从零开始 Spring Cloud 11:Elasticsearch II
从零开始 Spring Cloud 11:Elasticsearch II

图源:laiketui.com
在上篇文章中我们学习了 es 的基本功能,在本篇文章中会学习 es 的一些高级功能,比如:
- 聚合查询
- 自动补全
- 集群部署
数据聚合
类型
**聚合(aggregations)**可以让我们极其方便的实现对数据的统计、分析、运算。
聚合常见的有三类:
-
**桶(Bucket)**聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
**度量(Metric)**聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
-
**管道(pipeline)**聚合:其它聚合的结果为基础做聚合
**注意:**参加聚合的字段必须是keyword、日期、数值、布尔类型,也就是说不能对 text 进行聚合,因为 text 可以分词。
更多关于聚合的介绍可以观看这个视频。
DSL
桶聚合
下面是一个使用酒店品牌进行桶聚合的示例:
GET /hotel/_search
{
"size": 0, // 返回文档条数,进行聚合的时候可以指定为0,不返回文档
"aggs":{ // 聚合定义
"brandAgg":{ // 聚合名称
"terms": { // 聚合类型
"field": "brand", // 参与聚合的字段名
"size": 10 // 返回的聚合结果数量
}
}
}
}
返回的内容:
{
// ...
"aggregations" : {
"brandAgg" : { // 聚合名称
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 39,
"buckets" : [ // 聚合分组
{
"key" : "7天酒店",
"doc_count" : 30 // 聚合后的文档数目
},
{
"key" : "如家",
"doc_count" : 30
},
{
"key" : "皇冠假日",
"doc_count" : 17
},
// ...
]
}
}
}
聚合的结果默认按照doc_count倒序排列,可以通过指定排序规则改变这一点:
GET /hotel/_search
{
"size": 0,
"aggs":{
"brandAgg":{
"terms": {
"field": "brand",
"size": 10,
"order": {
"_count": "asc"
}
}
}
}
}
返回内容:
{
// ...
"aggregations" : {
"brandAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 130,
"buckets" : [
{
"key" : "万丽",
"doc_count" : 2
},
{
"key" : "丽笙",
"doc_count" : 2
},
{
"key" : "君悦",
"doc_count" : 4
},
// ...
]
}
}
}
默认情况下,es 需要对指定索引库的所有文档进行聚合,这就意味着较多的内存开销(需要将所有文档读入内存)。所以在使用聚合时添加一个查询条件以缩小聚合范围是个不错的优化手段。
比如对所有价格在 200 以下的酒店进行聚合:
GET /hotel/_search
{
"query": {
"range": {
"price": {
"lte": 200
}
}
},
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 10
}
}
}
}
度量聚合
使用度量聚合可以对文档内容进行数据分析,比如分析所有酒店评分情况:
GET /hotel/_search
{
"size": 0,
"aggs": {
"scoreAgg": {
"stats": {
"field": "score"
}
}
}
}
返回结果:
{
// ...
"aggregations" : {
"scoreAgg" : {
"count" : 201,
"min" : 35.0,
"max" : 49.0,
"avg" : 43.55223880597015,
"sum" : 8754.0
}
}
}
可以将桶聚合和度量聚合结合(嵌套)起来使用,比如统计每种品牌酒店的评分情况:
GET /hotel/_search
{
"size": 0,
"aggs": { // 外层聚合
"brandAgg": { // 聚合名称
"terms": { // 桶聚合
"field": "brand", // 按照品牌进行桶聚合
"size": 10,
"order": { // 对桶聚合结果排序
"scoreAgg.avg": "desc" // 对桶聚合按照度量聚合的平均分进行排序
}
},
"aggs": { // 内层聚合
"scoreAgg": { // 聚合名称
"stats": { // 度量聚合
"field": "score" // 对用户评分进行聚合
}
}
}
}
}
}
返回内容:
{
// ...
"aggregations" : {
"brandAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 111,
"buckets" : [
{
"key" : "万丽",
"doc_count" : 2,
"scoreAgg" : {
"count" : 2,
"min" : 46.0,
"max" : 47.0,
"avg" : 46.5,
"sum" : 93.0
}
},
// ...
