前言
关于网络相关的文章已经写过很多了:
[1]《计算机网络引论》
[2]《计算机网络安全引论》
[3]《NIO 学习笔记(一)初遇》
[4]《Socket简介和I/O多路复用》
[5]《NIO 学习笔记(二)相识篇》
[6]《NIO学习笔记(三) 甚欢篇》
[7]《Netty学习笔记(一)初遇篇》
[8]《HTTP/2.0的二进制是什么?》
[9] 《我们来聊聊HTTPS吧》
[10] TCP 学习笔记(三) 可靠传输
[11] HTTP学习笔记(三) HTTP/2
[12] TCP学习笔记(二) 相识篇
[13] HTTP协议学习笔记(一) 初遇篇
[14] TCP学习笔记(一) 初遇篇
本系列打算糅合这些文章,使用Java写一个简单的HTTP/HTTPS服务器,我的预设是希望读者诸君已经看过上面的文章了,但是数了数上面大致有十四篇了,希望 读者诸君已阅上面的文章,想来有些奢望。那这里大致的理理这些文章的结构,并给出一个阅读本篇的最小知识点。让我们从网络通信开始说起,如果通信的双方不是面对面,那么交流就要借助于载体,我想起小时候经常看的武侠电影,卧底将情报绑在信鸽的腿上,但是这样传递情报的方式,情报就有被篡改、丢失、截获的风险。篡改、丢失、截获,这也是通信要面临的三个问题。随着时代的发展,越来越快的交互信息变得越来越迫切,计算机帮助我们完成任务之后,我们希望也在计算机上完成信息的交换,那么要完成信息的交换,两台计算机势必要有信道,信道是传输信息的通道,但是有了通道还不够,通信的双方还需要彼此知道地址,有了地址还不够,我们还要避免信息的截获、丢失、篡改。
在通信的时候,通信的双方是明确的,也就是说我知道我要和谁通信,以上就概括了两台计算机通信要面临的问题,面对这么多问题,计算机互联网的先驱们,选择了分层来解决问题,两台计算机之间的信道被划到物理层,信息最终要转变为信号,而物理层就负责传输信号。单纯的0和1没有任何意义,必须规定解读方式,多少个电信号算一组? 每个信号位有何意义? 如果我们只有两台计算机,信号送给是明确的,最早的网络是猫+电话线,连一条电话线。理论上双方只要完成拨号,双方就能进行通信。这个过程跟两个人打电话没什么区别。
这种链路我们称之为点对点链路。点对点链路的有点是简单,缺点是每加入一台计算机,就要给电脑新配置一个猫,如果我有多台电脑,这些电脑需要互相连接,就需要每个电脑的猫连接到一起,这带来的成本很高,管理成本也非常重,这种连接方式被称为全网状拓扑(Full Mesh)网络。这种连接方式也不是一无是处,优点是可靠性高,网络中部分链接出现故障不会影响到整个网络。但成本高,维护困难是真的承受不住。

为了降低成本,人们想到了另外一种连接方式,也就是所有的电脑只需要连接一个猫,然后所有猫连接到同一条网线上(叫总线)。我们称这种连接方式为总线网络。这种方式的确降低了组网的成本,但是使用成本却上升了。如果上图中的A想给B发送数据,可以启动自己的猫发送,那么如果此时C和D发数据,那么就会形成干扰,最终谁的数据也发不出来。为了解决这个问题,人们规定,如果想发数据,必须先试用自己的猫听一下网线上有没有其他电脑正在通信。如果有,就自觉等待一段时间,然后再检查。这套机制后来演化了成载波侦听多路访问/碰撞检测(CSMA/CD)机制。教科书上都会将这个CSMA/CD(我已经给忘记了)。
解决了冲突问题,总线网络就能工作吗?当然是不能的! 我们在签名讲的点对点两边各有一台电脑,收房双方非常明确,不需要额外信息。那么在总线网络中,所有电脑共享一条电缆,可以同时接收网络上的全部信号。那大家如何确定数据是如何发给自己的呢?为了解决这个问题,人们发明了数据帧这个概念。帧是发送数据的最小单位,当时有很多链路层协议,以太网只是后面涉及的一种。但是不同的帧结构都是大同小异,核心都包含目标地址、源地址和数据三部分,这也是和寄信一样,信封是携带了发送人的地址、收信人的地址、信内容。
这里首次出现了地址这个概念。正是因为总线网线中所有设备共享总线,所以需要通过引入地址的概念来区分不同的设备。对于以太网,这个地址就是我们常说的MAC地址。这个时候猫已经变成了我们现在常说的网卡了。以太网规定MAC地址占6个字节,也就是前面说的48位。
所有发出的包都带着目标电脑的MAC地址。网络中所有设备收到数据后会自觉比较目标地址是不是自己,如果不是就丢弃,是的,你没有听错,全凭大家自觉。这样就解决了上面我们提出的问题。
引入地址的概念,也就产生了新的问题-如何给计算机设置MAC地址呢? 不同的网络有不同的处理方式。
曾经有一种叫ARCNET的网络协议,它的MAC地址只有1个字节(8位),需要网络管理员通过网卡上的拨动开关手工设置开关设置。好在当年能连网的设备很少,8位地址可以支持最多256台设备连网,也够用了。
以太网规定在网卡出厂的时候就得分配48位MAC地址,全球唯一。
随着总线网络的普及,越来越多的大公司或者是大学开始使用网络连接它们的设备。为了方便传输数据,人们还发明了网桥,我们可以将网桥想象成装有多个网卡的设备,每个网卡连接一个总线网络。网桥唯一的作用就是把一个网卡收到的内容原样转发到另一张网卡所在的网络。
这样网络的规模越来越大,连网的设备越来越多,通信冲突的频率页越来越高。最终的结果就是数据传输的越来越低(因为只要有一个人在发数据,其他所有人都得等待)。但就这样,人们对互联互通的要求还是没被满足。除了公司或者组织内部的网络,人们还想把不同城市的设备和网络都连起来,这就需要用到长途电话线。
前面我们说过网桥是一种无脑转发设备,它的无脑不仅体现在不关心数据内容方面,还体现在尽自己最大能力转发。如果是相同局域网,两边的网速相近,那不会有什么问题。那如果一边是局域网,一边是长途电话线,那么来自局域网的广播数据会把电话线挤爆,大家谁也别想玩。
既然出现了这样的问题,我么就需要对网桥进行改造,我们希望那个网桥智能一点。让它可以学习不同网络所有设备的MAC地址。当有数据要转发的时候,它可以根据目标地址判断应该转发到哪个网卡,从而减少广播数量。
但是因为以太网的MAC地址是在出厂的时候指定的,那么就没有办法确定某个总线网络中所有的AMC地址,只能通过广播来学习,也只能在网桥设备保存全部MAC地址,而且还要及时更新。除此之外,网桥本身只转发,理论上也不需要MAC地址。所以网络内的计算机知道数据是经过了几个网桥转发,如果出了问题,也不知道在哪个环节出了问题。
最终IETF(Internet Enginering Task Force)给出了解决方案 ,也就是再加一层,也就是在以太网之上引入了网络层(也就是IP层)。 就是引入逻辑地址,这也就是IP地址,而且觉得32位差不多够用了,甚至都没考虑MAC地址都是48位。通过IP地址我们就可以将网络划分成许多个子网,根据逻辑地址,我们就能知道要转发给哪个网卡了,从而减少广播数量。所以,每个设备想要加入一个网络都需要被分配一个IP地址,通信的双方使用IP地址进行通信。IP地址是管理员按需指定的,可以根据前缀聚合。所以原来的网桥,现在变成了路由器,不需要保存网络中所有的MAC地址,只要保存网络前缀就能进行转发。
那么请问,如何根据逻辑地址得到目标的mac地址呢? 这也就是ARP协议。每当电脑在通信之前会先在网络上发一个广播(这个广播不会被转发到其他网络), 问谁的IP地址是某某,这个时候对应的电脑就会回复,是我,我的MAC地址是某某某。发送方就当拿到了接收方的MAC地址,进而完成通信。
