Java集合容器详解:ArrayList、LinkedList和HashMap、HashTable及其区别
文章目录
-
- 一、简介
- 二、ArrayList详解
-
- 2.1 动态数组
- 2.2 扩容机制
- 2.3 特点
- 2.4 操作
- 三、LinkedList详解
-
- 3.1 双向链表结构
- 3.2 双向链表结构
- 3.3 操作
- 四、HashMap详解
-
- 4.1 概述
- 4.2 内部实现
-
- 4.2.1 哈希表结构
- 4.2.2 散列冲突解决
- 4.2.3 扩容机制
- 4.3 版本差异
- 4.4 实操
- 五、HashTable
-
- 5.1 概述
- 5.2 内部实现
- 5.3 特点
- 六、区别与总结
-
- 6.1 ArrayList和LinkedList的区别
- 6.2 HashMap和HashTable的区别
- 6.3 总结
一、简介
Java集合框架是Java提供的一组用于存储和操作数据的类和接口。其中,ArrayList、LinkedList和HashMap、HashTable是常用的集合容器,它们在不同的场景中具有重要性和广泛应用。
二、ArrayList详解
ArrayList内部使用数组作为数据存储结构,数组可以通过下标直接访问元素的内存地址,因此访问的效率很高。通过下标访问元素的时间复杂度为O(1),即常数时间。
2.1 动态数组
数组是一块连续的内存空间,数组建立后就无法修改数组长度。ArrayList为了能够动态扩容数组,在每次扩容时都创建一个新的数组,再把旧的数组中的元素添加到新数组中。通过不断更换更大容量的数组来实现动态数组。
2.2 扩容机制
在数组容量不足时,需要创建更大的新数组,这个过程叫做“扩容”。
一开始创建ArrayList对象,并为添加元素时,ArrayList的容量为0。再添加第一个元素后,初始容量变为默认的10,也就是可以存储下标0-9的的数据。
即使可以存10个元素,在存储数据时也要按下标顺序存,不允许按照下标跳着存数据,例如数组为空,直接在下标1存数据,不是从下标0开始存数据,这样会报错。
什么时候扩容?
每次添加元素都会判断是否需要扩容,如果需要,会先扩容,再插入元素。扩容时,新数组的容量是原数组容量的1.5倍。
2.3 特点
-
随机访问高效
由于ArrayList使用数组作为内部数据结构,可以通过下标直接访问元素的内存地址,因此随机访问的效率很高。通过索引访问元素的时间复杂度为O(1),即常数时间。 -
查询和修改操作
ArrayList提供了丰富的查询和修改操作方法。可以根据索引查询元素,也可以根据索引修改元素。这使得ArrayList在需要频繁访问和修改元素的场景中非常适用。
2.4 操作
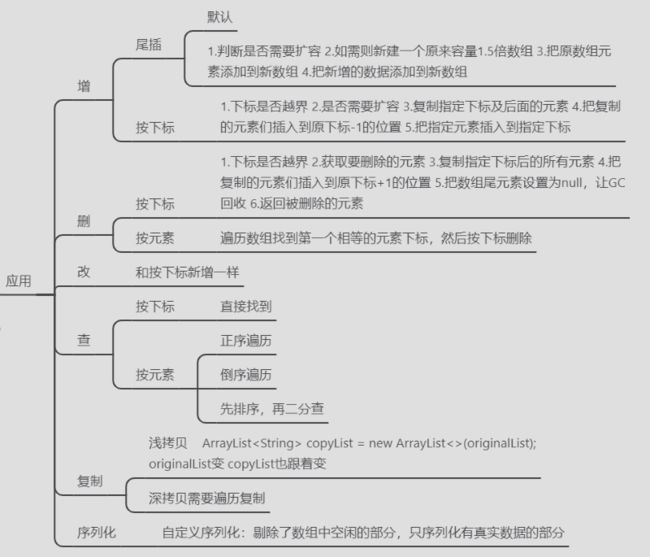
因为底层数据结构是数组,在操作数组时会有些步骤,下图是场景操作的步骤,数组的优点是按下标读取快,但是操作数据就有些复杂。
下面是一个使用ArrayList的示例代码:
import java.util.ArrayList;
public class ArrayListExample {
public static void main(String[] args) {
// 创建ArrayList
ArrayList<String> list = new ArrayList<>();
// 添加元素
list.add("苹果");
list.add("香蕉");
list.add("橙子");
// 遍历元素
for (String fruit : list) {
System.out.println(fruit);
}
// 根据索引访问元素