{
"key" : "君悦",
"doc_count" : 4,
"scoreAgg" : {
"count" : 4,
"min" : 44.0,
"max" : 47.0,
"avg" : 45.5,
"sum" : 182.0
}
},
{
"key" : "希尔顿",
"doc_count" : 10,
"scoreAgg" : {
"count" : 10,
"min" : 37.0,
"max" : 48.0,
"avg" : 45.4,
"sum" : 454.0
}
}
]
}
}
}
RestAPI
下面展示如何用 RestAPI 实现聚合。
桶聚合
假设 DSL 语句如下:
GET /hotel/_search
{
"query": {
"range": {
"price": {
"lte": 200
}
}
},
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 10
}
}
}
}
RestAPI 实现调用:
@Test
@SneakyThrows
void testBrandAgg() {
// 准备查询语句
SearchRequest request = new SearchRequest("hotel");
request.source()
.query(QueryBuilders.rangeQuery("price")
.lte(200))
.size(0)
.aggregation(AggregationBuilders.terms("brandAgg")
.field("brand")
.size(20));
SearchResponse searchResponse = restHighLevelClient.search(request, RequestOptions.DEFAULT);
// 处理返回值
// 获取 aggregations 中的内容
Aggregations aggregations = searchResponse.getAggregations();
if (aggregations != null) {
// 获取查询时定义的聚合结果
// 返回的类型与查询时的聚合类型相关
Terms brandAgg = aggregations.get("brandAgg");
if (brandAgg != null) {
// 遍历聚合查询结果并打印
List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();
buckets.forEach(b -> {
System.out.println(String.format("key:%s, count: %d", b.getKeyAsString(), b.getDocCount()));
});
}
}
}
度量聚合
假设 DSL 语句:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 10,
"order": {
"scoreAgg.avg": "desc"
}
},
"aggs": {
"scoreAgg": {
"stats": {
"field": "score"
}
}
}
}
}
}
对应的 RestAPI 实现:
@Test
@SneakyThrows
void testScoreAgg() {
SearchRequest request = new SearchRequest("hotel");
TermsAggregationBuilder brandAgg = AggregationBuilders.terms("brandAgg");
request.source().size(0)
.aggregation(brandAgg);
StatsAggregationBuilder scoreAgg = AggregationBuilders.stats("scoreAgg");
brandAgg.field("brand")
.size(10)
.order(BucketOrder.aggregation("scoreAgg.avg", false))
.subAggregation(scoreAgg);
scoreAgg.field("score");
SearchResponse searchResponse = restHighLevelClient.search(request, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
if (aggregations != null) {
Terms brandTerms = aggregations.get("brandAgg");
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.println(String.format("brand: %s, count: %d", bucket.getKeyAsString(), bucket.getDocCount()));
Aggregations subAggregations = bucket.getAggregations();
if (subAggregations != null) {
Stats scoreStats = subAggregations.get("scoreAgg");
System.out.println(String.format("min: %.2f, max: %.2f, avg: %.2f, sum: %.2f",
scoreStats.getMin(),
scoreStats.getMax(),
scoreStats.getAvg(),
scoreStats.getSum()));
}
}
}
}
案例:动态筛选项
可以利用前边所学的知识,为酒店项目中的检索页面提供一个接口,动态查询并返回相关的聚合结果(城市、星级、品牌等)。
相关内容可以查看两个视频:
- 06-数据聚合-多条件聚合.mp4
- 07-数据聚合-带过滤条件的聚合.mp4
也可以从这里下载实现后的源码。
自动补全
下载 && 安装
要能够支持拼音的自动补全,需要安装一个 es 的拼音自动补全插件。
- 注意,插件版本要与 es 版本一致。
- 这里提供一个该插件 7.12.1 版本的百度云下载。
安装插件需要将插件解压到 es 挂载的插件目录下然后重启 es:
[icexmoon@192 ~]$ docker volume inspect es-plugins
[
{
"CreatedAt": "2023-08-03T21:12:21+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]
[icexmoon@192 ~]$ cd 下载
[icexmoon@192 下载]$ sudo mv ./py /var/lib/docker/volumes/es-plugins/_data
[icexmoon@192 下载]$ docker restart es
可以通过 devtool 执行以下 DSL 测试拼音分词器:
POST /_analyze
{
"text": ["如家酒店还不错"],
"analyzer": "pinyin"
}
返回内容:
{
"tokens" : [
{
"token" : "ru",
// ...
},
{
"token" : "rjjdhbc",
// ...
},
{
"token" : "jia",
// ...
},
{
"token" : "jiu",
// ...
},
{
"token" : "dian",
// ...
},
{
"token" : "hai",
// ...
},
{
"token" : "bu",
// ...
},
{
"token" : "cuo",
// ...
}
]
}
语句的分词结果是每个汉字对应的拼音以及每个汉字拼音首字母的结合。
自定义分词器
直接使用拼音分词器进行分词会存在一些问题:
- 分词后的结果没有中文
- 分词结果中不需要单个字对应的拼音
可以使用自定义分词器解决以上问题。
elasticsearch 中分词器(analyzer)的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
- tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
这里我们可以让 ik 分词器作为 tokenizer 切割词条,然后再用拼音分词器作为 tokenizer filter 添加词条对应的拼音。
具体实现:
PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word", // 作为 tokenizer 使用的分词器
"filter": "py" // 使用自定义过滤器 py 作为分词器的 tokenizer filter
}
},
"filter": { // 自定义 tokenizer filter
"py": { // 过滤器名称
"type": "pinyin", // 过滤器类型,这里使用 pinyin 分词器
"keep_full_pinyin": false, // 关闭单个汉字对应的拼音分词
"keep_joined_full_pinyin": true, // 开启完整词条对应的拼音分词
"keep_original": true, // 保留原始输入(汉字)
"limit_first_letter_length": 16,
"remove_duplicated_term": true, // 删除重复词条的索引结果
"none_chinese_pinyin_tokenize": false // 关闭对拼音进行分词
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer", // 文档创建时使用的分词器
"search_analyzer": "ik_smart" // 检索文档时使用的分词器
}
}
}
}
这里使用 pinyin 分词器作为 tokenizer filter。为了满足要求,这里还使用了 pinyin 分词器的一系列配置选项,作用见注释,完整的 pinyin 分词器配置项可以查看项目页面。
最后,在映射定义中,指定用自定义分词器 my_analyzer 作为文档索引时的分词器,而使用 ik_smart 作为检索文档时使用的分词器。这是因为如果检索的时候依然使用 my_analyzer 分词器对检索关键字进行分词,就会查询到一些汉字不匹配但拼音匹配的结果,这是不正确的。
可以用 DSL 进行测试:
POST /test/_analyze
{
"text": ["如家酒店还不错"],
"analyzer": "my_analyzer"
}
返回结果:
{
"tokens" : [
{
"token" : "如家",
// ...
