【Linux】高级IO
目录
IO的基本概念
钓鱼五人组
五种IO模型
高级IO重要概念
同步通信 VS 异步通信
阻塞 VS 非阻塞
其他高级IO
阻塞IO
非阻塞IO
IO的基本概念
什么是IO?
I/O(input/output)也就是输入和输出,在著名的冯诺依曼体系结构当中,将数据从输入设备拷贝到内存就叫做输入,将数据从内存拷贝到输出设备就叫做输出。

- 对文件进行的读写操作本质就是一种IO,文件IO对应的外设就是磁盘。
- 对网络进行的读写操作本质也是一种IO,网络IO对应的外设就是网卡。
OS如何得知外设当中有数据可读取?
输入就是操作系统将数据从外设拷贝到内存的过程,操作系统一定要通过某种方法得知特定外设上是否有数据就绪。
- 并不是操作系统想要从外设读取数据时外设上就一定有数据。比如用户正在访问某台服务器,当用户的请求报文发出后就需要等待从网卡当中读取服务器发来的响应数据,但此时对方服务器可能还没有收到我们发出的请求报文,或是正在对我们的请求报文进行数据分析,也有可能服务器发来的响应数据还在网络中路由。
- 但操作系统不会主动检测外设上是否有数据就绪,这种做法一定会降低操作系统的工作效率,因为大部分情况下,外设当中都是没有数据的,因此操作系统所做的大部分检测工作其实都是徒劳的。
- 操作系统实际采用的是中断的方式来得知外设上是否有数据就绪的,当某个外设上面有数据就绪时,该外设就会向CPU当中的中断控制发送中断信号,中断控制器在根据产生的中断信号的优先级顺序发送给CPU。
- 每一个中断信号都有一个对应的中断处理程序,存储中断信号和中断处理程序映射关系的表叫做中断向量表,当CPU收到某个中断信号时就会自动停止正在运行的程序,然后根据中断向量表执行中断信号对应的中断处理程序,处理完毕后再返回原被暂停的程序继续运行。
需要注意的是,CPU不直接和外设打交道指的是在数据层面上,而外设其实是可以直接将某些控制信号发送给CPU的某些控制器的。
OS如何处理从网卡中读取到的数据包?
操作系统任何时刻都可能会收到大量的数据包,因此操作系统必须将这些数据包管理起来。所谓的管理就是“先描述,再组织”,在内核当中有一个结构叫做sk_buff,该结构就是用来管理和控制接收或发送数据包的信息的。
为了说明sk_buff的作用,下面给出一个简化版的sk_buff结构:

当操作系统从网卡当中读取到一个数据包后,会将该数据依次交给链路层、网络层、应用层进行解包和分用,最终将数据包中的数据交给了上层用户,那对应到这个sk_buff结构来说具体是如何进行数据包的解包和分用的呢?
- 当操作系统从网卡中读取到一个数据包后,就会定义出一个sk_buff结构,然后sk_buff当中的data指针指向这个读取到的数据包,并将定义出来的这个sk_buff结构与其他sk_buff结构以双链表的形式组织起来,此时操作系统对各个数据包的管理就变成了对双链表的增删改查等操作。
- 接下来我们需要将读取上来的数据包交给最底层的链路层处理,进行链路层的解包和分用,此时就是让sk_buff结构中的mac_header指针指向最初的数据包,然后向后读取链路层的报头,剩下的就是需要交给网络层处理的有效载荷了,此时便完成了链路层的解包。
- 这时链路层就需要将有效载荷向上交付给网络层进行解包和分用了,这里所说的向上交付只是形象的说法,实际向上交付并不是要将数据从链路层的缓冲区拷贝到网络层的缓冲区,我们只需要让sk_buff结构当中的network_header指针,指向数据包中链路层报头之后的数据即可,然后继续向后读取网络层的报头,便完成了网络层的解包。
- 紧接着就是传输层对数据进行处理,同样的道理,让sk_buff结构当中的transport_header指针,指向数据包中网络层报头之后的数据,然后继续向后读取传输层的报头,便完成了传输层的解包。
- 传输层解包后就可根据具体使用的传输层协议,对应将剩下的数据拷贝到TCP或UDP的接受缓冲区供用户读取即可。

发送数据时对数据进行封装也是同样的道理,就是依次在数据前面拷贝上对应的报头,最后再将数据发送出去(UDP)或拷贝到发送缓冲区(TCP)即可。也就是说,数据包在进行封装和解包的过程中,本质数据的存储位置是没有发生变化的,我们实际只是在用不同的指针对数据进行操作而已。
但内核中的sk_buff并不像上面那样简单:
- 一方面,为了保证高效的网络报文处理效率,这就要求sk_buff的结构也必须是高效的。
- 另一方面,sk_buff结构需要被内核协议中的各个协议共同使用,因此sk_buff必须能够兼容所有的网络协议。
因此sk_buff结构实际是非常复杂的,在我的云服务器中sk_buff结构的定义如下:
struct sk_buff {
#ifdef __GENKSYMS__
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
ktime_t tstamp;
#else
union {
struct {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
union {
ktime_t tstamp;
struct skb_mstamp skb_mstamp;
__RH_KABI_CHECK_SIZE_ALIGN(ktime_t a,
struct skb_mstamp b);
};
};
struct rb_node rbnode; /* used in netem, ip4 defrag, and tcp stack */
};
#endif
struct sock *sk;
struct net_device *dev;
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[48] __aligned(8);
unsigned long _skb_refdst;
#ifdef CONFIG_XFRM
struct sec_path *sp;
#endif
unsigned int len,
data_len;
__u16 mac_len,
hdr_len;