String firstFruit = list.get(0);
System.out.println("第一个水果:" + firstFruit);
// 根据索引修改元素
list.set(1, "草莓");
System.out.println("修改后的水果列表:" + list);
}
}
三、LinkedList详解
3.1 双向链表结构
LinkedList基于双向链表实现,可以高效地进行插入和删除操作,并提供了遍历和索引操作的能力。内部使用双向链表作为数据存储结构。每个Node(节点)包含一个元素和两个指针,分别指向前一个节点和后一个节点。通过这种结构,LinkedList可以在O(1)的时间复杂度内进行插入和删除操作。
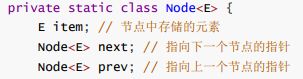
3.2 双向链表结构
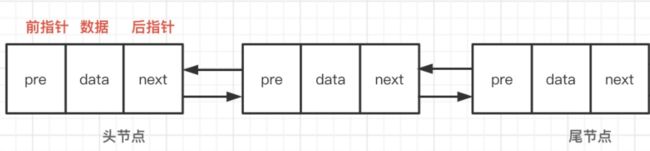
-
插入和删除操作高效
由于LinkedList使用双向链表结构,插入和删除操作非常高效。在插入和删除元素时,只需要修改相邻节点的指针,不需要像数组那样进行元素的移动和复制。 -
遍历和索引操作
LinkedList可以通过遍历访问每个元素,也可以通过索引访问特定位置的元素。但是,由于链表没有数组那样的随机访问能力,索引操作的效率较低,并且遍历建议不要使用for循环,使用迭代器效率更高。
3.3 操作
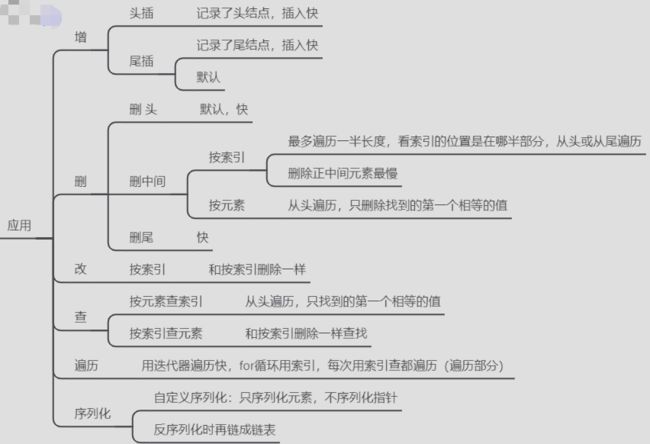
示例代码:
import java.util.LinkedList;
public class LinkedListExample {
public static void main(String[] args) {
// 创建LinkedList
LinkedList<String> list = new LinkedList<>();
// 添加元素
list.add("苹果");
list.add("香蕉");
list.add("橙子");
// 遍历元素
for (String fruit : list) {
System.out.println(fruit);
}
// 在指定位置插入元素
list.add(1, "草莓");
System.out.println("插入后的水果列表:" + list);
// 删除指定位置的元素
list.remove(2);
System.out.println("删除后的水果列表:" + list);
}
}
四、HashMap详解
4.1 概述
HashMap是基于哈希表实现的集合容器,具有高效的键值存储和查找能力。它适用于需要高效存储和查找键值对的场景,例如缓存数据、数据索引和键值对存储等。通过使用HashMap,我们可以方便地操作和管理键值对,提高代码的效率和灵活性。
4.2 内部实现
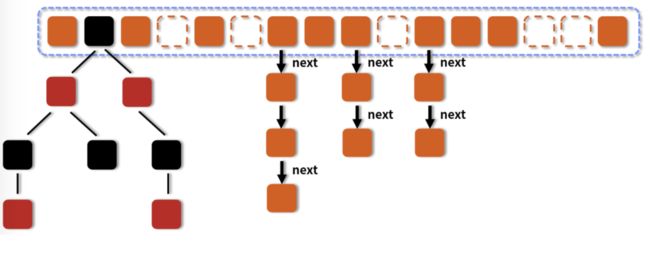
4.2.1 哈希表结构
HashMap内部使用哈希表作为数据存储结构。哈希表由一个数组和链表组成。数组的每个元素称为桶(bucket),每个桶可以存储一个或多个键值对。通过哈希函数将键映射到桶的索引(数组的下标),实现快速的存储和查找。
4.2.2 散列冲突解决
由于哈希函数的映射不是一对一的,可能会出现多个键映射到同一个桶的情况,称为散列冲突。
jdk1.8版本之前单纯使用链表解决哈希冲突,1.8以后使用链表+红黑树来解决。当链表长度超过阈值8时,链表会转换为红黑树,提高查找效率。当红黑树节点个数低于6时,又转变会链表结构。
4.2.3 扩容机制
HashMap的底层是数组,数组无法修改长度,本质也是创建一个新数组,再把数据挪进去。
什么时候需要扩容?