如果目标电脑在另一个网络,这个时候发送方就会在自己的网络里广播说拥有网关ip设备的是谁(我们假设它的默认网关IP是192.168.1.1),网关就会回复自己的MAC。然后,发送方就会通过网关的MAC地址给网关发送一条IP报文,报文的目标IP就是接收方的IP地址,来源IP自然也就是发送方的IP地址。网关是两个子网的桥梁。
那如果不在一个网络呢,我们来举例讲述这个通信过程,假设H1想和H2发送数据,H1在不知道H2在不在一个网络里面,首先在自己所在网络里广播,谁的IP是某某某,没人回复之后,就知道H2和自己不在一个网络了,这个时候他就会通过ARP协议解出来网关的mac地址,然后给网关的mac地址发送了一个报文,报文的目标ip是h2的ip,源ip地址是H1的ip地址,路由器收到这个报文之后,根据目标地址确定目标ip在哪一个子网下面,转发给对应的路由器R2,路由器R1保存了H2所在网络的前缀上,然后由路由器R2转发给H2, 如此就完成了通信过程,
整个过程,H1和R1都不需要知道H2的MAC地址,但所有节点必须知道相临节点的MAC地址(也叫下一跳)。所以说,到现在为止,哪怕是引入了IP层,实际通信还是依赖MAC地址。在IP网络中,如果模板在同一个网络,则通过广播进行通信; 否则,则通过网关转发。因为有广播的存在,所以网速还是会受到影响,这时每个局域网也叫冲突域。因为IP网络引入了路由器,所以跟原来的总线网络相比,冲突域变小了,广播减少了,网速提高了。但是我们还希望网速更快,于是我们发明了交换机,交换机也是一种局域网设备,功能和前面说的网桥类似,但是交换机可以进一步减少广播的数量。
声明到这里为止, 基本引用的是参考资料[1], 来自知乎作者涛叔。下面基本为我的原创。
但是,交换机可以进一步减少广播的数量。以上图为例。如果A想给C发送数据,它会先通过ARP广播查询C的MAC地址。这一步是免不了的。但是,这一步也会被交换机监听/学习到,所以交换机会将C连接的网口跟C的MAC地址绑定到一起,等A给C发数据的时候,交换机只会给C发数据。这个时候B和D都收不到数据。不但收不到,B和D还可以在A与C通信期间进行通信,这就进一步提高了网络的利用效率。
网络在发展的同时,计算机也在发展,两台计算机进行通信,本质上是两台计算机上的进程进行通信,那么一台计算机是可以运行多个进程的,那么ip层上报的报文,该交给哪个进程呢,由此就引出了传输层,传输层引入了端口这个概念,来解决这个问题,ip加上端口,就能知道报文交给哪个进程进行处理。但数据一定能送到嘛,这也是我们上面提出的数据丢失问题,丢失了怎么办,再重传,这也就是传输层要考虑的问题。传输层协议交给进程的是字节流,通信的双方需要制定规则才能解析出有意义的报文,由此就引出了应用层协议。
那么作为开发人员,我们该如何使用网络协议,操作系统提供了对应的实现,各个高级语言一般都内置了调用,目前来说只有几种可供应用程序使用的TCP/IP的应用程序接口,最著名的就是美国加利福利亚大学伯克利分校为Berkeley UNIX操作系统定义的API,被称为套接字接口(socket interface)。微软在其操作系统中采用了套接字 API,但是有一点不同,我们称之为Windows Socket。AT&T的Unix System V版本定义的接口,简写为TLI(Transport Layer port)
我们可以认为套接字作为进程和运输层协议之间的接口,像下面这样。

请注意: 在套接字以上的进程是受应用程序控制的,而在套接字以下则属于操作系统的控制。因此,只要程序要使用TCP/IP协议进行通信,它就必须调用操作系统提供的网络通信接口。这里的套接字是一个相对来说有些抽象的概念,那么该怎么理解这里的套接字呢? 为什么说这里的套接字? 因为在其他语境下套接字拥有其他语义,但是也叫套接字。我认为这里的套接字的就是一个规则、协约、机制 : 当程序需要使用网络通信时,必须首先调用操作系统提供的Socket接口,也可以称之为发出Socket系统调用,请求操作系统创建一个"套接字"。这个调用的实际效果就是请求操作系统把网络通信所需要的的一些资源(CPU时间,网络带宽、存储器空间等)分配给该应用进程。操作系统为这些资源的总和创建一个套接字描述符的号码(小的整数)来表示,然后将这个套接字描述符返回给应用进程。此后,应用进程所进行的网络操作(建立连接、收发数据、调整网络通信参数等)都必须使用这个套接字描述符。
到现在为止一切都很好,不好的是,我们的信息是明文,有被窃取篡改的风险,要防止窃取和篡改,我们可以使用SSL/TLS协议, 详细的可以参看:
- 我们来聊聊HTTPS吧
这个系列考虑的使用Java的API写出一个BIO和NIO模式下面的HTTP/HTTPS服务器,有了上面的知识,我们已经对网络有一个基本的了解了,下面就开始用Java构建HTTP/HTTPS服务器。
BIO模式的服务器
BIO/和NIO处理连接的策略不同,但是共同点都是使用了TCP协议,也就是它们都需要监听端口,只是启动的时候处理处理请求的方式不同,我们抽象出来一个基类,我们就姑且命名为Server, 这个Server是一个抽象类 ,我们通过ServerSocketChannel这个类监听端口,所以Server类里面需要有一个ServerSocketChannel成员变量,在ServerSocketChannel我们可以配置当前的使用哪种网络模型, NIO还是BIO:
// true 代表BIO,false代表NIO
public final SelectableChannel configureBlocking(boolean block)默认模式即是BIO,我们当前构建的就是BIO模式下面的HTTP服务器,我们上面说到我们想要使用应用层的协议需要端口,所以Server这个抽象类里面还需要一个端口初始变量,我们还想要我们的HTTP服务器支持HTTPS协议,但有希望这个是灵活配置的,那么Server也需要一个成员变量来切换HTTP、HTTPS模式,除此之外,TCP是面向连接的,但是服务端处理客户端请求建立的连接也需要时间,ServerSocket会维护一个队列,还没来得及处理的连接就会放到这个队列里面,如果队列已经满了,就会抛出连接被拒绝的异常。 所以我们的成员变量要要有控制队列大小的参数。
到现在为止,我们就可以通过ServerSocketChannel来拿到SocketChannel了,操作系统会将数据通过通道送入到Buffer中,那这里我们可以在设计一个类,将通道的数据处理到ByteBuffer中,那既然要处理到这个ByteBuffer里面,所以我们这个类里需要有一个ByteBuffer的成员变量,这里我们简单的讲一下ByteBuffer,本文的思路是在用到的哪些概念的时候,就会讲哪些,讲的刚好够用。要给SocketChannel读,首先我们得创造ByteBuffer这个对象:
ByteBuffer byteBuffer = ByteBuffer.allocate(4096);我们可以将ByteBuffer当做一个装数据的容器,那对于容器我们自然就关心如何存取,那如何存呢,ByteBuffer里面以put开头的就是将数据放入ByteBuffer中的方法,如果我们放入ByteBuffer的数据超过了设定的大小,就会抛出BufferOverFlowException这个异常:
ByteBuffer byteBuffer = ByteBuffer.allocate(1);
byteBuffer.put("hello world".getBytes(StandardCharsets.UTF_8));存的问题,我们解决了,下面我们来解决如何取的问题,在读之前,我们需要介绍一下Buffer的几个重要属性,来帮助我们理解我们取数据,为什么要这么取。在ByteBuffer里有以下几个变量:
- position: 下一个将要写入或读取的数组下标
- capacity: ByteBuffer的大小
limit: 第一个不能读不能写的数组下标
ByteBuffer在未放入数据之前, position是0,capacity是4096,limit则是4096。上面我们放了数据进入ByteBuffer,我就只想读有数据的位置,那么只需要将position赋值给limit就行,然后将position放到0,这也就是ByteBuffer中flip方法做的事。现在我们已知的是, 通过ServerSocketChannel的accept方法在阻塞I/O模式下,直到连接建立,才会返回给我们一个SocketChannel,我们可以通过SocketChannel将数据读取到ByteBuffer中,那么对于TCP协议来说,TCP数据的负载1400字节,所以应用层如果交付给传输层的数据为1500字节,那么就需要两个TCP数据包传输,我们可以理解为拆成两个包裹发送,那对于SocketChannel来说,我们自然就关心他的读取方式,是到了多少数据包就读多少,还是根据ByteBuffer的剩余容量去读取呢? 如果是到了多少数据包就读多少,那么我们知道ByteBuffer来说,超过了预设值的容量,就会抛异常, 我们应当根据TCP最大数据包进行扩容,如果ByteBuffer的剩余容量小于最大TCP数据包,那么就当进行扩容,这种假设建立在SocketChannel读的是一个有一个TCP数据包,因为SocketChannel的read方法在Oracle JDK中是不开源的,源码注释上又没写读写的行为,那我们如何针对ByteBuffer进行扩容呢, 毕竟SocketChannel向ByteBuffer里面读取数据的行为也不归我们控制,其实我是为这个问题思考过一阵的,我将这个问题定义为,在应用层未限制报文大小的前提,交付给传输层报文的大小不固定的情况下,该如何选择最优扩容时机。 我将这个问题抽象为了一个数学问题,苦苦思索,与朋友交谈之后,朋友建议我去看Netty是如何对ByteBuf进行扩容的, ByteBuf是Netty对ByteBuffer的扩展类,我虽然看的懂ByteBuf是如何扩容的,但是我还是无法回答我自己提出的问题,某一天我在公司这个问题还在我的脑海中盘旋,我装了Open JDK,OpenJDK是开源的,我们可以看Open JDK的实现,SocketChannel是一个抽象类,read方法是一个抽象方法,所以我们还得看SocketChannel的实现类,SocketChannelImpl, IDEA可以帮我们自动寻找子类,我电脑上的Open JDK是JDK11,read方法的实现如下:
public int read(ByteBuffer buf) throws IOException {
Objects.requireNonNull(buf);
readLock.lock();
try {
ensureOpenAndConnected();
boolean blocking = isBlocking();
int n = 0;
try {
beginRead(blocking);
// check if input is shutdown
if (isInputClosed)
return IOStatus.EOF;
if (blocking) {
do {
n = IOUtil.read(fd, buf, -1, nd);
} while (n == IOStatus.INTERRUPTED && isOpen());
} else {
n = IOUtil.read(fd, buf, -1, nd);
}
} finally {
endRead(blocking, n > 0);
if (n <= 0 && isInputClosed)
return IOStatus.EOF;
}
return IOStatus.normalize(n);
} finally {
readLock.unlock();
}
}这里我们只关注操纵ByteBuffer的代码,其他我们不做研究,最终还是IOUtil来将数据放入ByteBuffer中,我们接着来看IOUtil的read方法,对应的实现如下:
static int read(FileDescriptor fd, ByteBuffer dst, long position,
boolean directIO, int alignment, NativeDispatcher nd)
throws IOException
{
if (dst.isReadOnly())
throw new IllegalArgumentException("Read-only buffer");
if (dst instanceof DirectBuffer)
return readIntoNativeBuffer(fd, dst, position, directIO, alignment, nd);
// Substitute a native buffer
ByteBuffer bb;
int rem = dst.remaining();
if (directIO) {
Util.checkRemainingBufferSizeAligned(rem, alignment);
bb = Util.getTemporaryAlignedDirectBuffer(rem, alignment);
} else {
bb = Util.getTemporaryDirectBuffer(rem);
}
try {
int n = readIntoNativeBuffer(fd, bb, position, directIO, alignment,nd);
bb.flip();
if (n > 0)
dst.put(bb);
return n;
} finally {
Util.offerFirstTemporaryDirectBuffer(bb);
}