},
{
"token" : "rujia",
// ...
},
{
"token" : "rj",
// ...
},
{
"token" : "酒店",
// ...
},
{
"token" : "jiudian",
// ...
},
{
"token" : "jd",
// ...
},
{
"token" : "还不",
// ...
},
{
"token" : "haibu",
// ...
},
{
"token" : "hb",
// ...
},
{
"token" : "不错",
// ...
},
{
"token" : "bucuo",
// ...
},
{
"token" : "bc",
// ...
}
]
}
自动补全查询
要使用 DSL 进行自动补全查询,所查询的文档属性必须是 completion 类型:
PUT /test
{
"mappings": {
"properties": {
"title": {
"type": "completion"
}
}
}
}
添加一些示例数据:
POST test/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test/_doc
{
"title": ["Nintendo", "switch"]
}
自动补全字段对应的数据是一个包含多个词条的数组,这是为了能更好的自动补全。比如第一个文档的title字段有Sony和WH-1000XM3两个词条,查询的时候关键字是s就可以用Sony自动补全,如果关键字是w就可以用WH-1000XM3自动补全。
自动补全查询的 DSL:
POST /test/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 检索关键字
"completion": {
"field": "title", // 用于自动补全的字段名
"skip_duplicates": true, // 是否跳过重复词条
"size": 10 // 返回结果条数
}
}
}
}
案例:酒店检索自动补全
重建索引库
先删除之前的索引库:
DELETE /hotel
添加新的索引库定义:
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"text_anlyzer": { // 用于切分并添加拼音的分词器
"tokenizer": "ik_max_word", // 用于切分的分词器
"filter": "py" // 过滤器
},
"completion_analyzer": { // 不切分只添加拼音的分词器
"tokenizer": "keyword", // 用于切分的分词器, keyword 为不切分
"filter": "py" // 过滤器
}
},
"filter": { // 自定义过滤器
"py": { // 过滤器名称
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer", // 对酒店名称分词后添加对应的拼音
"search_analyzer": "ik_smart", // 检索酒店名称时对关键字进行中文分词
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer", // 对 all 中文分词后添加对应拼音作为分词
"search_analyzer": "ik_smart" // 检索 all 时对关键字进行中文分词
},
"suggestion":{
"type": "completion", // 用于自动补全的字段
"analyzer": "completion_analyzer" // 自动补全字段已经是分词后的短语,只需要附加拼音
}
}
}
}
重新导入数据
之前示例中已经看到,对于completion类型的字段,添加文档时的 DSL 中是以一个 json 数组的形式传入的,所以 Java 代码中对应的属性应该是 List 类型:
@Data
@NoArgsConstructor
public class HotelDoc {
// ...
private List<String> suggestion = new ArrayList<>();
// ...
}
可以将需要自动补全的内容直接添加到这个属性,比如商圈和品牌:
public class HotelDoc {
// ...
public HotelDoc(Hotel hotel) {
// ...
this.suggestion.addAll(Arrays.asList(this.brand, this.business));
}
}
但商圈中是存在类似江湾、五角场商业区这样的数据,这样的数据只会被jw之类的自动补全,不会被wj之类的自动补全,所以类似的存在我们可能需要切分后作为自动补全候选:
// ...
@Data
@NoArgsConstructor
public class HotelDoc {
// ...
private List<String> suggestion = new ArrayList<>();
public HotelDoc(Hotel hotel) {
// ...
if (business.contains("、")) {
String[] strings = business.split("、");
this.suggestion.addAll(Arrays.asList(strings));
this.suggestion.add(this.brand);
} else {
this.suggestion.addAll(Arrays.asList(this.brand, this.business));
}
}
}
现在执行批量添加酒店的测试用例导入酒店数据。
DSL 测试
用 DSL 查看导入的自动补全字段:
GET /hotel/_search
{
"size": 20,
"query": {"match_all": {}}
}
返回结果:
{
// ...
"hits" : {
//...
"hits" : [
{
// ...
"_source" : {
"address" : "静安交通路40号",
"brand" : "7天酒店",
"business" : "四川北路商业区",
// ...
"suggestion" : [
"7天酒店",
"四川北路商业区"
]
}
},
{
// ...
"_source" : {
"address" : "广灵二路126号",
"brand" : "速8",
"business" : "四川北路商业区",
// ...
"suggestion" : [
"速8",
"四川北路商业区"
]
}
},
{
// ...
"_source" : {
"address" : "兰田路38号",
"brand" : "速8",
"business" : "长风公园地区",
// ...
"suggestion" : [
"速8",
"长风公园地区"
]
}
},
{
// ...
"_source" : {
"address" : "徐汇龙华西路315弄58号",
"brand" : "7天酒店",
"business" : "八万人体育场地区",
// ...
"suggestion" : [
"7天酒店",
"八万人体育场地区"
]
}
},
// ...
{
// ...
"_source" : {
"address" : "松江荣乐东路677号",
"brand" : "速8",
"business" : "佘山、松江大学城",
// ...
"suggestion" : [
"佘山",
"松江大学城",
"速8"
]
}
},
// ...
