CNN是一种深度学习神经网络结构,特别适用于处理和分析具有网格结构数据的任务,如图像和视频数据。CNN在计算机视觉领域广泛应用,能够自动学习图像中的特征,并在各种视觉任务中表现出色。
CNN的设计灵感来源于生物学中的视觉皮层的工作原理,它使用了卷积操作来捕捉图像中的局部特征,并通过池化操作来减少数据的维度,从而实现特征的平移不变性和空间层次结构的建模。
CNN的主要组成部分包括:
卷积层(Convolutional Layers):卷积层通过在输入数据上滑动卷积核(一组可学习的过滤器)来提取局部特征,从而捕捉图像的纹理、边缘等信息。
池化层(Pooling Layers):池化层用于减少特征图的维度,常用的池化操作包括最大池化和平均池化,有助于提取更加抽象的特征并减少计算量。
全连接层(Fully Connected Layers):全连接层用于将特征映射到输出类别,通常在网络的顶部进行分类或回归任务。
激活函数(Activation Functions):激活函数引入非线性性质,帮助网络学习更加复杂的模式。
CNN在计算机视觉任务中取得了许多突破性的成果,包括图像分类、目标检测、语义分割、人脸识别等。它通过层级特征提取和参数共享的方式,在处理大规模图像数据时表现出色,使得计算机能够更好地理解和处理图像信息。
本次训练分两部分,一部分是CPU版本,一部分是GPU版本
CPU版本完整代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import time
# 定义CNN模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(32, 64, 3)
self.fc1 = nn.Linear(64 * 5 * 5, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 5 * 5)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 加载和准备MNIST数据集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# 创建模型实例并移动到CPU
net = Net()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 记录开始时间
start_time = time.time()
# 训练模型
for epoch in range(5): # 进行5个周期的训练
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99: # 每100个小批次打印一次损失
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 100:.3f}')
running_loss = 0.0
# 记录结束时间
end_time = time.time()
print('Finished Training')
print(f'Training took {end_time - start_time:.2f} seconds')
# 保存模型
PATH = './mnist_cnn.pth'
torch.save(net.state_dict(), PATH)这段代码演示了使用PyTorch来定义、训练和保存一个简单的CNN模型来识别MNIST手写数字数据集。
导入必要的模块:
torch:PyTorch库的主要模块。torch.nn:包含神经网络相关的类和函数。torch.optim:包含各种优化算法。torch.nn.functional:包含一些常用的非线性函数,如激活函数。torchvision:PyTorch的视觉库,用于加载和处理图像数据。torchvision.transforms:包含图像转换操作。time:用于测量时间。
定义CNN模型(
Net类):- 在这个类中,我们继承了
nn.Module基类,并在__init__方法中定义了神经网络的各层。 - 该模型包括两个卷积层(
conv1和conv2),两个池化层(pool),以及两个全连接层(fc1和fc2)。 - 在
forward方法中,我们定义了前向传播的流程,包括卷积、池化和全连接等操作。
- 在这个类中,我们继承了
加载和准备MNIST数据集:
- 使用
transforms.Compose创建一个数据预处理管道,将图像数据转换为张量,并进行归一化操作。 - 通过
torchvision.datasets.MNIST加载MNIST数据集。 - 使用
torch.utils.data.DataLoader创建数据加载器,用于批量加载数据并进行训练。
- 使用
创建模型实例并定义损失函数和优化器:
- 创建
Net类的实例,并将模型移动到CPU上。 - 定义交叉熵损失函数和随机梯度下降(SGD)优化器。
- 创建
记录开始时间,训练模型,记录结束时间:
- 使用
time.time()记录开始时间。 - 使用嵌套的循环在训练数据上进行多个周期的训练。
- 在每个周期的每个小批次中,执行前向传播、计算损失、反向传播和优化步骤。
- 打印每100个小批次的平均损失。
- 使用
time.time()记录结束时间。
- 使用
输出训练结果:
- 打印出训练完成的消息。
- 打印出整个训练过程所花费的时间。
- 保存模型:
- 将训练好的模型参数保存到文件中,以便以后可以加载和使用。
- GPU版本代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import time
# 检查是否有可用的GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 定义CNN模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(32, 64, 3)
self.fc1 = nn.Linear(64 * 5 * 5, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 5 * 5)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 加载和准备MNIST数据集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# 创建模型实例并移动到GPU
net = Net().to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 记录开始时间
start_time = time.time()
# 训练模型
for epoch in range(5): # 进行5个周期的训练
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device) # 将数据移到GPU上
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99: # 每100个小批次打印一次损失
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 100:.3f}')
running_loss = 0.0
# 记录结束时间
end_time = time.time()
print('Finished Training')
print(f'Training took {end_time - start_time:.2f} seconds')
# 保存模型
PATH = './mnist_cnn.pth'
torch.save(net.state_dict(), PATH)使用炼丹侠算力市场的A100服务器,对两种版本的训练过程进行训练时间对比,炼丹侠提供了高性能的计算服务器,其中A100是目前业界先进的计算型GPU,此处训练结果对比如下:
GPU版本训练时长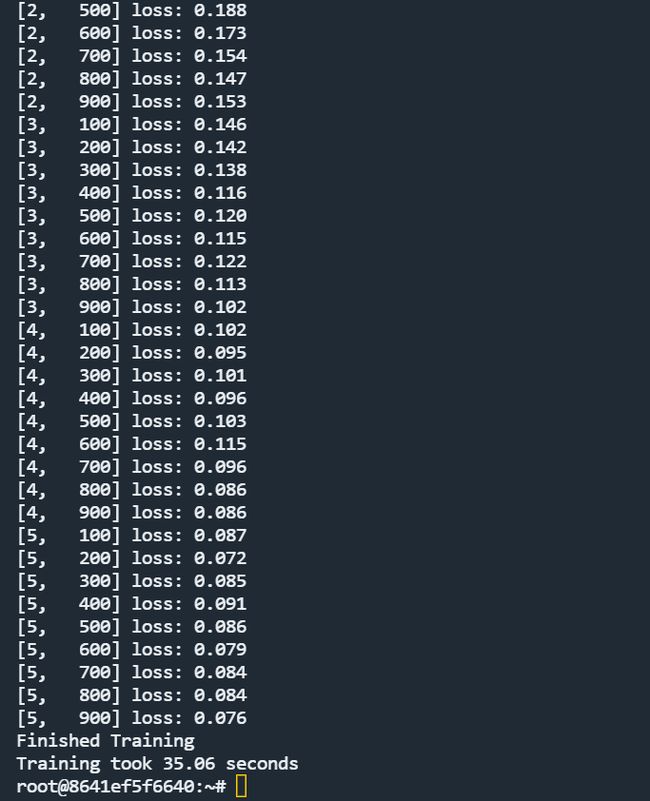
CPU版本训练时长
A100训练相比于使用CPU训练,时间性能提升了14倍。