变形金刚:从零开始【01/2】

一、说明
在我们的日常生活中,无论你是否是数据科学家,你都在单向地使用变压器模型。例如。如果您使用的是 ChatGPT 或 GPT-4 或任何 GPT,那么在为您回答问题的框中是变压器的一部分。如果您是数据科学家或数据分析师,则可能正在使用转换器执行文本分类、令牌分类、问答、Text2text 或任何与此相关的任务,您正在使用转换器模型。我们确实为我们的面试学习理论,每个人都这样做,但你有没有想过如何从头开始创建一个变压器模型。
先从变压器开始,我们先来看看整个架构:

图1.变压器模型体系结构
已经挠头了?让我们分解一下,以便我们可以更好地理解。
- 我们可以并排两个盒子(Nx),它们是左侧的编码器和右侧的解码器。
二、从编码器开始
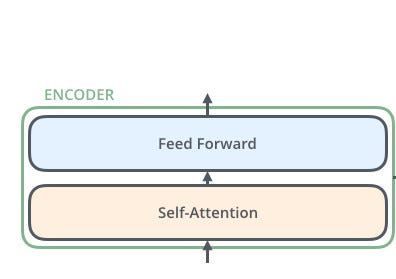 图2.编码器
图2.编码器
编码器内有两个块。我们只需要用python编写自我注意和前馈块。
为了更好地理解它,让我们使用一个分词器。因此,我们可以通过一个例子来理解该模型。
from transformers import AutoTokenizer
tokenizer = Autotokenizer.from_pretrained('bert-base-uncased')
text = 'I love data science.'
print(tokenizer(text, add_special_tokens=False, return_tensors='pt'))
inputs = tokenizer(text, add_special_tokens=False, return_tensors='pt')# The above code will produce the following output
# {'input_ids': tensor([[1045, 2293, 2951, 2671, 1012]]),
# 'token_type_ids': tensor([[0, 0, 0, 0, 0]]),
# 'attention_mask': tensor([[1, 1, 1, 1, 1]])}现在,在上面的单元格中,我们可以看到分词器已将句子“我爱数据科学”标记为标记 (input_ids)。现在请注意,我没有使用任何特殊令牌,如 [CLS] 或 [SEP]。
三、配置Bert
标记化我们的文本后,让我们尝试获取“bert-base-model”的配置,以便我们可以尝试制作可以像 BERT 模型一样产生结果的模型。听起来很有趣?赤穗让我们深入了解BERT的配置。
from transformers import AutoConfig
config = AutoConfig.from_pretrained('bert-base-uncased')
print(config)# The above cell should output as:
BertConfig {
"_name_or_path": "bert-base-uncased",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.29.2",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}如我们所见,BERT模型具有上述配置。
四、嵌入层
接下来,我们需要创建一些密集嵌入。在此上下文中,密集意味着嵌入中的每个条目都包含一个非零值。相比之下,独热编码是稀疏的,因为除了一个之外的所有条目都是零。在 PyTorch 中,我们可以通过使用一个层来做到这一点,该层充当每个输入 ID 的查找表:torch.nn.Embedding
from torch import nn
token_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
print(token_embeddings)
# output:
# Embedding(30522, 768)现在我们有了查找表,我们可以通过输入 ID 来生成嵌入:
inputs_embeds = token_embeddings(inputs.input_ids)
print(inputs_embeds.size())
# output:
# torch.Size([1, 5, 768]) 这给了我们一个 形状张量 .现在让我们计算注意力分数[batch_size, seq_len, hidden_dim]
要计算注意力权重,有四个步骤:
- 将嵌入的每个令牌投影到三个向量中,分别称为查询、键和值。
- 计算注意力分数。我们使用相似性函数确定查询和键向量之间的关联程度。顾名思义,缩放点积注意力的相似性函数是点积,使用嵌入的矩阵乘法高效计算。相似的查询和键将具有较大的点积,而那些没有太多共同点的查询和键将几乎没有重叠。此步骤的输出称为注意力分数,对于具有 n 个输入标记的序列,有一个相应的 n x n 个注意力分数矩阵。
- 计算注意力权重。点积通常可以产生任意大的数字,这可能会破坏训练过程的稳定性。为了解决这个问题,首先将注意力分数乘以比例因子以规范化其方差,然后使用 softmax 进行归一化,以确保所有列值的总和为 1。生成的 n × n 矩阵现在包含所有注意力权重。
- 更新令牌嵌入。一旦计算出注意力权重,我们将它们乘以值向量以获得嵌入的更新表示。
import torch
import torch.nn.functional as F
from math import sqrt
query = key = value = inputs_embeds
def scaled_dot_product_attention(query, key, value):
dim_k = query.size(-1)
scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(dim_k) # torch.bmm is batch matrix - matrix multiplication.