union {
__wsum csum;
struct {
__u16 csum_start;
__u16 csum_offset;
};
};
__u32 priority;
kmemcheck_bitfield_begin(flags1);
__u8 RH_KABI_RENAME(local_df, ignore_df) :1,
cloned : 1,
ip_summed : 2,
nohdr : 1,
nfctinfo : 3;
__u8 pkt_type : 3,
fclone : 2,
ipvs_property : 1,
peeked : 1,
nf_trace : 1;
kmemcheck_bitfield_end(flags1);
__be16 protocol;
void(*destructor)(struct sk_buff *skb);
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
struct nf_conntrack *nfct;
#endif
#if IS_ENABLED(CONFIG_BRIDGE_NETFILTER)
struct nf_bridge_info *nf_bridge;
#endif
/* fields enclosed in headers_start/headers_end are copied
* using a single memcpy() in __copy_skb_header()
*/
/* private: */
RH_KABI_EXTEND(__u32 headers_start[0])
/* public: */
int skb_iif;
RH_KABI_REPLACE(__u32 rxhash,
__u32 hash)
__be16 vlan_proto;
__u16 vlan_tci;
#ifdef CONFIG_NET_SCHED
__u16 tc_index; /* traffic control index */
#ifdef CONFIG_NET_CLS_ACT
__u16 tc_verd; /* traffic control verdict */
#endif
#endif
__u16 queue_mapping;
kmemcheck_bitfield_begin(flags2);
#ifdef CONFIG_IPV6_NDISC_NODETYPE
__u8 ndisc_nodetype : 2;
#endif
__u8 pfmemalloc : 1;
__u8 ooo_okay : 1;
__u8 RH_KABI_RENAME(l4_rxhash, l4_hash) :1;
__u8 wifi_acked_valid : 1;
__u8 wifi_acked : 1;
__u8 no_fcs : 1;
__u8 head_frag : 1;
/* Indicates the inner headers are valid in the skbuff. */
__u8 encapsulation : 1;
RH_KABI_EXTEND(__u8 encap_hdr_csum : 1)
RH_KABI_EXTEND(__u8 csum_valid : 1)
RH_KABI_EXTEND(__u8 csum_complete_sw : 1)
RH_KABI_EXTEND(__u8 xmit_more : 1)
RH_KABI_EXTEND(__u8 inner_protocol_type : 1)
RH_KABI_EXTEND(__u8 remcsum_offload : 1)
/* 0/2 bit hole (depending on ndisc_nodetype presence) */
kmemcheck_bitfield_end(flags2);
#if defined CONFIG_NET_DMA_RH_KABI || defined CONFIG_NET_RX_BUSY_POLL || defined CONFIG_XPS
union {
unsigned int napi_id;
RH_KABI_EXTEND(unsigned int sender_cpu)
RH_KABI_DEPRECATE(dma_cookie_t, dma_cookie)
};
#endif
#ifdef CONFIG_NETWORK_SECMARK
__u32 secmark;
#endif
union {
__u32 mark;
__u32 dropcount;
__u32 reserved_tailroom;
};
#ifdef __GENKSYMS__
__be16 inner_protocol;
#else
union {
__be16 inner_protocol;
__u8 inner_ipproto;
};
#endif
__u16 inner_transport_header;
__u16 inner_network_header;
__u16 inner_mac_header;
__u16 transport_header;
__u16 network_header;
__u16 mac_header;
RH_KABI_EXTEND(kmemcheck_bitfield_begin(flags3))
RH_KABI_EXTEND(__u8 csum_level : 2)
RH_KABI_EXTEND(__u8 rh_csum_pad : 1)
RH_KABI_EXTEND(__u8 rh_csum_bad_unused : 1) /* one bit hole */
RH_KABI_EXTEND(__u8 offload_fwd_mark : 1)
RH_KABI_EXTEND(__u8 sw_hash : 1)
RH_KABI_EXTEND(__u8 csum_not_inet : 1)
RH_KABI_EXTEND(__u8 dst_pending_confirm : 1)
