原文链接:http://tecdat.cn/?p=23305
在这篇文章中,我将展示如何使用R语言来进行支持向量回归SVR。
我们将首先做一个简单的线性回归,然后转向支持向量回归,这样你就可以看到两者在相同数据下的表现。
一个简单的数据集
首先,我们将使用这个简单的数据集。

正如你所看到的,在我们的两个变量X和Y之间似乎存在某种关系,看起来我们可以拟合出一条在每个点附近通过的直线。
我们用R语言来做吧!
第1步:在R中进行简单的线性回归
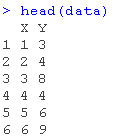
下面是CSV格式的相同数据,我把它保存在regression.csv文件中。
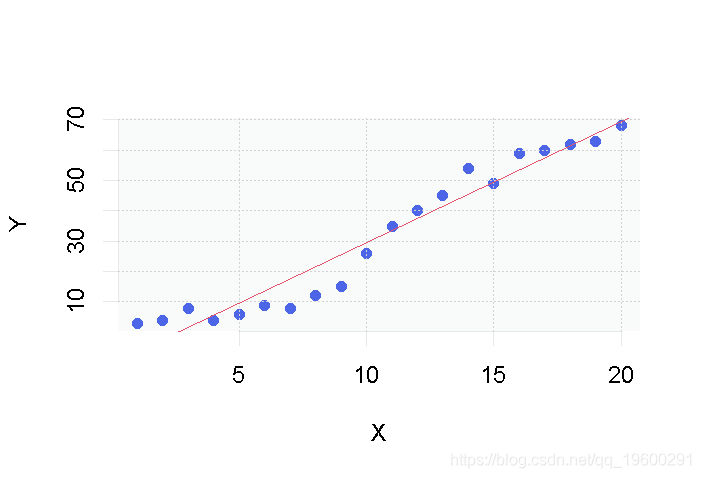
我们现在可以用R来显示数据并拟合直线。
# 从csv文件中加载数据
dataDirectory <- "D:/" #把你自己的文件夹放在这里
data <- read.csv(paste(dataDirectory, 'data.csv', sep=""), header = TRUE)
# 绘制数据
plot(data, pch=16)
# 创建一个线性回归模型
model <- lm(Y ~ X, data)
# 添加拟合线
abline(model)上面的代码显示以下图表:
第2步:我们的回归效果怎么样?
为了能够比较线性回归和支持向量回归,我们首先需要一种方法来衡量它的效果。
为了做到这一点,我们改变一下代码,使模型做出每一个预测可视化
# 对每个X做一个预测
pred <- predict(model, data)
# 显示预测结果
points(X, pred)产生了以下图表。
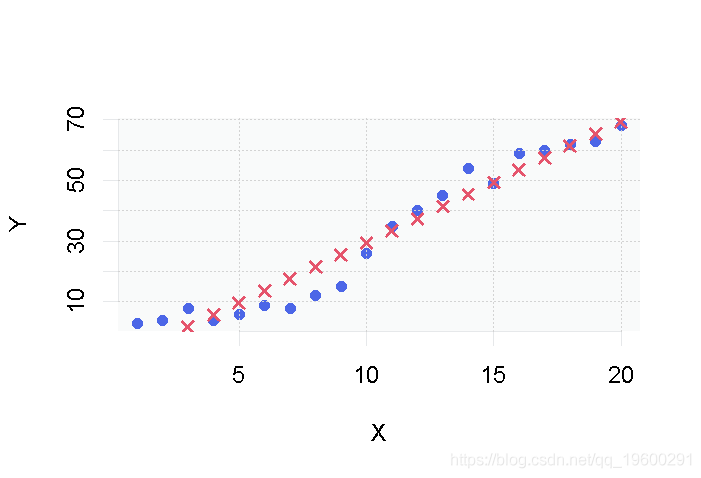
对于每个数据点Xi,模型都会做出预测Y^i,在图上显示为一个红色的十字。与之前的图表唯一不同的是,这些点没有相互连接。
为了衡量我们的模型效果,我们计算它的误差有多大。
我们可以将每个Yi值与相关的预测值Y^i进行比较,看看它们之间有多大的差异。
请注意,表达式Y^i-Yi是误差,如果我们做出一个完美的预测,Y^i将等于Yi,误差为零。
如果我们对每个数据点都这样做,并将误差相加,我们将得到误差之和,如果我们取平均值,我们将得到平均平方误差(MSE)。
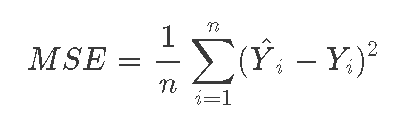
在机器学习中,衡量误差的一个常见方法是使用均方根误差(RMSE),所以我们将使用它来代替。
为了计算RMSE,我们取其平方根,我们得到RMSE

使用R,我们可以得到以下代码来计算RMSE
rmse <- function(error)
{
sqrt(mean(error^2))
}
我们现在知道,我们的线性回归模型的RMSE是5.70。让我们尝试用SVR来改善它吧!
第3步:支持向量回归
用R创建一个SVR模型。
下面是用支持向量回归进行预测的代码。
model <- svm(Y ~ X , data)如你所见,它看起来很像线性回归的代码。请注意,我们调用了svm函数(而不是svr!),这是因为这个函数也可以用来用支持向量机进行分类。如果该函数检测到数据是分类的(如果变量是R中的一个因子),它将自动选择SVM。
代码画出了下面的图。