根据泊松算法,当数组的数据存储达到容量的70%-80%左右,产生哈希冲突的概率会大大增加,所以HashMap设置了一个负载因子——0.75,也就是说当数组的数据量达到容量的75%后就该马上扩容了。HashMap在每次插入新数据的时候都会判断是否需要扩容,和ArrayList扩容时间一样。最大扩到2的31次方-1(int类型最大值)。
HashMap的扩容流程如下:
-
HashMap初始容量是16,当元素数量达到负载因子(0.75)与容量的乘积时,即元素数量超过了扩容阈值,需要进行扩容操作。
-
创建一个新的数组,其长度是原数组的两倍。新数组的长度一般选择为原数组长度的两倍,这是经验性的选择,可以在时间和空间效率之间做一个折中。
-
遍历原数组中的每个元素,重新计算它们在新数组中的位置,并将其移动到新数组中的对应位置。这一步是为了保持元素之间的相对顺序不变。
-
在移动元素时,如果发现新数组中的某个位置已经被占用,则使用链表或红黑树(在JDK 8及以后的版本中)来解决哈希冲突。这是因为在扩容后,原本哈希冲突的元素可能被分散到新数组的不同位置,需要重新处理冲突。
-
扩容完成后,HashMap的容量会增加为原来的两倍,并且负载因子的值保持不变。
4.3 版本差异
| 特性 | HashMap 1.7 | HashMap 1.8 |
|---|---|---|
| 处理哈希冲突的方式 | 链表 | 链表 + 红黑树 |
| 扩容机制 | 先扩容再插入 | 先插入再扩容 |
| 扩容后 | 先重新计算所有元素hash值,更换桶位置 | 不用重新计算hash,新的下标为原索引+原来的容量 |
4.4 实操
HashMap适用于需要高效的键值存储和查找的场景。
- 缓存数据:HashMap可以用作缓存数据的容器,提供快速的查找和插入能力。
- 数据索引:由于HashMap提供了快速的查找操作,可以用于构建数据索引,加快数据的检索速度。
- 键值对存储:如果需要将一组键值对进行存储和管理,并且对快速查找的需求较高,可以选择使用HashMap。

代码示例:
import java.util.HashMap;
public class HashMapExample {
public static void main(String[] args) {
// 创建HashMap
HashMap<String, Integer> map = new HashMap<>();
// 添加键值对
map.put("苹果", 10);
map.put("香蕉", 5);
map.put("橙子", 8);
// 获取键对应的值
int appleCount = map.get("苹果");
System.out.println("苹果的数量:" + appleCount);
// 遍历键值对
for (String fruit : map.keySet()) {
int count = map.get(fruit);
System.out.println(fruit + "的数量:" + count);
}
// 判断键是否存在
boolean containsKey = map.containsKey("橙子");
System.out.println("是否包含橙子:" + containsKey);
// 删除键值对
map.remove("香蕉");
System.out.println("删除香蕉后的水果列表:" + map);
}
}
五、HashTable
5.1 概述
HashTable是Java中的一个集合容器,它是线程安全的数据结构。
5.2 内部实现
- 哈希表结构
HashTable内部使用哈希表作为数据存储结构。哈希表由一个数组和链表组成,每个桶可以存储一个或多个键值对。 - 散列冲突解决
HashTable使用开放地址法(Open Addressing)解决散列冲突。当发生冲突时,它会尝试将键映射到下一个空闲的桶,直到找到合适的位置。
5.3 特点
-
线程安全性
HashTable是线程安全的集合容器,它在操作上提供了同步机制,保证多线程环境下的安全性。它使用synchronized关键字来实现同步,但这也导致了性能的降低。 -
性能
由于HashTable提供了线程安全性,它在多线程环境下的性能较差。在单线程环境下,HashMap的性能通常优于HashTable。
import java.util.Arrays;
class HashTable {
private static final int TABLE_SIZE = 10;
private Entry[] table;
HashTable() {
table = new Entry[TABLE_SIZE];
}
// 哈希函数
private int hashFunction(int key) {
return key % TABLE_SIZE;
}
// 插入键值对
public void put(int key, String value) {
int index = hashFunction(key);
Entry entry = new Entry(key, value);
if (table[index] == null) {
table[index] = entry;
} else {
Entry current = table[index];
while (current.next != null) {
