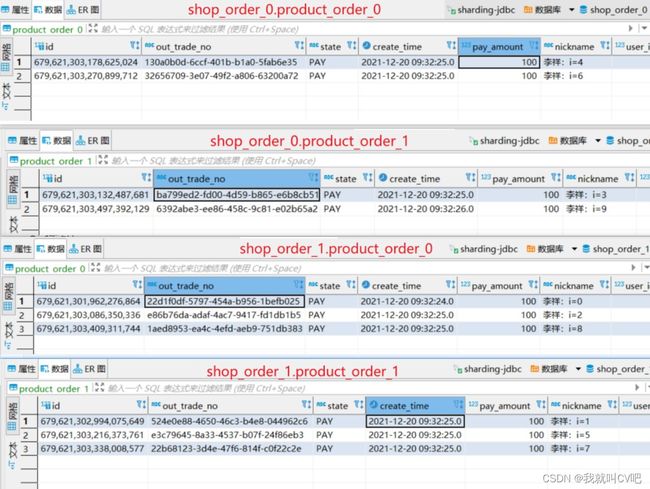
8.4.范围分片算法
RangeShardingAlgorithm范围分片
- 用于处理BETWEEN AND语法,没配置的话会报错Cannot find range sharding strategy in sharding rule。

- 主要是会根据 SQL中给出的分片健值范围值处理分库、分表逻辑。
代码示例
public class CustomRangeShardingAlgorithm implements RangeShardingAlgorithm<Long> {
/**
* @param dataSourceNames 数据源集合
* 分库时为所有的库的集合
* 分表时为所有的表的集合
* @param rangeShardingValue 范围分片对象
* logicTableName:逻辑表名
* columnName:分片键名
* valueRange:范围对象,包括lower和upper
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> dataSourceNames, RangeShardingValue<Long> rangeShardingValue) {
Set<String> result = new LinkedHashSet<>();
//between 起始值
Long lower = rangeShardingValue.getValueRange().lowerEndpoint();
//between 结束值
Long upper = rangeShardingValue.getValueRange().upperEndpoint();
//循环范围计算分库逻辑
for (long i = lower; i <= upper; i++) {
for (String dataSourceName : dataSourceNames) {
if(dataSourceName.endsWith(i % dataSourceNames.size() +"")){
result.add(dataSourceName);
}
}
}
return result;
}
}
配置文件
spring.shardingsphere.sharding.tables.product_order.key-generator.column=id
spring.shardingsphere.sharding.tables.product_order.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds$->{0..1}.product_order_$->{0..1}
#根据用户id分库
spring.shardingsphere.sharding.tables.product_order.database-strategy.standard.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.database-strategy.standard.precise-algorithm-class-name=com.lixiang.strategy.CustomPreciseShardingAlgorithm
#根据订单id分表
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.sharding-column=id
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.precise-algorithm-class-name=com.lixiang.strategy.CustomPreciseShardingAlgorithm
#根据订单id进行范围分表
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard..range-algorithm-class-name=com.lixiang.strategy.CustomRangeShardingAlgorithm
测试代码
@Test
public void testBetweenSelect(){
productOrderMapper.selectList(new QueryWrapper<ProductOrderDO>().between("id",1L,2L));
}