RH_KABI_EXTEND(__u8 offload_mr_fwd_mark : 1)
/* 7 bit hole */
RH_KABI_EXTEND(kmemcheck_bitfield_end(flags3))
/* private: */
RH_KABI_EXTEND(__u32 headers_end[0])
/* public: */
/* RHEL SPECIFIC
*
* The following padding has been inserted before ABI freeze to
* allow extending the structure while preserve ABI. Feel free
* to replace reserved slots with required structure field
* additions of your backport, eventually moving the replaced slot
* before headers_end, if it need to be copied by __copy_skb_header()
*/
u32 rh_reserved1;
u32 rh_reserved2;
u32 rh_reserved3;
u32 rh_reserved4;
union {
unsigned int napi_id;
RH_KABI_EXTEND(unsigned int sender_cpu)
RH_KABI_DEPRECATE(dma_cookie_t, dma_cookie)
};
#endif
#ifdef CONFIG_NETWORK_SECMARK
__u32 secmark;
#endif
union {
__u32 mark;
__u32 dropcount;
__u32 reserved_tailroom;
};
#ifdef __GENKSYMS__
__be16 inner_protocol;
#else
kmemcheck_bitfield_begin(flags1);
__u8 RH_KABI_RENAME(local_df, ignore_df) :1,
cloned : 1,
ip_summed : 2,
nohdr : 1,
nfctinfo : 3;
__u8 pkt_type : 3,
fclone : 2,
ipvs_property : 1,
peeked : 1,
nf_trace : 1;
kmemcheck_bitfield_end(flags1);
__be16 protocol;
void(*destructor)(struct sk_buff *skb);
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
struct nf_conntrack *nfct;
#endif
#if IS_ENABLED(CONFIG_BRIDGE_NETFILTER)
struct nf_bridge_info *nf_bridge;
#endif
/* fields enclosed in headers_start/headers_end are copied
* using a single memcpy() in __copy_skb_header()
*/
/* private: */
/* private: */
RH_KABI_EXTEND(__u32 headers_start[0])
/* public: */
int skb_iif;
RH_KABI_REPLACE(__u32 rxhash,
__u32 hash)
__be16 vlan_proto;
__u16 vlan_tci;
#ifdef CONFIG_NET_SCHED
__u16 tc_index; /* traffic control index */
#ifdef CONFIG_NET_CLS_ACT
__u16 tc_verd; /* traffic control verdict */
#endif
#endif
__u16 queue_mapping;
kmemcheck_bitfield_begin(flags2);
#ifdef CONFIG_IPV6_NDISC_NODETYPE
__u8 ndisc_nodetype : 2;
#endif
__u8 pfmemalloc : 1;
__u8 ooo_okay : 1;
__u8 RH_KABI_RENAME(l4_rxhash, l4_hash) :1;
__u8 wifi_acked_valid : 1;
__u8 wifi_acked : 1;
__u8 no_fcs : 1;
__u8 head_frag : 1;
/* Indicates the inner headers are valid in the skbuff. */
__u8 encapsulation : 1;
RH_KABI_EXTEND(__u8 encap_hdr_csum : 1)
RH_KABI_EXTEND(__u8 csum_valid : 1)
RH_KABI_EXTEND(__u8 csum_valid : 1)
RH_KABI_EXTEND(__u8 csum_complete_sw : 1)
RH_KABI_EXTEND(__u8 xmit_more : 1)
RH_KABI_EXTEND(__u8 inner_protocol_type : 1)
RH_KABI_EXTEND(__u8 remcsum_offload : 1)
/* 0/2 bit hole (depending on ndisc_nodetype presence) */
kmemcheck_bitfield_end(flags2);
#if defined CONFIG_NET_DMA_RH_KABI || defined CONFIG_NET_RX_BUSY_POLL || defined CONFIG_XPS
union {