]
}
}
用 DSL 进行自动补全查询:
POST /hotel/_search
{
"suggest": {
"hote_suggestion": {
"text": "wj",
"completion": {
"field": "suggestion",
"skip_duplicates": true,
"size": 10
}
}
}
}
返回结果:
{
// ...
"suggest" : {
"hote_suggestion" : [
{
"text" : "wj",
"offset" : 0,
"length" : 2,
"options" : [
{
"text" : "五角场商业区",
// ...
},
{
"text" : "望京",
// ...
}
]
}
]
}
}
使用 RestAPI 实现自动补全
上面的 DSL 语句用 RestAPI 实现就是:
@Test
@SneakyThrows
void testHotelSuggestion() {
SearchRequest request = new SearchRequest("hotel");
request.source().suggest(new SuggestBuilder().addSuggestion("hotel_suggestion",
SuggestBuilders.completionSuggestion("suggestion")
.prefix("wj")
.skipDuplicates(true)
.size(10)));
SearchResponse searchResponse = restHighLevelClient.search(request, RequestOptions.DEFAULT);
Suggest suggest = searchResponse.getSuggest();
if (suggest != null) {
CompletionSuggestion hotelSuggestion = suggest.getSuggestion("hotel_suggestion");
if (hotelSuggestion != null) {
List<CompletionSuggestion.Entry.Option> options = hotelSuggestion.getOptions();
List<String> matchedWords = options.stream().map(o -> o.getText().string()).collect(Collectors.toList());
System.out.println(matchedWords);
}
}
}
查询关键字由CompletionSuggestionBuilder.prefix指定,这里是wj。
解析返回值是需要注意的是:Suggest.getSuggestion方法是一个泛型方法,返回的是Suggestion的一个子类。具体来说就是CompletionSuggestion、PhraseSuggestion或TermSuggestion三者之一。实际上使用哪个取决于查询时使用的自动补全类型,比如我们这里查询时使用的是CompletionSuggestion,所以解析结果是也应该使用CompletionSuggestion。
之后就是按照上边的方式创建一个接口提供给前端页面用于自动补全,比较简单,这里不再说明。具体可以查看这个视频。
数据同步
除了初始阶段需要用数据库中的数据对 es 进行初始化以外,项目运行过程中数据库中的数据必然会发生改变,此时就需要通过某种方式将数据的改变同步到 es 中,也就是要解决数据库和 es 的数据同步问题。
如果是单体项目,只需要调用 RestAPI 同步数据即可。但如果是微服务架构,且一个微服务负责管理数据库,另一个微服务负责查询 es,这个问题就会变得复杂。
这里讨论三种解决方案。
方案分析
同步调用

这种方式比较简单,就是在管理数据库的微服务(这里是 hotel-admin)中,修改数据后调用使用 es 的微服务(这里是 hotel-demo)提供的索引库更新接口,然后由后者调用 RestAPI 完成 es 的数据更新。
异步调用
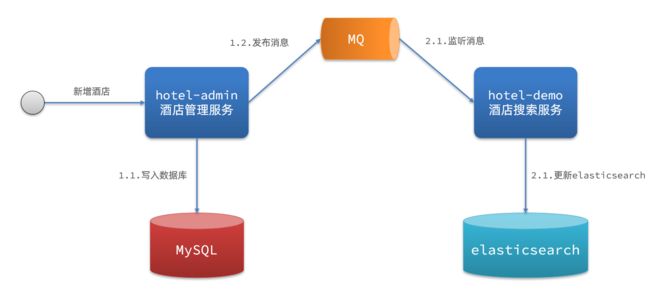
这个方案使用了 MQ 作为中间件,hotel-admin 写入数据后,会向 MQ 发送一个数据变更消息,hotel-demo 监听到该消息后,会自行更新 es。
监听 binlog
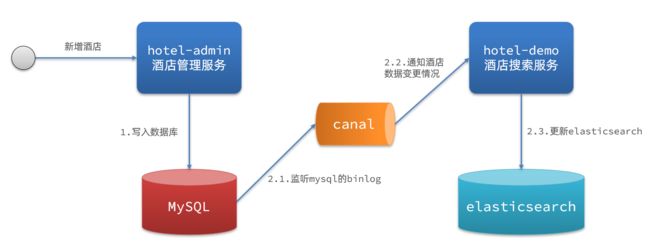
MySQL 可以产生一个 binlog 文件,可以用中间件 canal 监听 binlog 文件,如果该文件改变,就说明 MySQL 的数据发生变化,canal 就会自行通知 hotel-demo 有数据变更,hotel-demo 就会更新 es 中的数据。
对比
上面提到的三种方案各有优缺点:
方式一:同步调用
- 优点:实现简单,粗暴
- 缺点:业务耦合度高
方式二:异步通知
- 优点:低耦合,实现难度一般
- 缺点:依赖mq的可靠性
方式三:监听binlog
- 优点:完全解除服务间耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高
案例
准备框架代码
这里引入另一个示例项目 hotel-admin 来实现上边所说的数据同步。
先解压项目代码,并加载到 IDE 中。
修改数据库连接相关参数,并启动项目。
访问酒店管理页面(我这里是 http://localhost:8099/),可以进行数据库的增删改查。
创建 MQ 组件
数据同步需要使用一个交换机和两个队列:
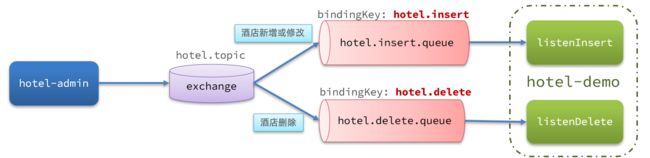
对于 es 来说,新增和修改的 DSL 是同样的,RestAPI 也是同样的,所以这里不需要对更新和新增做区分,都使用同一个队列即可。
在两个微服务中都添加 AMQP 依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-amqpartifactId>
dependency>
配置文件中添加连接信息:
spring:
rabbitmq:
host: 192.168.0.88 # RabbitMQ 服务端 ip
port: 5672 # 端口
virtual-host: / # 虚拟主机
username: itcast # 用户名
password: 123321 # 密码
在微服务 hotel-demo 中添加交换机和队列定义:
// ...