8.5.复合分片算法
复合分片算法ComplexShardingStrategy
-
提供对SQL语句中的=,in和between and的分片操作,支持【多分片健】
-
由于多分片键之间的关系复杂,Sharding-JDBC并未做过多的封装
-
而是直接将分片键值组合以及分片操作符交于算法接口,全部由应用开发者实现,提供最大的灵活度
代码案例
public class CustomComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
/**
*
* @param dataSourceNames 数据源集合
* @param complexKeysShardingValue 分片属性
* logicTableName:逻辑表名
* columnNameAndShardingValuesMap:多分片键集合 >>
* columnNameAndRangeValuesMap:范围策略,>>
*
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> dataSourceNames, ComplexKeysShardingValue<Long> complexKeysShardingValue) {
Collection<Long> orderIdValues = this.getShardingValue(complexKeysShardingValue,"id");
Collection<Long> userIdValues = this.getShardingValue(complexKeysShardingValue,"user_id");
List<String> shardingSuffix = new ArrayList<>();
//对两个分片键取模的方式
for (Long userId : userIdValues) {
for (Long orderId : orderIdValues) {
//拼接的效果,0_0,0_1,1_0,1_1,1去匹配product_order_0_0,product_order_0_1,product_order_1_0,product_order_1_1
String suffix = userId % 2 + "_" + orderId % 2;
for (String databaseName : dataSourceNames) {
if (databaseName.endsWith(suffix)) {
shardingSuffix.add(databaseName);
}
}
}
}
return null;
}
/**
* shardingValues:分片属性
* logicTableName:逻辑表
* columnNameAndShardingValuesMap 存储多个分片健 包括key-value
* value:分片value,66和99
* @param shardingValues
* @param key
* @return
*/
private Collection<Long> getShardingValue(ComplexKeysShardingValue<Long> shardingValues, String key) {
Collection<Long> valueSet = new ArrayList<>();
Map<String, Collection<Long>> columnNameAndShardingValuesMap = shardingValues.getColumnNameAndShardingValuesMap();
if(columnNameAndShardingValuesMap.containsKey(key)){
valueSet.addAll(columnNameAndShardingValuesMap.get(key));
}
return valueSet;
}
}
配置文件,记得注释其他策略,否则报错 Only allowed 0 or 1 sharding strategy configuration
#复合分片算法,order_id,user_id 同时作为分片健
spring.shardingsphere.sharding.tables.product_order.table-strategy.complex.sharding-columns=user_id,id
spring.shardingsphere.sharding.tables.product_order.table-strategy.complex.algorithm-class-name=com.lixiang.strategy.CustomComplexKeysShardingAlgorithm
测试代码
@Test
public void testComSelect(){
productOrderMapper.selectList(new QueryWrapper<ProductOrderDO>().eq("id",66L).eq("user_id",99L));
}

8.6.Hint分片算法
Hint分片策略HintShardingStrategy
- Hint分片策略无需配置文件进行配置分片健,分片健值也不再从SQL中解析,外部手动去指定分片健或分片库,让SQL在指定的分库、分表中执行。
- 通过Hint代码指定的方式而非SQL解析的方式分片的策略。
- Hint策略会绕过SQL解析,对于需要指定库表查询以及一些复杂的分片查询,Hint分片策略新跟那个可能会更好。
- 可以指定sql去某个库中某个表进行查询。
代码案例
//分库分表共用一个策略
public class CustomHintShardingAlgorithm implements HintShardingAlgorithm<Long> {
/**
*
* @param dataSourceNames 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param hintShardingValue 分片属性
* logicTableName:逻辑表
* columnName:分片健(字段),hint策略下为空,""
* value:不在从sql中解析分片的值,而是从
* hintManager.addDatabaseShardingValue("product_order",3L)和
* hintManager.addTableShardingValue("product_order", 8L)中拿值指定数据库,指定表
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> dataSourceNames, HintShardingValue<Long> hintShardingValue) {
Collection<String> result = new ArrayList<>();
for (String dataSourceName : dataSourceNames) {
for (Long value : hintShardingValue.getValues()) {
if(dataSourceName.endsWith(String.valueOf(value % dataSourceNames.size()))){
result.add(dataSourceName);
}
}
}
return result;
}
}
配置文件
spring.application.name=sharding-jdbc
server.port=8080
spring.shardingsphere.props.sql.show=true
# 配置数据源
spring.shardingsphere.datasource.names=ds0,ds1
# 配置ds0库
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://192.168.159.101:3306/shop_order_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
# 配置ds1库
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://192.168.159.101:3306/shop_order_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
spring.shardingsphere.sharding.tables.product_order.key-generator.column=id
spring.shardingsphere.sharding.tables.product_order.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds$->{0..1}.product_order_$->{0..1}
#Hint 分片算法
spring.shardingsphere.sharding.tables.product_order.table-strategy.hint.algorithm-class-name=com.lixiang.strategy.CustomHintShardingAlgorithm
spring.shardingsphere.sharding.tables.product_order.database-strategy.hint.algorithm-class-name=com.lixiang.strategy.CustomHintShardingAlgorithm
测试代码
/**
* HintManger可以配合AOP切面
*/
@Test
public void testHint(){
//清除掉历史的规则
HintManager.clear();
//Hint分片策略必须使用HintManager工具类
HintManager hintManager = HintManager.getInstance();
//设置库的分片健,value用于表分片取模
hintManager.addDatabaseShardingValue("product_order",3L);
//设置表的分片健,value用于表分片健
hintManager.addTableShardingValue("product_order",8L);
//如果在读写分离数据库中,Hint可以强制读主库(主从复制存在一定的延迟)
//hintManager.setMasterRouteOnly();
//对应的value只做查询,不做sql解析
productOrderMapper.selectList(new QueryWrapper<ProductOrderDO>().eq("id", 66L));
}