}我们可以看到在read方法里面又创建了一个ByteBuffer,然后调用了ByteBuffer的remaining方法,这个方法的作用是获取当前ByteBuffer还剩多少容量,directIO是false,到达的TCP数据包是先进了read方法自己创建的Bytebuffer中,然后在放入我们传入的Bytebuffer中。到现在为止我们就结案了,我们在用SocketChannel读之前也只需看下剩余容量,我们可以提前设定一个阈值为ByteBuffer的百分之五,如果剩余的小于百分之五,我们就可以认为ByteBuffer快用完了,然后我们就对ByteBuffer进行扩容,这个扩容的时机,你可以设定为ByteBuffer剩余容量为0,用完了再进行扩容,但我们应当避免频繁扩容,所以我这里不建议在ByteBuffer用完了再进行扩容,我设置的是百分之五,你也可以设置为百分之十,我为什么设置为百分之五呢,这是我参考别人的设计,至于为什么别人要设定为剩余容量小于百分之五,我暂时还没联系到那位作者,为什么这么设计。 其实我们也可以不扩容,简单一点就是设定接收的最大报文长度,然后ByteBuffer就分配这个大小,这么做似乎有些浪费,我们本篇采用的设计就是剩余容量小于百分之五对ByteBuffer进行扩容。
扩容的问题解决了, 我们的ByteBuffer可以放的下客户端发送的报文了,那么还有一个问题就是什么时候,读取数据完毕,然后对数据进行解析。对于HTTP请求报文来说是有结束符号的,所以我们可以判断ByteBuffer中的数据是否有结束符,如果有就代表HTTP请求的数据解析完毕,可以交给接收方来处理了。注意我们本次构建的HTTP服务器相对初级一点,只支持HTTP 1.0,而且用的I/O模型是BIO,所以我们也可以判断如果SocketChannel没有可以读的数据了,代表HTTP请求的数据解析完毕了。我们可以将数据交给专门解析数据的组件来进行处理,这个组件你可以理解为类。
到现在为止我们的流程有接收数据,解析数据,根据请求构建响应,然后发送响应。我们讲了这么多理论,已经可以开始着手写接收数据和解析数据的部分了,我们本系列的预期是用Java的标准库来实现BIO/NIO模式下的HTTP/HTTPS服务器,然后用Netty来实现HTTP服务器,设计的HTTP服务器比较简单,只回应的简单请求。后面逐步的扩展。
因为我们可以借助ServerSocketChannel来配置BIO还是NIO,而BIO和NIO就是在具体的行为上有所不同,在初始化属性方面是具备共性的,所以这里我们首先建立了一个抽象类Server,Server负责初始化端口,backlog,启动的是HTTP模式还是HTTPS模式,本篇不介绍HTTPS的实现,我们将HTTPS的实现放在后面介绍。
本篇我们写的是一个HTTP服务器, 这里我想做的灵活一些,在启动的时候可以指定端口、backlog等等。我们现在知道Java 启动的命令如下所示:
java -jar jar名 在jar名后面跟的参数会被main函数的args接收,我们来测试一下, 首先我们有一个Spring Boot Web工程,然后我们在main函数里面打印一下args参数:
@SpringBootApplication
public class SsmApplication {
public static void main(String[] args) {
System.out.println(Arrays.toString(args));
SpringApplication.run(SsmApplication.class, args);
}
}然后我们在IDEA的terminal里面输入:
mvn package然后在target里面就可以看到打包好的jar了,然后我们以命令行的方式启动这个jar:
java -jar jar名 hello就能在启动的时候看见,首先在终端里面输出的是hello:

我们一般用IDEA开发,在IDEA里面想配置这个参数可以通过如下步骤:
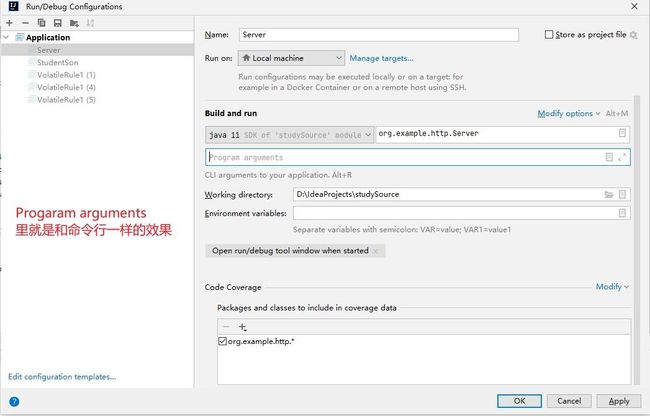
我们前面提到我们会用原生NIO、BIO,Netty实现HTTP服务器,我们就读取program aruments来决定当前的HTTP服务器是哪种模型,所以我们的基础Server类如下所示:
package org.example.http;
import javax.net.ssl.SSLContext;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.ServerSocketChannel;
import java.util.Arrays;
/**
* @author xingke
* @date 2023-07-15 15:36
*/
public abstract class Server {
protected ServerSocketChannel serverSocketChannel;
protected SSLContext sslContext;
static int port = 8000;
static int backlog = 1024;
static boolean secure = false;
public Server(int port, int backlog, boolean secure) throws IOException {
// 创建一个ServerSocketChannel
serverSocketChannel = ServerSocketChannel.open();
/**
* 可以重用ip+端口这个链接,TCP以链接为单位,当TCP链接要关闭的时候,会等待一段时间再进行关闭,
* 如果我想要重用端口,那么channel就无法绑定,在绑定到对应地址之前,设定重用地址。即使在这个端口上的tcp连接
* 处于处于TIME_WAIT状态,我们仍然可以使用
*/
serverSocketChannel.socket().setReuseAddress(true);
// 绑定端口和backlog
serverSocketChannel.bind(new InetSocketAddress(port),backlog);
}
/**
* 这里是抽象方法,我们后面要用NIO再实现一遍
* 所以这里交给子类来实现
*/
protected abstract void runServer();
/**
* 我们要写的是一个简单的HTTP服务器,
* 这个服务器可以从命令行方式启动的时候接收参数
* 我们可以选择从main函数
* @param args
*/
public static void main(String[] args) throws IOException {
Server server = null;
if (args.length == 0){
System.out.println("http server running default model");
server = new BlockingServer(port,backlog,secure);
server.runServer();
}
// 端口目前先固定死, 我们目前只读一个参数
if ("B".equals(args[0])){
server = new BlockingServer(port,backlog,secure);
}else if ("N".equals(args[0])){
server = new NonBlockingServer(port,backlog,secure);
}else{
System.out.println("input args error only support B OR N");
return;
}
server.runServer();
}
}