@Configuration
public class WebConfig {
// ...
@Bean
public TopicExchange topicExchange() {
return new TopicExchange(MQConstants.HOTEL_EXCHANGE_NAME, true, false);
}
@Bean
public Queue insertQueue() {
return new Queue(MQConstants.HOTEL_INSERT_QUEUE_NAME, true);
}
@Bean
public Queue deleteQueue() {
return new Queue(MQConstants.HOTEL_DELETE_QUEUE_NAME, true);
}
@Bean
public Binding insertQueueBinding() {
return BindingBuilder.bind(insertQueue())
.to(topicExchange())
.with(MQConstants.HOTEL_INSERT_ROUTINE_KEY);
}
@Bean
public Binding deleteQueueBinding() {
return BindingBuilder.bind(deleteQueue())
.to(topicExchange())
.with(MQConstants.HOTEL_DELETE_ROUTINE_KEY);
}
}
实现消息发送
在微服务 hotel-admin 的 Controller 中添加消息发送:
// ...
public class HotelController {
@Autowired
private IHotelService hotelService;
@Autowired
private RabbitTemplate rabbitTemplate;
// ...
@PostMapping
public void saveHotel(@RequestBody Hotel hotel){
hotelService.save(hotel);
rabbitTemplate.convertAndSend(MQConstants.HOTEL_EXCHANGE_NAME,
MQConstants.HOTEL_INSERT_ROUTINE_KEY,
hotel.getId());
}
@PutMapping()
public void updateById(@RequestBody Hotel hotel){
if (hotel.getId() == null) {
throw new InvalidParameterException("id不能为空");
}
hotelService.updateById(hotel);
rabbitTemplate.convertAndSend(MQConstants.HOTEL_EXCHANGE_NAME,
MQConstants.HOTEL_INSERT_ROUTINE_KEY,
hotel.getId());
}
@DeleteMapping("/{id}")
public void deleteById(@PathVariable("id") Long id) {
hotelService.removeById(id);
rabbitTemplate.convertAndSend(MQConstants.HOTEL_EXCHANGE_NAME,
MQConstants.HOTEL_DELETE_ROUTINE_KEY,
id);
}
}
实现消息接收
在微服务 hotel-demo 中添加一个负责监听消息的类:
@Component
public class HotelListener {
@Autowired
private IHotelService hotelService;
@RabbitListener(queues = MQConstants.HOTEL_INSERT_QUEUE_NAME)
public void listenHotelInsert(Long id){
hotelService.addHotel2ES(id);
}
@RabbitListener(queues = MQConstants.HOTEL_DELETE_QUEUE_NAME)
public void listenHotelDelete(Long id){
hotelService.deleteHotelFromES(id);
}
}
在 Service 层对应方法中实现具体的 RestAPI 调用:
@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {
// ...
@Override
@SneakyThrows
public void addHotel2ES(Long id) {
//从数据库读取酒店信息
Hotel hotel = this.getById(id);
if (hotel != null) {
HotelDoc hotelDoc = new HotelDoc(hotel);
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
restHighLevelClient.index(request, RequestOptions.DEFAULT);
}
}
@Override
@SneakyThrows
public void deleteHotelFromES(Long id) {
if (id != null) {
DeleteRequest request = new DeleteRequest("hotel").id(id.toString());