unsigned int napi_id;
RH_KABI_EXTEND(unsigned int sender_cpu)
RH_KABI_DEPRECATE(dma_cookie_t, dma_cookie)
};
#endif
#ifdef CONFIG_NETWORK_SECMARK
__u32 secmark;
#endif
union {
__u32 mark;
__u32 dropcount;
__u32 reserved_tailroom;
};
#ifdef __GENKSYMS__
__be16 inner_protocol;
#else
union {
__be16 inner_protocol;
__u8 inner_ipproto;
};
#endif
__u16 inner_transport_header;
__u16 inner_network_header;
__u16 inner_mac_header;
__u16 transport_header;
__u16 network_header;
__u16 mac_header;
RH_KABI_EXTEND(kmemcheck_bitfield_begin(flags3))
RH_KABI_EXTEND(__u8 csum_level : 2)
RH_KABI_EXTEND(__u8 rh_csum_pad : 1)
RH_KABI_EXTEND(__u8 rh_csum_bad_unused : 1) /* one bit hole */
RH_KABI_EXTEND(__u8 offload_fwd_mark : 1)
RH_KABI_EXTEND(__u8 sw_hash : 1)
RH_KABI_EXTEND(__u8 csum_not_inet : 1)
RH_KABI_EXTEND(__u8 dst_pending_confirm : 1)
RH_KABI_EXTEND(__u8 offload_mr_fwd_mark : 1)
/* 7 bit hole */
RH_KABI_EXTEND(kmemcheck_bitfield_end(flags3))
/* private: */
RH_KABI_EXTEND(__u32 headers_end[0])
/* public: */
/* RHEL SPECIFIC
*
* The following padding has been inserted before ABI freeze to
* allow extending the structure while preserve ABI. Feel free
* to replace reserved slots with required structure field
* additions of your backport, eventually moving the replaced slot
* before headers_end, if it need to be copied by __copy_skb_header()
*/
u32 rh_reserved1;
u32 rh_reserved2;
u32 rh_reserved3;
u32 rh_reserved4;
/* These elements must be at the end, see alloc_skb() for details. */
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head,
*data;
unsigned int truesize;
atomic_t users;
};
什么是高效的IO?
IO主要分为两步:
- 第一步是等,即等待IO条件就绪。
- 第二步是拷贝,也就是当IO条件就绪后将数据拷贝到内存或外设。
任何IO的过程,都包含“等”和“拷贝”这两个步骤,但在实际的应用场景中“等”消耗的时间往往比“拷贝”消耗的时间多,因此要让IO变得高效,最核心的方法就是尽量减少“等”的时间。
钓鱼五人组
IO的过程其实和钓鱼是非常类似的。
- 钓鱼的过程同样分为“等”和“拷贝”两个步骤,只不过这里的“等”指的是等鱼上钩,“拷贝”指的是当鱼上钩后将鱼从河里“拷贝”到我们的鱼桶当中。
- IO时“等”消耗的时间往往比“拷贝”消耗的时间多,钓鱼也恰好符合这个特点,钓鱼时我们大部分时间都在等鱼上钩,而当鱼上钩后只需要一瞬间就能将鱼“拷贝”上来。

在谈论高效的IO之前,我们先来看看什么样的钓鱼方式才是高效的。
下面给出五个人的钓鱼方式:
- 张三:拿了1个鱼竿,将鱼钩抛入水中后就死死的盯着浮漂,什么也不做,当有鱼上钩则挥动鱼竿将鱼勾上来。
- 李四:拿了1个鱼竿,将鱼钩抛入水中后就去做其他事情,然后定期观察浮漂,如果有鱼上钩则挥动鱼竿将鱼钓上来,否则继续去做其他事情。
- 王五:拿了1个鱼竿,将鱼抛入水中后将鱼竿顶部绑一个铃铛,然后去做其他事情,如果铃铛响了就挥动鱼竿将鱼钓上来,否则就根本不管鱼竿。
- 赵六:拿了100个鱼竿,将100个鱼竿抛入水中后就定期观察100个鱼竿的浮漂,如果某个鱼竿有鱼上钩则挥动对应的鱼竿将于钓上来。
- 田七:田七是一个有钱的老板,他给了自己的司机一个桶、一个电话、一个鱼竿,让司机去钓鱼,当鱼桶装满的时候再打电话告诉田七来拿鱼,而田七自己则开车去做其他事情去了。
张三、李四、王五的钓鱼效率是否一样?为什么?
- 首先他们他们的钓鱼方式都是一样的,都是先等鱼上钩,然后再将鱼钓上来。
- 其次,因为他们每个人都是拿的一根鱼竿,当河里有鱼来咬鱼钩时,这条鱼咬哪一个鱼钩的概率都是相等的。
因此张三、李四、王五他们三个人的钓鱼的效率是一样的,他们只是等鱼上钩的方式不同而已,张三是死等,李四是定期检测浮漂,而王五通过铃铛来判断是否有鱼上钩。
需要注意的是,这里问的是他们的钓鱼效率是否是一样的,而不是问他们整体谁做的事情最多,如果说整体做事情的量的话,那一定是王五做的最多,李四次之,张三最少。
张三、李四、王五它们三个人分别和赵六比较,谁的钓鱼效率更高?