再重新梳理一下我们需要的组件
在Java里面一切都是类,这里说的组件只是承担了特别功能的类,我们就姑且将其命名为组件。根据处理流程,我这里划分了以下几个类:
- Server 基础类, 根据读取的参数来以不同的IO模型处理请求
Server的子类:
- BlockingServer 真正处理请求的类 BIO模式
- NonBlockingServer 真正处理请求的类 NIO模式
- ChannelIO 负责从Channel里面读取数据到ByteBuffer中
- RequestServicer 解析请求 给响应
- Request 辅助解析请求
- Reply 辅助构建响应
运作流程如下所示:

这是我自己的分法,你也可以按照自己的方式去分解,我将最基础的原理都告诉了诸君,诸君也可以写在一个类里面,用上各种各样的设计模式,都可以有自己的写法。
BlockingServer
BIO模式下的解析数据相对简单一些,我们只需要调用SeverSocketChannel的accept方法,会一直阻塞,直到连接完全建立,连接建立之后我们将SocketChannel传递给ChannelIO即可。所以我们的BlockingServer可以这么写:
public class BlockingServer extends Server{
public BlockingServer(int port, int backlog, boolean secure) throws IOException {
super(port, backlog, secure);
}
@Override
protected void runServer() throws IOException {
SocketChannel socketChannel = serverSocketChannel.accept();
ChannelIO channelIO = ChannelIO.getInstance(socketChannel, true);
RequestServicer requestServicer = new RequestServicer(channelIO);
requestServicer.run();
}
}
跟我们上面的运作流程是一样的,连接建立之后拿到SocketChannel, 然后将SocketChannel传递给ChannelIO,读取通道的数据,读取完数据交给RequestServicer, 解析请求数据,给予客户端响应。
ChannelIO
我们上面提到我们要解析请求数据,那就代表要读取,给予客户端响应,代表要写,ChannelIO需要有一个读方法和写方法,在读之前我们需要ByteBuffer,所以我们在获得ChannelIO实例的时候,需要预先分配一个ByteBuffer,因为HTTP协议未限制报文大小,我们的ByteBuffer可能就会装不下,所以我们在读的时候就需要判断剩余容量,根据剩余容量的多少来判断是否需要扩容。读取数据完毕,数据写完了,我们就需要关闭通道,所以我们的ChannelIO如下所示:
package org.example.http;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
public class ChannelIO {
private SocketChannel socketChannel;
private ByteBuffer requestBuffer;
int defaultByteBufferSize = 4096;
private ChannelIO(SocketChannel socketChannel, boolean blocking) throws IOException {
this.socketChannel = socketChannel;
this.requestBuffer = ByteBuffer.allocate(4096);
this.socketChannel.configureBlocking(blocking);
}
public static ChannelIO getInstance(SocketChannel socketChannel, boolean blocking) throws IOException {
return new ChannelIO(socketChannel,blocking);
}
public int read() throws IOException {
// 剩余的小于百分之五自动扩容
resizeByteBuffer(defaultByteBufferSize / 20);
return socketChannel.read(requestBuffer);
}
private void resizeByteBuffer(int remaining) {
if (requestBuffer.remaining() < remaining){
// 扩容一倍
ByteBuffer newRequestBuffer = ByteBuffer.allocate(requestBuffer.capacity() * 2);
// 转为读模式
requestBuffer.flip();
// 将旧的buffer放入到新的buffer中
newRequestBuffer.put(requestBuffer);
requestBuffer = newRequestBuffer;
}
}
public ByteBuffer getReadBuf(){
return this.requestBuffer;
}
public int write(ByteBuffer byteBuffer) throws IOException{
return socketChannel.write(byteBuffer);
}
public void close() throws IOException{
socketChannel.close();
}
}ChannelIO有了,现在就需要RequestServicer来调用ChannelIO提取数据了。
RequestServicer
在HTTP协议下面,不限制报文的大小,那么TCP协议会对HTTP交付的报文分包发送,至于分几个包我们无法预设,所以提取数据应当是一个无限循环,虽然HTTP不限制报文的大小,但是也是有结束符的,所以我们可以解析报文判断解析到的数据是否有结束符,再有另一个条件就是SocketChannel读不到数据了,我们也可以认为读完了,所以这个无限循环结束的条件有两个,一是SocketChannel无数据可读,二是从接收到的数据解析到了结束符。
从接收到的数据解析到了结束符的这个功能我们放到Request这个类里面。
Request
HTTP 2.0 之前以\r\n作为结束符(这里不确定改了没),所以我们判断结束只需要判断ByteBuffer中的后四个字符是\r\n即可,判断报文是否接收完毕的事情结束了,我们接下来回答如何就解析数据这个问题,一只的是HTTP请求有请求方式: GET POST HEAD PUT等,我们目前设计的是只支持这四种,所以我们从数据里面解析到请求方式,如果不是我们支持的请求方式,我们就需要告诉客户端,bad request,也就是400。这里我们解析到数据后之后,就回复一个hello world给客户端。