restHighLevelClient.delete(request, RequestOptions.DEFAULT);
}
}
}
这样就实现了对 es 的数据同步,可以通过相关的酒店管理页面进行验证。
ES 集群
单台 ES 部署的方式会存在一些问题:
- 单台 ES 能存储的数据存在上限(受内存大小限制)
- 出现故障时整个系统将不可用
可以通过 ES 集群部署的方式解决上边的问题。
关于 ES 的集群部署,有以下概念:
- 集群(cluster):一组拥有共同的 cluster name 的 节点。
- 节点(node) :集群中的一个 Elasticearch 实例
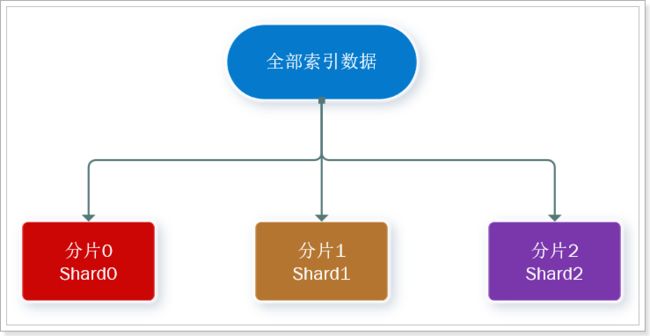
- 分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
通过将一个索引库拆分成多个分片并存储到不同的节点,可以解决单个 ES 所能存储的数据有限的问题。
对于单台 ES 出现问题会影响整个系统的问题,可以通过让不同的节点保留其它节点的分片副本的方式解决。
比如下面是其中一个可能的解决方案:
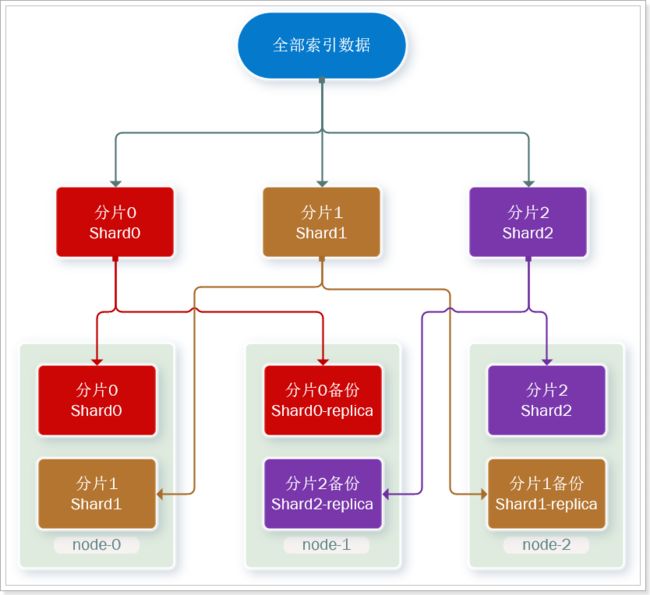
这有点像 Linux 的磁盘阵列中的 RAID 5,其本质的理念上是一致的:在保证一定读写性能的前提下提升数据恢复的冗余。
搭建 ES 集群
部署
这里使用 docker-compose 部署 es 集群的方式,docker-compose.yml文件定义如下:
version: '2.2'
services:
es01: # 服务名称
image: elasticsearch:7.12.1 # 使用的镜像
container_name: es01 # 容器名称
environment: # 环境变量
- node.name=es01 # es 节点名称,用于集群部署配置中的互相引用
- cluster.name=es-docker-cluster # 集群名称,同一个名称下的节点会被部署为一个集群
- discovery.seed_hosts=es02,es03 # 集群中的其它节点的主机名。一般使用ip,这里在同一个 docker 网络,所以可以使用容器名
- cluster.initial_master_nodes=es01,es02,es03 # 初始主节点候选
- "ES_JAVA_OPTS=-Xms512m -Xmx512m" # java 相关设置
volumes:
- data01:/usr/share/elasticsearch/data # 数据卷挂载
ports:
- 9200:9200 # 端口映射
networks:
- elastic # 所属 docker 网络
es02:
image: elasticsearch:7.12.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data02:/usr/share/elasticsearch/data
ports:
- 9201:9200
networks:
- elastic
es03:
image: elasticsearch:7.12.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
ports:
- 9202:9200
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
启动 es 集群服务:
[icexmoon@192 es-cluster]$ docker-compose up -d
需要确保宿主机有 4G 以上内存,如果内存不够,可以停止其它不需要的 docker 容器:
[icexmoon@192 es-cluster]$ docker stop kibana es mq
如果启动后 es 服务会自动退出,观察日志会出现类似下面的错误信息:
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
可以通过修改 Linux 系统权限的方式解决:
[icexmoon@192 es-cluster]$ sudo vim /etc/sysctl.conf
添加以下内容:
vm.max_map_count=262144
执行以下命令让其生效:
sysctl -p
状态监控
之前介绍的 kibana 默认情况下只能查看一台 es 的状态信息,如果需要用 kibana 监控 es 集群,需要依赖 es 的 x-pack 功能,配置比较复杂。
这里使用 cerebro 监控集群状态。
这里提供一个百度云的安装包
解压后执行 bin 目录下的 cerebro.bat 批处理文件即可。
会自动打开 cmd 并运行程序:
[info] play.api.Play - Application started (Prod) (no global state)
[info] p.c.s.AkkaHttpServer - Listening for HTTP on /0:0:0:0:0:0:0:0:9000
上边的输出说明程序已经监听本地的 9000 端口,因此可以访问 localhost:9000。
打开的页面需要输入一个 es 节点地址,输入任意节点即可,比如http://192.168.0.88:9200。
创建索引库
就像之前说的,在 es 集群部署的情况下,创建索引库可以使用多个分片和备份分片。
可以通过 DSL 创建这样的索引库:
PUT /itcast
{
"settings": {
"number_of_shards": 3, // 分片数量
"number_of_replicas": 1 // 每个分片的副本数量
},
"mappings": {
"properties": {
// mapping映射定义 ...