赵六毫无疑问是这四个人当中钓鱼效率最高的,因为赵六同时在等多个鱼竿上有鱼上钩,因此在单位时间内,赵六的鱼竿有鱼上钩的概率是最大的。
- 为了方便计算,我们假设赵六拿了97个鱼竿,加上张三、李四、王五的鱼竿一共就有100个鱼竿。
- 当河里有鱼来咬鱼钩时,这条鱼咬张三、李四、王五的鱼钩的概率都是百分之一,而咬赵六的鱼钩的概率就是百分之九十七。
- 因此在单位时间内,赵六的鱼竿上有鱼的概率是张三、李四、王五的97倍。
而高效的钓鱼就是要减少单位时间内“等”的时间,增加“拷贝”的时间,所以说赵六的钓鱼效率是这四个人当中最高的。
赵六的钓鱼效率之所以高,是因为赵六一次等待多个鱼竿上的鱼上钩,此时就可以将“等”的时间进行重叠。
如何看待田七的这种钓鱼方式?
田七让自己的司机帮自己钓鱼,自己开车去做其他事情去了,此时这个司机具体怎么钓鱼已经不重要了,他可以模仿张三、李四、王五、赵六任何一个人的钓鱼方式进行钓鱼。
最重要的是田七本人并没有参与整个钓鱼的过程,他只是发起了钓鱼的任务,而真正钓鱼的是司机,田七在司机钓鱼期间可能在做任何其他事情,如果将钓鱼看作是一种IO的话,那田七的这种钓鱼方式就叫做异步IO。
而对于张三、李四、王五、赵六来说,他们都需要自己等鱼上钩,当鱼上钩后又需要自己把鱼从河里钓上来,对应到IO当中就是需要自己进行数据的拷贝,因此他们四个人的钓鱼方式都叫做同步IO。
五种IO模型
实际这五个人的钓鱼方式分别对应的就是五种IO模型。
- 张三这种死等的钓鱼方式对应就是阻塞IO。
- 李四这种定时检测是否有鱼上钩的方式就是非阻塞IO。
- 王五这种通过设置铃铛得知事件是否就绪的方式就是信号驱动IO。
- 赵六这种一次等待多个鱼竿上有鱼的钓鱼方式就是IO多路转接。
- 田七这种让别人帮自己钓鱼的钓鱼方式就是异步IO。
通过这里的钓鱼例子我们可以看到,阻塞IO、非阻塞IO和信号驱动IO本质上是不能提高IO的效率的,但非阻塞IO和信号驱动IO能提高整体做事的效率。
其中,这个钓鱼场景中的各个事物都能与IO当中的相关概念对应起来,比如这里钓鱼的河对应就是内核,这里的每一个人都是进程或线程,鱼竿对应的就是文件描述符或套接字,装鱼的桶对应的就是用户缓冲区。
五种IO模型
阻塞IO
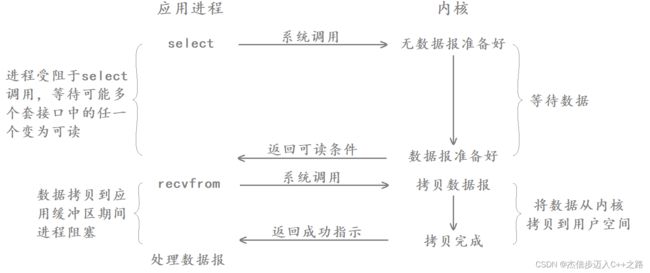
阻塞IO就是在内核将数据准备好之前,系统调用会一直等待。
图示如下:

阻塞IO是最常见的IO模型,所有的套接字,默认都是阻塞方式。
- 比如当调用recvfrom函数从某个套接字上读取数据时,可能底层数据还没有准备好,此时就需要等待数据就绪,当数据就绪后再将数据从内核拷贝到用户空间,最后recvfrom函数才会返回。
- 在recvfrom函数等待数据就绪期间,在用户看来该进程或线程就阻塞住了,本质就是操作系统将该进程或线程的状态设置为了某种非R状态,然后将其放入等待队列当中,当数据就绪后操作系统再将其从等待队列中唤醒,然后该进程或线程再将数据从内核拷贝到用户空间。
以阻塞方式进行IO操作的进程或线程,在“等”和“拷贝”期间都不会返回,在用户看来就像是阻塞住了,因此我们称之为阻塞IO。
非阻塞IO
非阻塞IO就是,如果内核还未将数据准备好,系统调用仍然会直接返回,并且返回EWOULDBLOCK错误码。
图示如下:
非阻塞IO往往需要程序员以循环的方式反复尝试读写文件描述符,这个过程称为轮询,这对CPU来说是较大的浪费,一般只有特定场景下才使用。
- 比如当调用recvfrom函数以非阻塞方式从某个套接字上读取数据时,如果底层数据还没有准备好,那么recvfrom函数立马返回错误放回,而不会让该进程或线程进行阻塞等待。
- 因为没有读取的数据,因此该进程或线程后续还需要继续调用recvfrom函数,检测底层数据是否就绪,如果没有就绪则继续错误返回,直到某次检测到底层数据就绪后,再将数据从内核拷贝到用户空间后进行成功返回。