8.7.多种分片策略总结
- 自定义分片策略的优缺点
- 优点:可以根据分片策略代码里面自己拼接真实的数据库、真实的表,灵活控制分片规则。
- 缺点:增加了编码,不规范的sql容易造成全库表扫描,部分sql语法支持不友好。
- 行表达式分片策略InlineShardingStrategy
- 只支持【单分片键】使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持。
- 可以通过简单的配置使用,无需自定义分片算法,从而避免繁琐的Java代码开发
product_order_$->{user_id % 8}表示订单表根据user_id模8,而分成8张表,表名称为`prouduct_order_0`到`prouduct_order_7
- 标准分片策略StandardShardingStrategy
- 只支持【单分片健】,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。
- PreciseShardingAlgorithm精准分片 是必选的,用于处理=和IN的分片。
- RangeShardingAlgorithm范围分片 是可选的,用于处理BETWEEN AND分片。
- 如果不配置RangeShardingAlgorithm,如果SQL中用了BETWEEN AND语法,则将按照全库路由处理,性能下降。
- 复合分片策略ComplexShardingStrategy
- 支持【多分片键】,多分片键之间的关系复杂,由开发者自己实现,提供最大的灵活度。
- 提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。
- Hint分片策略HintShardingStrategy
- 这种分片策略无需配置分片健,分片健值也不再从 SQL中解析,外部手动指定分片健或分片库,让 SQL在指定的分库、分表中执行。
- 用于处理使用Hint行分片的场景,通过Hint而非SQL解析的方式分片的策略。
- Hint策略会绕过SQL解析的,对于这些比较复杂的需要分片的查询,Hint分片策略性能可能会更好。
9.分库分表常见问题
9.1.分库分表已解决的三大问题
问题一:执行SQL排序、翻页、函数计算问题
-
分库后,数据分布再不同的节点上, 跨节点多库进行查询时,会出现limit分页、order by排序等问题。
-
而且当排序字段非分片字段时,更加复杂了,要在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序(也会带来更多的CPU/IO资源损耗)。
-
解决方式:
- 业务上要设计合理,利用好PartitionKey,查询的数据分布同个数据节点上,避免 跨节点多库进行查询时。
- sharding-jdbc在结果合并层自动帮我们解决很多问题(流式归并和内存归并)。
问题二:数据库全局主键重复问题
- 常规表的id是使用自增id进行实现,分库分表后,由于表中数据同时存在不同数据库中,如果用自增id,则会出现冲突问题
- 解决方式:
- UUID
- 自研发号器 redis
- 雪花算法
问题三:分库分表技术选型问题
- 市场分库分表中间件相对较多,框架各有各的优势与短板,应该如何选择
- 解决方式
- 开源产品:主要是Mycat和ShardingJdbc区别,也是被面试官问比较多的
- 两者设计理念相同,主流程都是SQL解析–>SQL路由–>SQL改写–>结果归并
- sharding-jdbc(推荐)
- 基于jdbc驱动,不用额外的proxy,在本地应用层重写Jdbc原生的方法,实现数据库分片形式
- 是基于 JDBC 接口的扩展,是以 jar 包的形式提供轻量级服务的,性能高
- 代码有侵入性
- Mycat
- 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成一个 MySQL 数据库
- 客户端所有的jdbc请求都必须要先交给MyCat,再有MyCat转发到具体的真实服务器
- 缺点是效率偏低,中间包装了一层
- 代码无侵入性
- 开源产品:主要是Mycat和ShardingJdbc区别,也是被面试官问比较多的
9.2.跨节点数据库复杂查询
- 数据库切分前,多表关联查询,可以通过sql join进行实现
- 分库分表后,数据可能分布在不同的节点上,sql join带来的问题就比较麻烦
- 不同维度查看数据,利用的partitionKey是不一样的
- 解决方案
- 冗余字段
- 广播表
- NOSQL汇总
- 案例一
- 订单需要用户的基本信息,但是分布在不同库上
- 进行字段冗余,订单表冗余用户昵称、头像
- 案例二
- 订单表 的partionKey是user_id,用户查看自己的订单列表方便
- 但商家查看自己店铺的订单列表就麻烦,分布在不同数据节点
- 订单冗余存储在es上一份
- 业务架构流程