这一次的预测结果更接近于真实的数值 ! 让我们计算一下支持向量回归模型的RMSE。
# 这次svrModel$residuals与data$Y - predictedY不一样。
#所以我们这样计算误差
svrPredictionRMSE
正如预期的那样,RMSE更好了,现在是3.15,而之前是5.70。
但我们能做得更好吗?
第四步:调整你的支持向量回归模型
为了提高支持向量回归的性能,我们将需要为模型选择最佳参数。
在我们之前的例子中,我们进行了ε-回归,我们没有为ε(ϵ)设置任何值,但它的默认值是0.1。 还有一个成本参数,我们可以改变它以避免过度拟合。
选择这些参数的过程被称为超参数优化,或模型选择。
标准的方法是进行网格搜索。这意味着我们将为ϵ和成本的不同组合训练大量的模型,并选择最好的一个。
# 进行网格搜索
tuneResultranges = list(epsilon = seq(0,1,0.1), cost = 2^(2:9))
# 绘制调参图
plot(Result)在上面的代码中有两个重要的点。
- 我们使用tune方法训练模型,ϵ=0,0.1,0.2,...,1和cost=22,23,24,...,29这意味着它将训练88个模型(这可能需要很长一段时间
- tuneResult返回MSE,别忘了在与我们之前的模型进行比较之前将其转换为RMSE。
最后一行绘制了网格搜索的结果。

在这张图上,我们可以看到,区域颜色越深,我们的模型就越好(因为RMSE在深色区域更接近于零)。
这意味着我们可以在更窄的范围内尝试另一个网格搜索,我们将尝试在0和0.2之间的ϵ值。目前看来,成本值并没有产生影响,所以我们将保持原样,看看是否有变化。
rangelist(epsilo = seq(0,0.2,0.01), cost = 2^(2:9))我们用这一小段代码训练了不同的168模型。
当我们放大暗区域时,我们可以看到有几个较暗的斑块。
从图中可以看出,C在200到300之间,ϵ在0.08到0.09之间的模型误差较小。
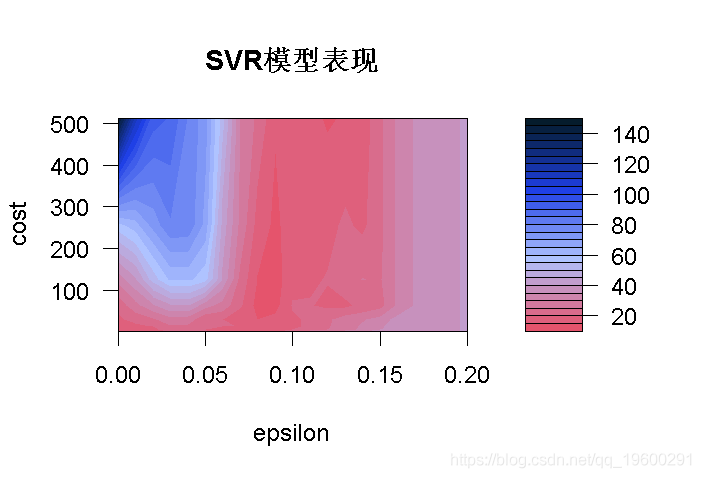 希望对我们来说,我们不必用眼睛去选择最好的模型,R让我们非常容易地得到它,并用来进行预测。
希望对我们来说,我们不必用眼睛去选择最好的模型,R让我们非常容易地得到它,并用来进行预测。
# 这个值在你的电脑上可能是不同的
# 因为调参方法会随机调整数据
tunedModelRMSE <- rmse(error)
我们再次提高了支持向量回归模型的RMSE !
我们可以把我们的两个模型都可视化。在下图中,第一个SVR模型是红色的,而调整后的SVR模型是蓝色的。
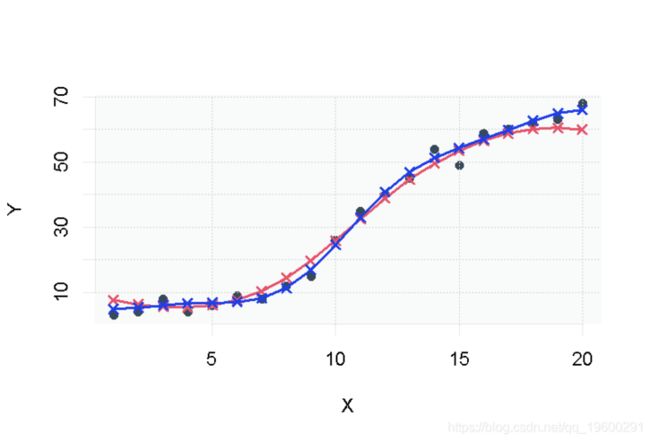
我希望你喜欢这个关于用R支持向量回归的介绍。你可以查看原文得到本教程的源代码。

最受欢迎的见解
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
6.r语言中对LASSO回归,Ridge岭回归和Elastic Net模型实现