我们在捋一下Request具备的功能,首先是判断报文是否接收完毕,再有就是解析报文,在解析报文的时候我们首先获取请求方式,如果请求方式不被支持,响应就是400,如果是支持的方式,我们就接着往下解析,用解析的信息构造URI这个类,我这里的设计是Request有三个成员变量一个是请求方式,这个我们用一个内部类来承接,一个是HTTP版本,一个是hostname。 所以我们的Request类构成如下:
public class Request {
private Action action;
private URI uri;
private String version;
public Request(Action action, URI uri, String version) {
this.action = action;
this.uri = uri;
this.version = version;
}
static class Action{
private String name;
static Action GET = new Action("GET");
static Action POST = new Action("POST");
static Action PUT = new Action("PUT");
static Action HEAD = new Action("HEAD");
public Action(String name) {
this.name = name;
}
public String toString(){
return this.name;
}
static Action parse(String s){
if ("GET".equals(s)){
return GET;
}
if ("POST".equals(s)){
return POST;
}
if ("PUT".equals(s)){
return PUT;
}
if ("HEAD".equals(s)){
return HEAD;
}
// 参数不合法
throw new IllegalArgumentException(s);
}
}
public static boolean isComplete(ByteBuffer byteBuffer){
int position = byteBuffer.position() - 4;
if (position < 0){
return false;
}
return byteBuffer.get(position + 0) == '\r'
&& byteBuffer.get(position + 1) == '\n'
&& byteBuffer.get(position + 2) == '\r'
&& byteBuffer.get(position + 2) == '\n';
}
private static Charset ascii = StandardCharsets.US_ASCII;
/**
* 正则表达式 用来分割请求报文
* http 请求的报文是: GET /dir/file HTTP/1.1
* Host: hostname
* 被正则表达式分割以后:
* group[1] = "GET"
* group[2] = "/dir/file"
* group[3] = "1.1"
* group[4] = "hostname"
*/
private static Pattern requestPattern
= Pattern.compile("\\A([A-Z]+) +([^ ]+) +HTTP/([0-9\\.]+)$"
+ ".*^Host: ([^ ]+)$.*\r\n\r\n\\z",
Pattern.MULTILINE | Pattern.DOTALL);
public static Request parse(ByteBuffer byteBuffer) throws RequestException {
// byte to char
CharBuffer charBuffer = ascii.decode(byteBuffer);
Matcher matcher = requestPattern.matcher(charBuffer);
// 未匹配
if (matcher.matches()){
throw new RequestException();
}
Action a;
try {
a = Action.parse(matcher.group(1));
}catch (IllegalArgumentException e){
throw new RequestException();
}
URI u = null;
try {
u = new URI("http://" + matcher.group(4) + matcher.group(2));
}catch (URISyntaxException e){
throw new RequestException(e);
}
return new Request(a,u,matcher.group(3));
}
}这里我们理一下一个报文被处理的过程,首先我们将Byte转为char,然后用正则表达式将数据进行分割,如果和我们设定的正则表达式不匹配,则抛出解析异常,如果解析正常,那么从解析的数据中解析请求方式,如果不是我们支持的请求方式,同样也抛出解析异常。解析请求方式正常我们用解析到的信息来构建URI对象。解析失败同样抛400。最后返回一个Request对象。解析完了请求,我们如何给响应,这也就是Reply类承接的工作。
Reply
一个响应首先有响应码、响应内容,然后辅助我们给响应头,那这个这个组件,应该具备什么样的功能呢?首先是辅助我们加响应头,所以这个类里面有一个headers方法,来辅助我们加请求头。请求标头里面还有一个状态编码值得我们注意,说的状态编码,各位同学可能还是不大理解, 我们直接看图:

这个状态代码也是需要我们的Server需要回应的,一个是http状态码,另一个是描述,这里我用类来描述状态代码,这个类我命名为Code,这是我取的名字,你可以命名为StatusCode,这个StatusCode 放置了一些常用的状态代码: 200、400、404、405。所以我们的Reply里面需要有一个Code类型的成员变量,一个HTTP请求,有响应标头和响应体,响应体里是放我们发送给客户端的内容。所以我们这里还需要有一个响应体的成员变量,我们也知道HTTP支持各种各样的消息类型,比如html、xml等等,除了类型之外,还需要告诉客户端的内容长度。我们发送内容的时候操纵的是字符所有我们的接口里面还需要有一个方法来将内容转码, 我们后面还需要回应文件内容,所以接口里面还需要有一个释放资源的方法。这里我选择用接口来抽象行为,发送的时候就能使用一组方法,构建起来更为简单。我认为转码,发送,释放资源应当在一个接口里面,我们姑且命名为Sendable:
public interface Sendable {
void prepare() throws IOException;