9.3.分库分表分布式事务问题
问题:分库操作带来的分布式事务问题
- 操作内容同时分布在不同库中,不可避免会带来跨库事务问题,即分布式事务
常见分布式事务解决方案
- 2PC 和 3PC
- 两阶段提交, 基于XA协议
- TCC
- Try、Confirm、Cancel
- 事务消息
- 最大努力通知型
分布式事务框架
- X-LCN:支持2PC、TCC等多种模式
- https://github.com/codingapi/tx-lcn
- 更新慢(个人感觉处于停滞状态)
- Seata:支持 AT、TCC、SAGA 和 XA 多种模式
- https://github.com/seata/seata
- 背靠阿里,专门团队推广
- 阿里云商业化产品GTS
- https://www.aliyun.com/aliware/txc
- RocketMq:自带事务消息解决分布式事务
- https://github.com/apache/rocketmq
- MQ+本地Task
- 定时任务
9.4.分库分表后二次扩容问题
问题:容量规划,分库分表后二次扩容问题
- 业务发展快,初次分库分表后,满足不了数据存储,导致需要多次扩容,数据迁移问题
- 取决是哪种分库分表规则
- Range范围
- 时间:不用考虑扩容迁移
- 区域:调整分片粒度,需要全量迁移
- Hash取模
- 业务最多的是hash取模分片,因扩分库分表涉及到rehash过程
- 分片数量建议可以成倍扩容策略,只需要【迁移部分数据】即可
- 旧节点的数据,有一半要迁移至一个新增节点中
- Range范围

解决方式
方式一:利用主从同步

- 新增两个数据库 A2、A3 作为从库,设置主从同步关系为:A0=>A2、A1=>A3,
- 开启主从数据同步,早期数据手工同步过去
- 发布新程序,某个时间点开始,利用MQ存储CUD操作
- 关闭数据库实例的主从同步关系
- 校验数据,消费原先MQ存储CUD操作,配置新分片规则和生效
- 数据校验和修复
- 依赖gmt_modified字段,所以常规数据表都需要加这个字段
- 由数据库自己维护值,根据业务场景,进行修复对应的数据
- 校验步骤
- 开始迁移时间假如是2022-01-01 00:00:00
- 查找 gmt_modified数据校验修复大于开始时间点,就是修改过的数据
- 各个节点的冗余数据进行删除
- 缺点
- 同步的很多数据到最后都需要被删除
- 一定要提前做,越晚做成本越高,因为扩容期间需要存储的数据更多
- 基本都离不开代码侵入,加锁等操作
- 优点
- 利用mysql自带的主从同步能力
- 方案简单,代码量相对少
方式二:停服务
- 对外发布公告,停机迁移
- 严格一致性要求:比如证券、银行部分数据等
- 优点:最方便、且安全
- 缺点
- 会造成服务不可用,影响业务
- 根据停机的时间段,数据校验人员有压力
户查看自己的订单列表方便 - 但商家查看自己店铺的订单列表就麻烦,分布在不同数据节点
- 订单冗余存储在es上一份
- 业务架构流程