clickhouse分片集群部署与错误记录
副本虽然能够提高数据的可用性,降低丢失风险,但是每台服务器实际上必须容纳全量数据,对数据的横向扩容没有解决。
要解决数据水平切分的问题,需要引入分片的概念。通过分片把一份完整的数据进行切分,不同的分片分布到不同的节点上,再通过 Distributed 表引擎把数据拼接起来一同使用。
Distributed 表引擎本身不存储数据,有点类似于 MyCat 之于 MySql,成为一种中间件,
通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据。
注意:ClickHouse 的集群是表级别的,实际企业中,大部分做了高可用,但是没有用分
片,避免降低查询性能以及操作集群的复杂性。
1. 集群及副本规划(2 个分片,只有第一个分片有副本)

| Hadoop102 |
hadoop103 |
hadoop104 |
| |
|
|
2. 配置步骤
1)在 hadoop102 的/etc/clickhouse-server/config.d 目录下创建 metrika-shard.xml
注:也可以不创建外部文件,直接在 config.xml 的
true
hadoop102
9000
default
000000
hadoop103
9000
default
000000
true
hadoop104
9000
default
000000
hadoop102
2181
hadoop103
2181
hadoop104
2181
01
rep_1_1
并且设置文件权限,chown clickhouse:clickhouse *

2)将 hadoop102 的 metrika-shard.xml 同步到 103 和 104 同地址下
xsync /etc/clickhouse-server/config.d/metrika-shard.xml
3)修改 103 和 104 中 metrika-shard.xml 宏的配置
(1)103
vim /etc/clickhouse-server/config.d/metrika-shard.xml

(2)104
vim /etc/clickhouse-server/config.d/metrika-shard.xml
4)在 hadoop102 上修改/etc/clickhouse-server/config.xml
5) 同步/etc/clickhouse-server/config.xml 到 103 和 104
xsync /etc/clickhouse-server/config.xml
6)重启三台服务器上的 ClickHouse,并查看集群
clickhouse restart
ps -ef |grep click

7)在 hadoop102 上执行建表语句
➢ 会自动同步到 hadoop103 和 hadoop104 上
➢ 集群名字要和配置文件中的一致
➢ 分片和副本名称从配置文件的宏定义中获取 gmall_cluster对应配置文件集群名称
create table st_order_mt on cluster gmall_cluster (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine
=ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id); 
可以到 hadoop103 和 hadoop104 上查看表是否创建成功

8)在 hadoop102 上创建 Distribute 分布式表
create table st_order_mt_all2 on cluster gmall_cluster
(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
)engine = Distributed(gmall_cluster,default, st_order_mt,hiveHash(sku_id));参数含义:
Distributed(集群名称,库名,本地表名,分片键)
分片键必须是整型数字,所以用 hiveHash 函数转换,也可以 rand()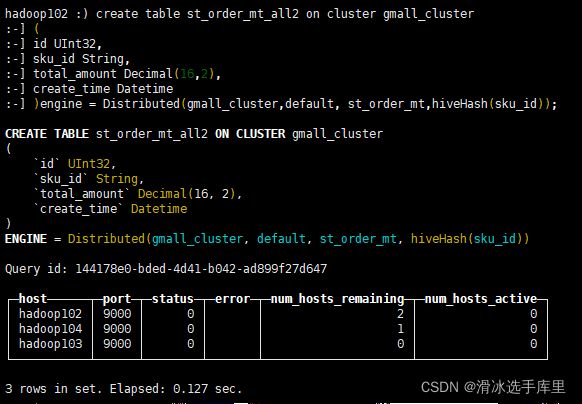
9)在 hadoop102 上插入测试数据
insert into st_order_mt_all2 values
(201,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(202,'sku_002',2000.00,'2020-06-01 12:00:00'),
(203,'sku_004',2500.00,'2020-06-01 12:00:00'),
(204,'sku_002',2000.00,'2020-06-01 12:00:00'),
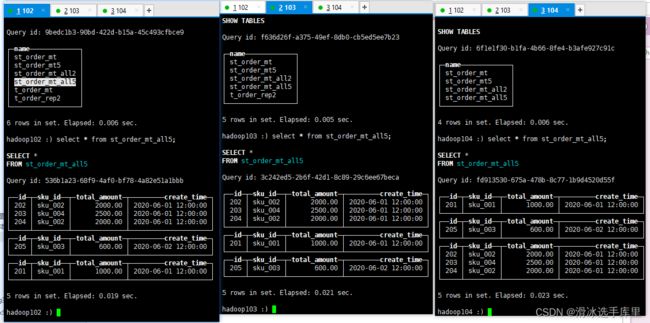
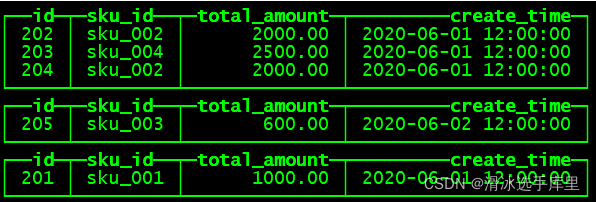
(205,'sku_003',600.00,'2020-06-02 12:00:00');10)通过查询分布式表和本地表观察输出结果
(1)分布式表
SELECT * FROM st_order_mt_all2;
(2)本地表
select * from st_order_mt;
(3)观察数据的分布
| st_order_mt_all |
|
| hadoop102: st_order_mt |
 |
| hadoop103: st_order_mt |
 |
| hadoop104: st_order_mt |
 |
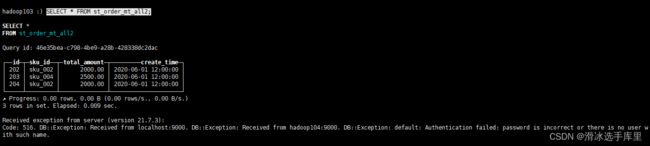
错误记录

去hadoop102查询只显示3条数据,报错信息显示104
Code: 516. DB::Exception: Received from localhost:9000. DB::Exception: Received from hadoop104:9000. DB::Exception: default: Authentication failed: password is incorrect or there is no user with such name.
猜测是机器互联时需要配置账号密码
| 配置 |
说明 |
| shard_1 |
自定义集群名称,全局唯一,是后续引用集群配置的唯一标识 |
| node |
用于定义节点,不包含副本 |
| host |
clickhouse 节点服务器地址 |
| port |
clickhouse 服务的tcp 端口 |
| weight |
分片权重,默认为 1 |
| user |
clickhouse 用户,默认为 default |
| password |
clickhouse 的用户密码,默认为空字符 |
| secure |
SSL 连接端口,默认 9440 |
| conpression |
是否要开启数据压缩功能,默认 true |
随后在上面的文件中配置号账号密码:重启clickhouse查询
再次查询,显示正常不报错