boolean send(ChannelIO channelIO);
void release();
}而响应内容类型和长度不应该放在发送接口里面,我建模的思路是某个对象类型有不同的响应类型和计算长度方法,而且都能发送出去,所以我这里设计的是实际内容接口继承Sendable接口:
public interface Content extends Sendable {
String type();
long length();
}我们这里实现一个文本类型,我们姑且将其命名为StringContent,字符串形式的响应类型有各种各样的,所以我们这里是需要在StringContent里面放置一个这样一个成员变量,实际内容也是由外部传入,传入的内容最终还是需要通过ByteBuffer返回给调用者,所以这里还是需要一个ByteBuffer一个成员变量。这里构造函数我们放置三个,第一个是内容和类型都由外部传入,第二个是由外部传入响应内容,响应内容类型固定为text/plain。 第三个是不接受支持的类型,这里我们接收的参数是Exception。在这种指导思想下我们的StringContent如下所示:
public class StringContent implements Content{
private String type; // MIME type
private String content;
private ByteBuffer byteBuffer;
private static final Charset ascii = StandardCharsets.US_ASCII;
StringContent(CharSequence c, String t) {
content = c.toString();
type = t + "; charset=iso-8859-1";
}
StringContent(CharSequence c) {
this(c, "text/plain");
}
StringContent(Exception x) {
StringWriter sw = new StringWriter();
x.printStackTrace(new PrintWriter(sw));
type = "text/plain; charset=iso-8859-1";
content = sw.toString();
}
@Override
public String type() {
return type;
}
@Override
public long length() {
return byteBuffer.remaining();
}
@Override
public void prepare() throws IOException {
encode();
byteBuffer.rewind();
}
private void encode() {
if (byteBuffer == null){
byteBuffer = ascii.encode(CharBuffer.wrap(content));
}
}
@Override
public boolean send(ChannelIO channelIO) throws IOException {
if (byteBuffer == null)
throw new IllegalStateException();
channelIO.write(byteBuffer);
return byteBuffer.hasRemaining();
}
/**
* 这是个空方法
* 后面只是为了统一调用
*/
@Override
public void release() {
}
}我们接着回到Reply,Reply里面有Code、Content,还有一个辅助构建请求头的,我将发送数据的也放置在这个方法里面,所以Reply也实现了Sendable接口, 负责将数据发送给客户端, 所以Reply如下所示:
public class Reply implements Sendable {
static class Code{
private int number;
private String description;
public Code(int number, String description) {
this.number = number;
this.description = description;
}
static Code OK = new Code(200,"OK");
static Code BAD_REQUEST = new Code(400,"Bad Request");
static Code NOT_FOUND = new Code(404,"Not Found");
static Code METHOD_NOT_ALLOWED = new Code(405,"Method Not Allowed");
}
private Code code;
private Content content;
private ByteBuffer headerBuffer;
private static String CRLF = "\r\n";
private static Charset ascii = Charset.forName("US-ASCII");
public Reply(Code code, Content content) {
this.code = code;
this.content = content;
}
/**
* 这个方法负责添加请求头
* @return
*/
private ByteBuffer headers(){
CharBuffer cb = CharBuffer.allocate(1024);
cb.put("HTTP/1.0 ").put(code.toString()).put(CRLF);
cb.put("Server: niossl/0.1").put(CRLF);
cb.put("Content-type: ").put(content.type()).put(CRLF);
cb.put("Content-length: ")
.put(Long.toString(content.length())).put(CRLF);
cb.put(CRLF);
cb.flip();
return ascii.encode(cb);
}
@Override
public void prepare() throws IOException {
content.prepare();
headerBuffer = headers();
}
@Override
public boolean send(ChannelIO channelIO) throws IOException {
// 先写请求头
if (headerBuffer.hasRemaining()){
if (channelIO.write(headerBuffer) <= 0)
return true;
}
// 再写响应内容
if (content.send(channelIO))