- 每次调用recvfrom函数读取数据时,就算底层数据没有就绪,recvfrom函数也会立马返回,在用户看来该进程或线程就没有被阻塞住,因此我们称之为非阻塞IO。
阻塞IO和非阻塞IO的区别在于,阻塞IO当数据没有就绪时,后续检测数据是否就绪的工作是有操作系统发起的,而非阻塞IO当数据没有就绪时,后续检测数据是否就绪的工作是由用户发起的。
信号驱动IO
信号驱动IO就是当内核将数据准备好的时候,使用SIGIO信号通知应用程序进行IO操作。
图示如下:

当底层数据就绪的时候会向当前进程或线程递交SIGIO信号,因此可以通过signal或sigaction函数将SIGIO的信号处理程序自定义为需要进行的IO操作,当底层数据就绪时就会自动执行对应的IO操作。
- 比如我们需要调用recvfrom函数从某个套接字上读取数据,那么就可以将该操作定义为SIGIO的信号处理程序。
- 当底层数据就绪时,操作系统就会递交SIGIO信号,此时就会自动执行我们定义的信号处理程序,进程将数据从内核拷贝到用户空间。
信号的产生是异步的,但信号驱动IO时同步IO的一种 。
- 我们说信号的产生是异步的,因为信号在任何时刻都可能产生。
- 但信号驱动IO是同步IO的一种,因为当底层数据就绪时,当前进程或线程需要停下正在做的事情,转而进行数据的拷贝操作,因此当前进程或线程仍然需要参与IO过程
判断一个IO过程是同步的还是异步的,本质就是看当前进程或线程是否需要参与IO过程,如果要参与就是同步IO,否则就是异步IO。
IO多路转接
IO多路转接也叫做IO多路复用,能够同时等待多个文件描述符的就绪状态。
图示如下:
IO多路转接的思想:
- 因为IO过程分为“等”和“拷贝”两个步骤,因此我们使用的recvfrom等接口的底层 实际上都做了两件事,第一件事就是当数据不就绪时需要等,第二件事就是当数据就绪后需要进行拷贝。
- 虽然recvfrom等接口也有“等”的能力,但这些接口一次只能“等”一个文件描述符上的数据或空间就绪,这样IO效率太低了
- 因此系统为我们提供了三组接口,分别叫做select、poll和epoll,这些接口的核心工作就是“等”,我们可以将所有“等”的工作都交给这些多路转接接口。
- 因为这些多路转接接口是一次“等”多个文件描述符的,因此能够将“等”的时间进行重叠,当数据就绪后再调用对应的recvfrom等函数进行数据的拷贝,此时这些函数就能够直接进行拷贝,而不需要进行“等”操作了。
IO多路转接就像现实生活中的黄牛一样,只不过IO多路转接更像帮人排队的黄牛,因为多路转接接口实际并没有帮我们进行数据拷贝的操作。这些排队黄牛可以一次帮多个人排队,此时就将多个人排队的时间进行了重叠。
异步IO
异步IO就是由内核在数据拷贝完成时,通知应用程序。
图示如下:

- 进行异步IO需要调用一些异步IO的接口,异步IO接口调用后会立马返回,因为异步IO不需要你进行“等”和“拷贝”的操作,这两个动作都由操作系统来完成,你要做的只是发起IO。
- 当IO完成后操作系统会通知应用程序,因此进行异步IO的进程或线程并不参与IO的所有细节。
高级IO重要概念
同步通信 VS 异步通信
同步和异步关注的是消息通信机制。
- 所谓同步,就是在发出一个调用时,在没有得到结果之前,调用就不返回,但是一旦调用返回,就得到返回值了;换句话说,就是由调用者主动等待这个调用的结果。
- 异步则是相反,调用出发之后,这个调用就直接放回了,所以没有返回值结果;换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果;而是在调用发出后,被调用者通过状态、通知来通知调用者,或者通过调用函数处理这个调用。
为什么非阻塞IO在没有得到结果之前就返回了?