current = current.next;
}
current.next = entry;
}
}
// 获取键对应的值
public String get(int key) {
int index = hashFunction(key);
Entry current = table[index];
while (current != null) {
if (current.key == key) {
return current.value;
}
current = current.next;
}
return null;
}
// 删除键值对
public void remove(int key) {
int index = hashFunction(key);
Entry current = table[index];
Entry previous = null;
while (current != null) {
if (current.key == key) {
if (previous == null) {
table[index] = current.next;
} else {
previous.next = current.next;
}
return;
}
previous = current;
current = current.next;
}
}
// 打印哈希表内容
public void printTable() {
for (int i = 0; i < TABLE_SIZE; i++) {
Entry current = table[i];
System.out.print(i + ": ");
while (current != null) {
System.out.print("(" + current.key + ", " + current.value + ") ");
current = current.next;
}
System.out.println();
}
}
// 哈希表的节点
private static class Entry {
int key;
String value;
Entry next;
Entry(int key, String value) {
this.key = key;
this.value = value;
this.next = null;
}
}
}
public class Main {
public static void main(String[] args) {
HashTable hashTable = new HashTable();
// 插入键值对
hashTable.put(1, "Value 1");
hashTable.put(11, "Value 11");
hashTable.put(21, "Value 21");
hashTable.put(2, "Value 2");
// 打印哈希表
hashTable.printTable();
// 获取键对应的值
System.out.println("Value for key 1: " + hashTable.get(1));
System.out.println("Value for key 11: " + hashTable.get(11));
// 删除键值对
hashTable.remove(11);
// 打印哈希表
hashTable.printTable();
}
}
六、区别与总结
6.1 ArrayList和LinkedList的区别
ArrayList和LinkedList都是Java中的集合容器,它们的区别如下:
- 内部实现:ArrayList基于动态数组,LinkedList基于双向链表。
- 随机访问:ArrayList通过索引可以快速访问元素,时间复杂度为O(1);LinkedList需要遍历链表才能访问元素,时间复杂度为O(n)。
- 插入和删除:ArrayList插入和删除元素时需要移动后续元素,时间复杂度为O(n);LinkedList插入和删除元素只需修改前后节点的指针,时间复杂度为O(1)。
- 适用场景:ArrayList适用于频繁访问和遍历元素的场景;LinkedList适用于频繁插入和删除元素的场景。
6.2 HashMap和HashTable的区别
HashMap和HashTable都是Java中的集合容器,它们的区别如下:
- 线程安全性:HashMap不是线程安全的,HashTable是线程安全的。
- 空键和空值:HashMap允许空键和空值,HashTable不允许空键和空值。
- 性能:HashMap在单线程环境下的性能通常优于HashTable,因为HashTable使用synchronized关键字实现同步,导致性能较差。
- 迭代器:HashMap的迭代器是快速失败的(fail-fast),而HashTable的迭代器不是。
6.3 总结
- ArrayList适用于频繁访问和遍历元素的场景,LinkedList适用于频繁插入和删除元素的场景。
- HashMap适用于非线程安全的场景,HashTable适用于线程安全的场景。
- HashMap在性能上通常优于HashTable,但HashTable提供了线程安全性。
- 在选择集合容器时,根据具体的需求和场景综合考虑线程安全性、性能和功能特点。
根据这些内容,可以选择适合自己需求的集合容器,并理解它们的特点和用法。