ES踩坑记录之UNASSIGNED分片无法恢复
问题背景
换节点
我们线上有一套ES集群,三台机器,共运行了6个节点。一直在线上跑了几个月也一直没出什么问题。然而好巧不巧,就在昨天,集群中的3号节点磁盘出现故障,导致机器直接瘫痪。本来大家觉得问题不大,ES不是有容灾吗,换个新节点上去不就能自动分配分片了。
unassigned
当我们信心满满换了个新节点上去之后,集群状态一直为red,我们发现一直存在180多个unassigned shards。
curl -XGET http://localhost:9200/_cluster/health
{
"cluster_name": "escluster",
"status": "red",
"timed_out": false,
"number_of_nodes": 6,
"number_of_data_nodes": 6,
"active_primary_shards": 498,
"active_shards": 767,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 185,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 80.5672268907563
}
curl -XGET http://localhost:9200/_cat/shards | grep UNASSIGNED

问题排查
分片恢复并发数❌
既然出现Unassigned shards,也就是说有一些分片未被分片。期初我们想当然的认为应该是节点新加入集群,分片还没有完成恢复。为了加速分片分配,我们调大了分片恢复并发数。
curl -XPUT http://localhost:9200/_cluster/settings -H 'Content-Type: application/json' -d'
{
"persistent": {
"cluster.routing.allocation.node_concurrent_recoveries": 10
}
}
'
然而并没有什么卵用,等了半天还是没什么变化。
allocation explain
随后我们使用allocation explain指令来查看分片的分配状态
curl -XGET http://localhost:9200/_cluster/allocation/explain?pretty
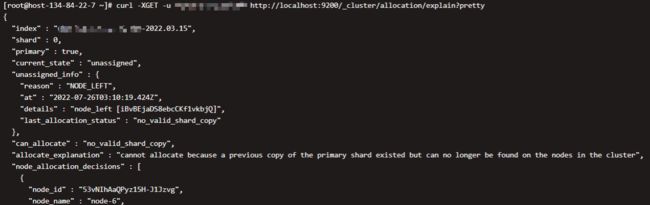
通过unassigned_info我们可以看到,NODE_LEFT,就是说节点无了。last_allocation_status说的更明确:no_valid_shard_copy,没有有效的分片副本。allocate_explanation也说了:cannot allocate because a previous copy of the primary shard existed but can no longer be found on the nodes in the cluster,大意就是集群节点上找不到能用的副本。
我们也很疑惑啊,为了让ES容灾,ES索引默认都有1个副本的呀,按照ES分片的策略,副本分片不会和主分片分发在同一台机器上,昨天宕机宕了1个节点,不应该主分配与副本分片都丢失吧。莫非…莫非这索引没副本???
抱着试一试的心态,我们查看了其中一个丢失的索引的信息
curl -XGET http://localhost:9200/XXX-2022.03.15/_settings
{
"XXX-2022.03.15": {
"settings": {
"index": {
"routing": {
"allocation": {
"require": {
"box_type": "hot"
}
}
},
"number_of_shards": "1",
"provided_name": "XXX-2022.03.15",
"creation_date": "1647273614797",
"number_of_replicas": "0",
"uuid": "Dy7G3ZaESYqLB_aFk8M3Cg",
"version": {
"created": "7080099"
}
}
}
}
}
不查不知道,一查吓一跳,这索引分片数为1,且没有副本…我副本呢???赶紧与研发确认了一下,由于机器磁盘比较小,为了节约存储,开发在写入索引时把就没留副本!!!
好家伙,我直接好家伙,合着我们还指望ES容灾呢,这还容个锤子灾。破案了,问题找到了,但数据也是找不回来了。
解决方案
数据是找不回来了,但集群也不能一直red啊,还有180多个unassigned的分片得处理呢。
reroute❌
通过在网上搜索相关的解决方案,得知可以通过重建所以路由是可以解决问题的。
curl -H 'Content-Type: application/json' \
-XPOST http://localhost:9200/_cluster/reroute?pretty -d '{
"commands" : [ {
"allocate_stale_primary" :
{
"index" : "XXX",
"shard" : 0,
"node" : "target-data-node-id",
"accept_data_loss" : true
}
}
]
}'
但我们由于数据节点已经丢失了,所以会收到如下报错:

这意味着什么呢,就是说除非丢失的节点重新加入集群,否则数据将消失。
allocate_empty_primary
数据是没法恢复了,所以我们只能将分片进行清空处理了。
curl -H 'Content-Type: application/json' \
-XPOST http://localhost:9200/_cluster/reroute?pretty -d '{
"commands" : [ {
"allocate_empty_primary" :
{
"index" : "XXX",
"shard" : 0,
"node" : "target-data-node-id",
"accept_data_loss" : true
}
}
]
}'
删除索引
还有一种更彻底的解决方案,就是把坏了的索引都删了就完事了,反正数据也没有了,没有数据的索引跟咸鱼有什么两样?眼不见为净完事了。
参考资料
- ElasticSearch Node Failure - Stackover Flow
- ES分片被删除后如何恢复 - CSDN
- ES集群中出现UNASSIGNED分片时的解决思路 - CSDN
- Elasticsearch 最佳实践系列之分片恢复并发故障 - 腾讯云开发者社区