- IO时分为“等”和“拷贝”两步的,当调用recvfrom进行非阻塞IO时,如果数据没有就绪,那么调用会直接返回,此时调用返回时并没有完成一个完整的IO过程,即便调用反悔了那也是属于错误的返回。
- 因此该进程或线程后续需要继续调用recvfrom,轮询检测数据是否就绪,当数据就绪后再把数据从内核拷贝到用户空间,这才是一次完整的IO过程。
因此,在进行非阻塞IO时,在没有得到结果之前,虽然这个调用会返回,但后续还需要继续进行轮询检测,因此可以理解成调用还没有返回,而只有当某次轮询检测到数据就绪,并且完成数据拷贝后才认为该调用返回了。
同步通信 VS 同步与互斥
在多进程和多线程当中有同步与互斥的概念,但是这里的同步通信和进程或线程之间的同步是完全不相干的概念。
- 进程/线程同步指的是,在保证数据安全的前提,让进程/线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问题,讨论的是进程/线程间的一种工作关系。
- 而同步IO指的是进程/线程与操作系统之间的关系,讨论的是进程/线程是否需要主动参与IO过程
因此当看到“同步”这个词的时候,一定要先明确这个同步是同步通信的同步,还是同步与互斥的同步
阻塞 VS 非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息、返回值)时的状态。
- 阻塞调用是指调用结果返回之前,当前线程会被挂起,调用线程只有在得到结果之后才会返回。
- 非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
其他高级IO
非阻塞IO,记录锁,系统V流机制,I/O多路转接(也叫I/O多路复用),readv和writev函数以及存储映射IO(mmap),这些统称为高级IO。
阻塞IO
系统中大部分的接口都是阻塞式接口,比如我们可以用read函数从标准输入当中读取数据。
#include
#include
#include
int main()
{
char buffer[1024];
while (true){
ssize_t size = read(0, buffer, sizeof(buffer)-1);
if (size < 0){
std::cerr << "read error" << std::endl;
break;
}
buffer[size] = '\0';
std::cout << "echo# " << buffer << std::endl;
}
return 0;
}
程序运行后,如果我们不进行输入操作,此时该进程就会阻塞住,根本原因就是因为此时底层数据不就绪,因此read函数需要进行阻塞等待。

一旦我们进行了输入操作,此时read函数就会检测到底层数据就绪,然后立马将数据读取到从内核拷贝到我们传入的buffer数组当中,并且将读取到的数据输出到显示器上面,最后我们就看到了我们输入的字符串。

说明一下:
- C++当中的cin和C语言当中的scanf也可以读取从键盘输入的字符,但是cin和scanf会提供用户缓冲区,为了避免这些因素的干扰,因此这里选择使用read函数进行读取。
非阻塞IO
打开文件时默认都是以阻塞的方式打开的,如果要以非阻塞的方式打开某个文件,需要在使用open函数打开文件时携带O_NONBLOCK或O_NDELAY选项,此时就能够以非阻塞的方式打开文件。

这是在打开文件时设置非阻塞的方式,如果要将已经打开的某个文件或套接字设置为非阻塞,此时就需要用到fcntl函数。
fcntl函数
fcntl函数的函数原型如下:
int fcntl(int fd, int cmd, ... /* arg */);
参数说明:
- fd:已经打开的文件描述符。
- cmd:需要进行的操作。
- …:可变参数,传入的cmd值不同,后面追加的参数也不同。
fcntl函数常用的5种功能与其对应的cmd取值如下:
- 复制一个现有的描述符(cmd=F_DUPFD)。
- 获得/设置文件描述符标记(cmd=F_GETFD或F_SETFD)。
- 获得/设置文件状态标记(cmd=F_GETFL或F_SETFL)。
- 获得/设置异步I/O所有权(cmd=F_GETOWN或F_SETOWN)。
- 获得/设置记录锁(cmd=F_GETLK, F_SETLK或F_SETLKW)。
返回值说明:
- 如果函数调用成功,则返回值取决于具体进行的操作。
- 如果函数调用失败,则返回-1,同时错误码会被设置。
实现SetNonBlock函数
我们可以定义一个函数,该函数就用于将指定的文件描述符设置为非阻塞状态。
- 先调用fcntl函数获取该文件描述符对应的文件状态标记(这是一个位图),此时调用fcntl函数传入的cmd值为F_GETFL。
- 在获取到的文件状态标记上添加非阻塞标记O_NOBLOCK,再次调用fcntl函数对文件状态标记进行设置,此时调用fcntl函数时传入的cmd值为F_SETFL
代码如下:
bool SetNonBlock(int fd)
{
int fl=fcntl(fd,F_GETFL);
if(fl<0)
{
cerr<<"fcntl error"<此时就将该文件描述符设置为了非阻塞状态。
此时在调用read函数读取标准输入之前,调用SetNonBlock函数将0号文件描述符设置为非阻塞就行了。
代码如下:
#include
#include
#include
#include
#include
#include
bool SetNonBlock(int fd)
{
int fl = fcntl(fd, F_GETFL);
if (fl < 0){
std::cerr << "fcntl error" << std::endl;