}
}
}
也可以通过 cerebro 工具创建:
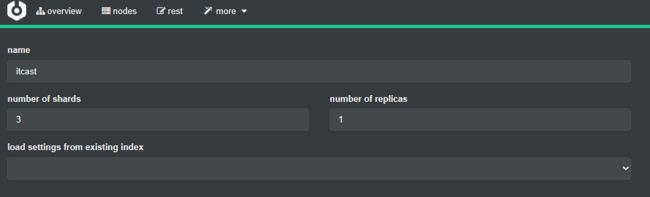
现在这个新建的索引库总共有3个正式分片以及3个备份分片:

图中的虚线就是备份分片。
脑裂问题
集群职责划分
elasticsearch中集群节点有不同的职责划分:
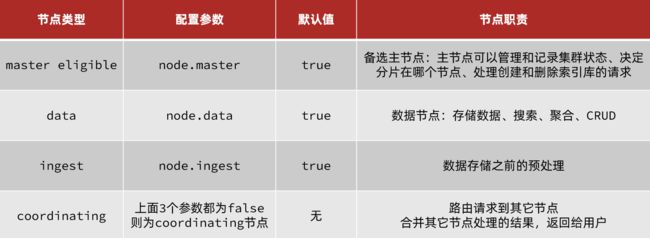
默认情况下,集群中的任何一个节点都同时具备上述四种角色。
但是真实的集群一定要将集群职责分离:
- master节点:对CPU要求高,但是内存要求低
- data节点:对CPU和内存要求都高
- coordinating节点:对网络带宽、CPU要求高
职责分离可以让我们根据不同节点的需求分配不同的硬件去部署。而且避免业务之间的互相干扰。
一个典型的es集群职责划分如图:

脑裂问题
脑裂是因为集群中的节点失联导致的。
例如一个集群中,主节点与其它节点失联:
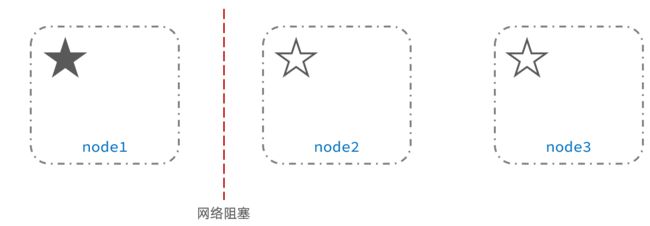
此时,node2和node3认为node1宕机,就会重新选主:
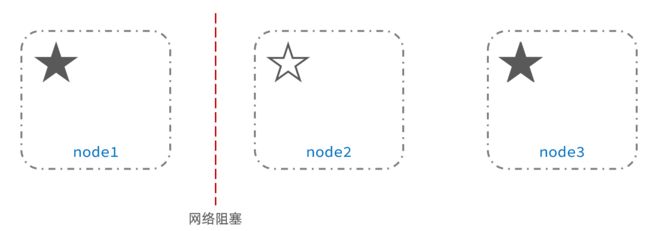
当node3当选后,集群继续对外提供服务,node2和node3自成集群,node1自成集群,两个集群数据不同步,出现数据差异。
当网络恢复后,因为集群中有两个master节点,集群状态的不一致,出现脑裂的情况:

解决脑裂的方案是,要求选票超过 ( eligible节点数量 + 1 )/ 2 才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题。
例如:3个节点形成的集群,选票必须超过 (3 + 1) / 2 ,也就是2票。node3得到node2和node3的选票,当选为主。node1只有自己1票,没有当选。集群中依然只有1个主节点,没有出现脑裂。
分布式存储
相比 es 单体部署,集群部署的 es 如何实现文档的新增和查询?
新增
前边已经说了,拆分成多个分片的索引库,保存数据时会保存存在不同的分片。
比如向之前创建的索引库 itcast(有3个分片) 存储文档:
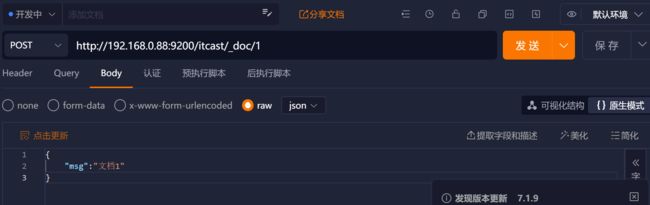
- 因为没有安装 kibana,所以这里用 API 调试工具 APIPost 执行 DSL,效果是相同的。
- 可以向任意一个节点发送请求,因为组成集群的3个节点都可以承担协调节点(coordinating node)职责。
用类似的方式存储 id 分别为 1、2、3 的三条数据。
可以查询这些文档所在的实际分片:
GET /itcast/_search
{
"explain": true, // 返回信息中包含所在分片信息
"query": {
"match_all": {}
}
}
返回结果:
{
// ...
"hits": {
// ...
"hits": [
{
"_shard": "[itcast][1]", // 文档位于 itcast 索引库的 1 号分片
"_node": "5wH00JaVQMmIBXHdtlFDBw",
"_index": "itcast",
"_type": "_doc",
"_id": "2",
"_score": 1,
"_source": {
"msg": "文档2"
},
// ...
},
{
"_shard": "[itcast][1]",
"_node": "5wH00JaVQMmIBXHdtlFDBw",
"_index": "itcast",
"_type": "_doc",
"_id": "3",
"_score": 1,
"_source": {
"msg": "文档3"
},
// ...
},
{
"_shard": "[itcast][2]",
"_node": "EyvF5IibQRGvEFfTMJEQ7g",
"_index": "itcast",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"msg": "文档1"
},
// ...