# Basically a dot product.
weights = F.softmax(scores, dim=-1)
return torch.bmm(weights, value)这就是我们计算自我注意力的方式。看起来很简单吧?到目前为止还好吗?赤穗现在让我们计算多头注意力。
好吧,你可能会想,如果我们有一个关注,那么我们为什么不停在那里呢?为什么要使用多头注意力?好吧,原因是一个头的softmax倾向于主要关注相似性的一个方面。拥有多个头部允许模型同时关注多个方面。例如,一个头可以专注于主谓互动,而另一个头可以找到附近的形容词。显然,我们不会将这些关系手工制作到模型中,它们是从数据中完全学习的。如果您熟悉计算机视觉模型,您可能会看到它与卷积神经网络中的过滤器相似,其中一个过滤器可以负责检测人脸,另一个过滤器可以在图像中发现汽车车轮。
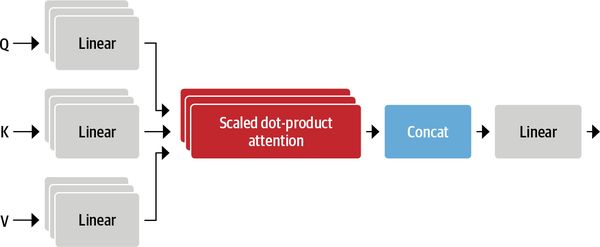 图3.多头注意力层
图3.多头注意力层
图 3 清楚地说明了我们将如何为多头注意力层编写代码。让我们从那开始:
class AttentionHead(nn.Module):
def __init__(self, embed_dim, head_dim):
super().__init__()
self.q = nn.Linear(embed_dim, head_dim)
self.k = nn.Linear(embed_dim, head_dim)
self.v = nn.Linear(embed_dim, head_dim)
def forward(self, hidden_state):
attn_outputs = scaled_dot_product_attention(self.q(hidden_state), self.k(hidden_state), self.v(hidden_state))
return attn_outputs
在这里,我们已经初始化了三个独立的线性层,它们将矩阵乘法应用于嵌入向量以产生形状的张量,其中是我们投影到的维度数。虽然不必小于令牌的嵌入维度数 (),但在实践中,它被选择为的倍数,以便每个头的计算是恒定的。例如,BERT 有 12 个注意力头,因此每个头的尺寸为 768/12 = 64[batch_size, seq_len, head_dim]head_dimhead_dimembed_dimembed_dim
五、多头注意力
这就是我们如何创建一个单一的头部注意力层。现在让我们制作多头注意力层:
class MultiHeadAttention(nn.Module):
def __init__(self, config):
super().__init__()
embed_dim = config.hidden_size
num_heads = config.num_attention_heads
head_dim = embed_dim // num_heads
self.heads = nn.ModuleList([AttentionHead(embed_dim, head_dim) for _ in range(num_heads)])
self.output_linear = nn.Linear(embed_dim, embed_dim)
def forward(self, hidden_state):
x = torch.cat([h(hidden_state) for h in self.heads], dim=-1)
x = self.output_linear(x)
return x让我们检查一下到目前为止的代码。
multihead_attn = MultiHeadAttention(config)
attn_output = multihead_attn(inputs_embeds)
print(attn_output.size())
# output
# torch.Size([1, 5, 768])如果我们得到类似的输出,那就干得好!
长话短说,这个模块接受一个输入张量(hidden_state),独立地应用多个“注意力头”,连接它们的输出并将它们传递到最终的线性层中。每个“注意力头”都学会“注意”数据中的不同部分/特征。理解?如果是,那么就是这样。您已经创建了自己的多头注意力图层,全部由您自己创建。太棒了!
六、前馈层
现在,让我们制作编码器的下一个块,即前馈层。编码器和解码器中的前馈子层只是一个简单的两层全连接神经网络,但有一个转折点:它不是将整个嵌入序列作为单个向量处理,而是独立处理每个嵌入。因此,该层通常称为按位置的前馈层。
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.linear_1 = nn.Linear(config.hidden_size, config.intermediate_size)
self.linear_2 = nn.Linear(config.intermediate_size, config.hidden_size)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, x):
x = self.linear_1(x)
x = self.gelu(x)
x = self.linear_2(x)
x = self.dropout(x)
return x 注意,前馈层通常应用于形状张量,它独立作用于批量维度的每个元素。这实际上适用于除最后一个维度以外的任何维度,因此当我们传递形状张量时,该层将独立地应用于批处理和序列的所有标记嵌入,这正是我们想要的。nn.Linear(batch_size, input_dim)(batch_size, seq_len, hidden_dim)
七、输出正确性检查
让我们检查一下我们编写的代码是否产生了正确的输出。
feed_forward = FeedForward(config)
ff_outputs = feed_forward(attn_output)
print(ff_outputs.size())
# output
# torch.Size([1, 5, 768])如果您获得相同的输出,那么您走在正确的道路上。
它将变得太大而无法阅读。所以我把它分成两部分。如果您觉得这很有趣,请在评论中或关注我时告诉我。我将很快发布第二部分。
八、后记
注意:在第二部分中,我们将研究层规范化的实现,位置嵌入以及如何向模型添加最后一层以使模型执行不同的任务,如文本分类,标记分类等。然后我们将研究解码器部分。希望你和我一样兴奋。在那之前,祝您编码愉快!
参考资料:
BERTopic: Fine-tune Parameters. In general, BERTopic works fine with… | by DamenC | Medium
Transformer’s from scratch in simple python. Part-I | by Harshad Patil | Aug, 2023 | Medium