return false;
}
fcntl(fd, F_SETFL, fl | O_NONBLOCK);
return true;
}
int main()
{
SetNonBlock(0);
char buffer[1024];
while (true){
ssize_t size = read(0, buffer, sizeof(buffer)-1);
if (size < 0){
if (errno == EAGAIN || errno == EWOULDBLOCK){ //底层数据没有就绪
std::cout << strerror(errno) << std::endl;
sleep(1);
continue;
}
else if (errno == EINTR){ //在读取数据之前被信号中断
std::cout << strerror(errno) << std::endl;
sleep(1);
continue;
}
else{
std::cerr << "read error" << std::endl;
break;
}
}
buffer[size] = '\0';
std::cout << "echo# " << buffer << std::endl;
}
return 0;
}
需要注意的是,当read函数以非阻塞方式读取标准输入时,如果底层数据不就绪,那么read函数就会立即返回,但当底层数据不就绪时,read函数是以出错的形式返回的,此时的错误码会被设置为EAGAIN或EWOULDBLOCK。

因此在以非阻塞方式读取数据时,如果调用read函数时得到的返回值是-1,此时还需要通过错误码进一步进行判断,如果错误码的值是EAGAIN或EWOULDBLOCK,说明本次调用read函数出错是因为底层数据还没有就绪,因此后续还应该继续调用read函数进行轮询检测数据是否就绪,当数据继续时再进行数据的读取。
此外,调用read函数在读取到数据之前可能会被其他信号中断,此时read函数也会以出错的形式返回,此时的错误码会被设置为EINTR,此时应该重新执行read函数进行数据的读取。
![]()
因此在以非阻塞的方式读取数据时,如果调用read函数读取到的返回值为-1,此时并不应该直接认为read函数在底层读取数据时出错了,而应该继续判断错误码,如果错误码的值为EAGAIN、EWOULDBLOCK或EINTR则应该继续调用read函数再次进行读取。
运行代码后,当我们没有输入数据时,程序就会不断调用read函数检测底层数据是否就绪。

一旦我们进行了输入操作,此时read函数就会在轮询检测时检测到,紧接着立马将数据读取到从内核拷贝到我们传入的buffer数组当中,并且将读取到的数据输出到显示器上面。

非阻塞IO可以在没有数据输入的时候,完成其它任务
#include
#include
#include
#include
using namespace std;
#include
#include
#include
#include
void PrintLog()
{
cout << "这是一个打印日志任务..." << endl;
}
void OperMysql()
{
cout << "这是一个数据库语句任务..." << endl;
}
void CheckNet()
{
cout << "这是一个检查网路情况任务..." << endl;
}
using func_t = function;
vector tasks;
void LoadTask()
{
tasks.push_back(PrintLog);
tasks.push_back(OperMysql);
tasks.push_back(CheckNet);
}
void HandlerTask()
{
for (auto &task : tasks)
{
task();
}
}
bool SetNonBlock(int fd)
{
int fl = fcntl(fd, F_GETFL);
if (fl < 0)
{
cerr << "error:" << strerror(errno) << endl;
return false;
}
int ret = fcntl(fd, F_SETFL, fl | O_NONBLOCK);
if (ret < 0)
{
cerr << "error:" << strerror(errno) << endl;
return false;
}
return true;
}
int main()
{
SetNonBlock(0);
char buffer[1024];
LoadTask();
while (true)
{
cout << ">>>";
int n = read(0, buffer, sizeof(buffer) - 1); // 检验条件是否就绪(等)+拷贝
if (n > 0) // 标准输入的数据就绪,可以进行读取
{
buffer[n] = 0;
cout << "echo#" << buffer << endl;
}
else // 读取数据出现报错
{
if (errno == EAGAIN || errno == EWOULDBLOCK) // 因为没有数据而报错,执行其它任务后,在进行读取试探
{
HandlerTask();
sleep(1);
continue;
}
else if (errno == EINTR) // 读取数据时因为信号到来而终止
{
continue;
}
else // 真正的出错了
{
cerr << "error:" << strerror(errno) << endl;
break;
}
}
}
return 0;
}