return true;
return false;
}
@Override
public void release() {
content.release();
}
}现在开始组合请求和响应
现在我们请求和响应组件都齐活了,现在就可以将这两个组件组合起来干活了,这里我处理的流程为接收数据、解析数据、构建响应、发送数据。这个组合流程类就是按照这个流程来写的, 如下所示:
public class RequestServicer implements Runnable {
private ChannelIO channelIO;
public RequestServicer(ChannelIO channelIO) {
this.channelIO = channelIO;
}
private void service() throws IOException {
ByteBuffer byteBuffer = receive(); // 接收数据
Request request = null;
Reply reply = null;
try {
request = Request.parse(byteBuffer);
} catch (RequestException e) {
reply = new Reply(Reply.Code.BAD_REQUEST, new StringContent(e));
}
// 说明正常解析
if (reply == null) {
reply = build(request); // 构建回复
}
reply.prepare();
do {} while (reply.send(channelIO)); // Send
}
@Override
public void run() {
try {
service();
} catch (IOException e) {
e.printStackTrace();
}
}
ByteBuffer receive() throws IOException {
for (; ; ) {
int read = channelIO.read();
ByteBuffer bb = channelIO.getReadBuf();
if ((read < 0) || (Request.isComplete(bb))) {
bb.flip();
return bb;
}
}
}
Reply build(Request rq) throws IOException {
Reply rp = null;
Request.Action action = rq.action();
if ((action != Request.Action.GET)) {
rp = new Reply(Reply.Code.METHOD_NOT_ALLOWED,
new StringContent(rq.toString()));
rp.prepare();
return rp;
}
rp = new Reply(Reply.Code.OK,
new StringContent("hello world"));
rp.prepare();
return rp;
}
}在BlockingServer里面组合
public class BlockingServer extends Server{
private static final ExecutorService POOL = Executors.newFixedThreadPool(8);
public BlockingServer(int port, int backlog, boolean secure) throws IOException {
super(port, backlog, secure);
}
@Override
protected void runServer() throws IOException {
SocketChannel socketChannel = serverSocketChannel.accept();
ChannelIO channleIO = ChannelIO.getInstance(socketChannel, true);
RequestServicer requestServicer = new RequestServicer(channleIO);
POOL.submit(requestServicer);
}
}运行代码,在浏览器里面访问localhost:8080,就能看到helloWorld了,但是我们的HTTP服务器仍然存在一些问题,你会发现第一次回应请求很快,第二次回应请求就很慢,这是代码有问题,我们后面放着优化。
总结一下
这篇文章的创作时间远远比自己想象的时间长,本来想偷个懒,不在介绍计算机网络的演化和网络编程的基本概念,但是又想做到轻量级的阅读体验,就又重新梳理了一下自己对网络的理解,翻了翻自己以前的文章,发现自己对网络的理解,从下层到上层的演化这一层还是很模糊,幸运的是在知乎看到了一篇讲解网络发展历史的文章, 见参考文档[1]。本篇也是为后面的用JavaFX做简单通信软件的铺垫,承前启后。本篇完成的HTTP服务器是比较初级的,就是访问localhost:8080, 在浏览器上会返回hello world,后面会再补充上文件类型,使用零拷贝技术来实现。后面再用NIO、Netty再实现一遍。先去实践,有了实践再去看Netty的源码,分析其原理。写本篇的时候,我也在有意识的去舍弃过去手册式的写法,我用的是我喜欢教科书的风格,力图把读者当成朋友,平等对待,娓娓谈心,我不仅告诉了哪些是对的,还告知了我的探索过程,就是我是如何得出这个结论的,写HTTP服务器的时候,我自认为比较熟悉了,但真正动笔的时候才发现,自己有些地方还是理解不对,颇有点纸上得来终觉浅,绝知此事要躬行的感觉。我在给出设计的时候,总是先给出目标,再给出我为什么要这么设计,诸君完全可以写出跟我完全不同的代码,原理本质的东西我都告诉了诸君。
本篇基本参考的事JDK 8的demo,JDK 8给了新特性的示例,我看了这个代码觉得比较有趣,就觉得以自己的方式来解读一下,本身预先设定的目标倒是没有这么多,写着写着内容就变得庞大了起来,本来还打算介绍一下面向对象设计,接口的动机,都糅合在本篇想来比较大了,太大的内容,整体上内容似乎也不连贯,后面用NIO重写的时候,会尝试将这些进行分拆,增加一下阅读体验。
强调一下,关于网络的演化,主要参考的是参考资料[1],关于网络演化的这方面写的真不错。
参考资料
[1] 有了 IP 地址,为什么还要用 MAC 地址? https://www.zhihu.com/question/21546408
[2] java socket编程中参数backlog的含义
[3] TCP 协议简介 https://www.ruanyifeng.com/blog/2017/06/tcp-protocol.html
[4] HTTP 消息结束的标志 https://www.jtr109.com/posts/http-end-identity/
[5] 浅入深出谭谈 HTTP 响应拆分(CRLF Injection)攻击(上) https://xz.aliyun.com/t/9707