}
]
}
}
返回信息中的_shard中包含所在分片信息。可以看到,文档1在2号分片,文档2和3在1号分片。
实际上,es 会根据以下算法决定文档应当会保存在哪个分片:
shard = hash(_routing) % number_of_shards
公式中的_routing默认为文档 id,number_of_shards则是索引库的分片数目。所以上边的算法和索引库的分片数目是相关的,这也就意味着索引库创建后,索引库使用的分片数目不能改变,否则文档就无法正常保存和查询(按文档 id 查询)。
具体来说,新增文档的流程如下:
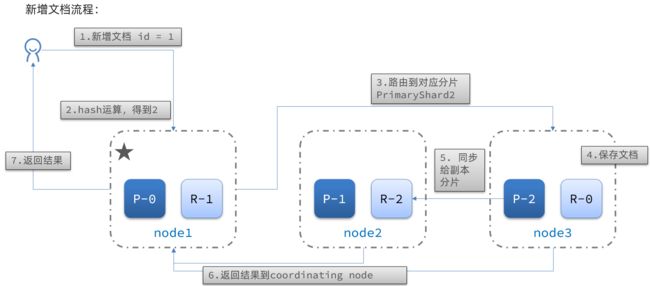
图中 P 是主分片(Primary Shard),R 是副本分片(Replica Shard),P-0 是0号主分片,R-0 是0号副本分片。
- 1)新增一个id=1的文档
- 2)对id做hash运算,假如得到的是2,则应该存储到shard-2
- 3)shard-2的主分片在node3节点,将数据路由到node3
- 4)保存文档
- 5)同步给shard-2的副本replica-2,在node2节点
- 6)返回结果给coordinating-node节点
查询
如果是按照文档 ID 查询,很简单,按照新增文档时使用的公式计算其所在分片,然后查找文档并返回即可。
但如果是按照条件查询,就很麻烦,因为无法在一开始就知道要查询的文档所在的分片。
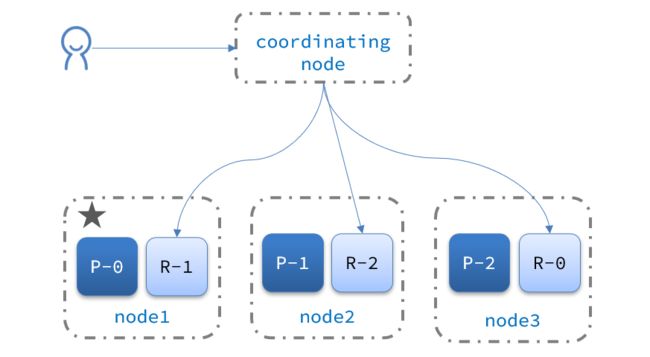
所以此时 es 需要按照两个阶段完成查询:
- scatter phase:分散阶段,coordinating node会把请求分发到每一个分片
- gather phase:聚集阶段,coordinating node汇总data node的搜索结果,并处理为最终结果集返回给用户
故障转移
当一个 es 集群中的主节点发生故障无法访问,集群中的候选节点将“选举”产生一个新的主节点。
当 es 集群中的数据节点发生故障,主节点将监控到这种故障,并检查分片是否完整(包含副本分片),如果缺少主分片或者副本分片,将进行数据迁移,以保证分片完整。
演示
我们可以实际演示这种故障转移。
目前我们的 es 集群包含3个节点:
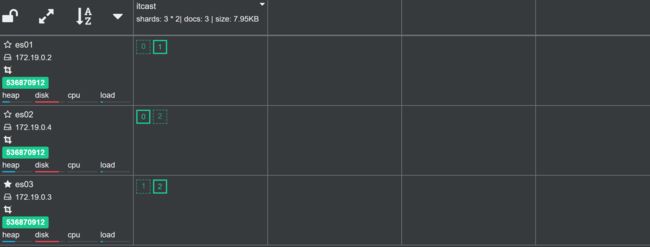
其中 es03 是主节点。
关闭该节点的 docker 容器以模拟主节点故障:
[icexmoon@192 ~]$ docker stop es03
可以通过监控工具观察到故障发生:

一段事件后 es 集群经过故障转移自动恢复正常:
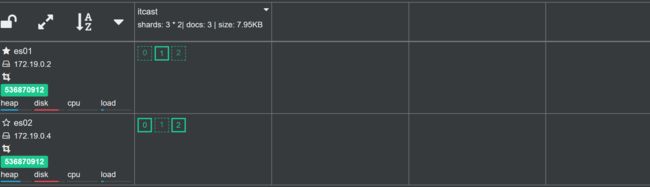
现在 es01 是主节点,且分片恢复成了3个主分片以及3个副本分片的规模。
如果通过 DSL 查询索引库的数据也会发现数据并没有丢失。
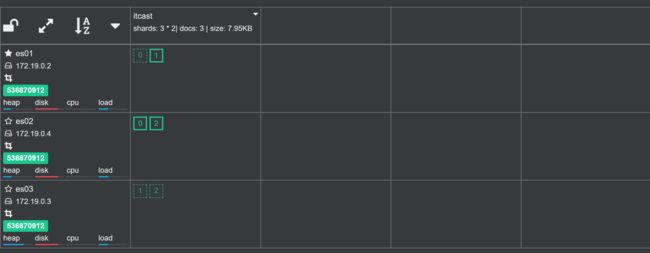
如果 es 节点恢复,集群依然可以自动恢复到之前的状态。比如:
[icexmoon@192 ~]$ docker start es03
除了主节点变成 es01 之外,分片依然延续之前的一个节点 2 个分片的结构。